阿里云 Serverless 异步任务处理系统在数据分析领域的应用
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里云 Serverless 异步任务处理系统在数据分析领域的应用相关的知识,希望对你有一定的参考价值。
异步任务处理系统中的数据分析
数据处理、机器学习训练、数据统计分析是最为常见的一类离线任务。这类任务往往都是经过了一系列的预处理后,由上游统一发送到任务平台进行批量训练及分析。在处理语言方面,Python 由于其所提供的丰富的数据处理库,成为了数据领域最为常用的语言之一。函数计算原生支持 Python runtime,并支持快捷的引入第三方库,使得使用函数计算异步任务进行处理变得极为方便。
数据分析场景常见诉求
数据分析场景往往具有执行时间长、并发量大的特点。在离线场景中,往往会定时触发一批大量的数据进行集中处理。由于这种触发特性,业务方往往会对资源利用率(成本)具有较高的要求,期望能够满足效率的同时,尽量降低成本。具体归纳如下:
- 程序开发便捷,对于第三方包及自定义依赖友好;
- 支持长时运行。能够查看执行过程中的任务状态,或登录机器进行操作。如果出现数据错误支持手动停止任务;
- 资源利用率高,成本最优。
以上诉求非常适合使用函数计算异步任务。
典型案例 - 数据库自治服务
业务基本情况
阿里云集团内部的数据库巡检平台主要用于对 sql 语句的慢查询、日志等进行优化分析。整个平台任务分为离线训练及在线分析两类主要任务,其中在线分析业务的的计算规模达到了上万核,离线业务的每日执行时长也在数万核小时。由于在线分析、离线训练时间上的不确定性,很难提高集群整体资源利用率,并且在业务高峰来时需要极大的弹性算力支持。使用函数计算后,整个业务的架构图如下:

业务痛点及架构演进
数据库巡检平台负责阿里巴巴全网各 Region 的数据库 SQL 优化及分析工作。mysql 数据来源于各 Region 的各个集群,并统一在 Region 维度进行一次预聚合及存储。在进行分析时,由于需要跨 region 的聚合及统计,巡检平台首先尝试在内网搭建大型 Flink 集群进行统计分析工作。但是在实际使用中,遇到了如下问题:
- 数据处理算法迭代繁琐。主要体现在算法的部署、测试及发布上。Flink 的 Runtime 能力极大限制了发布周期;
- 对于常见的及一些自定义的第三方库,Flink 支持不是很好。算法所依赖的一些机器学习、统计的库在 Flink 官方 Python runtime 中要么没有,要么版本老旧,使用不便,无法满足要求;
- 走 Flink 转发链路较长,Flink 排查问题困难;
- 峰值时弹性速度及资源均较难满足要求。并且整体成本非常高。
在了解了函数计算后,针对 Flink 计算部分进行了算法任务的迁移工作,将核心训练及统计算法迁移至函数计算。通过使用函数计算异步任务所提供的相关能力,整个开发、运维及成本得到了极大的提升。
迁移函数计算架构后的效果
- 迁移函数计算后,系统能够完整承接峰值流量,快速完成每日分析及训练任务;
- 函数计算丰富的 Runtime 能力支持了业务的快速迭代;
- 计算上相同的核数成本变为了原来 Flink 的 1/3。
函数计算异步任务非常适用于这类数据处理任务。函数计算在降低运算资源的成本同时,能够将您从繁杂的平台运维工作中解放出来,专注于算法开发及优化。
函数计算异步任务最佳实践-Kafka ETL
ETL 是数据处理中较为常见的任务。原始数据或存在于 Kafka 中,或存在于 DB 中,因为业务需要对数据进行处理后转储到其他存储介质(或存回原来的任务队列)。这类业务也属于明显的任务场景。如果您采用了云上的中间件服务(如云上的 Kafka),您就可以利用函数计算强大的触发器集成生态便捷的集成 Kafka,而无需关注诸如 Kafka Connector 的部署、错误处理等与业务无关的操作。
ETL 任务场景的需求
一个 ETL 任务往往包含 Source、Sink 及处理单元三个部分,因此 ETL 任务除了对算力的要求外,还需要任务系统具有极强的上下游连接生态。除此之外,由于数据处理的准确性要求,需要任务处理系统能够提供任务去重、Exactly Once 的操作语义。并且,对于处理失败的消息,需要能够进行补偿(如重试、死信队列)的能力。总结如下:
- 任务的准确执行:
- 任务重复触发支持去重;
- 任务支持补偿,死信队列;
- 任务的上下游:
- 能够方便的拉取数据,并在处理后将数据传递至其他系统;
- 算子能力的要求:
- 支持用户自定义算子的能力,能够灵活的执行各种数据处理任务。
Serverless Task 对 ETL 任务的支持
函数计算支持的 Destinationg 功能可以很好的支持 ETL 任务对于便捷连接上下游、任务准确执行的相关诉求。函数计算丰富的 Runtime 支持也使得对于数据处理的任务变得极为灵活。在 Kafka ETL 任务处理场景中,我们主要用到的 Serverless Task 能力如下:
- 异步目标配置功能:
- 通过配置任务成功目标,支持自动将任务投递至下游系统(如队列中);
- 通过配置任务失败目标,支持死信队列能力,将失败的任务投递至消息队列,等待后续的补偿处理;
- 灵活的算子及第三方库支持:
- Python 由于其丰富的统计、运算的第三方库的支持,在数据处理领域 Python 是用的最为广泛的语言之一。函数计算的 Python Runtime 支持对第三方库打包,使您能够快速的进行原型验证及测试上线。
Kafka ETL 任务处理示例
我们以简单的 ETL 任务处理为例,数据源来自 Kafka,经过函数计算处理后,将任务执行结果及上下游信息推送至消息服务 MNS。函数计算部分项目源码见:https://github.com/awesome-fc/Stateful-Async-Invocation
资源准备
Kafka 资源准备
- 进入 Kafka 控制台,点击购买实例,之后部署。等待实例部署完成;
- 进入创建好的实例中,创建一个测试用 Topic。
目标资源准备(MNS)
进入 MNS 控制台,分别创建两个队列:
- dead-letter-queue:作为死信队列使用。当消息处理失败后,执行的上下文信息将投递到这里;
- fc-etl-processed-message:作为任务成功执行后的推送目标。
创建完成后,如下图所示:

部署
- 下载安装 Serverless Devs:
npm install @serverless-devs/s
详细文档可以参考 Serverless Devs 安装文档
- 配置密钥信息:
s config add
详细文档可以参考 阿里云密钥配置文档
- 进入项目,修改 s.yaml 文件中的目标 ARN 为上述创建后的 MNS 队列 ARN,并修改服务角色为已存在的角色;
- 部署:
s deploy -t s.yaml
配置 ETL 任务
- 进入kafka 控制台 - connector 任务列表标签页,点击创建 Connector;
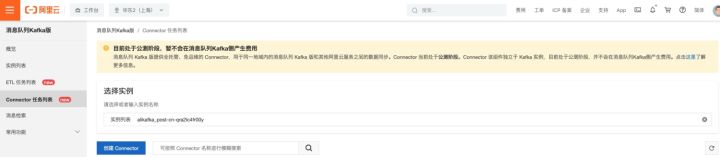
- 在配置完基本信息、源的 Topic 后,配置目标服务。在这里面我们选择函数计算作为目标
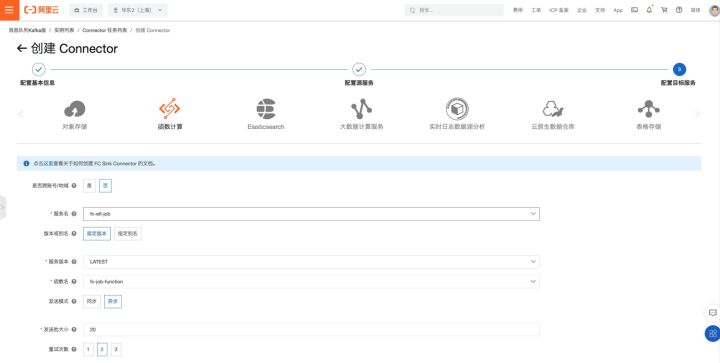
您可以根据业务需求配置发送批大小及重试次数。至此,我们已完成任务的基本配置。
注意:这里面的发送模式请选择“异步”模式。
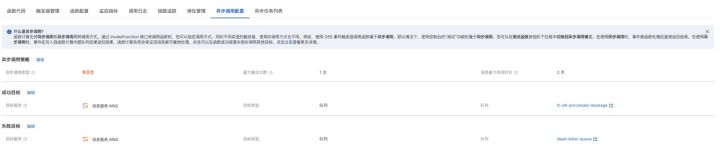
进入到函数计算异步配置页面,我们可以看到目前的配置如下:
测试 ETL 任务
- 进入kafka 控制台 - connector 任务列表标签页,点击测试;填完消息内容后,点击发送
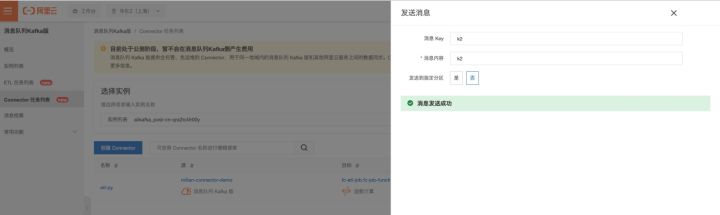
- 发送多条消息后,进入到函数控制台。我们可以看到有多条消息在执行中。此时我们选择使用停止任务的方式来模拟一次任务执行失败:

- 进入到消息服务 MNS 控制台中,我们可以看到两个先前创建的队列中均有一条可用消息,分别代表一次执行和失败的任务内容:

- 进入到队列详情中,我们可以看到两条消息内容。以成功的消息内容为例:
"timestamp":1646826806389,
"requestContext":
"requestId":"919889e7-60ff-408f-a0c7-627bbff88456",
"functionArn":"acs:fc:::services/fc-etl-job.LATEST/functions/fc-job-function",
"condition":"",
"approximateInvokeCount":1
,
"requestPayload":"[\\"key\\":\\"k1\\",\\"offset\\":1,\\"overflowFlag\\":false,\\"partition\\":5,\\"timestamp\\":1646826803356,\\"topic\\":\\"connector-demo\\",\\"value\\":\\"k1\\",\\"valueSize\\":4]",
"responseContext":
"statusCode":200,
"functionError":""
,
"responsePayload":"[\\n \\n \\"key\\": \\"k1\\",\\n \\"offset\\": 1,\\n \\"overflowFlag\\": false,\\n \\"partition\\": 5,\\n \\"timestamp\\": 1646826803356,\\n \\"topic\\": \\"connector-demo\\",\\n \\"value\\": \\"k1\\",\\n \\"valueSize\\": 4\\n \\n]"
在这里面,我们可以看到 "responsePayload" 这一个 Key 中有函数返回的原始内容。一般情况下我们会将数据处理的结果作为 response 返回,所以在后续的处理中,可以通过读取 "responsePayload" 来获取处理后的结果。
"requestPayload" 这一个 Key 中是 Kafka 触发函数计算的原始内容,通过读取这条数据中的内容,便可以获取原始数据。
函数计算异步任务最佳实践-音视频处理
随着计算机技术和网络的发展,视频点播技术因其良好的人机交互性和流媒体传输技术倍受教育、娱乐等行业的青睐。当前云计算平台厂商的产品线不断成熟完善,如果想要搭建视频点播类应用,直接上云会扫清硬件采购、技术等各种障碍。以阿里云为例,典型的解决方案如下:
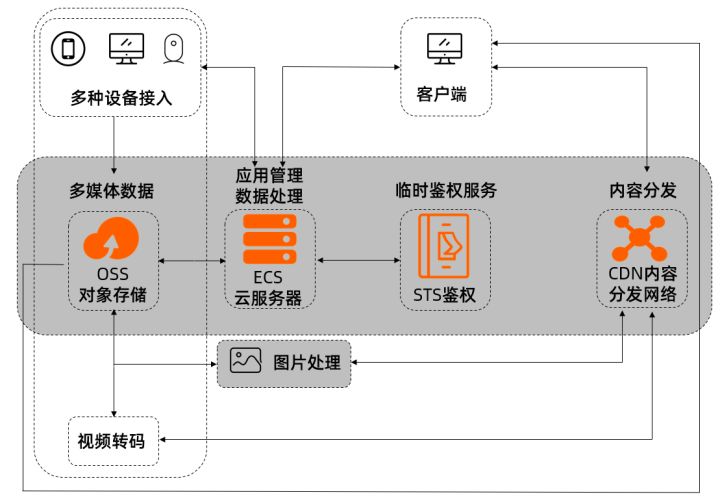
在该解决方案中,对象存储OSS可以支持海量视频存储,采集上传的视频被转码以适配各种终端、CDN加速终端设备播放视频的速度。此外还有一些内容安全审查需求,例如鉴黄、鉴恐等。
音视频是典型的长时处理场景,非常适合使用函数计算任务。
音视频处理的需求
在视频点播解决方案中,视频转码是最消耗计算力的一个子系统,虽然您可以使用云上专门的转码服务,但在某些场景下,您仍会选择自己搭建转码服务,例如:
- 需要更弹性的视频处理服务。例如,已经在虚拟机或容器平台上基于FFmpeg部署了一套视频处理服务,但想在此基础上提升资源利用率,实现具有明显波峰波谷、流量突增情况下的快弹及稳定性;
- 需要批量快速处理多个超大的视频。例如,每周五定时产生几百个4 GB以上1080P的大视频,每个任务可能执行时长达数小时;
- 对视频处理任务希望实时掌握进度;并在一些出现错误的情况下需要登录实例排查问题甚至停止执行中的任务避免资源消耗。
Serverless Task 对音视频场景的支持
上述诉求是典型的任务场景。而由于这类任务往往具有波峰波谷的特性,如何进行计算资源的运维,并尽可能的降低其成本,这部分的工作量甚至比实际视频处理业务的工作量还要大。Serverless Task 这一产品形态就是为了解决这类场景而诞生的,通过 Serverless Task,您可以快速构建高弹性、高可用、低成本免运维的视频处理平台。
在这个场景中,我们会用到的 Serverless Task 的主要能力如下:
- 免运维 & 低成本:计算资源随用随弹,不使用不付费;
- 长时执行任务负载友好:单个实例最长支持 24h 的执行时长;
- 任务去重:支持触发端的错误补偿。对于单一任务,Serverless Task 能够做到自动去重的能力,执行更可靠;
- 任务可观测:所有执行中、执行成功、执行失败的任务可追溯,可查询;支持任务的执行历史数据查询、任务日志查询;
- 任务可操作:您可以停止、重试任务;
- 敏捷开发 & 测试:官方支持 S 工具进行自动化一键部署;支持登录运行中函数实例的能力,您可以直接登录实例调试 ffmpeg 等第三方程序,所见即所得。
Serverless - FFmpeg 视频转码
项目源码:https://github.com/devsapp/start-ffmpeg/tree/master/transcode/src
部署
- 下载安装 Serverless Devs:
npm install @serverless-devs/s
详细文档可以参考 Serverless Devs 安装文档
- 配置密钥信息:
s config add
详细文档可以参考 阿里云密钥配置文档
- 初始化项目:
s init video-transcode -d video-transcode - 进入项目并部署:
cd video-transcode && s deploy
调用函数
- 发起 5 次异步任务函数调用
$ s VideoTranscoder invoke -e '"bucket":"my-bucket", "object":"480P.mp4", "output_dir":"a", "dst_format":"mov"' --invocation-type async --stateful-async-invocation-id my1-480P-mp4
VideoTranscoder/transcode async invoke success.
request id: bf7d7745-886b-42fc-af21-ba87d98e1b1c
$ s VideoTranscoder invoke -e '"bucket":"my-bucket", "object":"480P.mp4", "output_dir":"a", "dst_format":"mov"' --invocation-type async --stateful-async-invocation-id my2-480P-mp4
VideoTranscoder/transcode async invoke success.
request id: edb06071-ca26-4580-b0af-3959344cf5c3
$ s VideoTranscoder invoke -e '"bucket":"my-bucket", "object":"480P.mp4", "output_dir":"a", "dst_format":"flv"' --invocation-type async --stateful-async-invocation-id my3-480P-mp4
VideoTranscoder/transcode async invoke success.
request id: 41101e41-3c0a-497a-b63c-35d510aef6fb
$ s VideoTranscoder invoke -e '"bucket":"my-bucket", "object":"480P.mp4", "output_dir":"a", "dst_format":"avi"' --invocation-type async --stateful-async-invocation-id my4-480P-mp4
VideoTranscoder/transcode async invoke success.
request id: ff48cc04-c61b-4cd3-ae1b-1aaaa1f6c2b2
$ s VideoTranscoder invoke -e '"bucket":"my-bucket", "object":"480P.mp4", "output_dir":"a", "dst_format":"m3u8"' --invocation-type async --stateful-async-invocation-id my5-480P-mp4
VideoTranscoder/transcode async invoke success.
request id: d4b02745-420c-4c9e-bc05-75cbdd2d010f2、登录FC 控制台
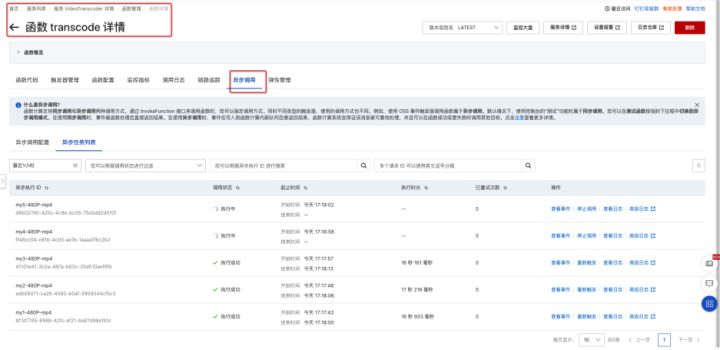
可以清晰看出每一次转码任务的执行情况:
-
- A 视频是什么时候开始转码的, 什么时候转码结束
- B 视频转码任务不太符合预期, 我中途可以点击停止调用
- 通过调用状态过滤和时间窗口过滤,我可以知道现在有多少个任务正在执行, 历史完成情况是怎么样的
- 可以追溯每次转码任务执行日志和触发payload
- 当您的转码函数有异常时候, 会触发 dest-fail 函数的执行,您在这个函数可以添加您自定义的逻辑, 比如报警
本文为阿里云原创内容,未经允许不得转载。
以上是关于阿里云 Serverless 异步任务处理系统在数据分析领域的应用的主要内容,如果未能解决你的问题,请参考以下文章
详解异步任务 | 看 Serverless Task 如何解决任务调度&可观测性中的问题
阿里云徐立:面向容器和 Serverless Computing 的存储创新