体验第一个spark程序(第四弹)
Posted 发量不足
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了体验第一个spark程序(第四弹)相关的知识,希望对你有一定的参考价值。
感谢您打开这篇文章👍👍
目录

体验第一个spark程序
一.先进入spark目录,然后执行如下命令:
$ bin/spark-submit \\
--class org.apache.spark.examples.SparkPi \\
--master spark://master:7077 \\
--executor-memory 1G \\
--total-executor-cores 1 \\
examples/jars/spark-examples_2.11-2.3.2.jar \\
10(1)--master spark://master:7077:指定master地址是master节点
(2)--executor-memory 1G:指定每个executor可用内存为1GB
(3)--total-executor-cores 1:指定每个executor使用CPU核心数为1个
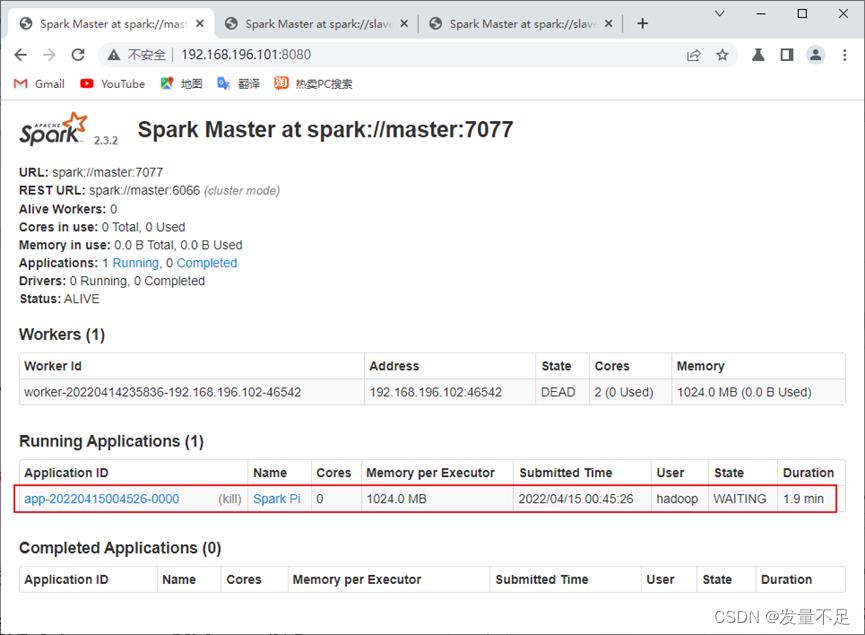
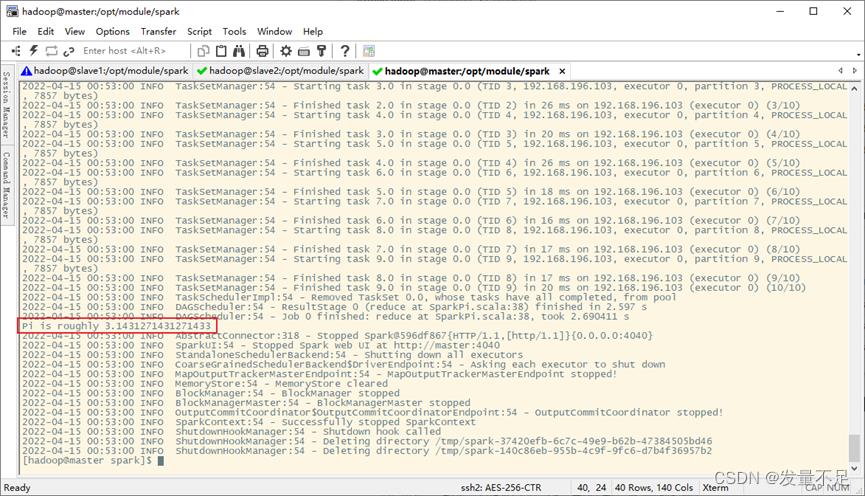
二.查看master地址页面应用执行完毕和Pi值被计算完毕
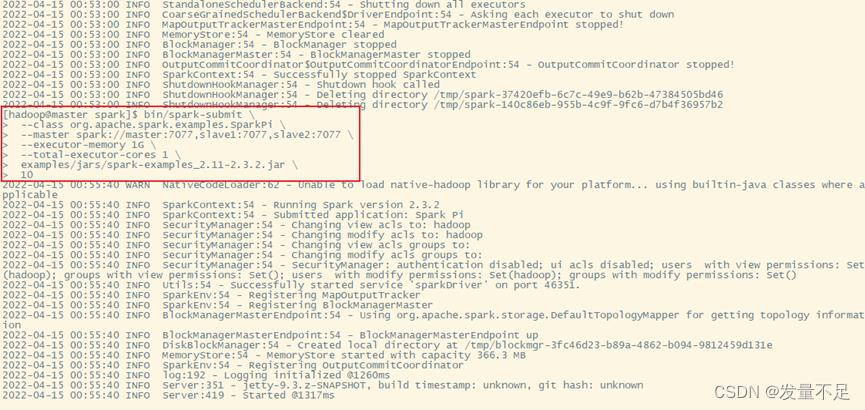
$bin/spark-submit \\
--class org.apache.spark.examples.SparkPi \\
--master spark://master:7077,slave1:7077,slave2:7077 \\
--executor-memory 1G \\
--total-executor-cores 1 \\
examples/jars/spark-examples_2.11-2.3.2.jar \\
10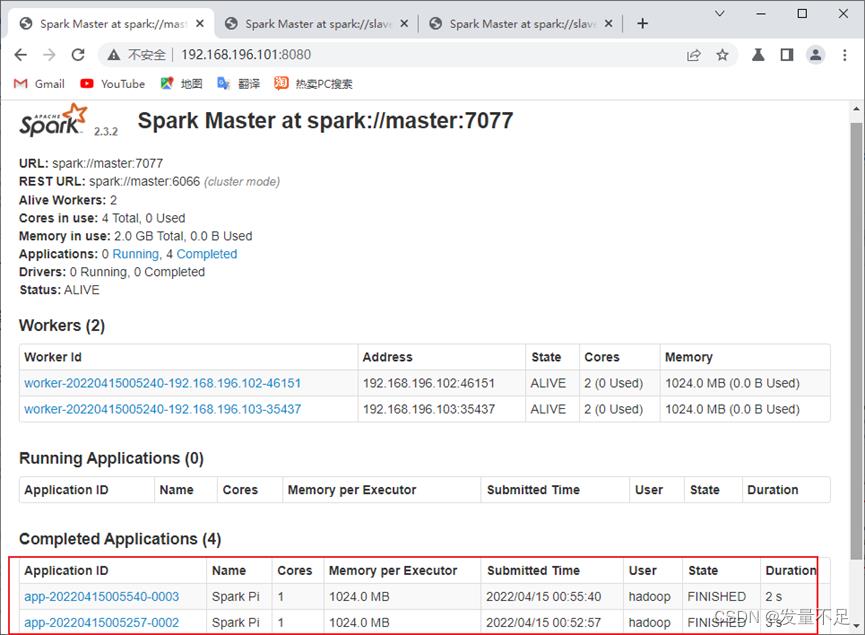
启动spark-shell
一.运行spark-shell命令
1.进入spark-shell交互式环境命令
$ bin/spark-shell --master <master-url>
--master : 当前连接的master节点
二.运行spark-shell 读取hdfs文件
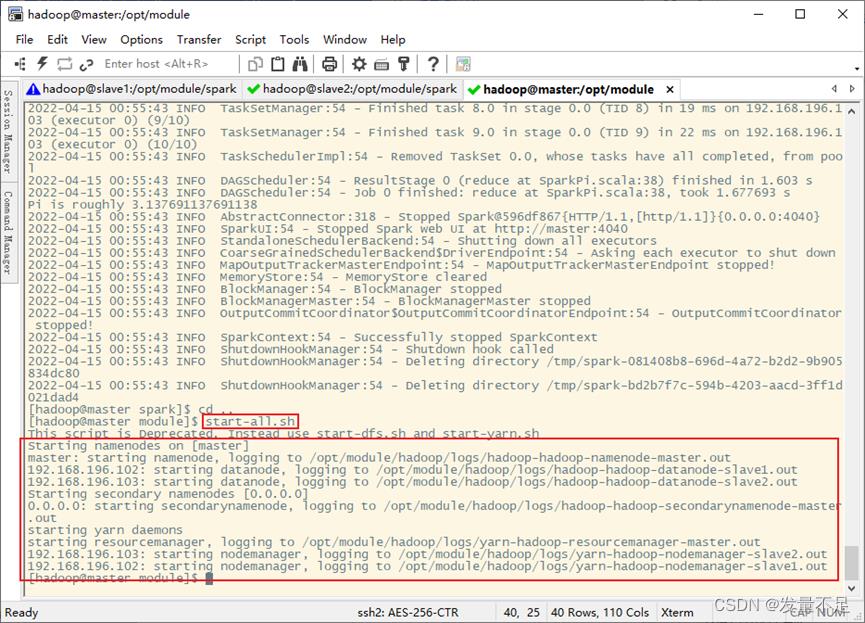
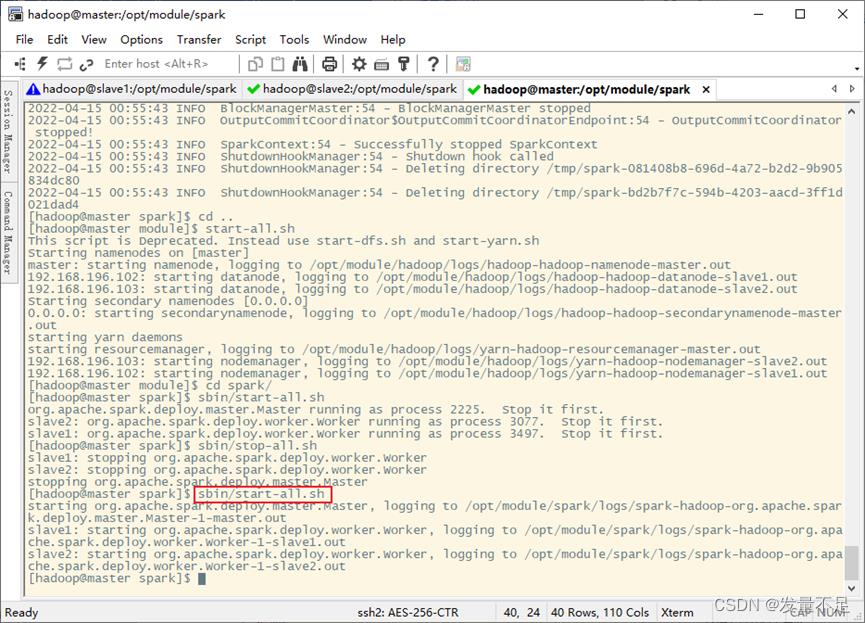
1.先启动spark集群或者启动hdfs集群,如果之前有开启,则需要重新关闭再开启spark集群或者启动hdfs集群
$ start-dfs.sh\\start-all.sh
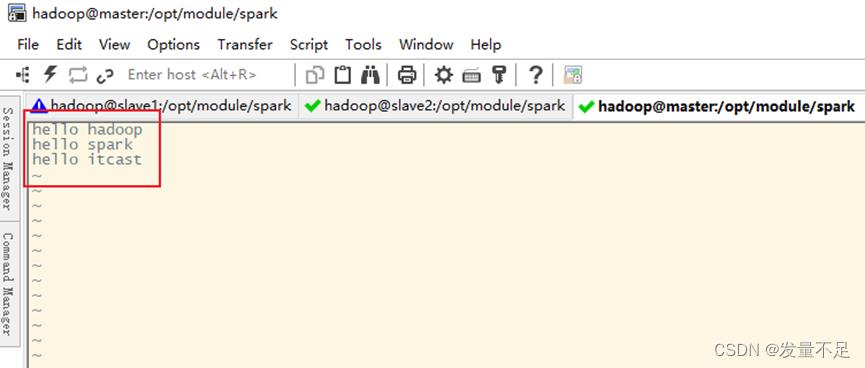
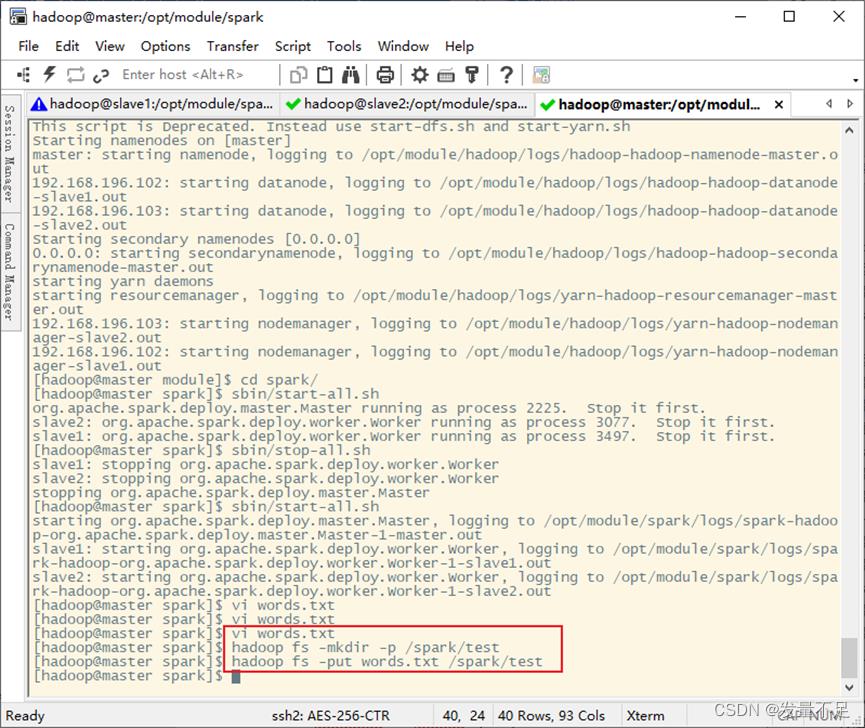
2.建一个文件words.txt,写入内容,然后创建2个目录,最后上传/spark/text/路径
$ vi words.txt
$ hadoop fs -mkdir -p /spark/test
$ hadoop fs -put words.txt /spark/test
遇到不能创建问题是因为分布式文件系统处于安全模式的情况
解决命令:
手动离开安全模式
$ Hadoop dfsadmin -safemode leave

三.整合spark和hdfs
1.修改spark-env.sh配置文件,添加HADOOP_CONF_DIR配置参数
$ vi spark-env.sh
export HADOOP_CONF_DIR=/opt/module/hadoop/etc/hadoop

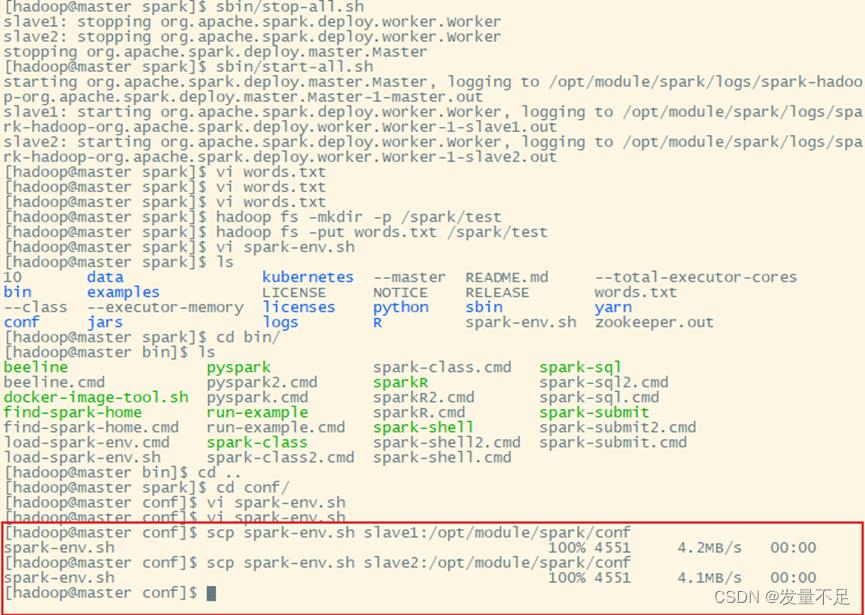
2.因为只在master上修改,但它是spark集群,所以得分发到slave1和slave2
$ scp spark-env.sh slave1:/opt/module/spark/conf
$ scp spark-env.sh slave2:/opt/module/spark/conf
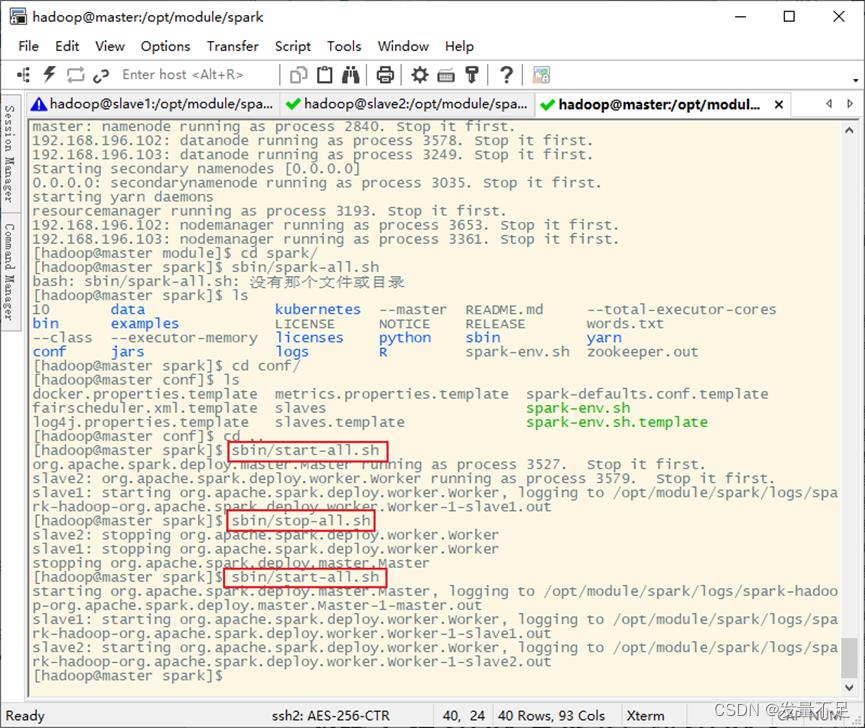
四.启动Hadoop、spark服务
1.启动Hadoop服务(未停止的,先停止在启动)
$ start-all.sh
2.在spark目录下启动spark服务(未停止的,先停止在启动)
$ sbin/start-all.sh
$ jps # 查看

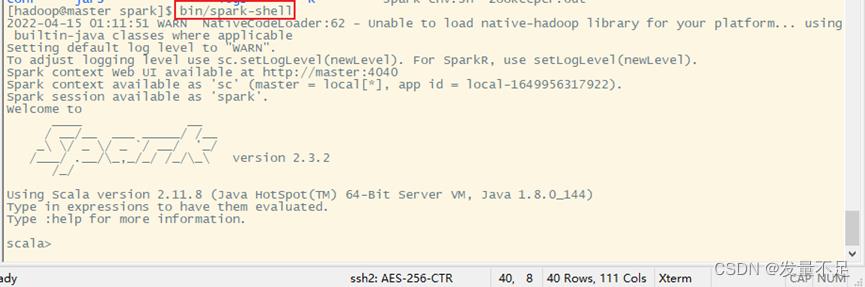
五.启动spark-shell编写程序
1.启动spark-shell交互命令
$ bin/spark-shell
2.编写Scala代码实现单词计数
sc.textFile(”/spark/test/words.txt”).flatMap(_.split(” ”)).map((_,1)).reduceByKey(_+_).collect

以上是关于体验第一个spark程序(第四弹)的主要内容,如果未能解决你的问题,请参考以下文章