案例:缺陷状态数据分析
Posted 麦哲思科技任甲林
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了案例:缺陷状态数据分析相关的知识,希望对你有一定的参考价值。
有网友询问如表1所示的原始数据如何分析,发现问题,我觉得很有代表性,试着分析进行了分析,供大家参考。
表1: 11个项目的缺陷状态原始数据
| 产品名称 | 未解决 | 设计如此 | 重复Bug | 外部原因 | 已解决 | 无法重现 | 延期处理 | 不予解决 | 转为需求 | 总计 |
| A产品 | 148 | 52 | 5 | 62 | 1701 | 20 | 14 | 8 | 8 | 2018 |
| B产品 | 52 | 11 | 1 | 16 | 515 | 12 | 3 | 6 | 0 | 616 |
| C产品 | 31 | 75 | 22 | 40 | 1621 | 37 | 38 | 103 | 33 | 2000 |
| D产品 | 25 | 7 | 0 | 2 | 223 | 2 | 0 | 0 | 1 | 260 |
| E产品 | 13 | 7 | 2 | 4 | 263 | 4 | 5 | 0 | 4 | 302 |
| F产品 | 7 | 2 | 0 | 8 | 269 | 4 | 6 | 3 | 0 | 299 |
| G产品 | 3 | 0 | 0 | 0 | 26 | 0 | 0 | 0 | 0 | 29 |
| H产品 | 0 | 17 | 0 | 3 | 273 | 1 | 4 | 4 | 0 | 302 |
| I产品 | 0 | 0 | 0 | 0 | 98 | 0 | 24 | 0 | 0 | 122 |
| J产品 | 0 | 0 | 4 | 14 | 223 | 4 | 17 | 8 | 0 | 270 |
| K产品 | 0 | 6 | 1 | 8 | 381 | 3 | 22 | 10 | 0 | 431 |
第1步:澄清数据的含义
问:设计如此是指设计缺陷吗?
答:设计如此包含了产品设计如此和技术设计如此。
问:B到J列的数据,没有包含的关系,是可以累加得到最后一列,对吧?
答:是的,B到J列没有包含关系。
问:这11个项目是已经完成的项目,还是当前正在进行的项目?
答:大部分是完成95%的项目。后面就是新的迭代了。
问:不予解决是什么意思?
答:不予解决就是接受这个问题存在。
问:你这个产品是项目级么?
答:产品级。
第2步:对数据做变换
为了确保不同项目之间的数据具有可比性,将绝对的数值,转换为相对的数值。
把每列与合计列相除得到缺陷状态的%,参见表2:
表2: 归一化的数据
| 产品名称 | 问题解决% | 未解决% | 设计% | 重复bug% | 外部原因% | 无法重现% | 延期处理% | 不解决% | 转为需求% |
| A产品 | 0.8429 | 0.0733 | 0.0258 | 0.0025 | 0.0307 | 0.0099 | 0.0069 | 0.0040 | 0.0040 |
| B产品 | 0.8360 | 0.0844 | 0.0179 | 0.0016 | 0.0260 | 0.0195 | 0.0049 | 0.0097 | 0.0000 |
| C产品 | 0.8105 | 0.0155 | 0.0375 | 0.0110 | 0.0200 | 0.0185 | 0.0190 | 0.0515 | 0.0165 |
| D产品 | 0.8577 | 0.0962 | 0.0269 | 0.0000 | 0.0077 | 0.0077 | 0.0000 | 0.0000 | 0.0038 |
| E产品 | 0.8709 | 0.0430 | 0.0232 | 0.0066 | 0.0132 | 0.0132 | 0.0166 | 0.0000 | 0.0132 |
| F产品 | 0.8997 | 0.0234 | 0.0067 | 0.0000 | 0.0268 | 0.0134 | 0.0201 | 0.0100 | 0.0000 |
| G产品 | 0.8966 | 0.1034 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| H产品 | 0.9040 | 0.0000 | 0.0563 | 0.0000 | 0.0099 | 0.0033 | 0.0132 | 0.0132 | 0.0000 |
| I产品 | 0.8033 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.1967 | 0.0000 | 0.0000 |
| J产品 | 0.8259 | 0.0000 | 0.0000 | 0.0148 | 0.0519 | 0.0148 | 0.0630 | 0.0296 | 0.0000 |
| K产品 | 0.8840 | 0.0000 | 0.0139 | 0.0023 | 0.0186 | 0.0070 | 0.0510 | 0.0232 | 0.0000 |
第3步 对数据进行横向或纵向对比分析
该数据表中的产品是同时进行的项目,没有时间的先后顺序数据,所以不做纵行对比分析,可以进行横向对比分析,即对同一时间段的项目进行对比分析。比如可以对问题解决%进行对比分析。对这11个项目可以采用柱状图分析,分析时要先排序:
表3: 排序后的问题解决%
| 产品名称 | 问题解决% |
| I产品 | 0.8033 |
| C产品 | 0.8105 |
| J产品 | 0.8259 |
| B产品 | 0.8360 |
| A产品 | 0.8429 |
| D产品 | 0.8577 |
| E产品 | 0.8709 |
| K产品 | 0.8840 |
| G产品 | 0.8966 |
| F产品 | 0.8997 |
| H产品 | 0.9040 |
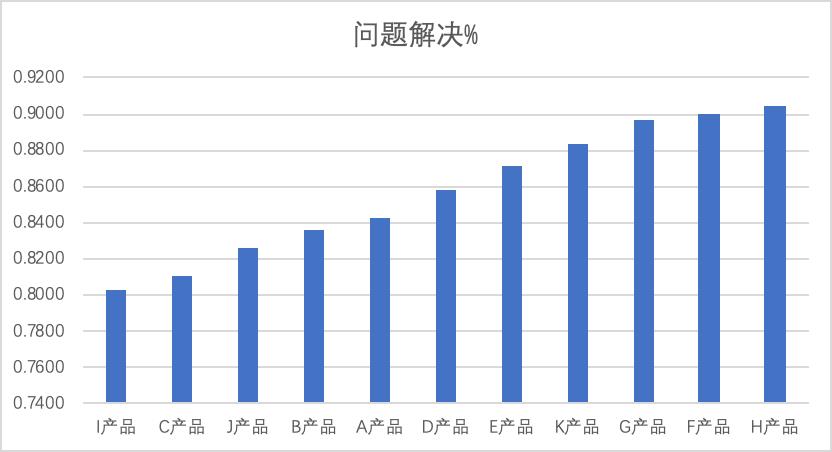
图1 问题解决%的柱状图
对于上图,可以采用80-20的原则,取排名最靠后的2个产品进行原因分析,即为什么产品I或C这2个产品问题解决%那么低?这2个项目未必一定是离群点,只是最低而已。
对于其他度量元依此类推,也可以画柱状图进行分析。
第4步 通过统计的方法识别离群点
采用柱状图、条形图、饼图等是基于经验识别不合理的现象,但是未必很合理,有可能得到的结论是不科学的,此时我们可以借助统计的方法来识别离群点,即识别小概率事件,小概率事件发生的概率很小,是有别于正常事件的,是特殊原因造成的。
对于本组数据,我们可以画箱线图来识别离群点。

图3 Minitab中问题解决%的箱线图
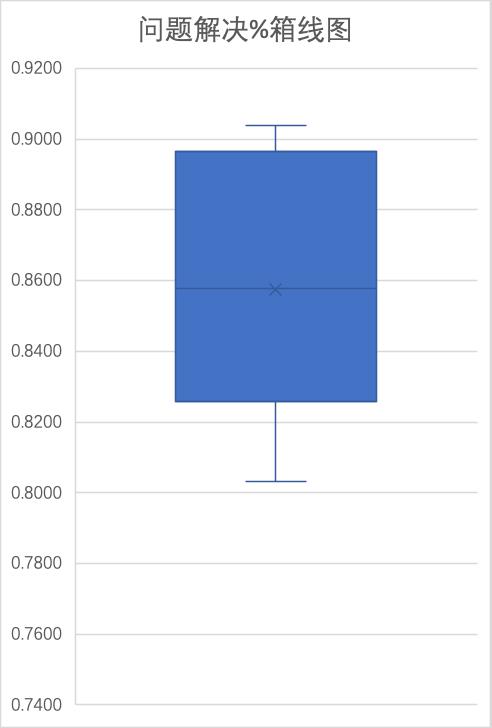
图4 Excel中问题解决%的箱线图
对该度量元没有发现离群点,但是如果我们对其他度量元也进行分析:
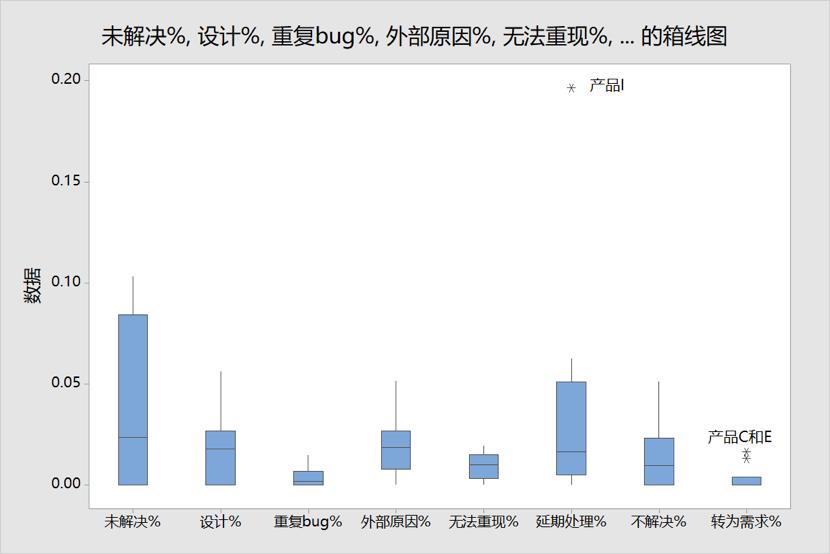
图5 Minitab中对多个度量元进行箱线图分布分析
则我们发现产品I的延期处理%是离群点,产品C和E的转为需求%是离群点,对这3个项目应该进行原因分析!是另类的产品!
Minitab是专业的统计分析工具,简单易用,比EXCEL功能强大。
第5步 分析数据之间的相关性
分析相关性是为了识别因果规律,原因决定了结果。
可以通过散点图观察两个变量之间的相关性,对于本组数据,如果我们画出无法重现%与外部原因%的散点图,得到图6:
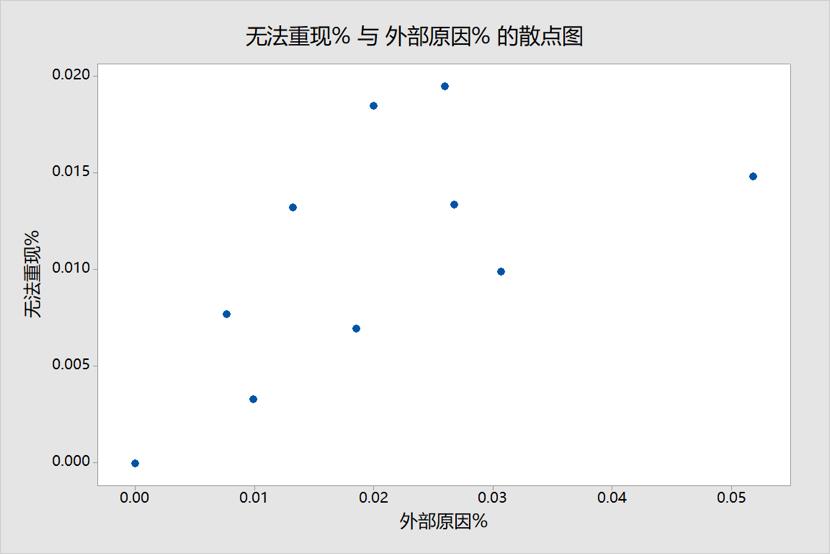
图6: 无法重现% 与 外部原因% 的散点图
观察上图,可以发现随着外部原因%的增加,无法重现%也是增加的,二者是正相关的!意味着很可能二者之间有因果关系,或者它们都是因另外一个因子影响而同步变化的!具体是哪种情况,需要继续和组织或产品组进行更多的沟通才能判定。
更准确的判断是否两个数据之间存在相关性可以在Minitab中计算相关性系数,进行相关性的假设检验,对上述数据,相关性检验的结果如下:
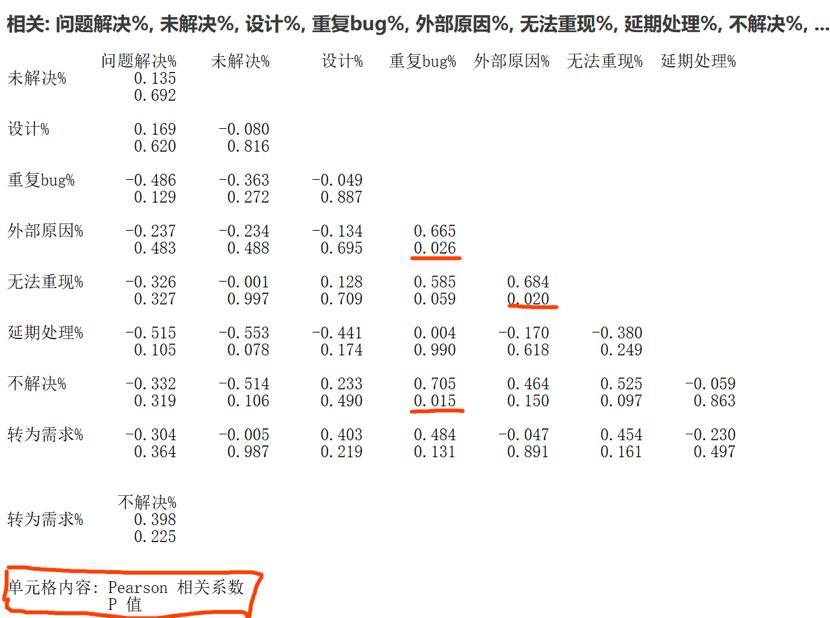
图7 相关性分析结果
当P值小于0.05时,可以认为这2个变量是相关的。我们找到了3对相关的度量元:
外部原因% 与 重复bug%
外部原因% 与 无法重现bug%
不解决% 与 重复Bug%
由于本组数据样本点比较少,我们还需要仔细看看散点图是否真的相关。通过图6的观察与相关性检验的结果,我们可以认可外部原因%与无法重现bug%是中度相关的,相关性系数为0.684。
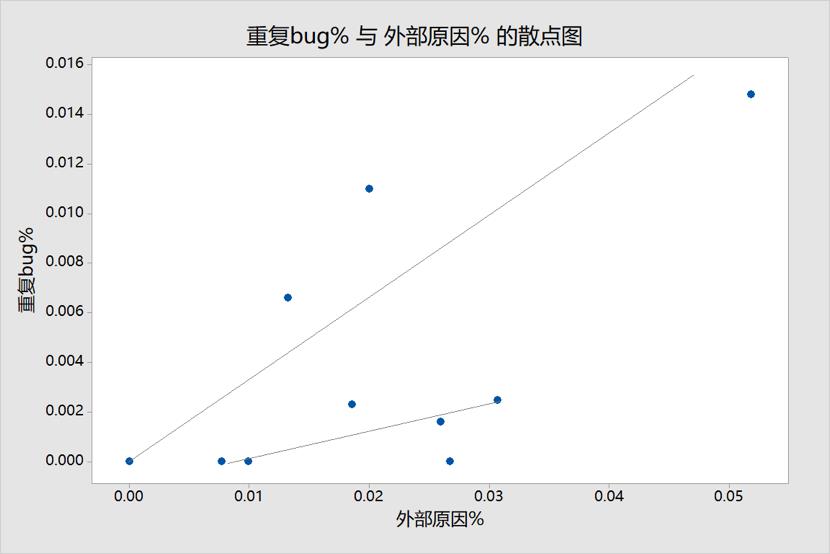
图8 重复bug%与外部原因%的散点图
仔细观察图8,隐隐的有2个趋势在里面,由于样本点少,不能轻易下结论,需要再采集数据,再观察。
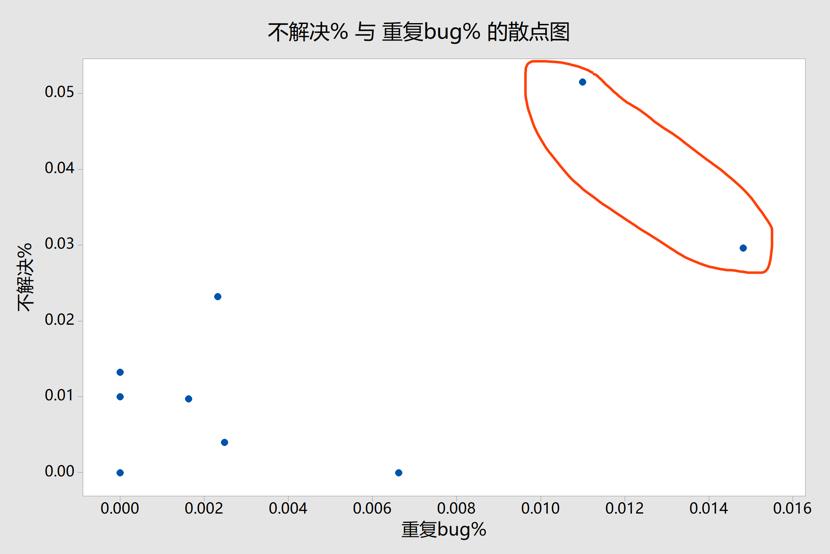
图9 不解决%与重复bug %的散点图
仔细观察图9,红圈中的样本点如果删除,相关趋势是否还那么明显呢?
该组数据只有11个点,相关性的趋势不是特别明显,需要再继续采集数据,不好轻易下结论。
综述:
1 简单的数据分析可以只做到第3步,并非要做第4、5步。
2 根据图8,我们怀疑存在2类项目,但是原始数据中没有给出每个项目的特征,比如是否新产品,采用的是迭代还是瀑布的生命周期模型,所以我们无法进行分类分析。
3 第4步中,如果数据记录了发生的先后顺序,我们也可以通过控制图的方法识别离群点。
4 样本点多了,数据的分布规律与因果规律才是规律,不是偶然。
5 如果再有各产品的规模数据(比如功能点数),就可以做产品间的质量水平对比,或算出各类bug缺陷密度的基准区间,比如延期处理的bug单位功能点有多少个是合理的。
以上是关于案例:缺陷状态数据分析的主要内容,如果未能解决你的问题,请参考以下文章