Hadoop技术之Apache Hadoop集群搭建
Posted 黑马程序员官方
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop技术之Apache Hadoop集群搭建相关的知识,希望对你有一定的参考价值。
Spark是大数据体系的明星产品,是一款高性能的分布式内存迭代计算框架,可以处理海量规模的数据。下面就带大家一起来开始学Spark!
▼往期内容汇总:
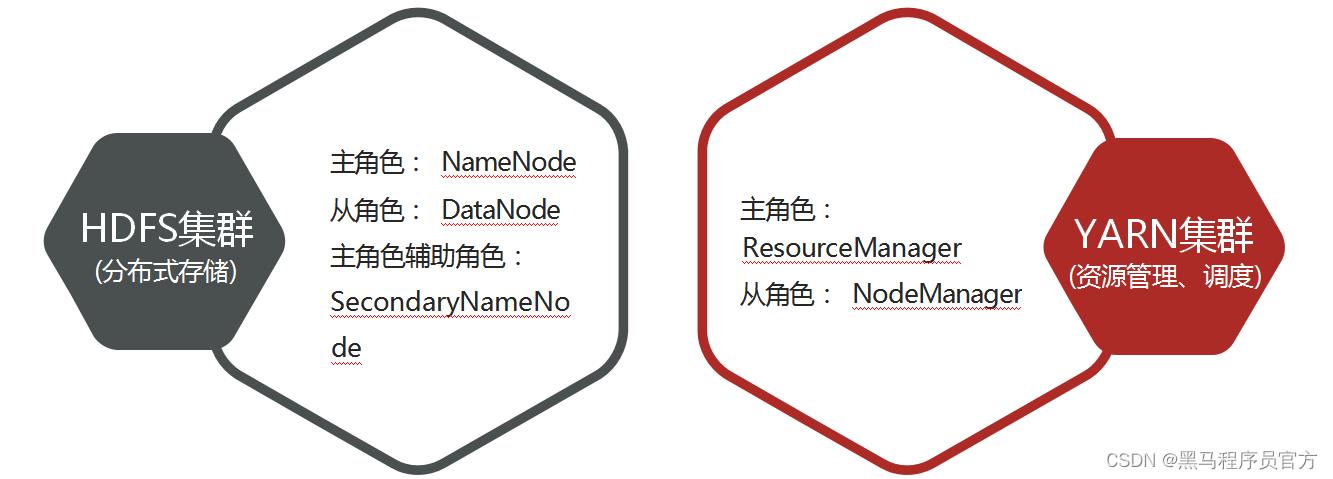
一、Hadoop集群简介
Hadoop集群整体概述
- Hadoop集群包括两个集群: HDFS集群、YARN集群
- 两个集群逻辑上分离、通常物理上在一起
- 两个集群都是标准的主从架构集群
Hadoop集群简介
Hadoop集群=HDFS集群+YARN集群
- 逻辑上分离
两个集群互相之间没有依赖、互不影响
- 物理上在一起
某些角色进程往往部署在同一台物理服务器上
- MapReduce集群呢?
MapReduce是计算框架、代码层面的组件 没有集群之说
二、Hadoop集群模式安装(Cluster mode)
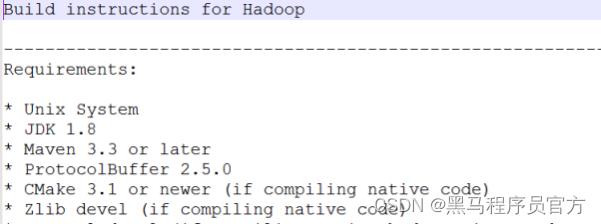
Hadoop源码编译
- 安装包、源码包下载地址
https://archive.apache.org/dist/hadoop/common/hadoop-3.3.0/
- 为什么要重新编译Hadoop源码?
匹配不同操作系统本地库环境, Hadoop某些操作比如压缩、 IO需要调用系统本地库(*.so|*.dll)
修改源码、重构源码。
- 如何编译Hadoop
源码包根目录下文件: BUILDING.txt 详细步骤参考附件资料
- 课程提供编译好的Hadoop安装包
hadoop-3.3.0-Centos7-64-with-snappy.tar.gz

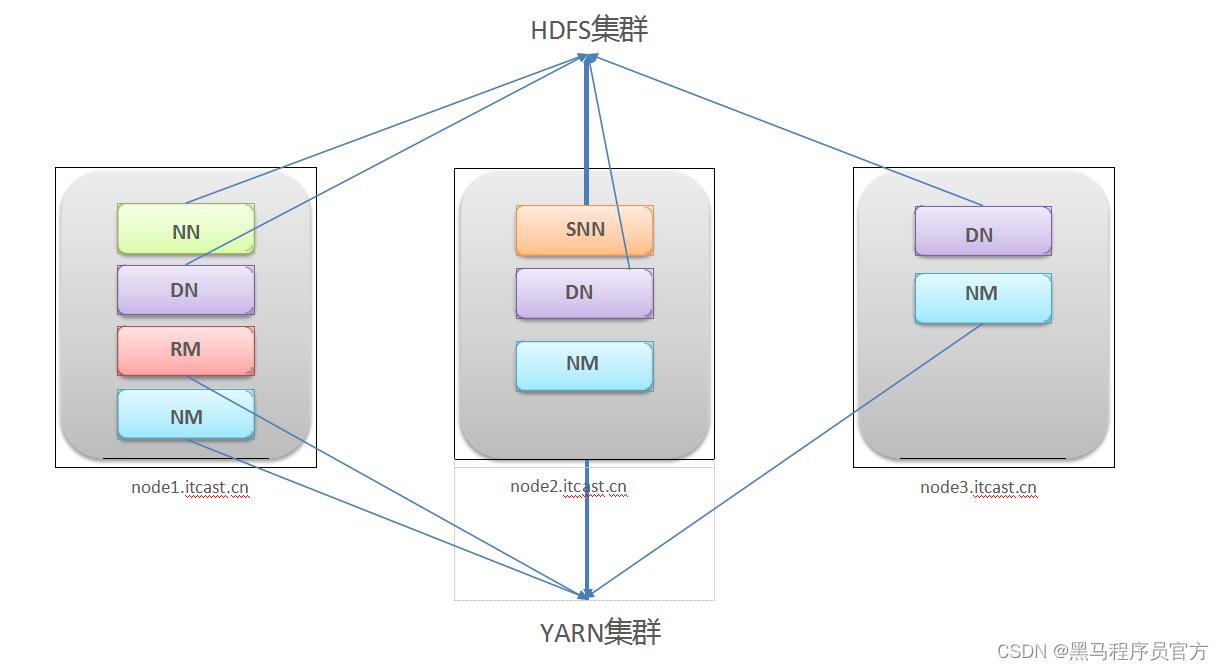
Step1:集群角色规划
- 角色规划的准则
根据软件工作特性和服务器硬件资源情况合理分配
比如依赖内存工作的NameNode是不是部署在大内存机器上?
- 角色规划注意事项
资源上有抢夺冲突的,尽量不要部署在一起
工作上需要互相配合的。尽量部署在一起
 Step2:服务器基础环境准备
Step2:服务器基础环境准备
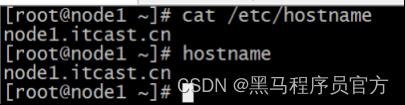
- 主机名(3台机器)
vim /etc/hostname
- Hosts映射(3台机器)
vim /etc/hosts

- 防火墙关闭(3台机器)
systemctl stop firewalld.service #关闭防火墙
systemctl disable firewalld.service #禁止防火墙开启自启
- ssh免密登录(node1执行- >node1|node2|node3)
ssh-keygen #4个回车 生成公钥、私钥
ssh-copy-id node1、ssh-copy-id node2、ssh-copy-id node3 #
- 集群时间同步(3台机器)
yum -y install ntpdate
ntpdate ntp4.aliyun.com

- 创建统一工作目录(3台机器)
mkdir -p /export/server/ #软件安装路径
mkdir -p /export/data/ #数据存储路径
mkdir -p /export/software/ #安装包存放路径

Step3:上传安装包、解压安装包
- JDK 1.8安装(3台机器)

- 上传、解压Hadoop安装包(node1)

Step4:Hadoop安装包目录结构

配置文件概述
官网文档: https://hadoop.apache.org/docs/r3.3.0/
第一类1个: hadoop-env.sh
第二类4个: xxxx-site.xml ,site表示的是用户定义的配置,会覆盖default中的默认配置。
core-site.xml 核心模块配置
hdfs-site.xml hdfs文件系统模块配置
mapred-site.xml MapReduce模块配置
yarn-site.xml yarn模块配置
第三类1个: workers
所有的配置文件目录: /export/server/hadoop-3.3.0/etc/hadoop
Step5:编辑Hadoop配置文件(1)
hadoop-env.sh

Step5:编辑Hadoop配置文件(2)
core-site.xml

Step5:编辑Hadoop配置文件(3)
hdfs-site.xml

Step5:编辑Hadoop配置文件(4)
mapred-site.xml

Step5:编辑Hadoop配置文件(5)
yarn-site.xml
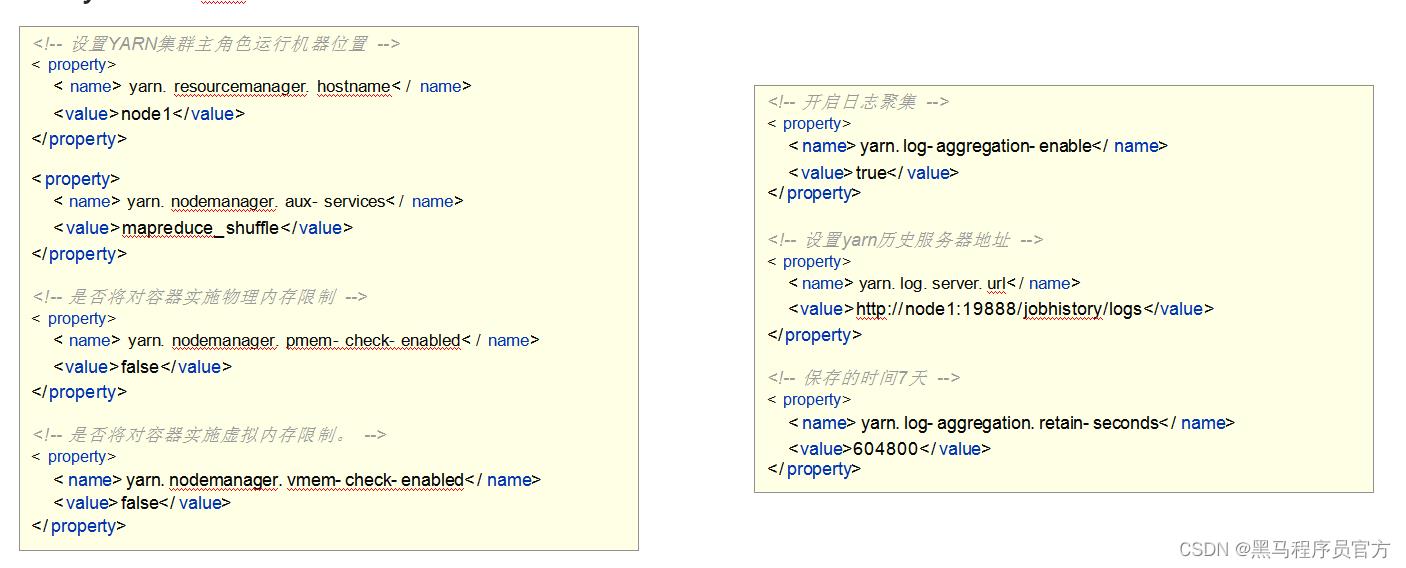
Step5:编辑Hadoop配置文件(6)
workers
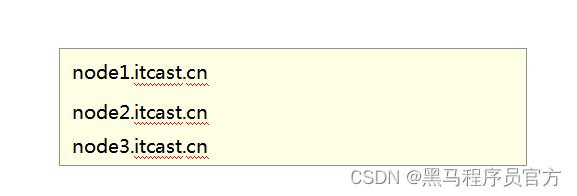
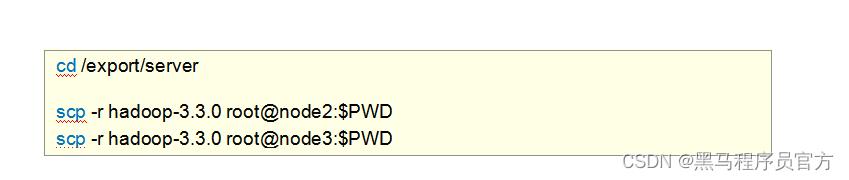
Step6:分发同步安装包
在node1机器上将Hadoop安装包scp同步到其他机器
Step7:配置Hadoop环境变量
- 在node1上配置Hadoop环境变量
vim /etc/profile
export HADOOP_HOME=/export/server/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 将修改后的环境变量同步其他机器
scp /etc/profile root@node2:/etc/
scp /etc/profile root@node3:/etc/
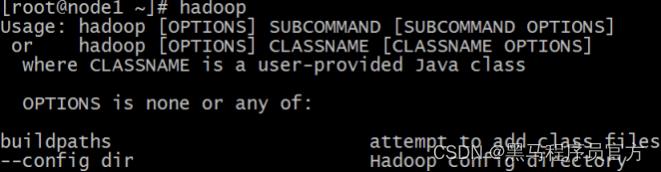
- 重新加载环境变量 验证是否生效(3台机器)
source /etc/profile
hadoop #验证环境变量是否生效
Step8:NameNode format (格式化操作)
首次启动HDFS时,必须对其进行格式化操作。
format本质上是初始化工作,进行HDFS清理和准备工作
命令:hdfs namenode -format


三、Hadoop集群启停命令、 Web UI
手动逐个进程启停
- 每台机器上每次手动启动关闭一个角色进程,可以精准控制每个进程启停,避免群起群停。
- HDFS集群

- YARN集群

shell脚本一键启停
在node1上,使用软件自带的shell脚本一键启动。前提: 配置好机器之间的SSH免密登录和workers文件。
- HDFS集群
start-dfs.sh
stop-dfs.sh
- YARN集群
start-yarn.sh
stop-yarn.sh
- Hadoop集群
start-all.sh
stop-all.sh
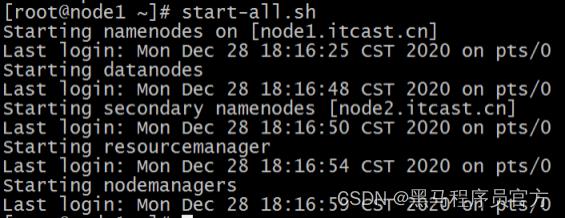
进程状态、日志查看
- 启动完毕之后可以使用jps命令查看进程是否启动成功

- Hadoop启动日志路径: /export/server/hadoop-3.3.0/logs/

HDFS集群
地址: http://namenode_host:9870
其中namenode_host是namenode运行所在机器的主机名或者ip
如果使用主机名访问,别忘了在Windows配置hosts
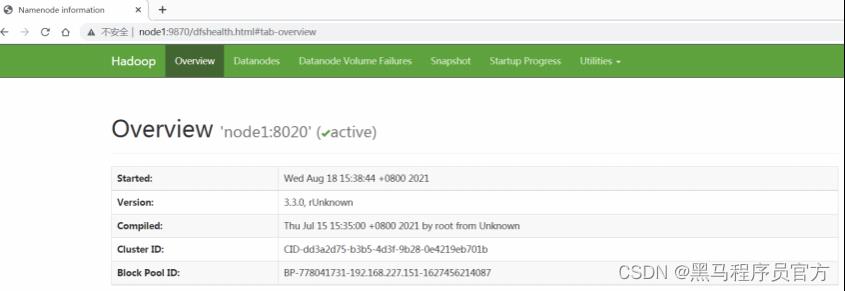
- HDFS文件系统Web页面浏览

YARN集群
地址: http://resourcemanager_host:8088
其中resourcemanager_host是resourcemanager运行所在机器的主机名或者ip
如果使用主机名访问,别忘了在Windows配置hosts

四、Hadoop初体验
HDFS 初体验
shell命令操作
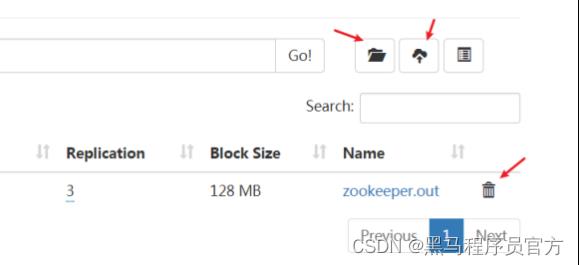
hadoop fs -mkdir /itcast
hadoop fs -put zookeeper.out /itcast
hadoop fs -ls /
Web UI页面操作

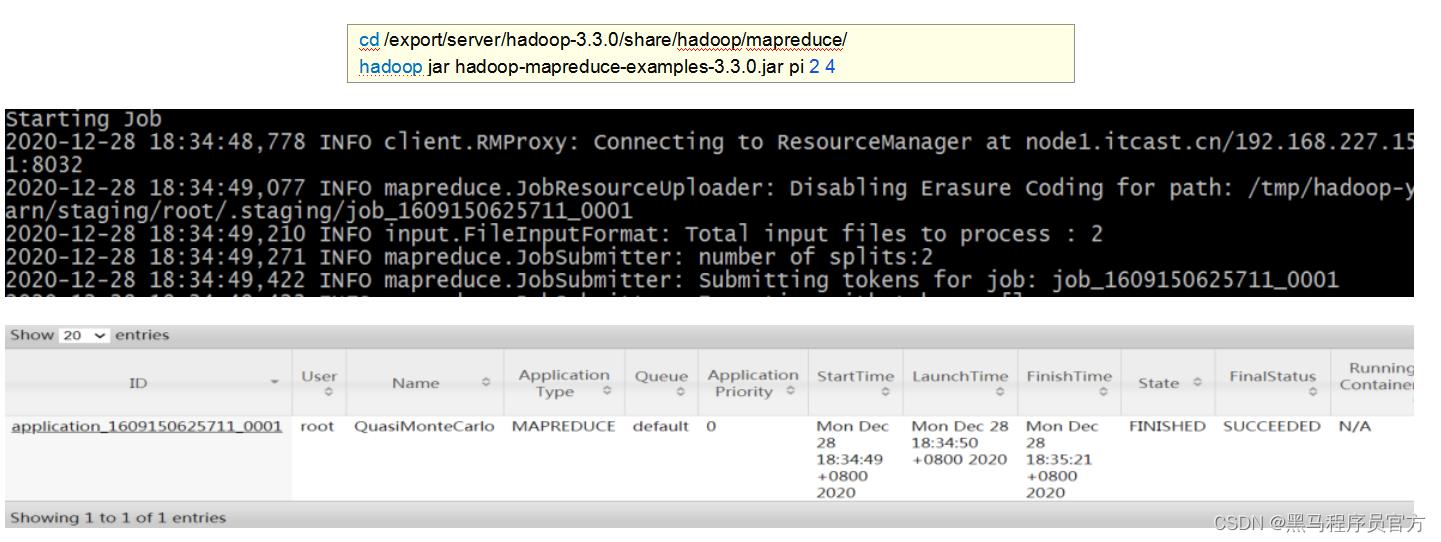
MapReduce+YARN 初体验
执行Hadoop官方自带的MapReduce案例, 评估圆周率π的值。
以上是关于Hadoop技术之Apache Hadoop集群搭建的主要内容,如果未能解决你的问题,请参考以下文章
hadoop + spark+ hive 集群搭建(apache版本)