监控平台设计 之 GraphitePrometheus 竞对
Posted 魏小言
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了监控平台设计 之 GraphitePrometheus 竞对相关的知识,希望对你有一定的参考价值。
目录
“ 监控平台在各个团队部门都很普及,什么是监控,我们做监控的诉求到底是什么?”

设计监控系统常见的问题
我们来思考,什么是监控?监控的对象是什么?
监控不应仅仅是对数据的收集展示,需要提供 OLAP 支持「行数据分析、挖掘及建模拆分/上下钻/排序/特定逻辑…」等处理,完成监控的智能化「观察动态数据趋势辅助业务做相关决策、定位问题、场景快照及复原…」,从而满足监控诉求,这样才是一个成熟的监控。
而监控对象,就社会面来讲,是人、物、行为「归根结底是数据…」。那么针对业务平台监控,数据可以是在线数据流、日志、数据库元数据…等。
简单阐述监控基要后,我们就目前行业中搭建监控系统(APM)提出常见的一些问题,深入探究:
-
数据如何采集?
推或拉的方式?更或其他...
-
监控系统架构是否可扩展伸缩?高可用?吞吐量如何?
需具备降级、调控、容灾等策略...
-
原始/加工/半加工数据如何存储?
涉及存储产品选型,时序数据库、关系型/非关系型数据库、缓存...
-
数据对象关系如何扩展?
数据模式化的选取,数据间关联结构的设计...
-
…
1.1 不同技术选型
监控技术成熟轮子很多,重复造意义不大。成熟的监控组合:ES+Kibana+Logstash、Graphite+Collectd、Grafana+Influxdb...等。这里主要点一下存储类型。
监控类一般是时序数据库,按照底层技术不同可以划分为三类:
-
直接基于文件的简单存储:RRD Tool,Graphite Whisper。这类工具附属于监控告警工具,底层没有一个正规的数据库引擎。只是简单的有一个二进制的文件结构。
-
基于K/V数据库构建:opentsdb(基于hbase),blueflood,kairosDB(基于cassandra),influxdb,prometheus(基于leveldb)。
-
基于关系型数据库构建:mysql,postgresql 都可以用来保存时间序列数据。
偏业务监控选型一般为第三类,偏数据监控一般使用前两类。
Graphite & Prometheus 架构
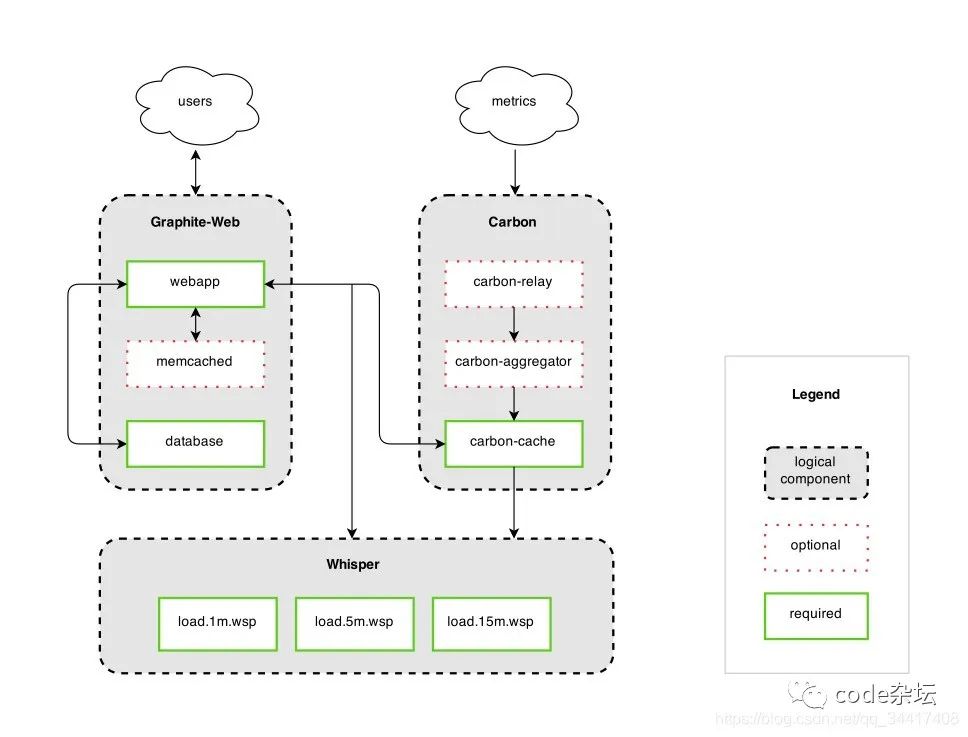
Graphite 原生无监控指标收集模块,数据存储为 Whisper,含Web-ui。架构图如下:
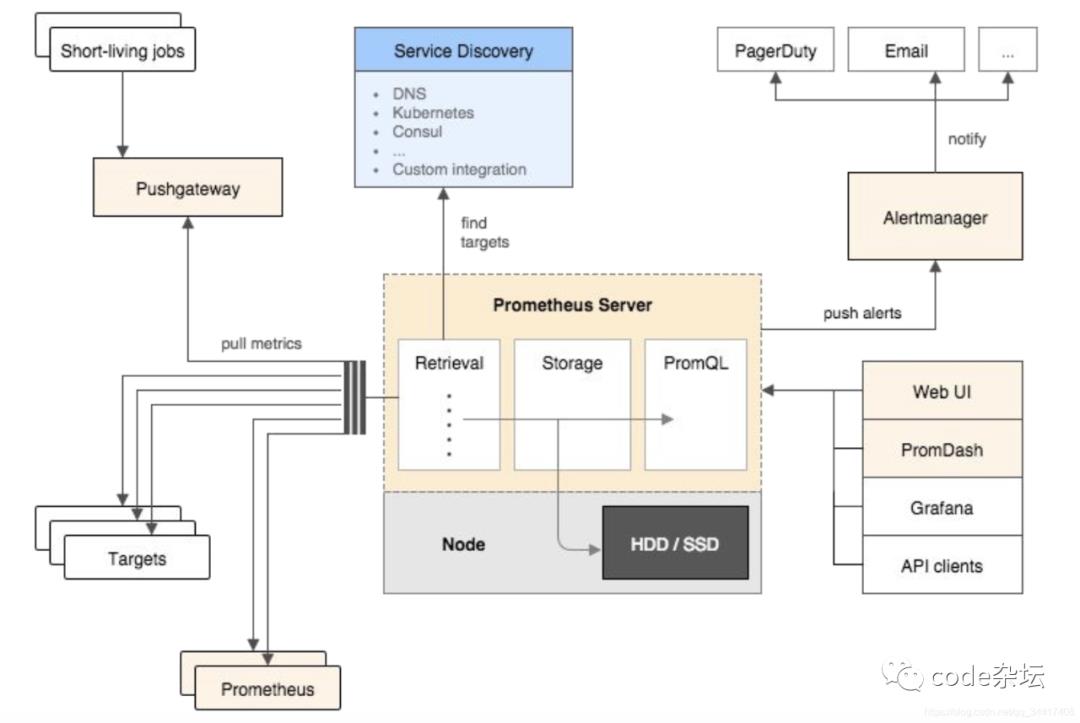
Prometheus 原生含收集、存储、Web-iu、AlterManage、Explore 。架构图如下:
2.1 Metric
Graphite:metric 名称以点 "." 分割指标,这种方式是一种维度的编码方式,通过 "." 来潜在的提供分割数据标识。
Prometheus:在提供 metric 名称之外,明确的通过标签键值对标识metric 不同的维度,更易于通过查询语句来过滤、分组、匹配 metrics。
举个例子:
使用Graphite/StatsD存储状态码为500、方法是POST、路径是 ”/tracks"、服务名称为api-server(api-server有多个实例)的http请求数,这样一个监控指标:
stats.api-server.tracks.post.500 -> 93使用 Prometheus 存储同样的监控指标:
api_server_http_requests_totalmethod="POST",handler="/tracks",status="500",instance="<sample1>" -> 34api_server_http_requests_totalmethod="POST",handler="/tracks",status="500",instance="<sample2>" -> 28api_server_http_requests_totalmethod="POST",handler="/tracks",status="500",instance="<sample3>" -> 31
2.2 Metric 存储规则
-
Graphite
常用 Whisper 数据库[python],是一款类 RRD(round-robin-database)[C]型数据库。特点是,把高精度的指标数据转换成低精度的指标数据以满足存储长期的历史数据的需求。比如说把按秒采集的指标转换成按分钟采集的指标,以减少数据量,进行长期存储。
-
RRD
数据库在存储的时候在存储的时候,按照 “循环” round-robin 的方式进行存储,也就是说,自己定义一个周期。在过了一个周期之后,后面的数据将覆盖前面的数据。
-
Whisper
数据点(监控指标)
一般是双精度类型,且包含时间戳、业务指标。
数据存储规则如下:[case_name]
Pattern = ^fe_idx.*retention = 15s:7d,1m:21d,15m:5y模版[name]#存储标识pattern = regex#用来匹配具体指标名的正则表达式。如果配置文件里面定义了多个策略,那么收到一个指标数据的时候,会从上到下使用每个策略里面的pattern对指标名称进行正则表达式匹配,最先匹配到的策略将会被使用。retentions = timePerPoint:timeToStore, timePerPoint:timeToStore, …#定义了数据采集精度和存储时长。timePerPoint就是多长时间采集一个数据点,timeToStore就是采集的数据最长存储多长时间。每个retentions后面可以定义多个timePerPoint:timeToStore对。每个timePerPoint:timeToStore对按高精度短时长到低精度长时长进行排序。上面的retentions包含了三个timePerPoint:timeToStore对,分别是15秒采集一个数据点,保存7天的数据,1分钟采集一个数据点,保存21天的数据和15分钟采集一个数据点,保存5年的数据。
指标精度转换规则如下:
[case_name]Pattern = ^fe_idx.*xFilesFactor = 0.2aggregationMethod = average模版[name]#规则标识pattern = <regex>#用来匹配具体指标名的正则表达式。如果配置文件里面定义了多个聚合规则,那么收到一个指标数据的时候,会从上到下使用每个规则里面的pattern对指标名称进行正则表达式匹配,最先匹配到的规则将会被使用。aggregationMethod = <average|sum|last|max|min>#数据聚合方法xFilesFactor = <float between 0 and 1>#必须是一个0到1之间的浮点型数值。这个值规定了要把高精度的数据转换成一个低精度的数据,高精度的数据必须有几个。以15s:7d,1m:21d这个定义为例子,高精度的定义是15秒采集一个数据,而低精度的定义是1分钟采集一个数据。那么在高低精度数据转换的时候,正常情况下就是把4个数据点转换成一个数据点。但是实际可能存在这样的情况,就是1分钟内的数据点没有4个,只有一个,两个,或者三个,就是有的时间点他没有采集到数据。那么xFilesFactor的意思就是在这种数据缺少的情况下,数据点数必须满足多少百分比,才能做数据聚合操作。如果定义成0.5,那么就是说,至少要有2个点才能做数据聚合操作,如果定义成0.1,那就是说只要有1个点就可以做数据聚合操作。这个值定义成多少,还跟具体的数据聚合策略有关系。如果数据聚合策略是sum(求和),这种策略下就算没有数据点,也是可以做求和操作的,那么xFilesFactor就可以定义成0。如果数据聚合策略是min(求最小值),这种策略下,没有数据点肯定就没法取最小值,那么xFilesFactor就可以定义成0.1,就是说至少要有一个数据点,才能做聚合操作,等等。
-
行为及空间效率
数据库文件生成时,就把所有的数据点都创建出来了。比如说 1m:1d 这个定义,在收到第一个数据点的时候,这个数据库文件就被创建了,数据库文件里面总共 1440 个数据点。不管这些数据点有没有收集到值,数据点都会提前创建好,如果没有值,就是 None。
以 retentions = 15s:7d,1m:21d,15m:5y这个多精度定义为例子,当数据写入这个数据库时,数据会被同时写多份。数据会首先被写入到最高精度的数据点中,然后当满足数据聚合条件后,再把多个高精度的数据聚合,写到低精度的数据点中。
-
Prometheus
Prometheus存储是KV存储,使用的是 LevelDb 的引擎。特点是顺序读写性能非常高,与其存储机制有关。
-
K-V
Prometheus的监控指标格式是:
metric_namelable_name:label_val,…… timestamp sample整体可划分为:
Key:metric_namelable_name:label_val,…… timestamp;value:ample「注:所有的数值都是64bit的。每条时间序列里面记录的其实就是64bit timestamp(时间戳) + 64bit value(采样值)」
其哈希值计算为:
FNV(sort(metric_name,lable_name:label_val……))FNV哈希算法全名为Fowler-Noll-Vo算法,是以三位发明人Glenn Fowler,Landon Curt Noll,Phong Vo的名字来命名的,最早在1991年提出。
FNV能快速hash大量数据并保持较小的冲突率,它的高度分散使它适用于hash一些非常相近的字符串,比如URL,hostname,文件名,text,IP地址等。
2.3 LevelDb 存储结构
Prometheus 存储结构是基于 levelDb 模式,而 levelDb 是生于 LSM 思想......由于篇幅问题,详细请关注后文。
推荐阅读:
|五分钟搭建基于Prometheus+Grafana实时监控...
以上是关于监控平台设计 之 GraphitePrometheus 竞对的主要内容,如果未能解决你的问题,请参考以下文章