ERMiner: Sequential Rule Mining Using Equivalence Classes
Posted Casey321
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ERMiner: Sequential Rule Mining Using Equivalence Classes相关的知识,希望对你有一定的参考价值。
目录
Abstract
序列规则挖掘是一项具有广泛应用前景的重要数据挖掘任务。针对该任务的当前最先进的算法(RuleGrowth)依赖于一种模式增长方法来发现序列规则。这种方法的一个缺点是,它重复执行昂贵的数据库投影操作,这降低了包含密集或长序列的数据集的性能。该文通过提出了一种名为ERMiner(基于等价类的序列规则)的挖掘序列规则的算法来解决这个问题。它依赖于使用具有相同前提或结果的规则的等价类进行搜索的新思想。此外,它还包括一个名为SCM(稀疏计数矩阵)的数据结构来修剪搜索空间。一项包含5个真实数据集的实验研究表明,ERMiner的速度比规则增长快5倍,但会消耗更多的内存。
Introduction
目前已经提出了两种主要类型的序列规则。第一种类型是规则,其中先行模式和后续模式都是序列模式。第二种类型是两组无序项]间的规则。该文中考虑了第二种类型,因为它更普遍并在某些领域的序列预测提供了相当高的预测精度。
目前已经提出了几种算法来挖掘这类序列规则。CMDeo是一种基于先验的算法,它使用宽度优先搜索来探索规则的搜索空间。CMDeo的一个主要缺点是它可以产生大量的候选对象。作为替代方案,提出了CMRules算法。它依赖于任何顺序规则也必须是一个关联规则来修剪顺序规则[6]的搜索空间的属性。对于稀疏数据集,它比CMDeo要快得多。最近,人们提出了规则增长算法。它依赖于一种模式增长的方法来避免候选生成。它被证明比CMDeo和CMRules快一个数量级以上。然而,对于包含密集或长序列的数据集,规则增长的性能会迅速提高,因为它必须重复执行昂贵的数据库投影操作。因为挖掘顺序规则仍然是一项计算成本非常昂贵的数据挖掘任务,一个重要的研究问题是:“我们能设计出更快的算法吗?”。
该文通过提出基于ERMiner(等价类的序列规则挖掘器)算法来解决这个问题。它依赖于数据库的垂直表示来避免执行数据库投影,以及使用具有相同先行词或结果的规则的等价类来探索规则的搜索空间的新想法。此外,它还包括一个名为SCM(稀疏计数矩阵)的数据结构来修剪搜索空间。
Problem Definition

序列规则

项集/规则出现

序列规则大小
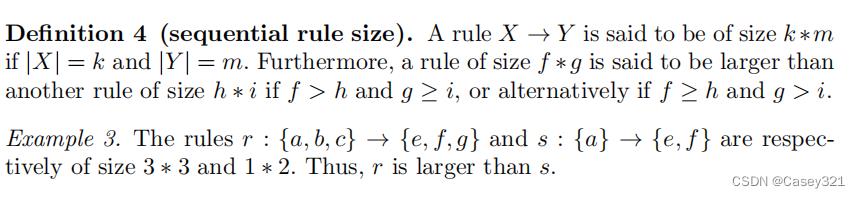
支持度、置信度

序列规则挖掘

The ERMiner Algorithm
ERMiner算法依赖于序列规则的等价类的新概念。
规则等价类

左/右合并

性质

为了使用上述合并操作探索频繁序列规则的搜索空间,ERMiner首先扫描数据库,为大小为1∗1的频繁规则构建所有等价类。然后,它递归地从这些等价类开始执行左右合并,以生成其他等价类。为了确保不会生成两次规则,该文使用了以下方法。




使用上述解决方案,很容易看到所有规则只生成一次。然而,为了更高效,序列规则挖掘算法应该能够修剪搜索空间。这将使用合并操作的以下属性来完成此操作。
剪枝

由于不存在任何类似的可信度剪枝属性,因此有必要探索频繁规则的搜索空间来获得有效的规则。图1显示了ERMiner的主要伪代码,它集成了之前的所有思想。ERMiner将序列数据库SDB、minsup、minconf阈值作为输入。它首先扫描数据库一次,以构建大小为1、∗1的规则的所有等价类,即在前项中包含单个项,在后续项中包含单个项。然后,为了发现更大的规则,通过调用leftSearch过程,对所有左等价类执行左合并。类似地,通过调用rightSearch过程,对所有正确的等价类执行右合并。请注意,rightSearch过程可能会生成一些新的左等价类,因为在右合并后允许左合并。这些等价类存储在一个名为leftStore的结构中。为了处理这些等价类,需要执行一个额外的循环。最后,该算法返回所找到的规则集。
伪代码
ERMiner


leftSearch

rightSearch

Conclusion
该文提出了一种新的序列规则挖掘算法ERMiner(基于等价类的序列规则挖掘)。它依赖于使用具有相同先行词或后续词的规则的等价类进行搜索的新思想。此外,它还包含了一个名为SCM(稀疏计数矩阵)的数据结构来修剪搜索空间。一项针对5个真实数据集的广泛实验研究表明,ERMiner的速度比最先进的算法快5倍,但包含更多的内存。当速度比内存更重要时,这是一个有趣的权衡。
Reading and Thinking
了解了序列规则挖掘分两类。文中采用了等价类合并的方法生成序列规则,与GSP算法中的连接过程类似,这个新想法值得学习。为了避免生成重复的序列规则,文章使用了两个优化方法。此外,文中还采用了稀疏矩阵来剪枝,大大提高了算法效率。
以上是关于ERMiner: Sequential Rule Mining Using Equivalence Classes的主要内容,如果未能解决你的问题,请参考以下文章