反思|Android 列表分页组件Paging的设计与实现:架构设计与原理解析
Posted 却把清梅嗅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了反思|Android 列表分页组件Paging的设计与实现:架构设计与原理解析相关的知识,希望对你有一定的参考价值。
本文是android Jetpack Paging系列的第二篇文章;强烈建议 读者将本系列作为学习Paging 阅读优先级最高的文章,如果读者对Paging还没有系统性的认识,请参考:
前言
Paging是一个非常优秀的分页组件,与其它热门的分页相关库不同的是,Paging更偏向注重服务于 业务 而非 UI 。——我们都知道业务类型的开源库的质量非常依赖代码 整体的架构设计(比如Retofit和OkHttp);那么,如何说服自己或者同事去尝试使用Paging?显然源码中蕴含的优秀思想更具有说服力。
反过来说,若从Google工程师们设计、研发和维护的源码中有所借鉴,即使不在项目中真正使用它,自己依然能受益匪浅。
本文章节如下:
架构设计与原理解析
1、通过建造者模式进行依赖注入
创建流程毫无疑问是架构设计中最重要的环节。
作为组件的门板,向外暴露的API对于开发者越简单友善方便调用越好,同时,作为API调用者的我们也希望框架越灵活,可配置选项越多越好。
这听起来似乎有点违反常理—— 如何才能保证既保证 简单干净的接口设计 易于开发者上手,同时又有 足够多的可配置项 保证框架的灵活呢?
Paging的API设计中使用了经典的 建造者(Builder)模式,并通过依赖注入将依赖一层层向下传递,最终依次构建了各个层级的对象实例。
对于开发者而言,只需要配置自己关心的参数,而不关心(甚至可以是不知道)的参数配置,全交给Builder类使用默认参数:
// 你可以这样复杂地配置
val pagedListLiveData =
LivePagedListBuilder(
dataSourceFactory,
PagedList.Config.Builder()
.setPageSize(PAGE_SIZE) // 分页加载的数量
.setInitialLoadSizeHint(20) // 初始化加载的数量
.setPrefetchDistance(10) // 预加载距离
.setEnablePlaceholders(ENABLE_PLACEHOLDERS) // 是否启用占位符
.build()
).build()
// 也可以这样简单地配置
val pagedListLiveData =
LivePagedListBuilder(dataSourceFactory, PAGE_SIZE).build()
需要注意的是,分页相关功能配置对象的构建 和 可观察者对象的构建 是否是两个不同的职责?显然是有必要的,因为:
LiveData<PagedList>=DataSource+PagedList.Config(即 分页数据的可观察者 = 数据源 + 分页配置)
因此,这里Paging的配置使用到了2个Builder类,即使是决定使用 建造者模式 ,设计者也需要对Builder类的定义有一个清晰的认知,这里也是设计过程中 单一职责原则 的优秀体现。
最终,Builder中的所有配置都通过依赖注入的方式对PagedList进行了实例化:
// PagedList.Builder.build()
public PagedList<Value> build()
return PagedList.create(
mDataSource,
mNotifyExecutor,
mFetchExecutor,
mBoundaryCallback,
mConfig,
mInitialKey);
// PagedList.create()
static <K, T> PagedList<T> create(@NonNull DataSource<K, T> dataSource,
@NonNull Executor notifyExecutor,
@NonNull Executor fetchExecutor,
@Nullable BoundaryCallback<T> boundaryCallback,
@NonNull Config config,
@Nullable K key)
// 这里我们仅以ContiguousPagedList为例
// 可以看到,所有PagedList都是将构造函数的依赖注入进行的实例化
return new ContiguousPagedList<>(contigDataSource,
notifyExecutor,
fetchExecutor,
boundaryCallback,
config,
key,
lastLoad);
依赖注入 是一个非常简单而又朴实的编码技巧,Paging的设计中,几乎没有用到单例模式,也几乎没有太多的静态成员——所有对象中除了自身的状态,其它所有通过依赖注入的配置项都是 final (不可变)的:
// PagedList.java
public abstract class PagedList<T>
final Executor mMainThreadExecutor;
final Executor mBackgroundThreadExecutor;
final BoundaryCallback<T> mBoundaryCallback;
final Config mConfig;
final PagedStorage<T> mStorage;
// ItemKeyedDataSource.LoadInitialParams.java
public static class LoadInitialParams<Key>
public final Key requestedInitialKey;
public final int requestedLoadSize;
public final boolean placeholdersEnabled;
上文说到 几乎没有用到单例模式,实际上线程切换的设计有些许例外,但其本身依然可以通过
Builder进行依赖注入以覆盖默认的线程获取逻辑。
通过 依赖注入 保证了对象的实例所需依赖有迹可循,类与类之间的依赖关系非常清晰,而实例化的对象内部 成员的不可变 也极大保证了PagedList分页数据的线程安全。
2、构建懒加载的LiveData
对于被观察者而言,只有当真正被订阅的时候,其数据的更新才有意义。换句话说,当开发者构建出一个LiveData<PagedList>时候,这时立即通过后台线程开始异步请求分页数据是没有意义的。
反过来理解,若没有订阅就请求数据,当真正订阅的时候,
DataSource中的数据已经过时了,这时还需要重新请求拉取最新数据,这样之前的一系列行为就没有意义了。
真正的请求应该放在LiveData.observe()的时候,即被订阅时才去执行,笔者这里更偏向于称其为“懒加载”——如果读者对RxJava比较熟悉的话,会发现这和Observable.defer()操作符概念比较相似:
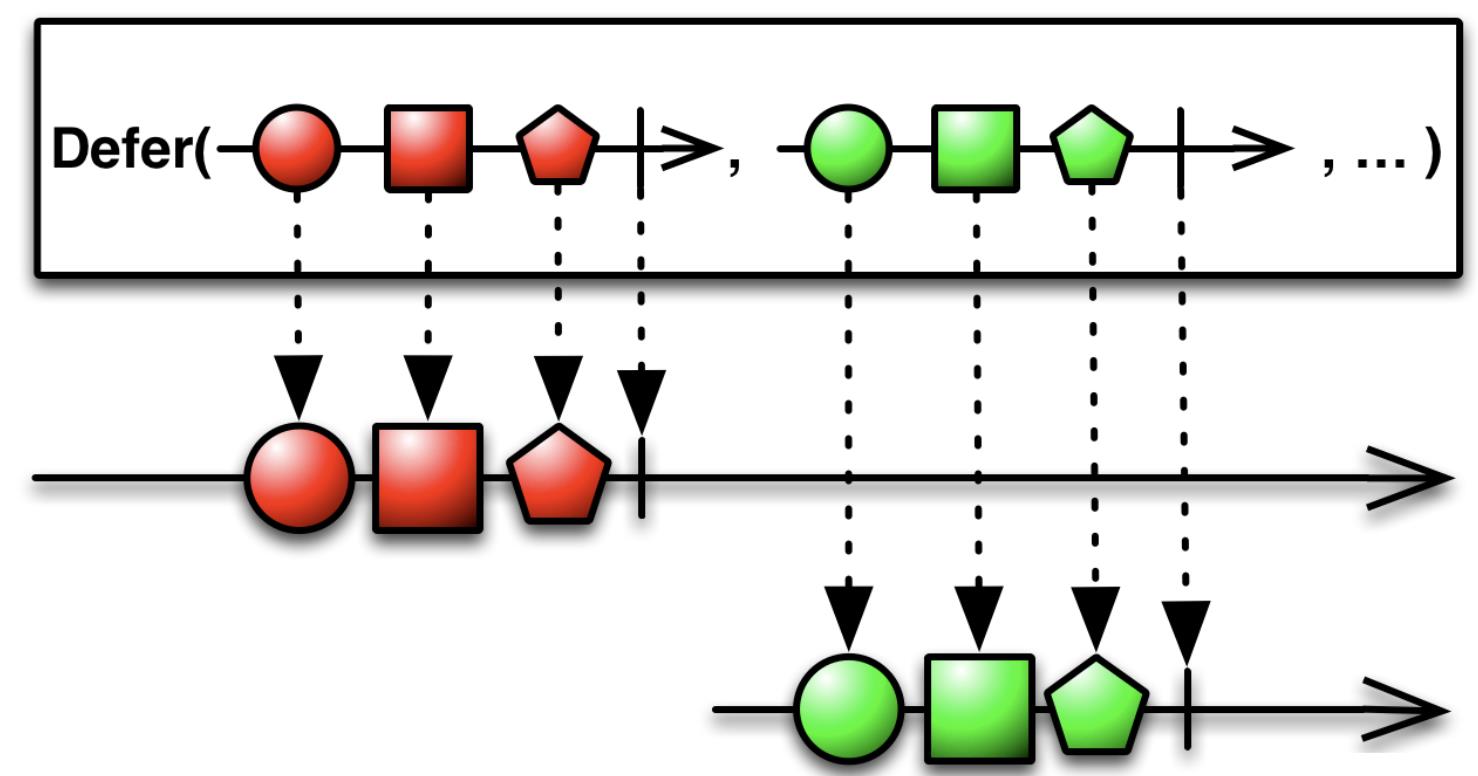
那么,如何构建“懒加载”的LiveData<PagedList>呢?Google的设计者使用了ComputableLiveData类对LiveData的数据发射行为进行了包装:
// @hide
public abstract class ComputableLiveData<T>
这是一个隐藏的类,开发者一般不能直接使用它,但它被应用的地方可不少,Room组件生成的源码中也经常可以看到它的身影。
用一句话描述ComputableLiveData的定义,笔者觉得 LiveData的数据源 比较适合,感兴趣的读者可以仔细研究一下它的源码,笔者有机会会为它单独开一篇文章,这里不继续展开。
总之,通过ComputableLiveData类,Paging实现了订阅时才执行异步任务的功能,更大程度上减少了做无用功的情况。
3、为分页数据赋予生命周期
分页数据PagedList理应也有属于自己的生命周期。
正常的生命周期内,PagedList不断从DataSource中尝试加载分页数据,并展示出来;但数据源中的数据总有过期失效的时候,这意味着PagedList生命周期走到了尽头。
Paging需要响应式地创建一个新的DataSource数据快照以及新的PagedList,然后交给PagedListAdapter更新在UI上。
为此,PagedList类中增加了对应的一个mDetached字段:
public abstract class PagedList<T> extends AbstractList<T>
//...
private final AtomicBoolean mDetached = new AtomicBoolean(false);
public boolean isDetached()
return mDetached.get();
public void detach()
mDetached.set(true);
这个AtomicBoolean类型的字段是有意义的:我们知道PagedList对分页数据的加载是异步的,因此尝试加载下一页数据时,若此时mDetached.get()为true,意味着此时的分页数据已经失效,因此异步的分页请求任务不再需要被执行:
class ContiguousPagedList<K, V> extends PagedList<V>
//...
public void onPagePlaceholderInserted(final int pageIndex)
mBackgroundThreadExecutor.execute(new Runnable()
@Override
public void run()
// 不再异步加载分页数据
if (isDetached())
return;
// 若数据源失效,则将mDetached.set(true)
if (mDataSource.isInvalid())
detach();
else
// ... 加载下页数据
);
通过上述代码片段读者也可以看到,PagedList的生命周期是否失效,则依赖DataSource的isInvalid()函数,这个函数表示当前的DataSource数据源是否失效:
public abstract class DataSource<Key, Value>
private AtomicBoolean mInvalid = new AtomicBoolean(false);
private CopyOnWriteArrayList<InvalidatedCallback> mOnInvalidatedCallbacks =
new CopyOnWriteArrayList<>();
// 通知数据源失效
public void invalidate()
if (mInvalid.compareAndSet(false, true))
for (InvalidatedCallback callback : mOnInvalidatedCallbacks)
// 数据源失效的回调函数,通知上层创建新的PagedList
callback.onInvalidated();
// 数据源是否失效
public boolean isInvalid()
return mInvalid.get();
当数据源DataSource失效时,则会通过回调函数,通知上文我们提到的ComputableLiveData<T>创建新的PagedList,并通知给LiveData的观察者更新在UI上。
因此,PagedList作为分页数据,DataSource作为数据源,ComputableLiveData<T>作为PagedList的创建和分发者三者形成了一个闭环:

4、提供Room的响应式支持
我们知道Paging原生提供了对Room组件的响应式支持,当数据库数据发生了更新,Paging能够响应到并自动构建新的PagedList,然后更新到UI上。
这似乎是一个神奇的操作,但原理却十分简单,上一小节我们知道,DataSource调用了invalidate()函数时,意味着数据源失效,DataSource会通过回调函数重新构建新的PagedList。
Room组件也是根据这个特性额外封装了一个新的DataSource:
public abstract class LimitOffsetDataSource<T> extends PositionalDataSource<T>
protected LimitOffsetDataSource(...)
// 1.定义一个"命令数据源失效"的回调函数
mObserver = new InvalidationTracker.Observer(tables)
@Override
public void onInvalidated(@NonNull Set<String> tables)
invalidate();
;
// 2.为数据库的失效跟踪器(InvalidationTracker)配置观察者
db.getInvalidationTracker().addWeakObserver(mObserver);
这之后,每当数据库中数据失效,都会自动执行DataSource.invalidate()函数。
现在读者回顾最初学习Paging的时候,Room中开发者定义的Dao类,返回的DataSource.Factory到底是怎样的一个对象?
@Dao
interface RedditPostDao
@Query("SELECT * FROM posts WHERE subreddit = :subreddit ORDER BY indexInResponse ASC")
fun postsBySubreddit(subreddit : String) : DataSource.Factory<Int, RedditPost>
答案不言而喻,正是LimitOffsetDataSource的工厂类:
@Override
public DataSource.Factory<Integer, RedditPost> postsBySubreddit(final String subreddit)
return new DataSource.Factory<Integer, RedditPost>()
// 返回能够响应数据库数据失效的 LimitOffsetDataSource
@Override
public LimitOffsetDataSource<RedditPost> create()
return new LimitOffsetDataSource<RedditPost>(__db, _statement, false , "posts")
// ....
原理上讲,这些代码平淡无奇,但设计者通过注解的一层封装,大幅简化了开发者的代码量。对于开发者而言,只需要配置一个接口,而无需去了解内部的代码实现细节。
中场:更多的困惑
上一篇文章中对DataSource进行了简单的介绍,很多朋友反应DataSource这一部分的源码过于晦涩,对于DataSource的选择也是懵懵懂懂。
复杂问题的解决依赖于问题的切割细分,本文将其细分成以下2个小问题,并进行一一探讨:
- 1、为什么设计出这么多的
DataSource和其子类,它们的使用场景各是什么? - 2、为什么设计出这么多的
PagedList和其子类?
5、数据源的连续性与分页加载策略
为什么设计出这么多的
DataSource和其子类,它们的使用场景各是什么?
Paging分页组件的设计中,DataSource是一个非常重要的模块。顾名思义,DataSource<Key, Value>中的Key对应数据加载的条件,Value对应数据集的实际类型, 针对不同场景,Paging的设计者提供了几种不同类型的DataSource实现类:
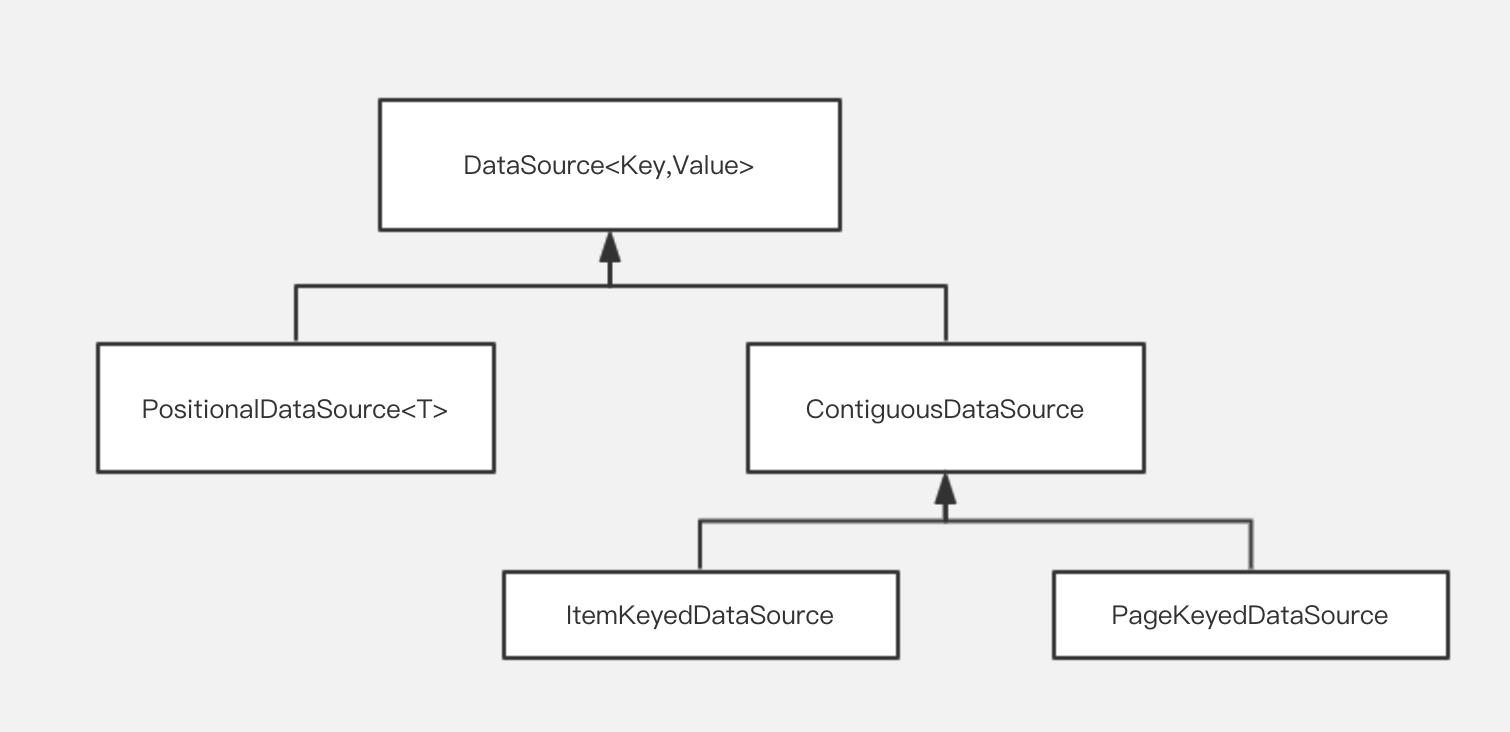
关于这些DataSource的介绍,请参考上一篇文章的这一小节,本文不再赘述。
第一次阅读这一部分源码时,笔者最困惑的是,ContiguousDataSource和PositionalDataSource的区别到底是什么呢?
翻阅过源码的读者也许曾经注意到,DataSource有这样一个抽象函数:
public abstract class DataSource<Key, Value>
// 数据源是否是连续的
abstract boolean isContiguous();
class ContiguousDataSource<Key, Value> extends DataSource<Key, Value>
// ContiguousDataSource 是连续的
boolean isContiguous() return true;
class PositionalDataSource<T> extends DataSource<Integer, T>
// PositionalDataSource 是非连续的
boolean isContiguous() return false;
那么,数据源的连续性 到底是什么概念?
对于一般的网络分页加载请求而言,下一页的数据总是需要依赖上一页的加载,这种时候,我们通常称之为 数据源是连续的 —— 这似乎毫无疑问,这也是ItemKeyedDataSource和PageKeyedDataSource被广泛使用的原因。
但有趣的是,在 以本地缓存作为分页数据源 的业务模型下,这种 分页数据源应该是连续的 常识性的认知被打破了。
每个手机都有通讯录,因此本文以通讯录APP为例,对于通讯录而言,所有数据取自于本地持久层,而考虑到手机内也许会有成千上万的通讯录数据,APP本身列表数据也应该进行分页加载。
这种情况下,分页数据源是连续的吗?
读者仔细思考可以得知,这时分页数据源 一定不能是连续的 。诚然,对于滑动操作而言,数据的连续分页请求没有问题,但是当用户从通讯录页面的侧边点击Z字母,尝试快速跳转Z开头的用户时,分页数据请求的连续性被打破了:
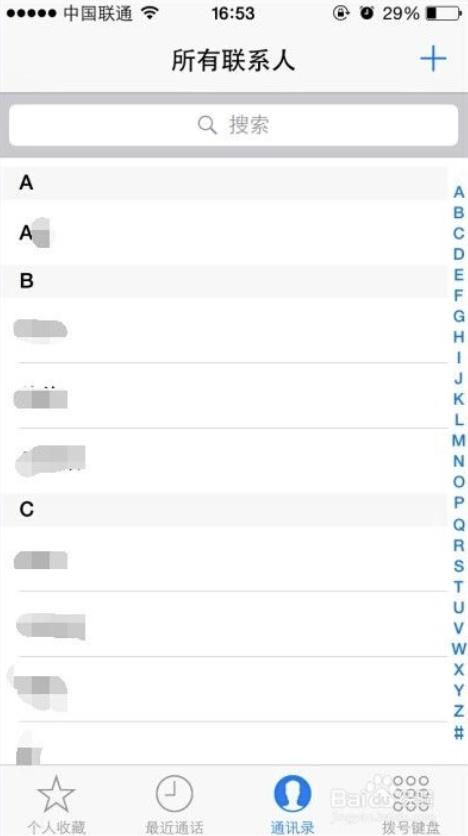
这便是PositionalDataSource的使用场景:通过特定的位置加载数据,这里Key是Integer类型的位置信息,每一条分页数据并不依赖上一条分页数据,而是依赖数据所处数据源本身的位置(Position)。
分页数据的连续性 是一个十分重要的概念,理解了这个概念,读者也就能理解DataSource各个子类的意义了:
无论是PositionalDataSource、ItemKeyedDataSource还是PageKeyedDataSource,这些类都是不同的 分页加载策略。开发者只需要根据不同业务的场景(比如 数据的连续性),选择不同的 分页加载策略 即可。
6、分页数据模型与分页数据副本
为什么设计出这么多的
PagedList和其子类?
和DataSource相似,PagedList同样拥有一个isContiguous()接口:
public abstract class PagedList<T> extends AbstractList<T>
abstract boolean isContiguous();
class ContiguousPagedList<K, V> extends PagedList<V>
// ContiguousPagedList 内部持有 ContiguousDataSource
final ContiguousDataSource<K, V> mDataSource;
boolean isContiguous() return true;
class TiledPagedList<T> extends PagedList<T>
// TiledPagedList 内部持有 PositionalDataSource
final PositionalDataSource<T> mDataSource;
boolean isContiguous() return false;
读者应该理解,PagedList内部持有一个DataSource,而 分页数据加载 的行为本质上是从DataSource中异步获取数据—— 在分页数据请求的过程中,不同的DataSource也会有不同的参数需求,从而导致PagedList内部的行为也不尽相同;因此PagedList向下导出了ContiguousPagedList和TiledPagedList类,用于不同业务情况的分页请求处理。
那么SnapshotPagedList又是一个什么类呢?
PagedList额外有一个snapshot()接口,以返回当前分页数据的快照:
public abstract class PagedList<T> extends AbstractList<T>
public List<T> snapshot()
return new SnapshotPagedList<>(this);
这个snapshot()函数非常重要,其用于保存分页数据的前一个状态,并且用于AsyncPagedListDiffer进行数据集的差异性计算,新的PagedList到来时(通过PagedListAdapter.submitList()),并未直接进行数据的覆盖和差异性计算,而是先对之前PagedList中的数据集进行拷贝。
篇幅原因不详细展示,有兴趣的读者可以自行阅读
PagedListAdapter.submitList()相关源码。
接下来简单了解下SnapshotPagedList内部的实现:
class SnapshotPagedList<T> extends PagedList<T>
SnapshotPagedList(@NonNull PagedList<T> pagedList)
// 1.这里我们看到,其它对象都没有改变堆内地址的引用
// 除了 pagedList.mStorage.snapshot(),最终执行 -> 2
super(pagedList.mStorage.snapshot(),
pagedList.mMainThreadExecutor,
pagedList.mBackgroundThreadExecutor,
null,
pagedList.mConfig);
mDataSource = pagedList.getDataSource();
mContiguous = pagedList.isContiguous();
mLastLoad = pagedList.mLastLoad;
mLastKey = pagedList.getLastKey();
final class PagedStorage<T> extends AbstractList<T>
PagedStorage(PagedStorage<T> other)
// 2.对当前分页数据进行了一次拷贝
mPages = new ArrayList<>(other.mPages);
此外,mSnapshot还用于状态的保存,当差异性计算未执行完毕时,若此时开发者调用getCurrentList()函数,则会尝试将mSnapshot——即之前数据集的副本进行返回,有兴趣的读者可以研究一下。
7、线程切换与Paging设计中的"Bug"
Google的工程师们设计Paging的初衷就希望能够让开发者 无感知地进行线程切换 ,因此大部分线程切换的代码都封装在内部:
public class ArchTaskExecutor extends TaskExecutor
// 主线程的Executor
private static final Executor sMainThreadExecutor = new Executor()
@Override
public void execute(Runnable command)
getInstance().postToMainThread(command);
;
// IO线程的Executor
private static final Executor sIOThreadExecutor = new Executor()
@Override
public void execute(Runnable command)
getInstance().executeOnDiskIO(command);
;
有兴趣的读者可以研究ArchTaskExecutor内部的源码,其内部sMainThreadExecutor原理依然是通过Looper.getMainLooper()创建对应的Handler并向主线程发送消息,本文不赘述。
源码的设计者希望,使用Paging的开发者能够在执行数据的分页加载任务时,内部切换到IO线程,而分页数据加载成功后,则内部切换回到主线程更新UI。
从设计上讲,这是一个非常优秀的设计,但是开发者真正使用时,却很难注意到DataSource中对数据加载的回调方法,本身就是执行在IO线程的:
public abstract class PositionalDataSource<T> extends DataSource<Integer, T>
// 通过注解提醒开发者回调在子线程
@WorkerThread
public abstract void loadInitial(...);
@WorkerThread
public abstract void loadRange(...);
回调本身在子线程执行,意味着,开发者对分页数据的加载最好不要使用异步方法,否则很可能出问题。
对于OkHttp的使用者而言,开发者应该使用execute()同步方法:
override fun loadInitial(..., callback: LoadInitialCallback<RedditPost>)
// 使用同步方法
val response = request.execute()
callback.onResult(...)
对于
RxJava而言,则应该使用blocking相关的方法进行阻塞操作。
如果说PositionalDataSource还有@WorkerThread提醒,那么另外的ItemKeyedDataSource和PageKeyedDataSource干脆就没有@WorkerThread注解:
public abstract class ItemKeyedDataSource<Key, Value> extends ContiguousDataSource<Key, Value>
public abstract void loadInitial(...);
public abstract void loadAfter(...);
// PageKeyedDataSource也没有`WorkerThread`注解,不赘述
因此如果没有注意到这些细节,开发者很可能误入歧途,从而导致未知的一些问题,对此,开发者可以尝试参考Google这个示例代码。
奇怪的是,即使是Google官方的代码示例中,对于loadInitial和loadAfter两个函数,也只有loadInitial中使用了同步方法进行请求,而loadAfter中依然是使用enqueue()进行异步请求。尽管注释中明确声明了这点,但笔者还是无法理解这种行为,因为这的确有可能令一些开发者误入歧途。
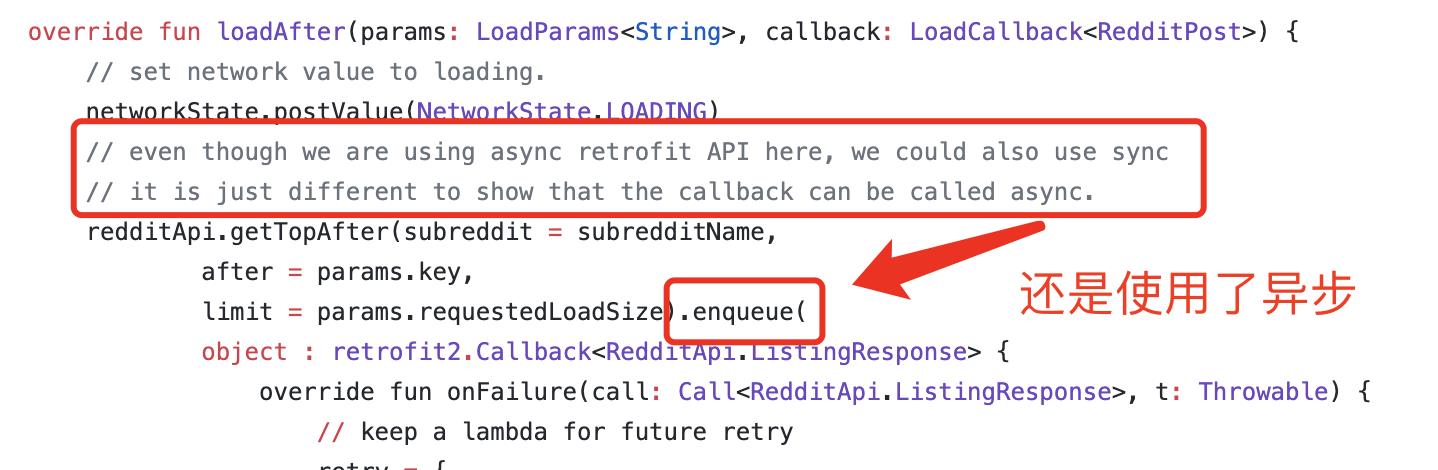
总之,Paging的设计中,其初衷将线程切换的实现细节进行隐藏是好的,但是结果的确没有达到很好的效果,相反还有可能导致错误的理解和使用(笔者踩坑了)。
也许线程切换不交给内部的默认参数去实现(尤其是不要交给Builder模式去配置,这太容易被忽视了),而是强制要求交给开发者去指定更好?
欢迎有想法的朋友在本文下方留言,思想的交流会更容易让人进步。
总结
本文对Paging的原理实现进行了系统性的讲解,那么,Paging的架构设计上,到底有哪些优点值得我们学习?
首先,依赖注入。Paging内部所有对象的依赖,包括配置参数、内部回调、线程切换,绝大多数都是通过依赖注入进行的,简单 且 朴实 ,类与类之间的依赖关系皆有迹可循。
其次,类的抽象和将不同业务的下沉,DataSource和PagedList分工明确,并向上抽象为一个抽象类,并将不同业务情况下的分页逻辑下沉到各自的子类中去。
最后,明确对象的边界:设计分页数据的生命周期,当数据源无效时,避免执行无效的异步分页任务;使用 懒加载的LiveData ,保证未订阅时不执行分页逻辑。
参考 & 更多
如果对Paging感兴趣,欢迎阅读笔者更多相关的文章,并与我一起讨论:
关于我
Hello,我是 却把清梅嗅 ,如果您觉得文章对您有价值,欢迎 ❤️,也欢迎关注我的 博客 或者 Github。
如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?
以上是关于反思|Android 列表分页组件Paging的设计与实现:架构设计与原理解析的主要内容,如果未能解决你的问题,请参考以下文章