apisix健康检查测试
Posted Flytiger1220
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了apisix健康检查测试相关的知识,希望对你有一定的参考价值。
健康检查简介
健康检查的目的是动态地将上游服务器标记为健康或不健康的状态。开启健康检查功能后,当后端某台上游服务器健康检查出现异常时,负载均衡会自动将新的请求分发到其它健康检查正常的上游服务器上;而当该上游服务器恢复正常运行时,负载均衡会将其自动恢复到负载均衡服务中。
如果业务对负载敏感性高,高频率的健康检查探测可能会对正常业务访问造成影响。可以结合业务情况,通过降低健康检查频率、增大健康检查间隔、七层检查修改为四层检查等方式,来降低对业务的影响。但为了保障业务的持续可用,不建议关闭健康检查。(http健康检查是一种比较精确地检查服务是否正常的情况,因为只是做端口探测的话,如果服务僵死了,端口还是探测得通的)
nginx的健康检查
nginx是没有针对负载均衡后端节点的健康检查的,但是可以通过默认自带的ngx_http_proxy_module和ngx_http_upstream_module模块中的相关指令来完成:当后端节点出现故障时,自动切换到健康节点来提供访问。
nginx自带健康检查的缺陷:
1、nginx只有当有访问时后,才发起对后端节点探测。
2、如果本次请求中,节点正好出现故障,Nginx依然将请求转交给故障的节点,然后再转交给健康的节点处理。所以不会影响到这次请求的正常进行。但是会影响效率,因为多了一次转发
3、自带模块无法做到预警
4、被动健康检查
nginx’自带’的check模块相对来说比较"粗糙",推荐使用’淘宝技术团队’开发的nginx_upstream_check_module
特点:
1、‘主动’地健康检查,nignx’定时’主动地去ping后端的服务列表;
2、当发现某’服务出现异常’时,把该服务从健康列表中’移除’;
3、当发现某服务’恢复’时,又能够将该服务’加回’健康列表中;
nginx_upstream_check_module指令
Syntax: check interval=milliseconds [fall=count] [rise=count] [timeout=milliseconds] [default_down=true|false] [type=tcp|http|ssl_hello|mysql|ajp] [port=check_port]
Default: 如果没有配置参数,默认值是:interval=30000 fall=5 rise=2 timeout=1000 default_down=true type=tcp
Context: upstream
该指令可以打开后端服务器的健康检查功能。指令后面的参数意义是:
interval:向后端发送的健康检查包的间隔。
fall(fall_count): 如果连续失败次数达到fall_count,服务器就被认为是down。
rise(rise_count): 如果连续成功次数达到rise_count,服务器就被认为是up。
timeout: 后端健康请求的超时时间。
default_down: 设定初始时服务器的状态,如果是true,就说明默认是down的,如果是false,就是up的。默认值是true,也就是一开始服务器认为是不可用,要等健康检查包达到一定成功次数以后才会被认为是健康的。
type:健康检查包的类型,现在支持以下多种类型
tcp:简单的tcp连接,如果连接成功,就说明后端正常。
ssl_hello:发送一个初始的SSL hello包并接受服务器的SSL hello包。
http:发送HTTP请求,通过后端的回复包的状态来判断后端是否存活。
mysql: 向mysql服务器连接,通过接收服务器的greeting包来判断后端是否存活。
ajp:向后端发送AJP协议的Cping包,通过接收Cpong包来判断后端是否存活。
port: 指定后端服务器的检查端口。你可以指定不同于真实服务的后端服务器的端口,比如后端提供的是443端口的应用,你可以去检查80端口的状态来判断后端健康状况。默认是0,表示跟后端server提供真实服务的端口一样。该选项出现于Tengine-1.4.0。
Syntax: check_keepalive_requests request_num
Default: 1
Context: upstream
该指令可以配置一个连接发送的请求数,其默认值为1,表示Tengine完成1次请求后即关闭连接。
Syntax: check_http_send http_packet
Default: "GET / HTTP/1.0\\r\\n\\r\\n"
Context: upstream
该指令可以配置http健康检查包发送的请求内容。为了减少传输数据量,推荐采用"HEAD"方法。
当采用长连接进行健康检查时,需在该指令中添加keep-alive请求头,如:“HEAD / HTTP/1.1\\r\\nConnection: keep-alive\\r\\n\\r\\n”。
同时,在采用"GET"方法的情况下,请求uri的size不宜过大,确保可以在1个interval内传输完成,否则会被健康检查模块视为后端服务器或网络异常。
Syntax: check_http_expect_alive [ http_2xx | http_3xx | http_4xx | http_5xx ]
Default: http_2xx | http_3xx
Context: upstream
该指令指定HTTP回复的成功状态,默认认为2XX和3XX的状态是健康的。
Syntax: check_shm_size size
Default: 1M
Context: http
所有的后端服务器健康检查状态都存于共享内存中,该指令可以设置共享内存的大小。默认是1M,如果你有1千台以上的服务器并在配置的时候出现了错误,就可能需要扩大该内存的大小。
Syntax: check_status [html|csv|json]
Default: check_status html
Context: location
显示服务器的健康状态页面。该指令需要在http块中配置。
在Tengine-1.4.0以后,你可以配置显示页面的格式。支持的格式有: html、csv、 json。默认类型是html。
apisix健康检查
apisix健康检查说明
主动健康检查或者被动健康检查都会生成用于确定上游节点健康与否的数据,请求可能会导致 TCP 错误、超时或者生成一个 http 状态码,基于这些数据,健康检查器会更新一系列内部计数器:
- 如果返回的状态码配置为健康,那么它会累加 成功 计数器,并清空其他所有计数器;
- 如果连接失败,那么它会累加 TCP 失败 计数器,并清空所有 成功 计数器 ;
- 如果超时,那么它会累加 超时 计数器,并清空所有 成功 计数器;
- 如果返回的状态码配置为不健康,那么它会累加 HTTP 失败 计数器,并清空所有 成功 计数器;
- 如果TCP 失败、超时或HTTP 失败计数器中的任何一个达到它们配置的阈值,节点 就会标记为不健 康;如果成功计数器达到它配置的阈值,节点 就会标记为健康;
主动健康检查:
- 在节点被请求时才会开始健康检查(请求发出之后进行健康检查),如果节点被配置但没有被请求,不会触发启动健康检查。
- 如果没有健康的节点,那么请求会继续发送给上游。
- 如果上游只有一个节点,就不会触发启动健康检查,该唯一节点无论是否健康,请求都将被转发到上游。
- 配置了http健康检查,也会先建立tcp连接,如果tcp连接失败,默认是不健康的,就不会发起http探测了。
被动健康检查:
- 不会主动请求,会根据每次路由的结果,判断上游节点是否为健康状态。
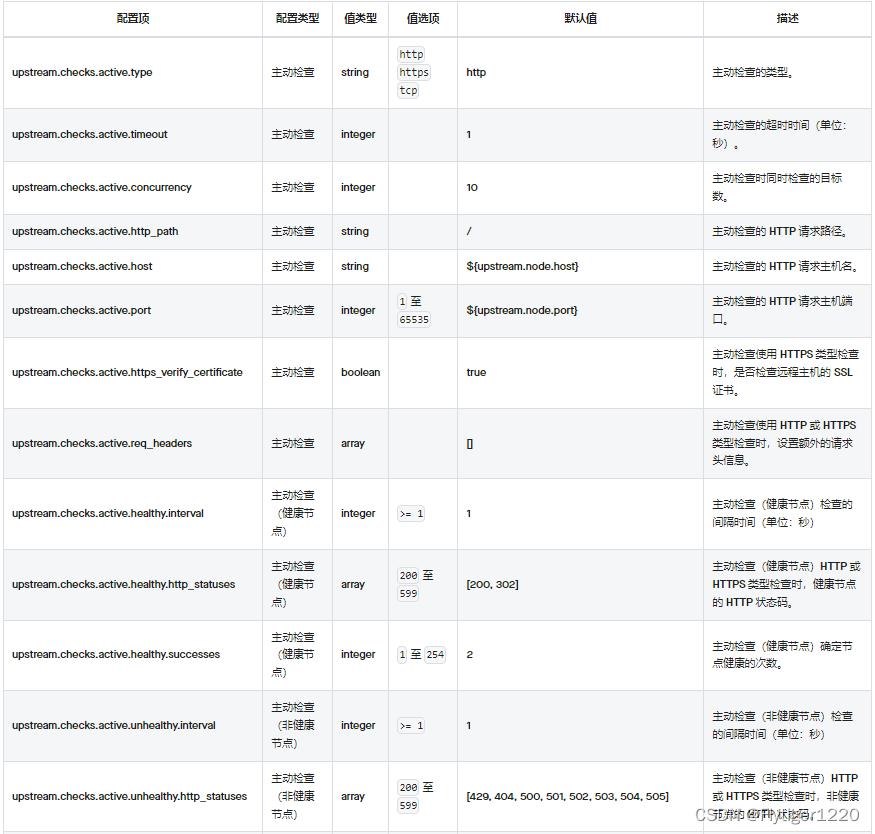
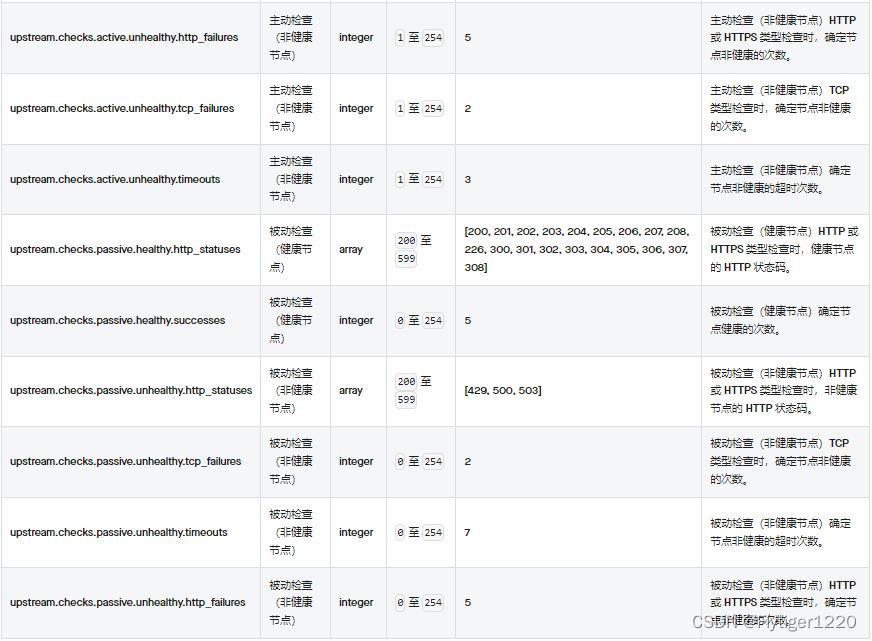
apisix健康检查配置项
apisix健康检查测试
配置环境
| 节点 | 描述 |
|---|---|
| 192.168.131.115:8081 | 服务可以拦截/hello和/mock/aqapi/test的请求; |
| 192.168.131.189:8081 | 服务不通,上游没有开启8081端口 |
| 192.168.131.189:8082 | 可以拦截/mock/aqapi/test的请求 |
拓扑信息
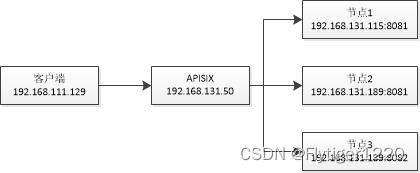
apisix路由基本信息
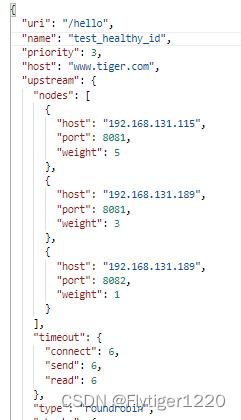
测试场景1
基本信息
开启主动健康检查,不开启被动健康检查,使用带权轮询请求;
节点1的路由和主动健康检查接口均可以正常访问;
节点2不可用;
节点3主动健康检查接口正常,路由不通;
配置信息
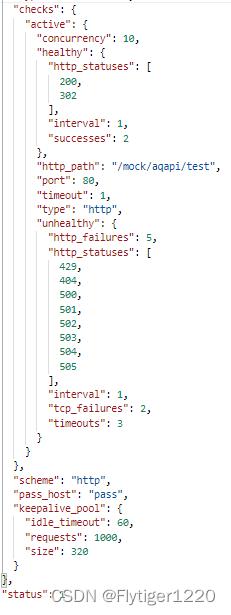
请求路径
http://www.tiger.com:9180/hello(我本地hosts文件将www.tiger.com映射到apisix上了)
测试结果
6次请求会有5次请求会到节点1上,有1次请求会到节点3上,节点3收到/hello请求返回404
测试说明
主动健康检查在收到请求之后,会去探测三个节点。
1、节点2的tcp不通,设置为不健康节点,请求会跳过此节点;
2、节点1和节点3经过2次http探测(upstream.checks.active.healthy.successes = 2),状态都是success,故两个节点均设置为健康节点;
3、apisix收到访问请求,根据负载均衡算法,对可用节点进行访问;(即便节点3并没有提供/hello的服务)
测试场景2
基本信息
同时开启主动健康检查和被动健康检查,使用带权轮询请求;
节点1的路由和主动健康检查接口均可以正常访问;
节点2不可用;
节点3主动健康检查接口正常,路由不通;
配置信息
在场景1主动健康检查的基础上增加被动健康检查的配置,配置信息如下:
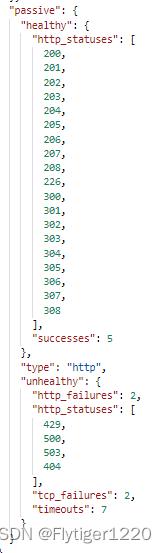
请求路径
http://www.tiger.com:9180/hello
测试结果
和主动健康检查结果一样;
每6次请求会有5次请求会到节点1上,有1次请求会到节点3上,节点3收到/hello请求返回404
测试说明
主动健康检查在收到请求之后,会去探测三个节点。
1、节点2的tcp不通,设置为不健康节点,请求会跳过此节点;
2、节点1和节点3经过2次http探测(upstream.checks.active.healthy.successes = 2),状态都是success,故两个节点均设置为健康节点;
3、apisix收到访问请求,根据负载均衡算法,对可用节点进行访问;(即便节点3并没有提供url为/hello的服务)
4、节点3被动健康检查虽然不通,但是主动健康检查成功,会将其他计数器清空,故请求还是会到这个节点;
测试场景3
基本信息
只开启主动健康检查;
节点1的路由和主动健康检查接口均可以正常访问;
节点2不可用;
节点3路由接口正常,主动健康检查接口不通;
配置信息
在场景1的基础上,将"http_path"改成"/hello",路由的"uri"改成"/mock/aqapi/test";
请求url
http://www.tiger.com:9180/mock/aqapi/test
测试结果
6次请求均到节点1上(主动健康检查http失败5次,才将节点设置成不健康(间隔1s,总共5次,总用时超过5s);故如果请求过快,可能还是有请求到节点3上面)
测试说明
主动健康检查在收到请求之后,会去探测三个节点。
1、节点2的tcp不通,设置为不健康节点,请求会跳过此节点;
2、节点1经过2次http探测(upstream.checks.active.healthy.successes = 2),状态都是健康的,故节点1设置为健康节点;
3、节点3经过5次http探测(upstream.checks.active.unhealthy.http_failures = 5),状态均是不健康的,故节点3设置为不健康节点;
4、apisix收到访问请求,根据负载均衡算法,对可用节点进行访问;
测试场景4
基本信息
同时开启主动健康检查和被动健康检查;
节点1的路由和主动健康检查接口均可以正常访问;
节点2不可用;
节点3路由接口正常,主动健康检查接口不通;
配置信息
在场景3的基础上,增加被动健康检查信息:
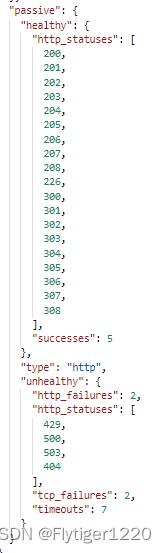
请求url:
http://www.tiger.com:9180/mock/aqapi/test
测试结果:
6次请求均到节点1上(和测试场景3结果一样,主动健康检查将节点状态设置成不健康了,就不会触发被动健康检查的计数器了)
总结
- 被动健康检查不会对目标产生额外的流量,主动进行健康检查会产生额外流量。
- 主动健康检查需要在target中配置要探测URL(可以简单配置为“ /”)和判定健康或不健康的状态码,而被动运行状况检查不需要这种配置。
- 在实际使用中,使用被动健康检查可能会误杀一些还处于正常状态的target可以承接的流量,所以应该谨慎使用被动模式;
- 对target进行探活探死的时候,不能进行有冲突的配置,比如HTTP 403在主动探测模式下认为是健康的返回码,而在被动模式下却认为是不健康的返回码;
- 在使用HTTP类型探测的时候,可以同时配置TCP错误的探测,但是如果仅仅使用TCP类型进行探测,则最好禁用HTTP类型的探测,在实际测试中发现只使用TCP探测,也会根据HTTP响应码进行健康状态的判断。
- 要完全禁用主动健康游的健康状况检查,可以把healthchecks.active.healthy.interval和healthchecks.active.unhealthy.interval都设置为0。
- 要完全禁用被动健康检查,需要将healthchecks.passive下所有计数器的阈值设置为零;
参考
ngx_http_proxy_module
ngx_http_upstream_check_module
nginx(三十六)健康检查
OpenResty中的upstream healthcheck功能沉思录
健康检查
Kong健康检查&熔断器向导
apisix-健康检查
以上是关于apisix健康检查测试的主要内容,如果未能解决你的问题,请参考以下文章