PyTorch笔记 - Attention Is All You Need
Posted SpikeKing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch笔记 - Attention Is All You Need相关的知识,希望对你有一定的参考价值。
CNN:
- 权重共享:平移不变形、可并行计算
- 滑动窗口:局部关联性建模、依赖多层堆积来进行长程建模
- 对相对位置敏感,对绝对位置不敏感
RNN:依次有序递归建模
- 对顺序敏感
- 串行计算耗时
- 长程建模能力弱
- 计算复杂度与序列长度呈线性关系
- 单步计算复杂度不变
- 对相对位置敏感,对绝对位置敏感
Transformer:
- 无局部假设:可并行计算、对相对位置不敏感
- 无有序假设:需要位置编码来反映位置变化对于特征的影响、对绝对位置不敏感
- 任意两字符都可以建模:擅长长短程建模,自注意机制需要序列长度的平台级别复杂度
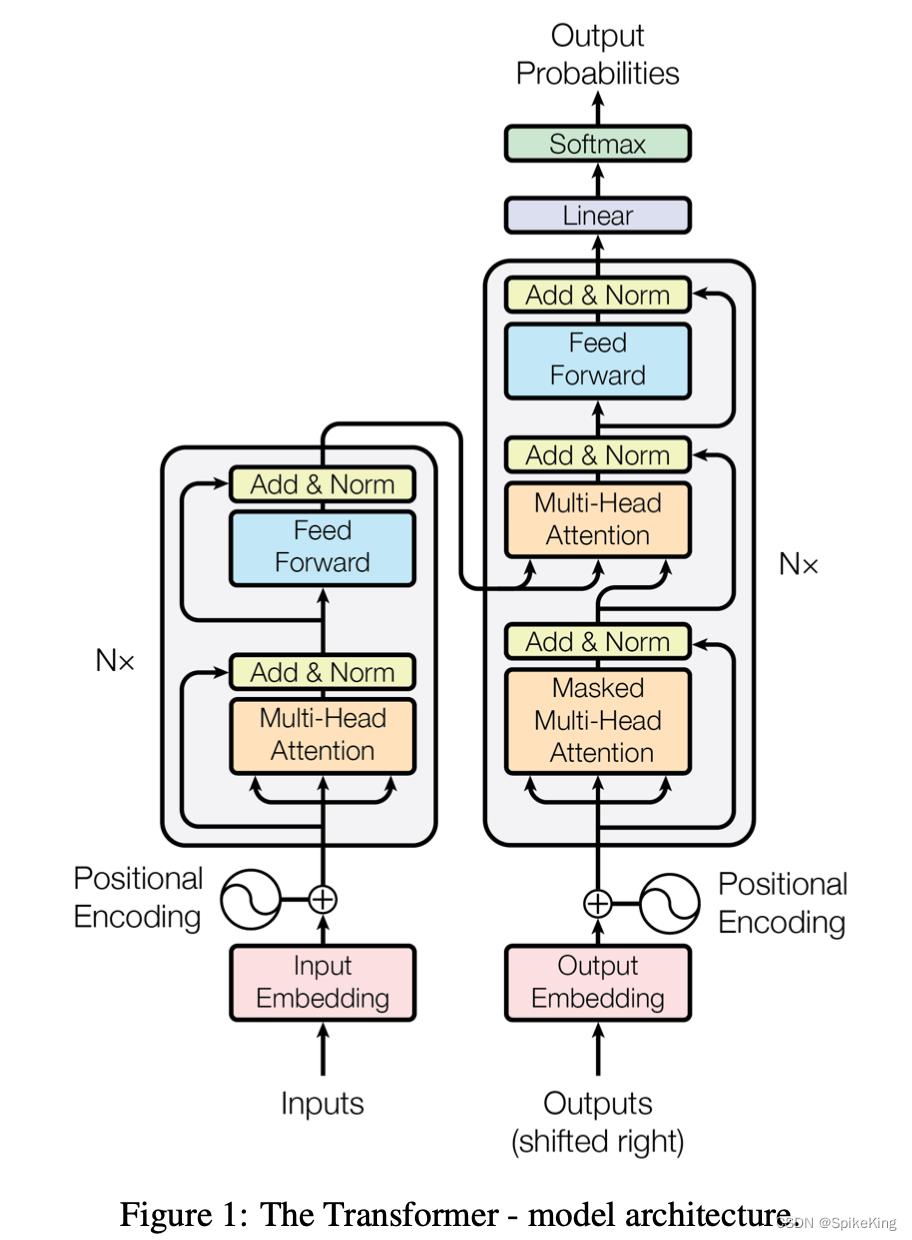
Encoder和Decoder模式
- Encoder:Input Embeding + Position Encoding,N层
- Multi-Head Attention
- Feed Forward
- Decoder:Output Embeding + Position Encoding
- Masked Multi-Head Attention -> Query
- Encoder -> Key/Value
- Multi-Head Attention
- Feed Forward
- Linear -> Softmax
位置信息逐层传递
Transformer:
- Encoder
- Input Word Embedding:由稀疏的one-hot进入一个不带bias的FFN得到一个稠密的连续向量
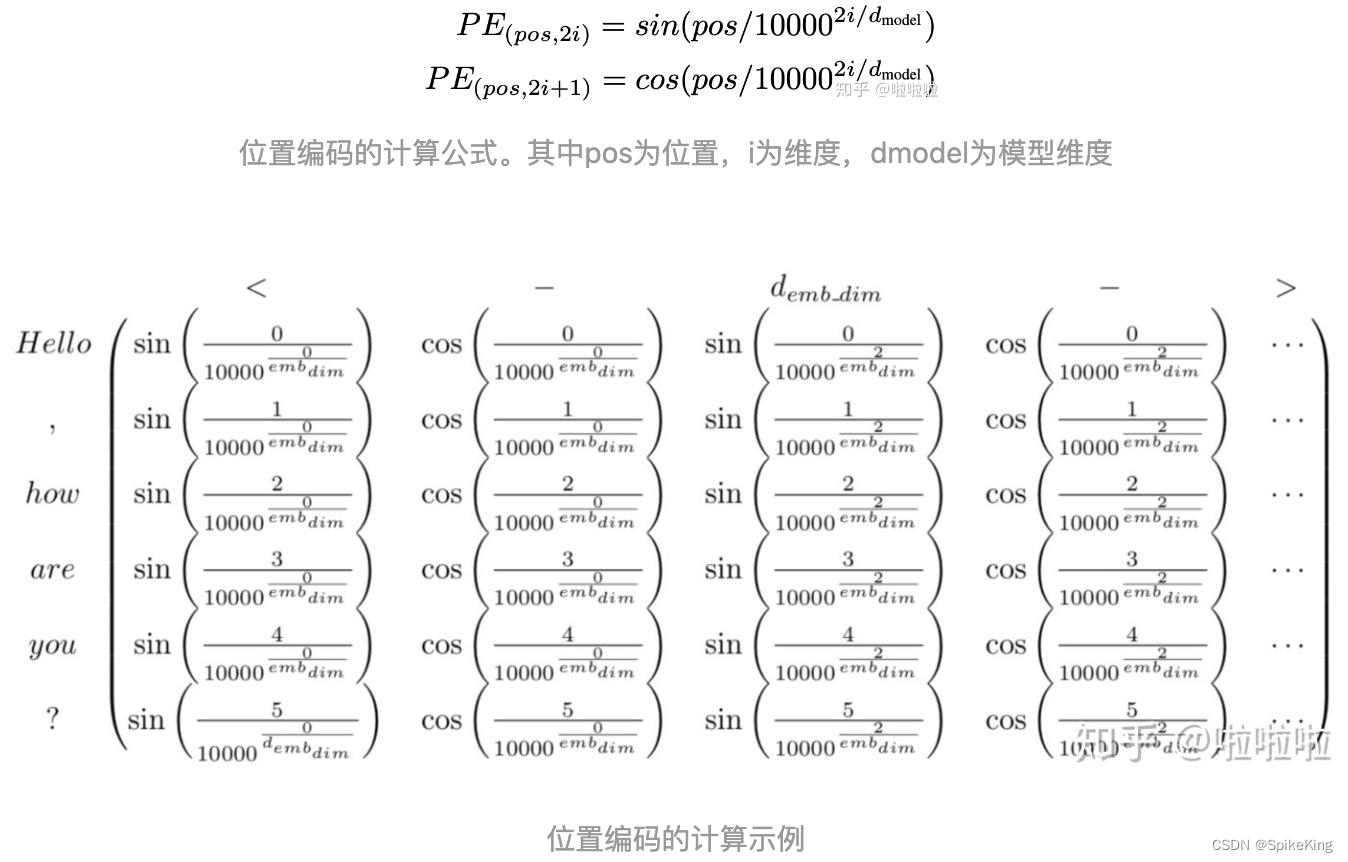
- Position Encoding:
- 通过sin/cos来固定表征:每个位置确定的;对于不同的句子,相同位置的距离一致;可以推广到更长的测试句子
- pe(pos+k)可以写成pe(k)的线性组合
- 通过残差连接来是的位置信息流入深层
- Multi-Head Self-Attention:
- 使得建模能力更强,表征空间更丰富
- 由多组Q\\K\\V构成,每组单独计算一个Attention向量
- 把每组的Attention向量拼起来,并进入一个不带bias的FFN得到最终的向量
- Feed-Forward network:
- 只考虑每个单独位置进行建模
- 不同位置的参数共享
- 类似于Pointwise Convolution
- Decoder:
- output word embedding
- multi-head self-attention
- multi-head cross-attention
- feed-forward network
- softmax
中文翻译成英文,则encoder是中文,decoder是英文
PyTorch实现Transformer,源码torch.nn.Transformer:
输入参数:
d_model:Transformer的输入维度nhead:multi-head self-attention,头的数目num_encoder_layers:encoder的block数量num_decoder_layers:decoder的block数量dim_feedforward:feed-forward的输出维度
encoder_layer x num_encoder_layers + encoder_norm -> encoder
decoder_layer x num_decoder_layers + decoder_norm -> decoder
encoder输入:src、mask、src_key_padding_mask
decoder输入:tgt、memory、tgt_mask、memory_mask、tgt_key_padding_mask、memory_key_padding_mask
模型预测流程
- 将输入源语言句子的Embedding经过Encoder进行编码
- 将Encoder输出的编码和句子起始标志位
</BOS>一起输入Decoder进行预测 - 将Decoder的预测结果和Encoder输出的编码作为Decoder的输入进行预测,直到预测结果出现句子结束标志位
</EOS>
模型训练流程
训练流程和预测流程稍有不同。在训练时,如果每次将预测结果输入还没有训练好的模型会让输出结果越走越偏。因此在训练时采用了”Teacher Forcing“技巧,不管模型输出的结果是什么,每次将正确的输出结果作为Decoder的输入继续预测。
位置编码示例
TransformerEncoderLayer继承于Module,被TransformerEncoder调用:
- MultiheadAttention ->
self.self_attn - Feedforward model -> Linearx2 + Dropout
- LayerNorm x 2,Dropout x 2,LayerNorm和Dropout都有不一样的参数,需要实例化多次
- Activation,激活函数可以复用
self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first,
**factory_kwargs)
# Implementation of Feedforward model
self.linear1 = Linear(d_model, dim_feedforward, **factory_kwargs)
self.dropout = Dropout(dropout)
self.linear2 = Linear(dim_feedforward, d_model, **factory_kwargs)
self.norm_first = norm_first
self.norm1 = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.norm2 = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.dropout1 = Dropout(dropout)
self.dropout2 = Dropout(dropout)
if isinstance(activation, str):
activation = _get_activation_fn(activation)
forward:
_sa_block:自注意力模块_ff_block:前馈模块- 可以选择,残差和norm的先后顺序
- 自注意力和前馈使用不同的norm
x = src
if self.norm_first:
x = x + self._sa_block(self.norm1(x), src_mask, src_key_padding_mask)
x = x + self._ff_block(self.norm2(x))
else:
x = self.norm1(x + self._sa_block(x, src_mask, src_key_padding_mask))
x = self.norm2(x + self._ff_block(x))
TransformerEncoder,继承于Module
- 复制
num_layers次encoder_layer,encoder_layer就是TransformerEncoderLayer _get_clones是copy.deepcopy()
self.layers = _get_clones(encoder_layer, num_layers)
self.num_layers = num_layers
def _get_clones(module, N):
return ModuleList([copy.deepcopy(module) for i in range(N)])
forward:
- 默认不使用
convert_to_nested加速 - 调用的mod就是
TransformerEncoderLayer,output进output出,循环调用 - norm是指最后一个输出,是否增加一个norm,本身在mod中包含LayerNorm和Dropout
for mod in self.layers:
if convert_to_nested:
output = mod(output, src_mask=mask)
else:
output = mod(output, src_mask=mask, src_key_padding_mask=src_key_padding_mask)
if convert_to_nested:
output = output.to_padded_tensor(0.)
if self.norm is not None:
output = self.norm(output)
return output
TransformerDecoderLayer,继承于Module,与TransformerEncoderLayer类似
- 实例化两个MultiHeadAttention
- Feedforward model与EncoderLayer相似
- LayerNorm和Dropout实例化3次,比EncoderLayer多一次
self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first, **factory_kwargs)
self.multihead_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first, **factory_kwargs)
# Implementation of Feedforward model
self.linear1 = Linear(d_model, dim_feedforward, **factory_kwargs)
self.dropout = Dropout(dropout)
self.linear2 = Linear(dim_feedforward, d_model, **factory_kwargs)
self.norm_first = norm_first
self.norm1 = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.norm2 = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.norm3 = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.dropout1 = Dropout(dropout)
self.dropout2 = Dropout(dropout)
self.dropout3 = Dropout(dropout)
forward
_sa_block->_mha_block->_ff_block,所以需要3组LayerNorm和Dropout- 输入与输出相同,一层一层进行
x = tgt
if self.norm_first:
x = x + self._sa_block(self.norm1(x), tgt_mask, tgt_key_padding_mask)
x = x + self._mha_block(self.norm2(x), memory, memory_mask, memory_key_padding_mask)
x = x + self._ff_block(self.norm3(x))
else:
x = self.norm1(x + self._sa_block(x, tgt_mask, tgt_key_padding_mask))
x = self.norm2(x + self._mha_block(x, memory, memory_mask, memory_key_padding_mask))
x = self.norm3(x + self._ff_block(x))
_sa_block和_mha_block的query、key、value不同
_sa_block中,qkv都是x_mha_block中,q是x,kv都是mem,即encoder的输入
# MultiheadAttention
def forward(self, query: Tensor, key: Tensor, value: Tensor, key_padding_mask: Optional[Tensor] = None, need_weights: bool = True, attn_mask: Optional[Tensor] = None, average_attn_weights: bool = True) -> Tuple[Tensor, Optional[Tensor]]:
def _sa_block(self, x: Tensor,
attn_mask: Optional[Tensor], key_padding_mask: Optional[Tensor]) -> Tensor:
x = self.self_attn(x, x, x,
attn_mask=attn_mask,
key_padding_mask=key_padding_mask,
need_weights=False)[0]
return self.dropout1(x)
# multihead attention block
def _mha_block(self, x: Tensor, mem: Tensor,
attn_mask: Optional[Tensor], key_padding_mask: Optional[Tensor]) -> Tensor:
x = self.multihead_attn(x, mem, mem,
attn_mask=attn_mask,
key_padding_mask=key_padding_mask,
need_weights=False)[0]
return self.dropout2(x)
QKV的公式:
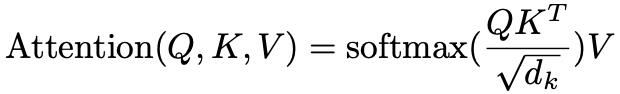
TransformerDecoder
for mod in self.layers:
output = mod(output, memory, tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask)
if self.norm is not None:
output = self.norm(output)
MultiheadAttention,参考 Harvard NLP 的 The Annotated Transformer
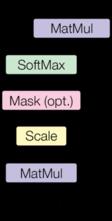
Scaled Dot-Product Attention,Softmax的分布更加稳定,方差更小,Q和K做矩阵内积。
scores.masked_fill(mask == 0, -1e9),填充0的操作- 单Head,多Head直接拼接
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) \\
/ math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
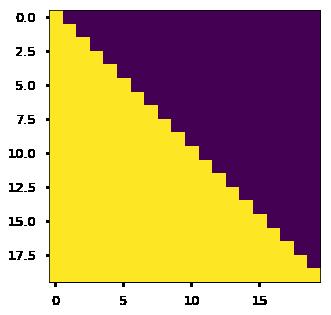
Decoder的Mask:
def subsequent_mask(size):
"Mask out subsequent positions."
attn_shape = (1, size, size)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
return torch.from_numpy(subsequent_mask) == 0
plt.figure(figsize=(5,5))
plt.imshow(subsequent_mask(20)[0])
None
以上是关于PyTorch笔记 - Attention Is All You Need的主要内容,如果未能解决你的问题,请参考以下文章