Kafka什么是消息中间件&Kafka的介绍及使用
Posted 赵四司机
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka什么是消息中间件&Kafka的介绍及使用相关的知识,希望对你有一定的参考价值。

个人简介:
> 📦个人主页:赵四司机
> 🏆学习方向:JAVA后端开发
> 📣种一棵树最好的时间是十年前,其次是现在!
> ⏰往期文章:SpringBoot项目整合微信支付
> 🧡喜欢的话麻烦点点关注喔,你们的支持是我的最大动力。
前言:
1.前面基于Springboot的单体项目介绍已经完结了,至于项目中的其他功能实现我这里就不打算介绍了,因为涉及的知识点不难,而且都是简单的CRUD操作,假如有兴趣的话可以私信我我再看看要不要写几篇文章做个介绍。
2.完成上一阶段的学习,我就投入到了微服务的学习当中,所用教程为B站上面黑马的微服务教程。由于我的记性不是很好,所以对于新事物的学习我比较喜欢做笔记以加强理解,在这里我会将笔记的重点内容做个总结发布到“微服务学习”笔记栏目中。我是赵四,一名有追求的程序员,希望大家能多多支持,能给我点个关注就更好了。
目录
一:Kafka简介
1.概述
Kafka是一款常用的消息中间件,是一个分布式流媒体平台,类似于消息队列或企业消息传递系统, 具有很高的吞吐量,官网地址。那么什么是消息中间件呢?消息中间件是利用高效可靠的消息传递机制进行异步的数据传输,并基于数据通信进行分布式系统的集成。通过提供消息队列模型和消息传递机制,可以在分布式环境下扩展进程间的通信。
你可以将消息中间件简单理解为邮局或者快递服务,我们只需要将信件或者物品交给他们之后便可以去做别的事情,这就实现了异步。至于物品的运输流程则不需要我们操心,而且传输可靠性还是较高的。
2.常用消息中间件对比
常用的消息中间件有ActiveMQ、RabbitMQ、RocketMQ、Kafka四种,由于前面我已经使用过RabbitMQ来实现对订单的管理(RabbitMQ社区活跃度高,功能完备,数据量没有那么大时候适合使用),这里我就学习一下Kafka(追求高吞吐量,适合产生大量数据的互联网服务的数据收集业务 )。这四种消息中间件的对比见下表:
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 开发语言 | java | erlang | java | scala |
| 单机吞吐量 | 万级 | 万级 | 10万级 | 100万级 |
| 时效性 | ms | us | ms | ms级以内 |
| 可用性 | 高(主从) | 高(主从) | 非常高(分布式) | 非常高(分布式) |
| 功能特性 | 成熟的产品、较全的文档、各种协议支持好 | 并发能力强、性能好、延迟低 | MQ功能比较完善,扩展性佳 | 只支持主要的MQ功能,主要应用于大数据领域 |
3.名词解释
一个简单的消息队列模型可以用下图来表示:

-
producer:发布消息的对象称之为主题生产者(Kafka topic producer)
-
topic:Kafka将消息分门别类,每一类的消息称之为一个主题(Topic)
-
consumer:订阅消息并处理发布的消息的对象称之为主题消费者(consumers)
-
broker:已发布的消息保存在一组服务器中,称之为Kafka集群。集群中的每一个服务器都是一个代理(Broker)。 消费者可以订阅一个或多个主题(topic),并从Broker拉数据,从而消费这些已发布的消息。
二:Kafka安装配置
我选取的策略是在云服务器的Docker上安装该服务,不得不说云服务器用过都说香,特别是在开发时候用来安装各种容器作为服务器使用,可以大大节省自己电脑的内存,而且速度还比较快。由于Kafka对于zookeeper是强依赖,保存kafka相关的节点数据,所以安装Kafka之前必须先安装zookeeper。
1.安装Zookeeper
(1)拉取镜像(注意版本对应)
docker pull zookeeper:3.4.14(2)创建容器
docker run -d --restart=always --name zookeeper -p 2181:2181 zookeeper:3.4.142.安装Kafka
(1)拉取镜像(注意版本对应)
docker pull wurstmeister/kafka:2.12-2.3.1(2)创建容器(注意修改成自己的ip地址)
docker run -d --name kafka \\
--env KAFKA_ADVERTISED_HOST_NAME=4.24.52.122 \\
--env KAFKA_ZOOKEEPER_CONNECT=4.24.52.122:2181 \\
--env KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://4.24.52.122:9092 \\
--env KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \\
--env KAFKA_HEAP_OPTS="-Xmx256M -Xms256M" \\
--restart=always \\
-p 9092:9092 wurstmeister/kafka:2.12-2.3.1(3)查看日志
docker logs kafka如果你的也是云服务器,查看日志时候出现如下情况

这时候你就是你的2181端口还未开放,需要自己到防火墙上面进行端口开放设置,除了开放2181端口,9092端口也是需要开放的。
注意:要是你的服务器不是云服务器,你可以将-p 9092:9092替换成--net=host,表示直接使用容器宿主机的网络命名空间,即没有独立的网络环境,它使用宿主机的ip和端口。使用云服务器的话则使用-p参数进行端口映射。
三:入门案例
1.引入依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
</dependency>2.配置生产者
package com.my.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/**
* 生产者
*/
public class ProducerDemo
public static void main(String[] args)
//1.kafka的配置信息
Properties pro = new Properties();
//Kafka的连接地址
pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"4.234.52.122:9092");
//发送失败,失败重连次数
pro.put(ProducerConfig.RETRIES_CONFIG,5);
//消息key的序列化器
pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
//消息value的序列化器
pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
//2.生产者对象
KafkaProducer<String,String> producer = new KafkaProducer<String, String>(pro);
//3.封装发送消息
ProducerRecord<String, String> message = new ProducerRecord<>("my-topic", "asd007", "hello kafka");
//4.发送消息
producer.send(message);
//5.关闭消息通道(必选)
producer.close();
代码解释:上面设置序列化器时候,我们怎么知道序列化器的引用地址呢?你可以点击项目左下角的“外部库”:
往下翻找到org.apache.kafka并进入common包里面

然后找到serialization包,找到下面两个类:

直接复制引用即可(下面的消费者也是如此,只不过需要复制的是反序列化的类)。
3.配置消费者
package com.my.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
/**
* 消费者
*/
public class ConsumerDemo
public static void main(String[] args)
//1.添加Kafka配置信息
Properties pro = new Properties();
//Kafka的连接地址
pro.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"4.234.52.122:9092");
//消费者组
pro.put(ConsumerConfig.GROUP_ID_CONFIG,"group2");
//消息key的反序列化器
pro.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
//消息value的反序列化器
pro.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
//2.消费者对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(pro);
//3.订阅主题
consumer.subscribe(Collections.singletonList("my-topic"));
//4.设置线程一种处于监听状态
while (true)
//5.获取消息
ConsumerRecords<String, String> messages = consumer.poll(Duration.ofMillis(1000)); //设置每秒钟拉取一次
for (ConsumerRecord<String, String> message : messages)
System.out.print(message.key() + ":");
System.out.println(message.value());
四:结果测试
1.单消费者
启动消费者,然后启动生产者,可以看到成功接收到消息:

2.多消费者同组
首先需要创建多个消费者

然后继续发送消息

可以看到只有一个消费者能够获取到消息。
3.多消费者不同组
将消费者1设置在group1,将消费者2设置在group2,然后生产者发送消息:

可以看到两个消费者都能接收到消息。
4.总结
-
生产者发送消息,多个消费者订阅同一个主题,只能有一个消费者收到消息(一对一)
-
生产者发送消息,多个消费者订阅同一个主题,所有消费者都能收到消息(一对多)
五:Kafka高可用设计(深入原理)
1.集群

-
Kafka 的服务器端由被称为 Broker 的服务进程构成,即一个 Kafka 集群由多个 Broker 组成
-
这样如果集群中某一台机器宕机,其他机器上的 Broker 也依然能够对外提供服务。这其实就是 Kafka 提供高可用的手段之一
2.备份机制(Replication)
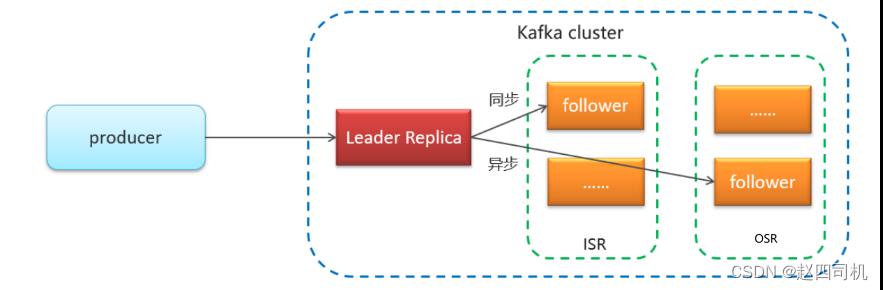
Kafka的副本分为领导者和追随者,只有Leader副本才能对外提供读写服务(也有资料说Kafka2.4之后社区通过引入新的Broker参数使得Follower副本能有限度地提供读服务),响应Client请求,Follower副本只是采用拉(PULL)方式被动地同步Leader中的数据,见下图:
首先我们先了解几个概念:
- AR(Assigned Repllicas):一个分区里面所有的副本(不区分leader和follower)
- ISR(In-Sync Replicas):能够和leader保持同步的follower+leader本身组成的集合
- OSR(Out-Sync Replicas):不能和leader保持同步的follower集合
需要注意的是,Kafka只会保证ISR中的副本实现和Leader同步,Kafka一定会保证Leader接收到消息之后完全同步给ISR中所有副本,ISR的机制保证了处于ISR内部的Follower都可以和Leader保持同步,一旦出现故障或者延迟(一段时间没有同步),该Follower就会被踢出ISR。
为什么会出现ISR呢?世界上没有完全稳定的系统,假如一个Kafka节点的Leader副本出现了问题,这就需要Follower来竞争称为新的Leader,那么这时候是所有的Follower都能参与竞争吗?显然是不可以的,因为并不是所有的Follower都能保持和原Leader数据高同步,假如一个Follower的数据量明显少于Leader的数据量,那么这时候它就不具备竞争资格,这时候ISR的重要性便体现出来了。要选举新的Leader时候,Kafka会优先从ISR中选取,如果ISR中的节点都不行了,这时候才会从OSR中选取。
前面提到同步率跟不上的Follower会被踢出ISR,那么什么原因会导致不同步呢?主要有如下三点:
-
同步数据请求速度追不上:follower副本在一段时间无法追上leader副本端的消息接收速度。比如follower副本的网络I/O阻塞,这会导致follower副本同步leader副本的速度大大降低。你可以这么理解,如果leader副本的消息流入速度大于follower副本的拉取速度时,你follower就是实时同步有什么用?相关参数为replica.lag.max.messages,该参数用来检测同步数据请求速度追不上的问题,如果ISR中的副本消息数落后于leader副本的消息数超过了该参数的设置,将会被踢出ISR。但是这个参数在kafka0.9.0.9版本之后被移除,至于为什么会被移除,主要原因还是当数据高峰时候Follower数据拉取速度跟不上Leader流入速度,而到了低峰时段Follower又能够慢慢追赶回来,假如在高峰时候就将其踢出ISR这显然是不太合理的。
-
进程卡住:follower副本一段时间无法向leader发出请求,比如follower频繁的进行GC。
-
新创建的副本:用户主动增加副本数,新创建的副本在启动后会追赶leader的进度,这段时间新增的follower副本通常与leader副本是不同步的。
极端情况下,假如所有副本都挂了,这时候有两种策略:
- 等待ISR中的一个活过来,选为Leader,数据可靠,但活过来的时间不确定。
- 选择第一个活过来的Replication,不一定是ISR中的,选为leader,以最快速度恢复可用性,但数据不一定完整。
以上是关于Kafka什么是消息中间件&Kafka的介绍及使用的主要内容,如果未能解决你的问题,请参考以下文章