数据系统读写权衡的一知半解
Posted 半吊子全栈工匠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据系统读写权衡的一知半解相关的知识,希望对你有一定的参考价值。
在计算机领域,有一个有趣的趋势,往系统中写入数据需要做更多的工作。我们需要对数据进行重新组织、合并、重新建立数据库索引等操作,才能使写入的内容更加有用。如果不这样做,必须实现内容搜索或其他工作来支持未来的数据读取。

数据库中的索引
我关系数据库的索引是个有趣而令人困惑的概念,索引如何在对应用程序透明的情况下优化访问的呢?当然,更新索引意味着另外的磁盘访问,因为 b + 树的索引不适合放在内存中。如果以后读取数据,那么对数据库进行更改的额外工作是值得的。
下一个令人困惑的问题是,应该编制多少索引?是否应该对每一列都建立索引?什么时候应该把一列数据编入索引?我索引越多,读取查询就会变得越快。同时,索引越多,数据更新的速度就越慢。
这是一个常见的权衡方案,快速读意味着慢速写。
行存储与列存储
将高性能更新与行存储联系起来是很自然的,如果按列组织数据的话,因为具有相同值的许多逻辑行在物理上彼此相近,柱状数据库执行查询的速度非常快。但是,更新列存储就不那么容易了。
通常,行存储中的更新单独保存,因为每一行的数据较小,查询会以相对快速的方式检查行。这些查询与更快的列存储的结果相结合,以提供统一的准确结果。新的行存储更新会定期与列存储合并,以创建新的列存储,这可以以类似于 LSM 树中合并的级联方式完成。
当插入到一个列存储区中时,这种重写和整合新数据的负担是一种写入数据放大的形式,在这种形式下,一次写入之后会变成更多的写入。
LSM树的应用
LSM树最早是在1996年提出的,这个想法是将对键值存储的更改作为事务跟踪,并在内存中保留新的值。事务提交时,可以将最近键值对的排序集合写入磁盘中唯一命名的文件。此文件包含已排序的键值对以及文件中键的索引。一旦写入磁盘,新提交的更改不需要保存在内存中。
逐键查找值看起来就像在随机地点找东西时的样子。在一个小房间里线性搜索自己的钱包可能是易于处理,但是当搜索空间在大型酒店里就不那么容易了。为了减少数据读取时的烦琐,LSM 树组织数据的方法是边读边重写。
当从存储引擎新写入一个新文件时,它有一堆键值对。为了便于查找键,这些键与前面编写的文件合并。每个 LSM 树都具有某种形式的扇出,其中较低级别的树保存在更多的文件中。LSM 树的深度取决于扇出、每个文件的大小以及树中键值对的数量。一般来说,大部分存储都位于树的最底层。
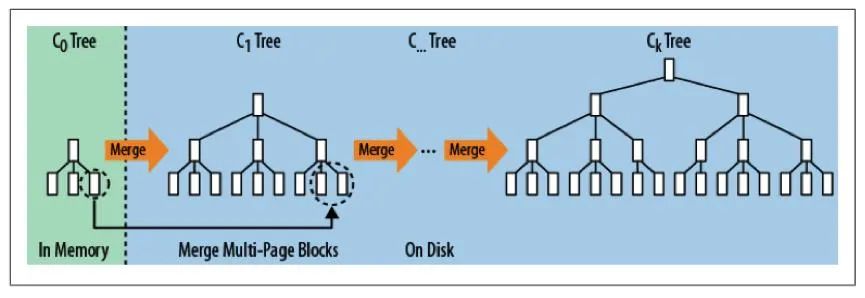
因此,在越来越受欢迎的 LSM 结构中,有各种各样的实现选择:
平衡合并
当一个新文件被添加到一个级别时,在循环遍历中选择下一个文件,并将其与下一个级别的文件合并。假设从10个文件中选择一个扇出,会发现文件中的键范围通常涵盖了下面级别中大约10个文件中的键范围。把11个文件合并在一起,一个下降到下个级别,进而得到11个文件。现在,下一级已经被一个文件增加了,所以需要重复并再次合并。
分层合并
在进行合并之前,让一堆文件在每个级别上堆叠起来。假设在每个级别合并之前堆积了10个文件,大大减少了所需的合并数量。
平衡合并有着很大的写入放大, 每次将一个新的键值对写入到级别0,在每个级别上都要重写10到11次,但是读取数据的成本较少。分层合并的写入放大要低得多,因为新文件在合并之前会在每个级别上堆叠起来,所以合并的次数会减少,写入的内容也会减少,但是数据读取所付出的努力要多得多。

索引和搜索
搜索在许多方面都是数据库索引的变体。在数据库中,索引标识一般以行 id 或主键的形式隐藏在数据库中。在关系型数据库系统中,索引更新是通过事务集成的,我们能够看到性能差异。
搜索系统在处理文档方面有些不同。大多数搜索系统在文档发生变更后异步更新搜索索引, 这是与某种形式的ID交织在一起。搜索使得读取文档更加容易。它极大地降低了数据读取时的成本,而创建和合并搜索索引是一项复杂的工作,也是数据写入放大的一种形式。
搜索的索引需要语料库,以找到最近写入或更新的文档。其中每一个都需要有一个标识符,然后需要对其进行处理以定位搜索条件(有时称为 n-grams,https://en.wikipedia.org/wiki/n-gram)。在一个典型的文档中找到这些 n-gram 中的每一个元素都需要发送到包含许多索引元素的索引器。因此,文档标识符与可搜索文档中的每个术语(或 n-gram)相关联,所有这一切都是因为用户进行了写操作或创建了文档。每个文档都需要做大量的工作,而且还有很多很多的文档。

数据的规范化
在关系数据库的世界里,一般要在数据库中保存规范化数据,努力避免更新异常被认为是极其重要的。大多数系统的分布式趋势在增强,其中大多数都有包含其数据的键值对,这些键值对是为了扩展分片使用的。通过将相关数据分组为一个键值对,很容易获取这个值 ,然后发出请求到远程系统。
如果规范化这个大型分片系统中的数据,规范化的值将可能不会在同一个分片上,执行分布式联接比执行集中式联接更加烦人。
为了解决这个问题,一般在数据上加上版本号,方案虽然并不完美,但比起分布式通信或者跨非规范化数据进行大规模更新,它的挑战性要小得多。大规模的分布式系统对一致读的语义施加了很大的压力,这反过来可以被看作是写入放大和读读成本之间的紧张关系。
一句话小结
随着分布式系统的普遍化,数据系统的读写权衡越来越关键,辨认系统中数据读写的使用模式,才能进行设计上的权衡和优化。
【关联阅读】
以上是关于数据系统读写权衡的一知半解的主要内容,如果未能解决你的问题,请参考以下文章