PyTorch - 存储和加载模型
Posted SpikeKing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch - 存储和加载模型相关的知识,希望对你有一定的参考价值。
面试问题:
-
PyTorch的state_dict里面都包含什么?
-
PyTorch有几种模型保存方式,checkpoint和其他方式有什么不同,一般都保存什么?
SAVING AND LOADING MODELS FOR INFERENCE IN PYTORCH
两种保存方式:
- state_dict,torch.nn.modules.module,Module类,是多个类的父类,例如层、优化器等
- state_dict函数,存储parameters和buffers,例如,批归一化的值是buffers
- 全部模型
Net继承于Module,__init__初始化层,forward将层连接起来,输入x,实例化net = Net()
调用优化器optim.SGD,第1个参数是模型的参数,net.parameters()函数,包含当前和子module的参数
torch.save(net.state_dict(), PATH),带名称、epoch、train loss、eval loss,只保存参数,没有保存模型的结构(图)
对于Net实例化,调用load_state_dict()函数,把dict导入进去,使用torch.load(PATH)
保存:
- save -> state_dict
- load -> load_state_dict
调用eval(),将training设置为False,不会保存梯度,也会将require_grad设置为false,同时使用推理模式,例如Dropout、BN层
torch.save(net, PATH),直接保留图结构和参数,直接调用即可,torch.load(PATH)
import torch
import torch.nn as nn
import torch.optim as optim
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
print(net)
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# Specify a path
PATH = "state_dict_model.pt"
# Save
torch.save(net.state_dict(), PATH)
# Load
model = Net()
model.load_state_dict(torch.load(PATH))
model.eval()
# Specify a path
PATH = "entire_model.pt"
# Save
torch.save(net, PATH)
# Load
model = torch.load(PATH)
model.eval()
SAVING AND LOADING A GENERAL CHECKPOINT IN PYTORCH
保存和加载一般的checkpoint
checkpoint保存,调用torch.save(),当epoch % 5 == 0时,调用torch.save(dict, PATH)
常见参数:epoch、model_state_dict、optimizer_state_dict、loss,训练时,非常重要的信息量
torch.load(PATH)加载checkpoint,再赋值
- model.load_state_dict()
- optimizer.load_state_dict()
- epoch
- loss
训练时,尽量按checkpoint方式保存
# Additional information
EPOCH = 5
PATH = "model.pt"
LOSS = 0.4
torch.save(
'epoch': EPOCH,
'model_state_dict': net.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': LOSS,
, PATH)
model = Net()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
checkpoint = torch.load(PATH)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
model.eval()
# - or -
model.train()
SAVING AND LOADING MULTIPLE MODELS IN ONE FILE USING PYTORCH
保存和加载多个模型在一个文件
与保存单个模型的checkpoint类似,将多个模型的参数放入一个大字典,再一起加载,进行处理
PATH = "model.pt"
torch.save(
'modelA_state_dict': netA.state_dict(),
'modelB_state_dict': netB.state_dict(),
'optimizerA_state_dict': optimizerA.state_dict(),
'optimizerB_state_dict': optimizerB.state_dict(),
, PATH)
modelA = Net()
modelB = Net()
optimModelA = optim.SGD(modelA.parameters(), lr=0.001, momentum=0.9)
optimModelB = optim.SGD(modelB.parameters(), lr=0.001, momentum=0.9)
checkpoint = torch.load(PATH)
modelA.load_state_dict(checkpoint['modelA_state_dict'])
modelB.load_state_dict(checkpoint['modelB_state_dict'])
optimizerA.load_state_dict(checkpoint['optimizerA_state_dict'])
optimizerB.load_state_dict(checkpoint['optimizerB_state_dict'])
modelA.eval()
modelB.eval()
# - or -
modelA.train()
modelB.train()
使用docker容器创建环境:
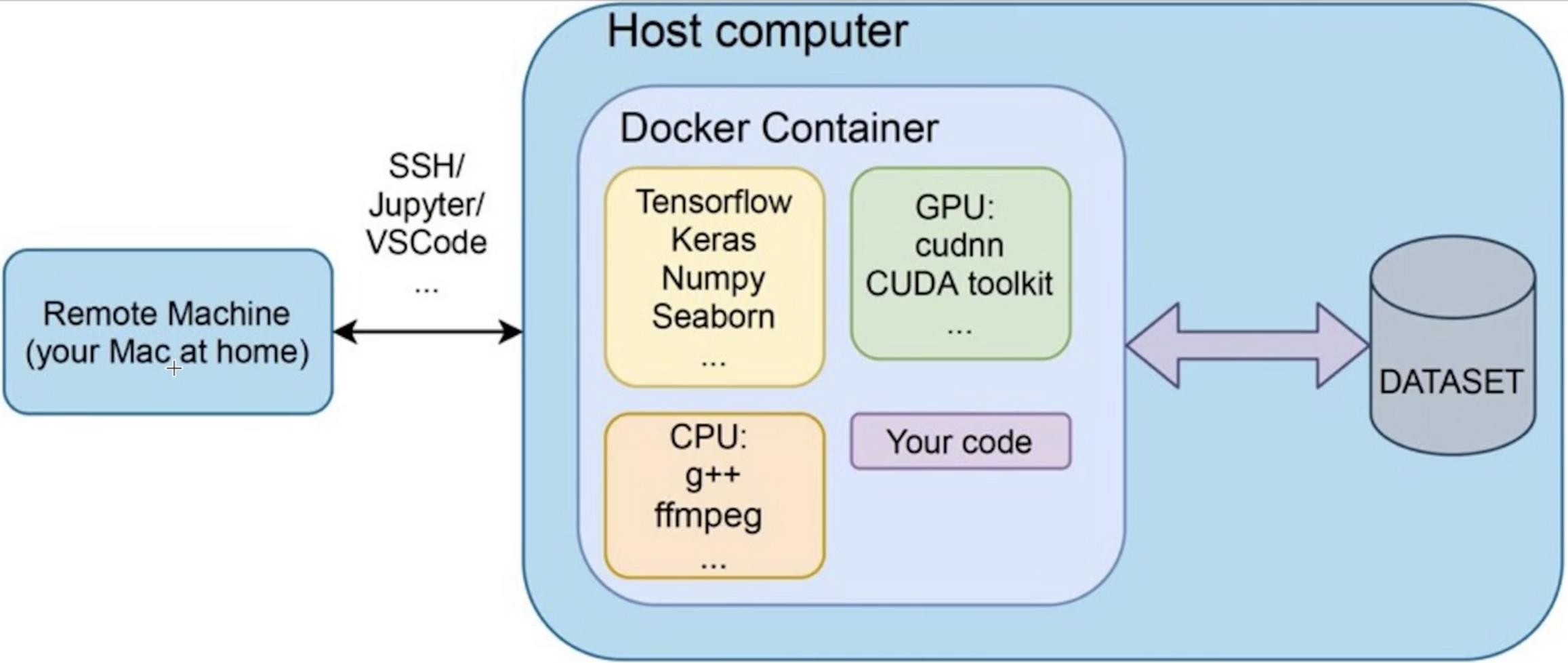
seaborn:https://seaborn.pydata.org/
常用软件:
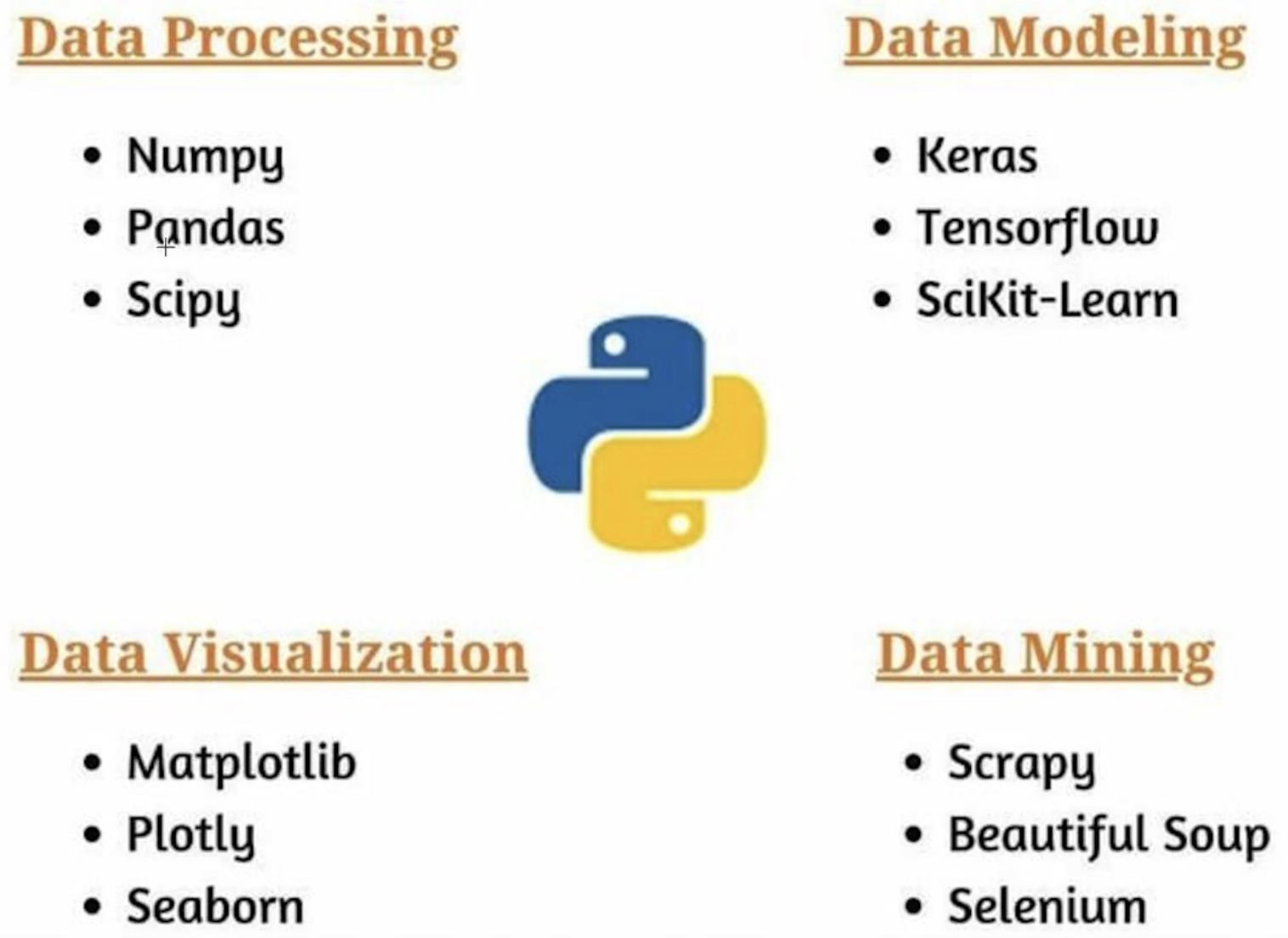
免费的GPU资源:Colaboratory
以上是关于PyTorch - 存储和加载模型的主要内容,如果未能解决你的问题,请参考以下文章