操作系统内存分区与分页--11
Posted 大忽悠爱忽悠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了操作系统内存分区与分页--11相关的知识,希望对你有一定的参考价值。
操作系统内存分区与分页--11
引言
上一节简单介绍了一下对内存的使用和分段处理,下面先来复习一下整个流程:
- 我们需要将程序1从磁盘中分段读入到内存中,数据段读入到3000开始处,代码段读入到1000开始处
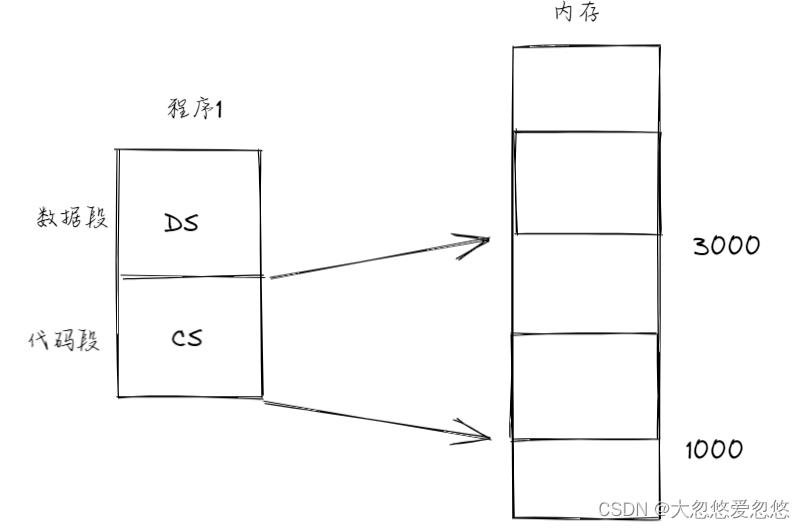
因为程序是分段在内存中存放的,因此需要额外的空间记录每个段的存放位置和占用大小,这就引出了段表,这里的段表又被称为LDT表,每个进程都对应一个LDT表:
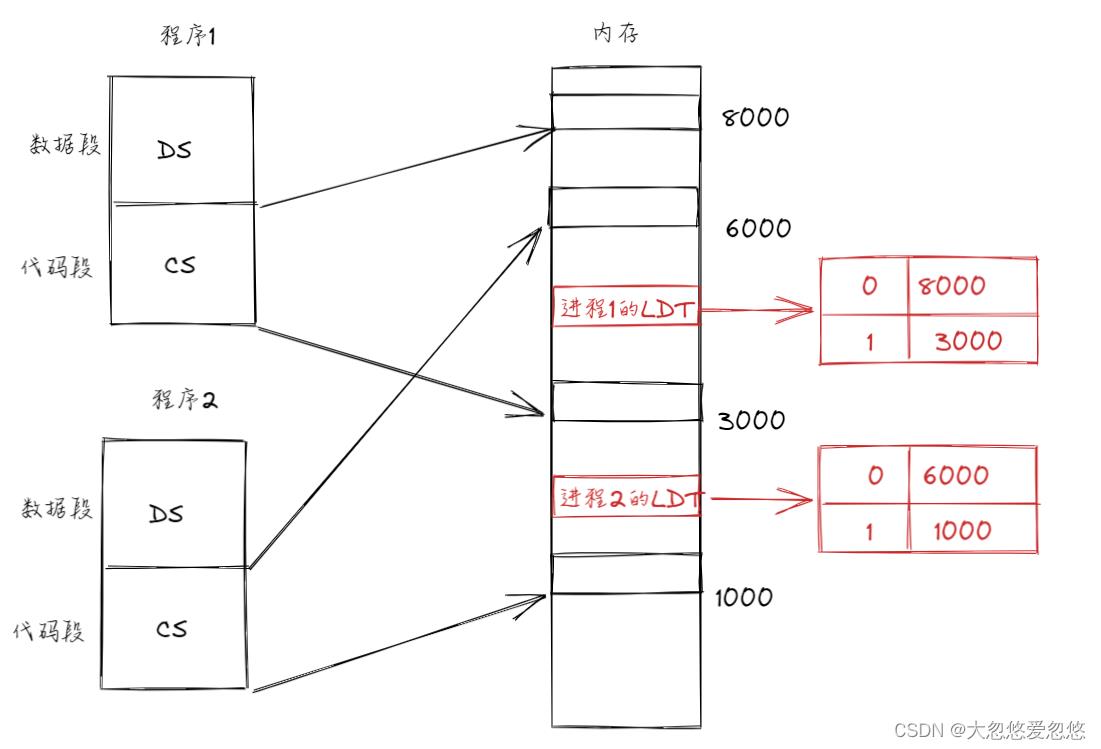
进程1的数据段段号为0,在内存中的起始地址为8000,代码段段号为1,在内存中的起始地址为3000.
进程2的分析同理
因为一个CPU同时只能处理一个进程,那么当CPU处理当前进程1时,需要知道当前进程1对应的LDT表在何处,因此就需要一个寄存器来记录当前正在被处理的进程的LDT表位置,该寄存器为LDTR:
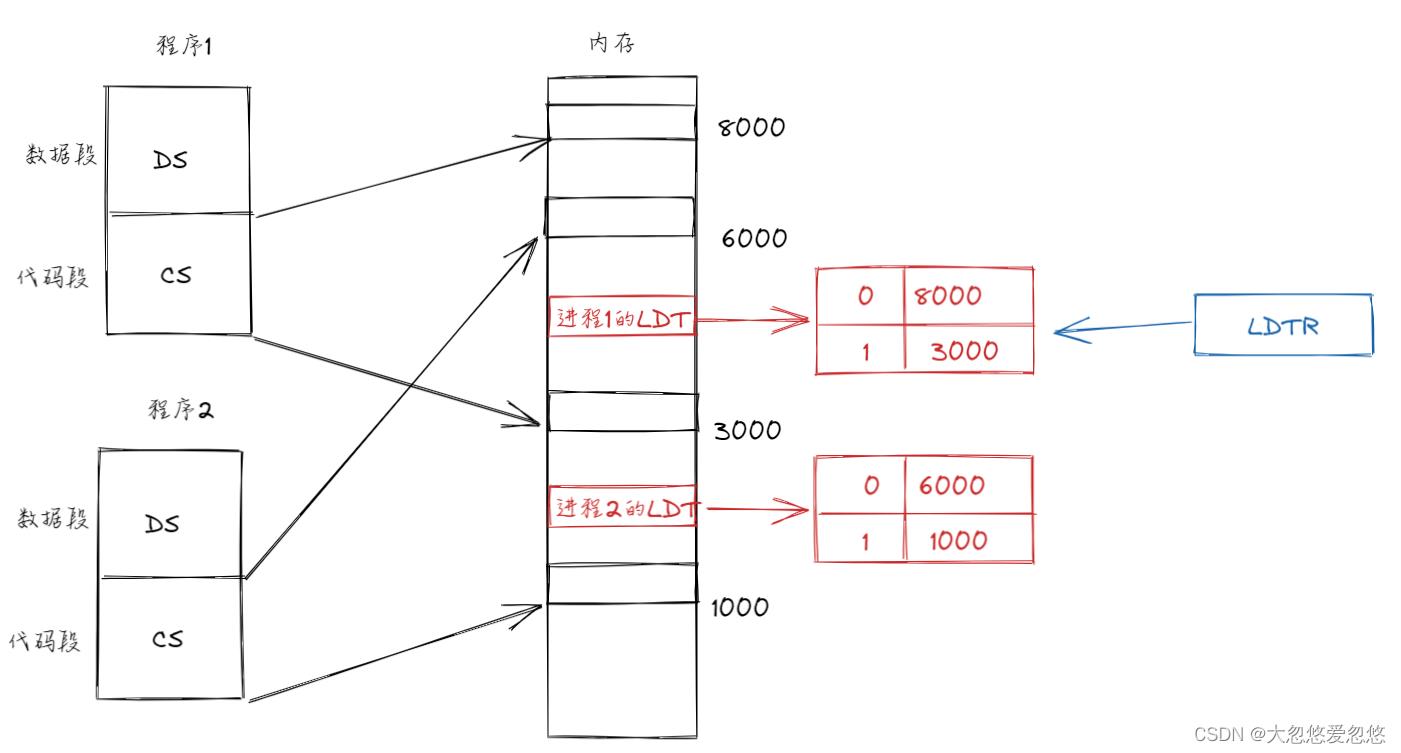
当需要进行访存时,CPU需要先通过LDTR定位到当前进程的LDT表,然后通过cs或者其他段寄存器中保存的段选择子(下标,段号),去LDT表中定位到具体的段,然后获取段的基址,然后基址加上偏移地址得到真实的物理地址。
但是因为每个进程都需要一个LDT表,进程数量又是在动态变化的,因此为了统计和管理LDT表,就利用GDT表来存放所有存在的LDT表,GDT表整个系统只有一份:
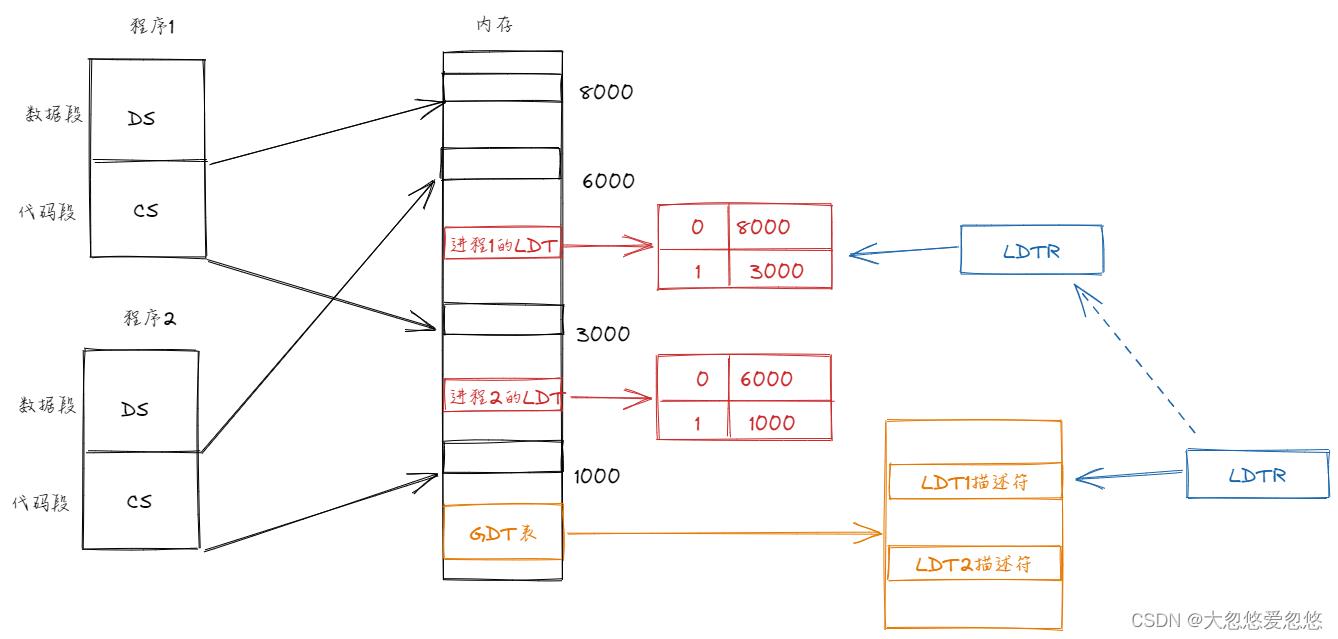
所以,是先通过GDTR寄存器定位到GDT表在内存中的位置,然后通过LDTR中保存的选择子(下标),去GDT表中定位到对应的LDT表描述符,该描述符提供了当前LDT表的基值,然后将该基址赋值给LDTR,那么LDTR就指向了当前进程的LDT表。
然后再通过cs或者ds中保存的段选择子(段号),去LDT表中定位到具体的段描述符,例如: 定位当前程序1的数据段,然后通过对应的段基址,就可以定位到程序1数据段的真实物理位置,然后直接访问即可。
可以看出来,每个进程关联的LDT表,其实就是我们之前说的,用来完成进程间内存隔离用到的映射表,因此,再进行进程切换时,需要切换LDT表,即处理器会把新任务LDT的段选择符和段描述符自动地加载进LDTR中。
内存分区
上面讲了那么多,总结下来就三步:
- 程序在编译时,进行分段处理
- 在内存中寻找空闲分区
- 将对应的程序段从磁盘读入到空闲分区,并且初始化好对应的LDT表中的表项,和对应的PCB信息
今天的重点在于如何在内存中寻找到可用的空闲内存,即空闲分区?
固定分区 与 可变分区
给你一个面包,一堆孩子来吃,怎么办?
- 等分,操作系统初始化时将内存等分成k个分区
- 但孩子有大有小,段也有大有小,需求不一定
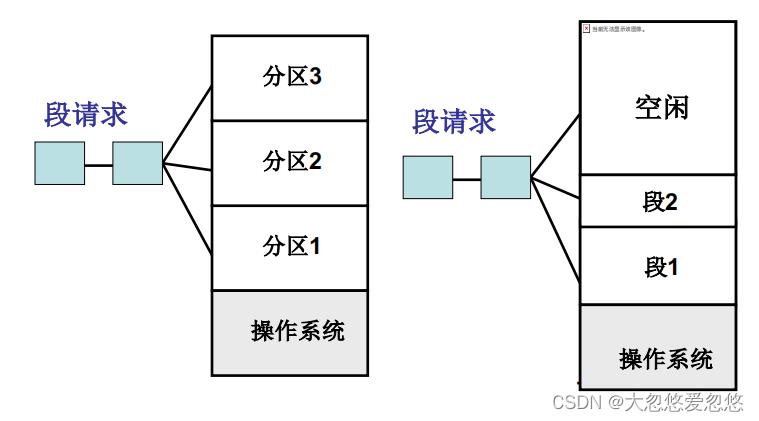
显然,固定分区不符合现实要求,因此需要采用可变分区
可变分区的管理过程 — 核心数据结构
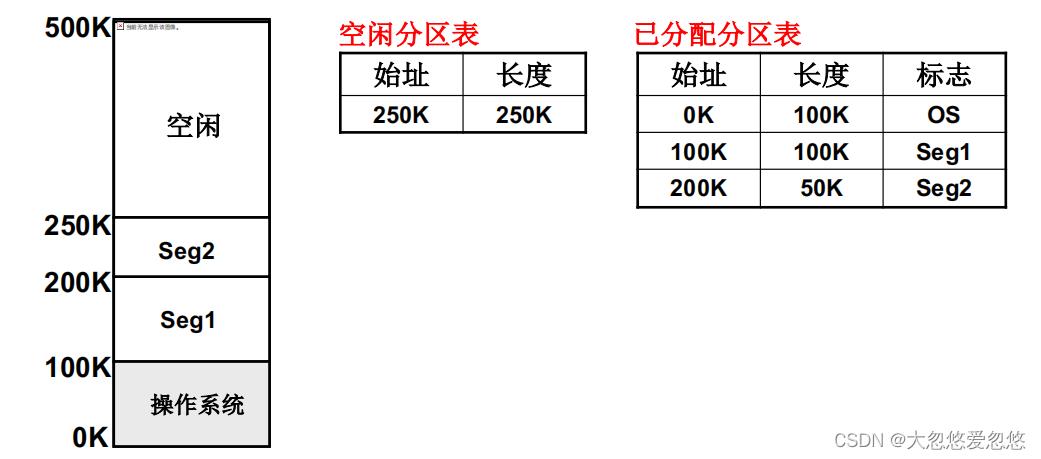
为了实现可变分区,我们需要两个表,一个记录已经分配的分区,一个记录空闲分区。
可变分区的管理—请求分配
当操作系统接收到一个段内存请求时,例如: 某个数据段需要100k的内存大小,怎么分配?
- 首先查询空闲分区白表,发现此时空闲分区中剩余内存大小满足需求,可以进行分配

- 从空闲分区起始地址分配出去100k内存,更新空闲分区表和已分配分区表
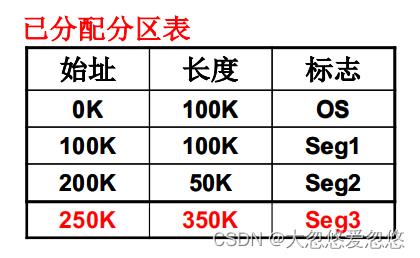

可变分区的管理—释放内存
因为进程并一定会一直存活,可能会终止,因此在进程终止时,需要将当前进程涉及到的段全部释放掉。
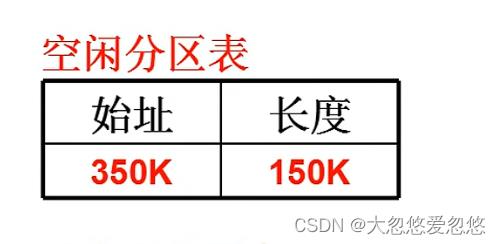
假设这里段2占用的内存空间需要进行释放,首先需要在空闲分区表中记录下这块被释放的内存空间。
然后再删除掉已分配分区表中段2的分配记录。

可变分区的管理—再次申请
- 又一个段提出内存请求: reqSize=40K, 怎么办?
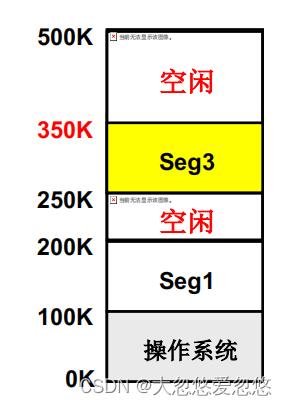

有2个空闲分区,选哪一个? - 首先适配: (350,150): 遍历空闲分区表,选择第一个可以放下需求中需要内存数的空闲分区,复杂度为O(1)
- 最佳适配: (200,50): 遍历空闲分区表,选择一个空闲分区大小和需要的内存大小最接近的一个分区,复杂度为O(n),并且会产生很多的内存碎片
- 最差适配: (350,150):遍历空闲分区表,选择一个空闲分区大小和需要的内存大小差距最大的一个分区,复杂度为O(n),不会产生很多的内存碎片,得到的分区大小相当来说比较均匀
对于空闲分区选择的算法设计也很重要,需要灵活转变,按照实际情况,选择合适的算法。

引入分页: 解决内存分区导致 的内存效率问题
内存分区最大的缺点是什么呢?

内存分区无论采用哪种分配算法,都容易导致内存碎片的产生,随着分配次数增加,内存碎片会越来越多,当某个内存申请请求发起后,发现只有合并内存碎片才能够完成内存分配,这时候就需要进行内存的紧缩。
但是内存紧缩需要花费的时间开销会很大,在此期间CPU无法访问内存,也就没办法去执行上层应用程序,给用户的感觉就是系统无响应,卡死住了。
段在移动过程中,还涉及到对LDT表的修改,因此只有空闲分区整合完毕后,程序的基址才能被确定,CPU才能去执行程序,因此在内存碎片整理期间,CPU无法访存
从连续到离散…
上面每次都是按当前段的大小来分配内存,当前段需要多少内存,我们就必须找到一块连续内存分配给它,这样的方式很容易导致内存碎片的产生,怎么解决呢? 去生活中找灵感!
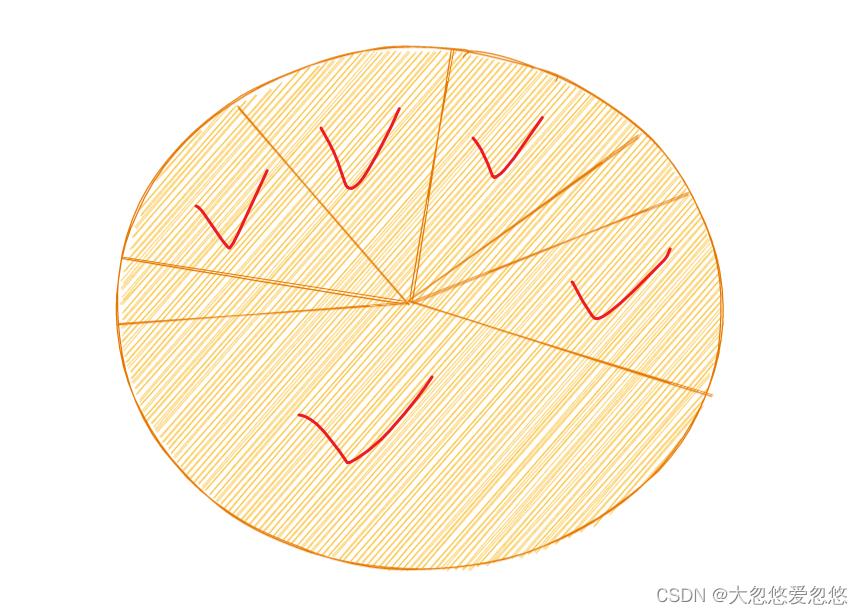
就像吃披萨一样,如果买了一整块披萨如下,每个人都按照自己的分量去切割披萨吃,那么切到最后,会发现剩下来很多一小块一小块的披萨,没人要了,这不是很浪费吗?
怎么办呢? 我们提前将披萨分成若干等份如下,每一份的大小都是固定的,谁想吃,就拿出一份吃,而不是像上面那样自己去切割出来一块。
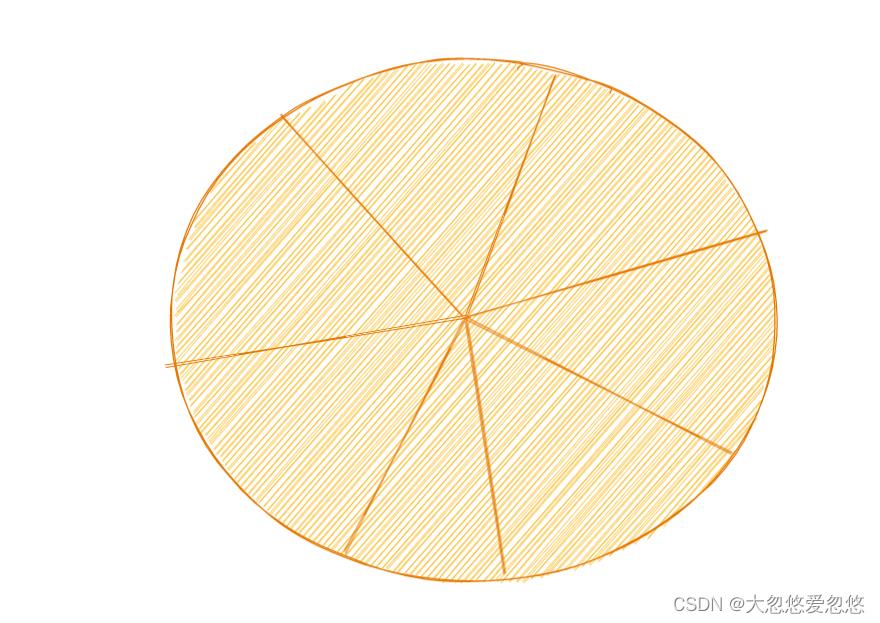
这样一处理之后,就会发现不会存在披萨碎片了,也就没用浪费了。
将披萨处理的思想换到内存管理上来,就是将内存分成页
针对每个段内存请求,系统一页一页的分配给这个段,假如这个段需要3页半大小的内存,那我就分配给他四整页内存。

问题:此时需要内存紧缩吗? 最大的内 存浪费是多少?
- 不需要内存紧缩,因为内存分配最小单元为页
- 最大浪费内存为4k,例如: 有个段需要3页多一丢丢的内存,此时还是需要分配给他四页内存,相当于浪费了接近一页内存,而一页内存在linux 0.11中的大小为4k
页已经载入了内存,接下来的事情…
还是看下面这幅图,内存初始时按页进行分割,一个页框对应一个页的大小。
而当我们需要为段0分配内存的时候,也是按照页的大小来分配的,例如: 段0需要四个页,那么首先就需要在内存中找到四个空闲页,然后分配给段0,但是这四个页的顺序未必是连续的,否则就退化到一开始按照空闲分区分配的模样了。
既然不是连续的页,那么就需要将分配给段0的页进行编号,例如下图中的页0,页1,页2,页3等。
段中的数据依次存放在编好号码的页中,这里被编好的页号可以看做是虚拟页号,而页框对应页号才是真实的页号:

既然段0中的数据被保存到了四个不相邻的页中,并且每个页也被按顺序被编了号,那么怎么根据虚拟页号定位到真实页号呢?
- 页表: 存放虚拟页号和真实页号的映射关系
上面页0放在页框5中,页0中的地址就需要重定位
假设有下面这段汇编指令,他需要将寄存器eax中保存的值,设置到0x2240中去:
mov [0x2240], %eax
这里0x2240是虚拟地址,是通过cs中存放的段选择子查询LDT表,得到段基址,然后加上ip中保存段偏移地址,得到的虚拟地址(注意这里得到的是虚拟地址,什么是虚拟地址,后面章节讲到段页结合的时候会说)
首先需要计算出该虚拟地址映射到当前进程的哪一个虚拟页号中,然后再通过查询当前进程对应的页表,得到这个虚拟页号对应的真实页号,计算真实页号的起始地址很容易,只需要将真实页号*页大小即可,然后得到真实页的起始地址,加上页内偏移地址,就得到了真实的物理地址。
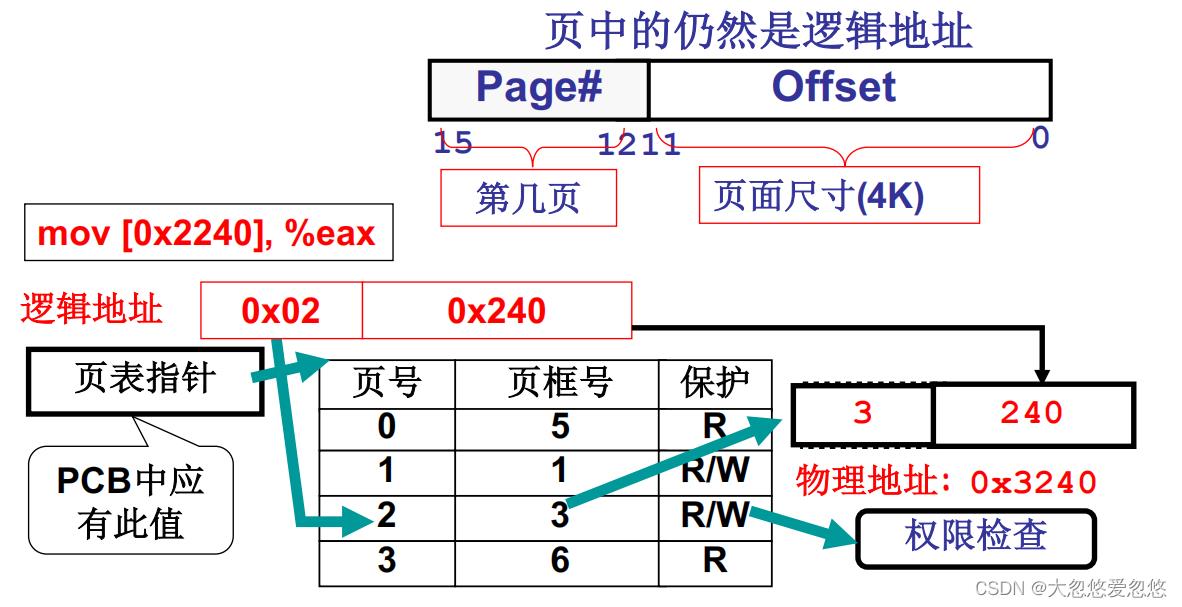
具体步骤如下:
- 因为一个段被分为了好几页,因此需要先计算出当前虚拟地址具体映射到哪一个虚页号上,这个过程只需要将虚拟地址除页大小4k即可,然后还能顺便计算出页内偏移地址
上面这个过程由硬件MMU完成
- 计算出虚页号和页内偏移地址后,需要去查询页表,直接去当前进程关联的PCB中找到页表指针即可,通过页表指针就能找到当前进程对应的页表位置,通过页表可以查询出当前页号对应的实际页框号,知道了实页号,只需要通过实页号*页大小,就可以计算出实际物理页在内存中的起始地址,然后加上页内偏移地址,就得到了真实的物理地址。
其实查询页表不需要去查询当前进程关联PCB中的页表指针,因为和定位当前进程的LDT表位置一样,CPU内部提供了一个cr3寄存器,指向当前正在执行的进程关联的页表。因此当进程切换时,cr3寄存器需要指向下一个进程的页表。
小结
从最开始直接将整个程序加载进内存,到将程序分段载入,但是考虑到分段载入会导致内存中产生大量的内存碎片,因此又把一个段存放在很多不同的页上面,为了知道虚拟页号映射到的真实页号,因此才有了页表。
以上是关于操作系统内存分区与分页--11的主要内容,如果未能解决你的问题,请参考以下文章