控制抽象
Posted dabokele
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了控制抽象相关的知识,希望对你有一定的参考价值。
本章主要讲解在Scala中如何使用函数值来自定义新的控制结构,并且介绍Curring和By-name参数的概念。
一、减少重复代码
1、重复代码的场景描述
前面定义的函数,将实现某功能的代码封装到一起形成一个特定功能的代码块。那么,正常情况下,各函数之间有可能会有部分逻辑是相同的。不好理解的话,看看下面的代码。
object FileMatcher
private def filesHere = (new java.io.File(".")).listFiles
def filesEnding(query: String) =
for (file <- filesHere; if file.getName.endsWith(query))
yield file
def filesContaining(query: String) =
for (file <- filesHere; if file.getName.contains(query))
yield file
def filesRegex(query: String) =
for (file <- filesHere; if file.getName.matches(query))
yield file
上面代码中定义了一个文件操作对象FileMatcher,其中有三个函数,filesEnding是表示筛选出其中以特定字符结尾的文件,filesContaining表示筛选出其中包含特定字符的文件,filesRegex表示根据正则表达式匹配。仔细看这三个函数,大体上的代码都是相同的,只有部分特殊逻辑不相同。
2、使用函数参数
幸好Scala为这种情况提供了一个简化代码的策略,即定义一个方法,该方法传入两个参数,第一个参数为文件名,第二个参数为一个方法变量。比如
def filesMatching(query: String, matcher: (String, String) => Boolean) =
for (file <- filesHere; if matcher(file.getName, query))
yield file
其中filesMatching方法的第二个参数是一个函数,输入参数为两个String类型变量,返回值为一个Boolean类型的值。
如果想要基于该函数实现一个filesEnding函数,第一反应是写如下一段代码
def filesEnding(query: String) =
filesMatching(query, _.endsWith(_))这里的filesEnding函数接收一个参数query,以及一个函数参数_.endsWith(_)。该函数参数使用了下划线的形式来表示输入参数,表示该函数参数接收两个参数,其中第一个参数作用在第一个下划线处,第二个参数作用在第二个下划线处,即该函数参数完整的表现形式是
(fileName: String, query: String) => fileName.endsWith(query) 进一步,我们看到,filesMatching函数在调用该函数参数时,传入一个函数名,然后将传入的query参数不作任何处理直接传递到_.endsWith的函数参数中。从前面有关闭包部分的知识我们知道这里其实也是可以进行简化的,进一步简化的filesEnding函数如下所示
def filesEnding(query: String) =
filesMatching(_.endsWith(query)) 这里解释一下,_.endsWith(query)根据传入的query参数的内容,动态的生成一个闭包函数,该函数只接收一个String类型的参数,并且该参数实质上应该是传入一个文件名。此时filesMatching函数的也需要重写,可以参考下面一段代码。
3、代码简化
那么,对于最前面那段代码中的功能,可以将代码简化成如下形式。将逻辑相同的部分进一步剥离,形成一个函数finesMatching,然后其他三个函数,分别调用该函数,传入一个文件名处理函数即可。注意这里的filesMatching函数与前面的不同之处。
object FileMatcher
private def filesHere = (new java.io.File(".")).listFiles
def filesMatching(matcher: String => Boolean) =
for (file <- filesHere; if matcher(file.getName))
yield file
def filesEnding(query: String) =
filesMatching(_.endsWith(query))
def filesContaining(query: String) =
filesMatching(_.contains(query))
def filesRegex(query: String) =
filesMatching(_.matches(query))
二、简化客户端代码
这里也是和第一节中的类似,通过调用接收函数参数的函数来实现代码简化,只不过第一节中的函数是用户自定义的,而这里的函数是Scala API提供的。
1、直观的定义ccontainsNeg方法
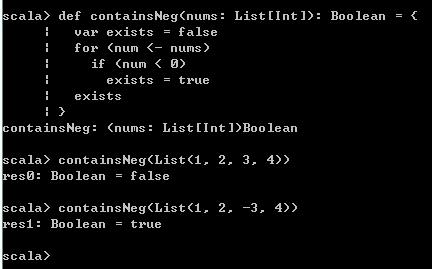
接下来通过自定义一个containsNeg方法来展开本节。containsNeg方法主要作用于Collection类型的对象上,用于判断List[Int]类型对象中是否包含小于0的元素。那么,最直观的实现方法是定义如下函数,在其中定义一个var变量,初始值为false,依次循环取出该List[Int]对象中的元素与给定元素进行比较,如果遇到小于0的元素,将该var变量更新为true,如下所示
def containsNeg(nums: List[Int]): Boolean =
var exists = false
for (num <- nums)
if (num < 0)
exists = true
exists
containsNeg(List(1, 2, 3, 4))
containsNeg(List(1, 2, -3, 4)) 运行结果如下,
2、使用exists方法接收函数参数简化containsNeg方法
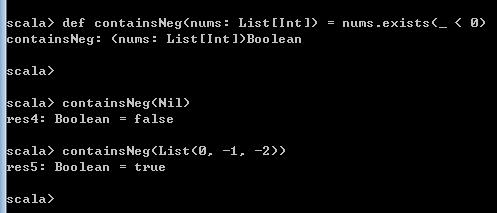
重新定义一个containsNeg方法,通过调用Collection对象的exists方法,传入一个函数,如下所示
def containsNeg(nums: List[Int]) = nums.exists(_ < 0)
containsNeg(Nil)
containsNeg(List(0, -1, -2)) 运行结果如下,
这里的exists方法,是Scala语言提供的一个具有特殊功能的控制结构语句,有点类似于while或for循环,但是用户可以根据需求传入一个自定义的函数用来实现更多功能。
这里和第二节中的filesMatching方法不同的是,filesMatching方法是用户自定义的,而exists方法是Scala API中提供的。在Scala API中还有一些类似于exists的方法,在写代码时最好多使用这些函数,以便简化代码。
三、Curring
在Scala中,除了可以使用之前介绍的Scala提供的控制结构之外,还可以用户自定义控制结构。在自定义控制结构之前,需要首先明确一个概念——柯里化(curring)。
柯里化的函数可以接收多个参数列表,而不是之前的那些函数中的一个参数列表。下面分别举例了一个非柯里化函数和一个柯里化函数,实现相同的求两个整数之和的功能。
1、非柯里化函数
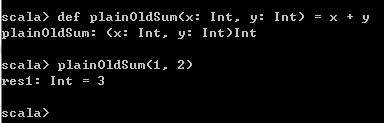
按照之前的函数定义风格,定义一个求和函数。
def plainOldSum(x: Int, y: Int) = x + y
plainOldSum(1, 2) 运行结果如下:
2、柯里化函数
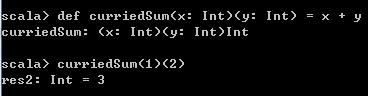
与上面的函数对比,这里列举出一个柯里化的求和函数。可以看到柯里化函数与非柯里化函数的明显区别是函数名后有两个括号,分别接收一个参数列表。
def curriedSum(x: Int)(y: Int) = x + y
curriedSum(1)(2) 运行结果如下:
3、柯里化函数分析
在调用curriedSum函数时,实际上会连续执行两个传统的函数。第一个函数接收一个Int型参数x,得到一个函数值,然后改函数值接收另一个Int型参数y,得到最终的计算结果。
curriedSum的执行过程可以由如下两个函数模拟得到。
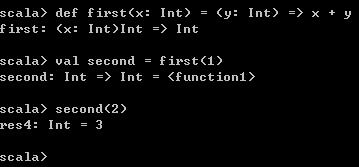
def first(x: Int) = (y: Int) => x + y
val second = first(1)
second(3) 执行过程如下
注意,上面的first和second只是对柯里化函数curriedSum执行过程的模拟,如果需要从curriedSum函数直接得到类似于second的函数,需要按部分应用函数的形式来表示,将第二个函数列表用下划线代替,如下所示
val onePlus = curriedSum(1)_
onePlus(2) 执行结果如下,部分应用函数的下划线和前面的函数调用之间可以加空格也可以不加空格。
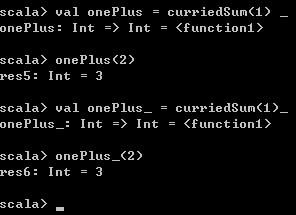
前面介绍部分应用函数,比如println _时明确强调需要在下划线前加空格,而在curriedSum(1)_时不需要空格。这是由于在Scala中println_可以合法表示一个变量名,而curriedSum(1)_明显不是一个变量名,Scala编译器在遇到这种表示法时不会出现歧义。
四、自定义控制结构
在Scala中,通过定义接收函数参数的函数可以定义新的控制结构。上一节中的柯里化的概念主要将作用于本节最后一部分,将代码中的圆括号改成花括号,使自定义控制结构的使用风格更加类似于Scala提供的控制结构。
1、简单的控制结构示例
比如下面的twice函数的参数列表中是一个函数参数以及一个Double类型的变量,当调用twice时会自动将传入的函数参数在传入的变量值上执行两遍。
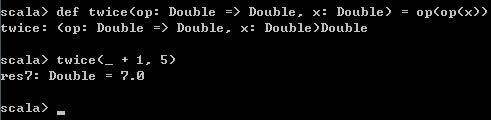
def twice(op: Double => Double, x: Double) = op(op(x))
twice(_ + 1, 5) 运行结果如下,
2、借贷模式(loan pattern)
所以,当在写代码时发现部分代码结构频繁使用到时,就需要考虑将这部分逻辑抽取出来形成一个自定义控制结构。在前面章节中提到的filesMatching函数是自定义控制结构的一种简单实现,接下来将实现一个稍微复杂一点的逻辑。
下面代码打开一个文件,操作该文件,最终关闭该文件的连接。
def withPrintWriter(file: File, op: PrintWriter => Unit)
val writer = new PrintWriter(file)
try
op(writer)
finally
writer.close()
withPrintWriter(new File("date.txt"), writer => writer.println(new java.util.Date)) 使用上面这种代码格式的一个好处是,定义好withPrintWtirer的整体结构后,用户只需要实现对文件的操作逻辑即可,不再需要显示的执行文件关闭的操作,并且也能保证文件操作完毕后一定会在finally中关闭该文件的连接。
这里也体现出了一种借贷模式的思想,在withPrintWriter方法中,writer获取到该文件的连接,然后将该文件借给操作函数op,待op用完该文件的连接时再将该文件连接还回withPrintWriter方法的后续代码,比如在finally代码中关闭该文件连接。
3、在自定义控制结构中使用代替()
回想一下for或while循环,在函数体部分使用的是花括号而非圆括号(),但是在上面的withPrintWriter方法的调用时使用的仍然是圆括号。
为了使得自定义控制结构和Scala提供的控制结构使用风格类似,可以将上面代码中的()替换成。
比如,
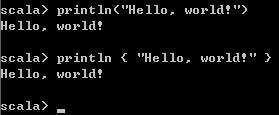
println("Hello, world!")
println "Hello, world!" 执行效果是相同的,
需要注意的是,将圆括号替换成花括号只能发生在接收一个参数值的函数上,如果某个函数接收的是两个参数,那么将圆括号改成花括号就会报错,如下所示
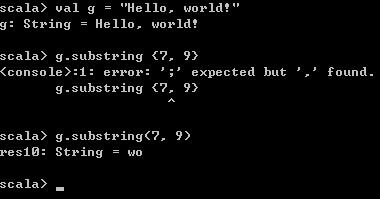
val g = "Hello, world!"
g.substring 7, 9
g.substring(7, 9) 执行结果如下,
4、使用柯里化改造withPrintWriter函数
接下来以前面的withPrintWriter函数为例,对其进行改造使调用时更像Scala提供的控制结构语法。回顾一下前面的withPrintWriter函数,参数列表中有两个参数,根据上一节中的分析,无法直接将圆括号改造成花括号。
要怎么办?回想一下之前的柯里化,可以将一个只有一个参数列表的函数改造成有多个参数列表的函数,这里如果将withPrintWriter进行柯里化,把后面的函数参数分离成只有一个参数的参数列表,那么就可以将其改造成花括号了,如下所示
def withPrintWriter(file: File)(op: PrintWriter => Unit)
val writer = new PrintWriter(file)
try
op(writer)
finally
writer.close()
然后,我们再看一下对改造后的withPrintWriter函数的调用方法
val file = new File("date.txt")
withPrintWriter(file)
writer => writer.println(new java.util.Date)
比较一下自定义的控制结构和Scala提供的for和while循环,使用风格已经很类似了。
五、By-name参数
再仔细看一下上面的改造后的withPrintWriter函数,在花括号中需要传入一个PrintWriter类型的writer变量,而在whie和for等Scala控制结构的函数体中是不需要参数传递的。这个可以使用by-name参数来解决。
接下来自定义一个myAssert函数,该函数接收一个函数参数,这个函数参数没有输入参数,直接用一个()来表示。然后根据一个Boolean类型的变量来确定是否执行该函数参数。
1、不使用by-name参数
在这种情况下,函数定义如下
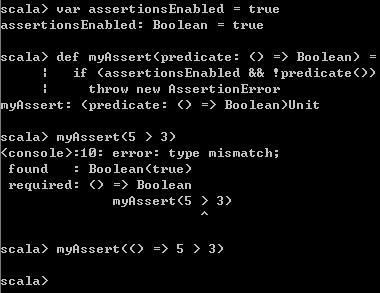
var assertionsEnabled = true
def myAssert(predicate: () => Boolean) =
if (assertionsEnabled && !predicate())
throw new AssertionError光从定义上看,上面这个函数定义好像也没什么。但是在使用时,
myAssert(5 > 3)
myAssert(() => 5 > 3) 从执行结果来看,第二种写法才是正确的。
这个myAssert函数定义后调用的话会显得很麻烦,代码臃肿。
2、使用by-name参数的情况
接下来以by-name参数的形式重新定义一个byNameAssert函数,by-name参数的情况的函数参数不再以()=>开头,而是以=>开头,如下
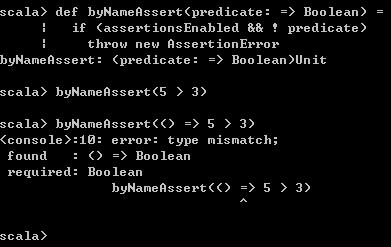
def byNameAssert(predicate: => Boolean) =
if (assertionsEnabled && ! predicate)
throw new AssertionError此时再看一下该函数的调用
byNameAssert(5 > 3) 执行结果如下
3、boolean类型参数函数
如果将=>也省略掉,直接指定boolAssert函数接收一个Boolean类型的参数,从函数的调用形式来看,和前面的byNameAssert函数相同,如下所示
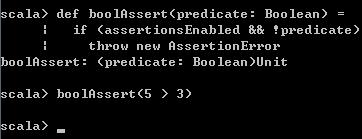
def boolAssert(predicate: Boolean) =
if (assertionsEnabled && !predicate)
throw new AssertionError
boolAssert(5 > 3) 执行结果如下:
4、三个函数的比较
将上面的三个方法myAssert,byNameAssert,boolAssert以及方法的调用写入同一个ByName.scala文件中,该scala文件完整内容如下:
object ByName
var assertionsEnabled = true
def main(args: Array[String])
myAssert(() => 5 > 3)
byNameAssert(5 > 3)
boolAssert(5 > 3)
def myAssert(predicate: () => Boolean) =
if (assertionsEnabled && !predicate())
throw new AssertionError
def byNameAssert(predicate: => Boolean) =
if (assertionsEnabled && ! predicate)
throw new AssertionError
def boolAssert(predicate: Boolean) =
if (assertionsEnabled && !predicate)
throw new AssertionError
对ByName.scala进行编译,查看编译后的结果。
首先看一下三个函数的定义,其中myAssert和byNameAssert都是接收一个Function0类型的对象,而boolAssert接收一个boolean类型的参数。

再看一下函数调用,myAssert和byNameAssert方法都是传入上面的Function0类型的对象,该对象的apply方法计算出5 > 3的结果为true并返回。而boolAssert方法,在方法调用之前就已经计算出了5 > 3的值为true,然后直接将该true传入boolAssert方法。

总结一下,myAssert和byNameAssert方法在编译后的代码中不管是方法定义,还是方法调用,都是相同的,所以byNameAssert的确是myAssert的简化形式。这两种形式的方法,接收的都是一个函数参数,该函数参数的函数值会编译成一个Function0类型对象,并且方法调用时该对象的apply方法才会去计算5 > 3的结果。
而boolAssert方法,编译后的接收参数只是一个boolean类型的变量,并且方法调用时,首先将5 > 3进行解析,然后将解析后的结果传入boolAssert方法。
以上是关于控制抽象的主要内容,如果未能解决你的问题,请参考以下文章