双目深度算法——基于Transformer的方法(STTR)
Posted Leo-Peng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了双目深度算法——基于Transformer的方法(STTR)相关的知识,希望对你有一定的参考价值。
双目深度算法——基于Transformer的方法(STTR)
双目深度算法——基于Transformer的方法(STTR)
STTR是STereo TranformeR的缩写,原论文名为《Revisiting Stereo Depth Estimation From a Sequence-to-Sequence Perspectivewith Transformers》,发表于2021年,据我了解这应该是第一篇使用Transformer进行双目视差估计的方法,打破了基于Correlation或者Cost Volume进行视差估计的方法论,在论文的摘要中,作者提到该方法主要有三大优势:(1)解放了视差的限制;(2)明确定义了遮挡区域;(3)保证了匹配的唯一性,这篇文章实验做得非常充分,开源代码也些得很好,下面我们结合代码和文中的实验来详细学习下这篇论文。
1. 网络构架
网络整体结果如下图所示,主要包括三部分:Feature Extractor、Transformer和Context Adjustment Layer,其中Feature Extractor主要用于特征提取,Transformer通过Attention计算视差,Context Adjustment Layer用于后处理。
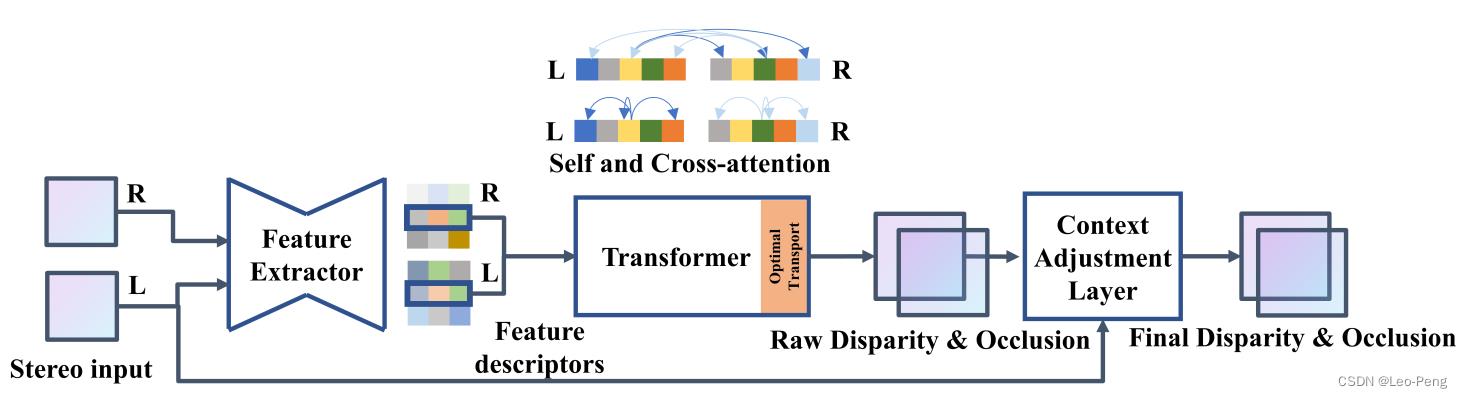
在STTR的代码中也对应地将网络抽象为几部分:
def forward(self, x: NestedTensor):
"""
:param x: input data
:return:
a dictionary object with keys
- "disp_pred" [N,H,W]: predicted disparity
- "occ_pred" [N,H,W]: predicted occlusion mask
- "disp_pred_low_res" [N,H//s,W//s]: predicted low res (raw) disparity
"""
bs, _, h, w = x.left.size()
# extract features
feat = self.backbone(x) # concatenate left and right along the dim=0
tokens = self.tokenizer(feat) # 2NxCxHxW
pos_enc = self.pos_encoder(x) # NxCxHx2W-1
# separate left and right
feat_left = tokens[:bs]
feat_right = tokens[bs:] # NxCxHxW
# downsample
if x.sampled_cols is not None:
feat_left = batched_index_select(feat_left, 3, x.sampled_cols)
feat_right = batched_index_select(feat_right, 3, x.sampled_cols)
if x.sampled_rows is not None:
feat_left = batched_index_select(feat_left, 2, x.sampled_rows)
feat_right = batched_index_select(feat_right, 2, x.sampled_rows)
# transformer
attn_weight = self.transformer(feat_left, feat_right, pos_enc)
# regress disparity and occlusion
output = self.regression_head(attn_weight, x)
return output
其中backbone为encoder部分,tokenizer为decoder部分。
1.1 Feature Extractor
Feature Extractor主要分为Encoder和Decoder两部分,其中Encoder部分使用的是类似Hourglass的结构,在Decoder部分使用的是转置卷积和Dense Block,特征提取的网络结构就不在此展开,其主要作用就是从原始的图像输入中提取图像特征,特征图大小和原始图像大小相同,但是每个像素变成了一个长为 C e C_e Ce的特征向量。
尽管论文中是讲,基于Transformer的网络结构没有视差的限制,但是由于特征提取使用的CNN网络,因此计算Self Attention和Cross Attention使用的特征向量还是从图像的一个局部区域(感受野)抽象出来的。
1.2 Transformer
Transformer部分结构如下图所示:
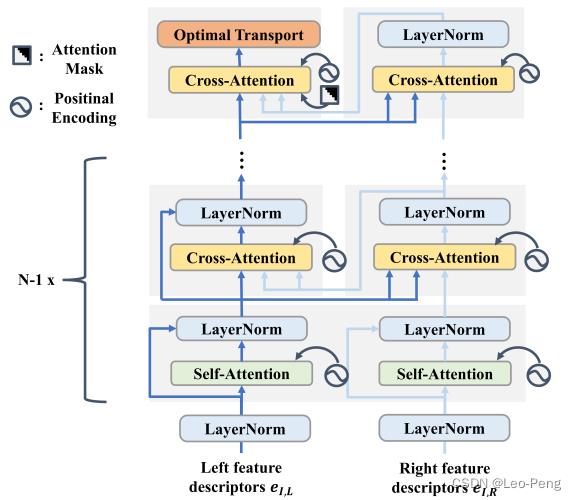
这种反复叠加Self-Attention和Cross-Attention的机制是参考的特征匹配算法SuperGlue,对该算法不熟悉的同学可以参考视觉SLAM总结——SuperPoint / SuperGlue,在该算法的论文中提到,使用这种反复叠加的机制的目的是模仿人类在完成此类任务时的行为,我们寻找两幅图像上相似的像素点时也是先在其中一幅图像上对比该像素与其他像素的区别,然后再在另一幅图像上去尝试寻找最接近的像素。
本论文使用的是带残差的多头注意力机制,公式如下: Q h = W Q h e I + b Q h \\mathcalQ_h=W_\\mathcalQ_h e_I+b_\\mathcalQ_h Qh=WQheI+bQh K h = W K h e I + b K h \\mathcalK_h=W_\\mathcalK_h e_I+b_\\mathcalK_h Kh=WKheI+bKh V h = W V h e I + b V h \\mathcalV_h=W_\\mathcalV_h e_I+b_\\mathcalV_h Vh=WVheI+bVh α h = softmax ( Q h T K h C h ) \\alpha_h=\\operatornamesoftmax\\left(\\frac\\mathcalQ_h^T K_h\\sqrtC_h\\right) αh=softmax(ChQhTKh) V O = W O Concat ( α 1 V 1 , … , α N h V N h ) + b O V_\\mathcalO=W_\\mathcalO \\text Concat \\left(\\alpha_1 \\mathcalV_1, \\ldots, \\alpha_N_h \\mathcalV_N_h\\right)+b_\\mathcalO VO=WO Concat (α1V1,…,αNhVNh)+bO e I = e I + V O e_I=e_I+\\mathcalV_\\mathcalO eI=eI+VO其中 W Q h , W K h , W V h ∈ R C h × C h , b Q h , b K h , b V h ∈ R C h W_\\mathcalQ_h, W_\\mathcalK_h, W_\\mathcalV_h \\in \\mathbbR^C_h \\times C_h, b_\\mathcalQ_h, b_\\mathcalK_h, b_\\mathcalV_h \\in \\mathbbR^C_h WQh,WKh,WVh∈RCh×Ch,bQh,bKh,bVh∈RCh以及 W O ∈ R C e × C e , b O ∈ R C e W_\\mathcalO \\in \\mathbbR^C_e \\times C_e, b_\\mathcalO \\in \\mathbbR^C_e WO∈RCe×Ce,bO∈RCe,这就是普通的Attention计算公式,我们就不在此赘述,细节不清楚的同学可以参考计算机视觉算法——Transformer学习笔记,作者在实现Attention机制时是因为加入了相对位置编码和注意力掩膜,所以是继承原始pytorch中的MultiheadAttention类重新实现了下,但是这一部分基本的操作是保持不变的:
# project to get qkv
if torch.equal(query, key) and torch.equal(key, value):
# self-attention
q, k, v = F.linear(query, self.in_proj_weight, self.in_proj_bias).chunk(3, dim=-1)
else
...
# reshape
q = q.contiguous().view(w, bsz, self.num_heads