R语言R语言数据可视化——东北大学大数据班R实训第三次作业
Posted 爱做梦的鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言R语言数据可视化——东北大学大数据班R实训第三次作业相关的知识,希望对你有一定的参考价值。
数据可视化知识点回顾
- 基础知识点回顾:
条形图、饼图、直方图、核密度图、箱线图和点图。 - 中级知识点回顾:
散点图、气泡图、折线图、相关图、马赛克图。
title: “R实训第三次作业”
output: html_notebook
1.通过读取文件death rate.csv获取数据保存到df中;简单分析数据,获取共
有数据多少条,是否有缺失值或是异常值;若存在这样的数据,将这些数据
剔除;对于死亡率来说,它的值域是0<q<=1 。
df <-
read.csv("C:\\\\Users\\\\zzh\\\\Desktop\\\\R语言\\\\R第3次实训\\\\数据\\\\death rate.csv")
dim(df)
#缺失值的行数
sum(rowSums(is.na(df)) > 0)
# 男性死亡率异常
nrow(df) - nrow(df[df$q_male > 0 & df$q_male <= 1, ])
# nrow(df) - nrow(df[df$q_female > 0 & df$q_female <= 1,])
nrow(df)
df <- na.omit(df)
nrow(df)
df <- df[df$q_male > 0 & df$q_male <= 1, ]
# df <- df[df$q_female > 0 & df$q_female <= 1,]
nrow(df)
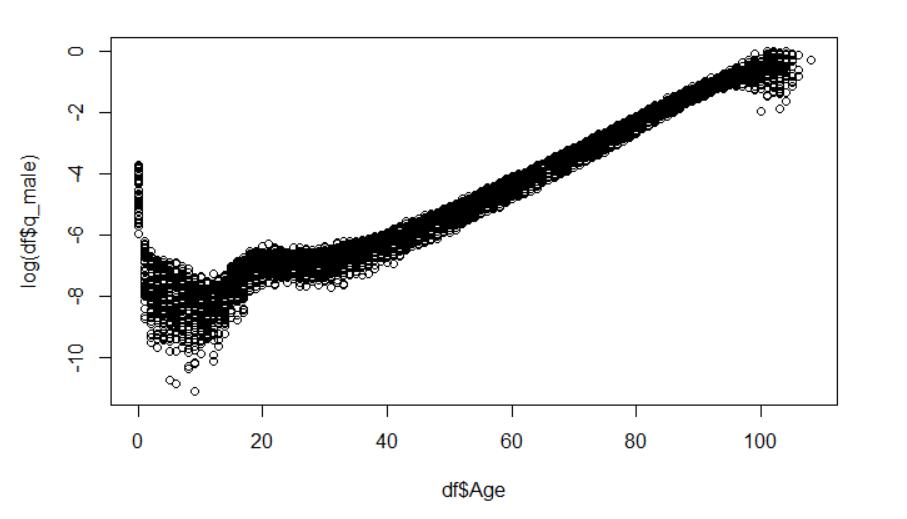
2.绘制散点图,分别展示年龄与男性的死亡率(对数即取log)的关系。
plot(df$Age,log(df$q_male))
3.绘制直方图来观察一下男性死亡人数的分布。
hist(df$Male_death,breaks=100)
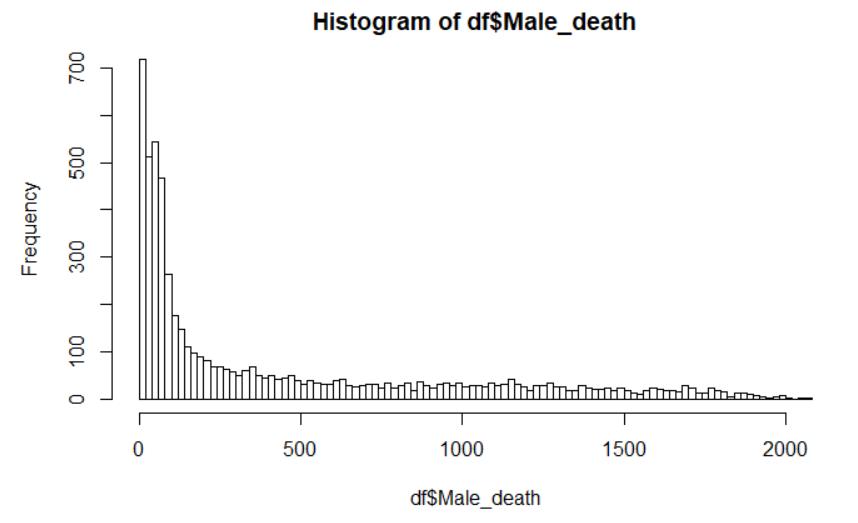
4.计算df的各变量的相关系数,并画出相关图。【用corrgram包】
# install.packages("corrgram")
library(corrgram)
options(digits=2)
cor(df)
corrgram(df, order=TRUE,
lower.panel=panel.shade,
upper.panel=panel.pie, text.panel=panel.txt,
main="Corrgram of df intercorrelations")
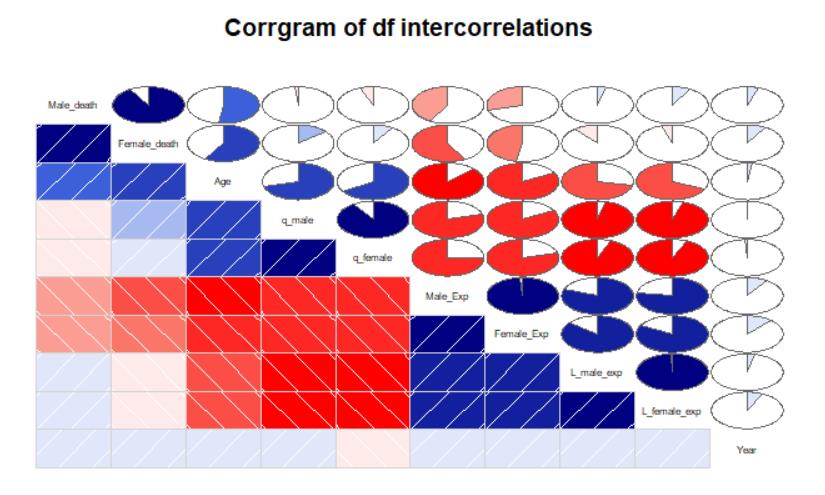
1.通过读取文件House-handle.csv获取数据保存到houseIndex中。
houseIndex<-read.csv("C:\\\\Users\\\\zzh\\\\Desktop\\\\R语言\\\\R第3次实训\\\\数据\\\\House-handle.csv")
2.数据探索,绘制一张图表来展示1990到2011年的HPI的变化情况,横轴是时间
(可以是数据的第一列),纵轴是HPI值。
Sys.setlocale("LC_TIME","English")
# 最初的date数据类型是factor
class(houseIndex$date)
head(houseIndex$date)
# 然后转化为character
houseIndex$date <- as.character(houseIndex$date)
class(houseIndex$date)
head(houseIndex$date)
# 然后转化为Date
houseIndex$date <- as.Date(houseIndex$date, "%d-%b-%y")
class(houseIndex$date)
head(houseIndex$date)
plot(houseIndex$date,houseIndex$index,type = "l",main = "HIP(Canberra)-since 1990")
3.绘制一张图,展示每个月的HPI的增长量,表示为delta,在0的位置添加参考线。
【注: 增长量,可以用下一条减上一条来计算;第一条的上一条的HPI值设置为1】
# a<-c(1,houseIndex$index)
# a<-a[1:length(a)-1]
# c<-houseIndex$index-a
# plot(houseIndex$date,c,main = "Increase in HPI")
# abline(h=0,lty=3)
houseIndex$rates <- which(houseIndex$index==houseIndex$index)-1
houseIndex$rates[1] <- 1
houseIndex$delta <-houseIndex$index-houseIndex$index[houseIndex$rates]
houseIndex$delta[1] <- houseIndex$index[1]-1
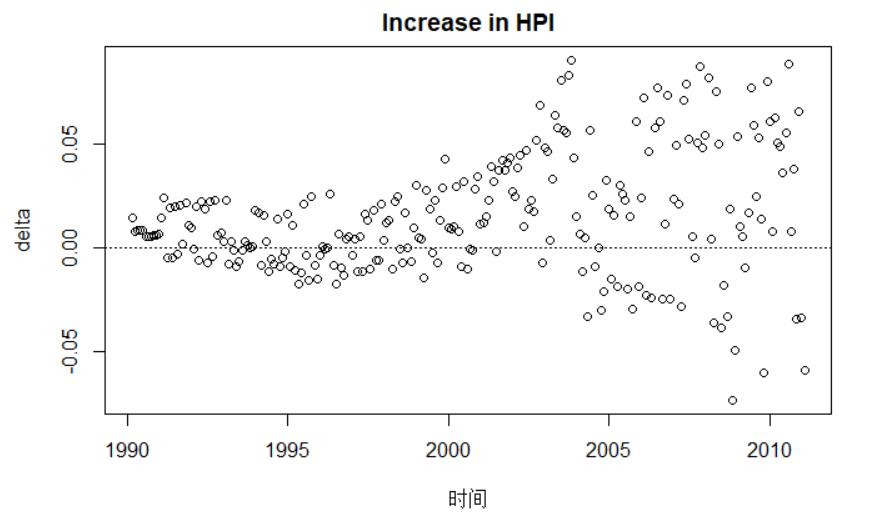
plot(houseIndex$date,houseIndex$delta,type="p", main="Increase in HPI",xlab="时间",ylab="delta")
abline(h=0,lty = 3)
4.对HPI增长率建立表格,其中每一行代表一个月份,每一列代表一个年份,显示
前四年的数据( HPI增长率舍入到小数点后4位);并可视化HPI的平均年增长率和
HPI的平均月增长率(全部年份的年增长率(列平均)和月增长率(行平均))。
【注:增长率,增长量/上一条的HPI值】
houseIndex$rates <- houseIndex$delta/houseIndex$index[houseIndex$rates]
houseIndex$rates[1] <- houseIndex$index[1]-1
rateMatrix <- xtabs(rates~month+year,data=houseIndex)
round(rateMatrix[,1:4],digits=4)
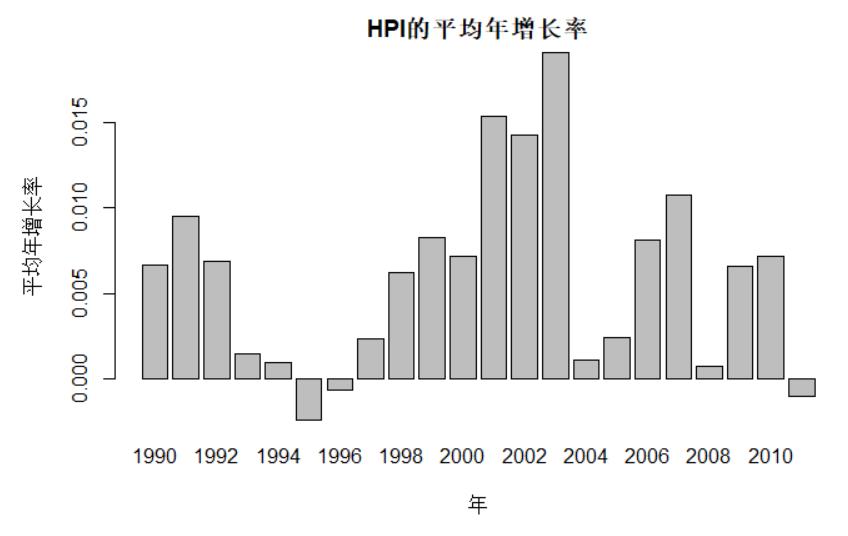
yearmean <- colMeans(rateMatrix)
barplot(yearmean,main="HPI的平均年增长率",xlab="年",ylab="平均年增长率")
mouthmean <- rowMeans(rateMatrix)
plot(1:12,mouthmean,type="b", main="HPI的平均月增长率",xlab="月",ylab="平均月增长率")

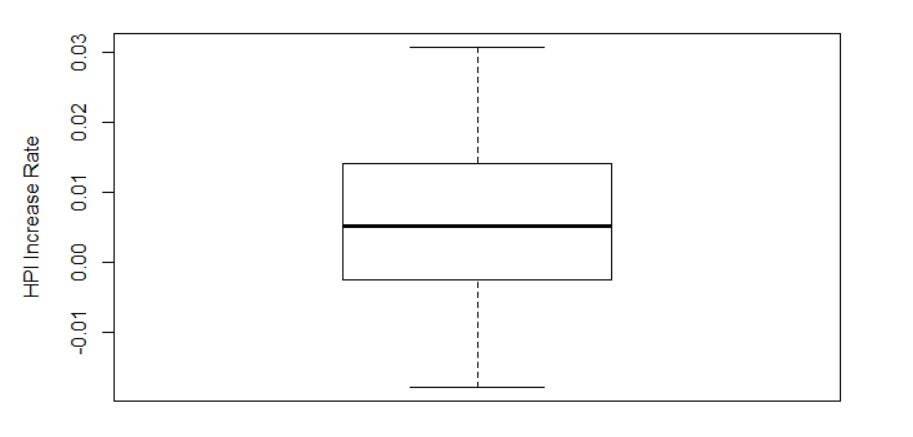
5.绘制一个箱线图,来查看HPI的增长率的分布情况。
boxplot(rateMatrix,ylab="HPI Increase Rate")
以上是关于R语言R语言数据可视化——东北大学大数据班R实训第三次作业的主要内容,如果未能解决你的问题,请参考以下文章