openpcdet之pointpillar代码阅读——第一篇:数据增强与数据处理
Posted 非晚非晚
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了openpcdet之pointpillar代码阅读——第一篇:数据增强与数据处理相关的知识,希望对你有一定的参考价值。
文章目录
pointpillar相关的其它文章链接如下:
1. 数据增强
数据增强部分,相对比较清晰,整体流程如下所示。后续openpcdet也出了一些新的数据增强方法,不过目前本人暂时还没有使用。
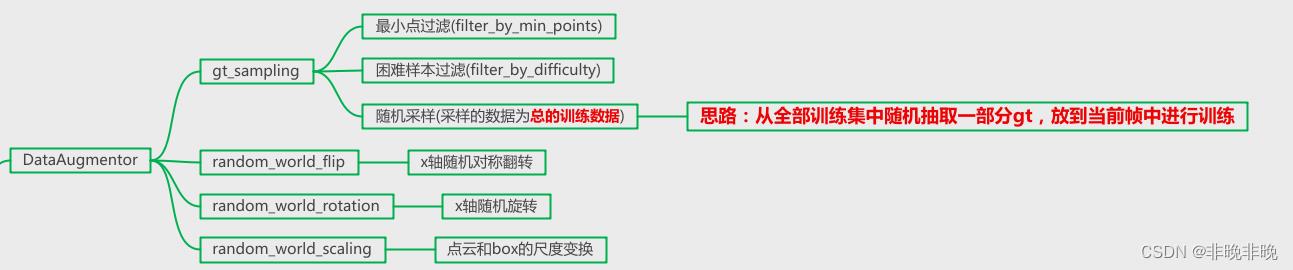
数据增强部分代码在:pcdet/datasets/augmentor/data_augmentor.py
1.1 gt数据采集——gt_sampling
该模块思路很简单,就是为了丰富训练数据,也就是将其它帧gt的点云以及box放入待训练帧中的空余位置。下面是这部分的配置文件,官方这部分训练了3种类型。
- NAME: gt_sampling
USE_ROAD_PLANE: True
DB_INFO_PATH:
- kitti_dbinfos_train.pkl
PREPARE:
filter_by_min_points: ['Car:5', 'Pedestrian:5', 'Cyclist:5'],
filter_by_difficulty: [-1],
SAMPLE_GROUPS: ['Car:15','Pedestrian:15', 'Cyclist:15']
NUM_POINT_FEATURES: 4
DATABASE_WITH_FAKELIDAR: False
REMOVE_EXTRA_WIDTH: [0.0, 0.0, 0.0]
LIMIT_WHOLE_SCENE: False
首先对采样的gt进行最小点过滤。代码注释如下:
class DataAugmentor(object):
def __init__(self, root_path, augmentor_configs, class_names, logger=None):
self.root_path = root_path
self.class_names = class_names
self.logger = logger
self.data_augmentor_queue = []
# 读取数据增强部分配置文件
aug_config_list = augmentor_configs if isinstance(augmentor_configs, list) \\
else augmentor_configs.AUG_CONFIG_LIST
#逐个读取数据增强部分
for cur_cfg in aug_config_list:
if not isinstance(augmentor_configs, list):
#不用数据增强的列表DISABLE_AUG_LIST
if cur_cfg.NAME in augmentor_configs.DISABLE_AUG_LIST:
continue
#使用partial,所以此刻只是把数据增强方法加入队列(data_dict=0)
# 执行数据增加的函数,并加入至data_augmentor_queue
cur_augmentor = getattr(self, cur_cfg.NAME)(config=cur_cfg)
self.data_augmentor_queue.append(cur_augmentor)
#gt数据采集部分
def gt_sampling(self, config=None):
db_sampler = database_sampler.DataBaseSampler(
root_path=self.root_path,
sampler_cfg=config,
class_names=self.class_names,
logger=self.logger
)
return db_sampler
其中DataBaseSampler的代码如下:
class DataBaseSampler(object):
def __init__(self, root_path, sampler_cfg, class_names, logger=None):
self.root_path = root_path
self.class_names = class_names
self.sampler_cfg = sampler_cfg
self.logger = logger
self.db_infos =
#按照类别分类
for class_name in class_names:
self.db_infos[class_name] = []
# use_shared_memory = false
self.use_shared_memory = sampler_cfg.get('USE_SHARED_MEMORY', False)
for db_info_path in sampler_cfg.DB_INFO_PATH:
db_info_path = self.root_path.resolve() / db_info_path
#按照类别加入数据各自的db数据
with open(str(db_info_path), 'rb') as f:
infos = pickle.load(f)
[self.db_infos[cur_class].extend(infos[cur_class]) for cur_class in class_names]
#执行最小点过滤和困难点过滤,我这里只用了filter_by_min_points过滤
for func_name, val in sampler_cfg.PREPARE.items():
self.db_infos = getattr(self, func_name)(self.db_infos, val)
self.gt_database_data_key = self.load_db_to_shared_memory() if self.use_shared_memory else None
self.sample_groups = #sample_num、pointer和indices
self.sample_class_num = #sample_num
self.limit_whole_scene = sampler_cfg.get('LIMIT_WHOLE_SCENE', False) #False
for x in sampler_cfg.SAMPLE_GROUPS:
class_name, sample_num = x.split(':')
if class_name not in class_names:
continue
self.sample_class_num[class_name] = sample_num
self.sample_groups[class_name] =
'sample_num': sample_num,
'pointer': len(self.db_infos[class_name]),
'indices': np.arange(len(self.db_infos[class_name]))
#最小点过滤函数
def filter_by_min_points(self, db_infos, min_gt_points_list):
for name_num in min_gt_points_list:
#对每个类别单独过滤
name, min_num = name_num.split(':')
min_num = int(min_num)
if min_num > 0 and name in db_infos.keys():
filtered_infos = []
for info in db_infos[name]:
#box内大于min_num的保留
if info['num_points_in_gt'] >= min_num:
filtered_infos.append(info)
if self.logger is not None:
self.logger.info('Database filter by min points %s: %d => %d' %
(name, len(db_infos[name]), len(filtered_infos)))
db_infos[name] = filtered_infos
return db_infos
1.2 全局翻转——random_world_flip
这部分配置如下,这部分的意义为使points和gt_boxes进行 X轴的全局翻转 。
- NAME: random_world_flip
ALONG_AXIS_LIST: ['x']
官方这部分只做了X轴的对称翻转,翻转概率为50%。
def random_world_flip(self, data_dict=None, config=None):
#data_dict如果为空数据,暂时返回
if data_dict is None:
return partial(self.random_world_flip, config=config)
gt_boxes, points = data_dict['gt_boxes'], data_dict['points']
for cur_axis in config['ALONG_AXIS_LIST']:
assert cur_axis in ['x', 'y']
#执行具体的翻转函数
gt_boxes, points = getattr(augmentor_utils, 'random_flip_along_%s' % cur_axis)(
gt_boxes, points,
)
data_dict['gt_boxes'] = gt_boxes
data_dict['points'] = points
return data_dict
# x轴对称翻转函数
def random_flip_along_x(gt_boxes, points):
"""
Args:
gt_boxes: (N, 7 + C), [x, y, z, dx, dy, dz, heading, [vx], [vy]]
points: (M, 3 + C)
Returns:
"""
# 0.5的概率翻转
enable = np.random.choice([False, True], replace=False, p=[0.5, 0.5])
if enable:
gt_boxes[:, 1] = -gt_boxes[:, 1] #box,修改x的值
gt_boxes[:, 6] = -gt_boxes[:, 6] #box,修改heading角
points[:, 1] = -points[:, 1] #点云翻转
if gt_boxes.shape[1] > 7:
gt_boxes[:, 8] = -gt_boxes[:, 8]
return gt_boxes, points
1.3 全局旋转——random_world_rotation
这部分配置如下,这部分的意义为使points和gt_boxes进行 绕Z轴的旋转 波动。
- NAME: random_world_rotation
WORLD_ROT_ANGLE: [-0.78539816, 0.78539816] #值为弧度
需要说明的是,这里Z轴旋转的角度为弧度。
def random_world_rotation(self, data_dict=None, config=None):
#data_dict如果为空数据,暂时返回
if data_dict is None:
return partial(self.random_world_rotation, config=config)
rot_range = config['WORLD_ROT_ANGLE']
if not isinstance(rot_range, list):
rot_range = [-rot_range, rot_range]
gt_boxes, points = augmentor_utils.global_rotation(
data_dict['gt_boxes'], data_dict['points'], rot_range=rot_range
)
# 旋转函数
def global_rotation(gt_boxes, points, rot_range):
"""
Args:
gt_boxes: (N, 7 + C), [x, y, z, dx, dy, dz, heading, [vx], [vy]]
points: (M, 3 + C),
rot_range: [min, max]
Returns:
"""
#旋转噪声,从最小至最大中随机取值
noise_rotation = np.random.uniform(rot_range[0], rot_range[1])
#点云和box的旋转
points = common_utils.rotate_points_along_z(points[np.newaxis, :, :], np.array([noise_rotation]))[0]
gt_boxes[:, 0:3] = common_utils.rotate_points_along_z(gt_boxes[np.newaxis, :, 0:3], np.array([noise_rotation]))[0]
gt_boxes[:, 6] += noise_rotation
if gt_boxes.shape[1] > 7:
gt_boxes[:, 7:9] = common_utils.rotate_points_along_z(
np.hstack((gt_boxes[:, 7:9], np.zeros((gt_boxes.shape[0], 1))))[np.newaxis, :, :],
np.array([noise_rotation])
)[0][:, 0:2]
return gt_boxes, points
# 具体调用的旋转函数为
def rotate_points_along_z(points, angle):
"""
Args:
points: (B, N, 3 + C)
angle: (B), angle along z-axis, angle increases x ==> y
Returns:
"""
points, is_numpy = check_numpy_to_torch(points)
angle, _ = check_numpy_to_torch(angle)
cosa = torch.cos(angle)
sina = torch.sin(angle)
zeros = angle.new_zeros(points.shape[0])
ones = angle.new_ones(points.shape[0])
rot_matrix = torch.stack((
cosa, sina, zeros,
-sina, cosa, zeros,
zeros, zeros, ones
), dim=1).view(-1, 3, 3).float()
points_rot = torch.matmul(points[:, :, 0:3], rot_matrix)
points_rot = torch.cat((points_rot, points[:, :, 3:]), dim=-1)
return points_rot.numpy() if is_numpy else points_rot
1.4 全局尺度变换——random_world_scaling
这部分配置如下,这部分的意义为使points和gt_boxes进行 尺度的缩放。
- NAME: random_world_scaling
WORLD_SCALE_RANGE: [0.95, 1.05]
def random_world_scaling(self, data_dict=None, config=None):
#data_dict如果为空数据,暂时返回
if data_dict is None:
return partial(self.random_world_scaling, config=config)
#调用尺度函数
gt_boxes, points = augmentor_utils.global_scaling(
data_dict['gt_boxes'], data_dict['points'], config['WORLD_SCALE_RANGE']
)
data_dict['gt_boxes'] = gt_boxes
data_dict['points'] = points
return data_dict
#尺度函数
def global_scaling(gt_boxes, points, scale_range):
"""
Args:
gt_boxes: (N, 7), [x, y, z, dx, dy, dz, heading]
points: (M, 3 + C),
scale_range: [min, max]
Returns:
"""
#变换尺度太小,则不用了
if scale_range[1] - scale_range[0] < 1e-3:
return gt_boxes, points
#尺度因子
noise_scale = np.random.uniform(scale_range[0], scale_range[1])
points[:, :3] *= noise_scale
gt_boxes[:, :6] *= noise_scale
return gt_boxes, points
2. 数据处理
数据处理有3个函数,分别为限制范围、随机打乱点云范围和点云至voxels(或者pillars)的变换。这部分的流程如下:
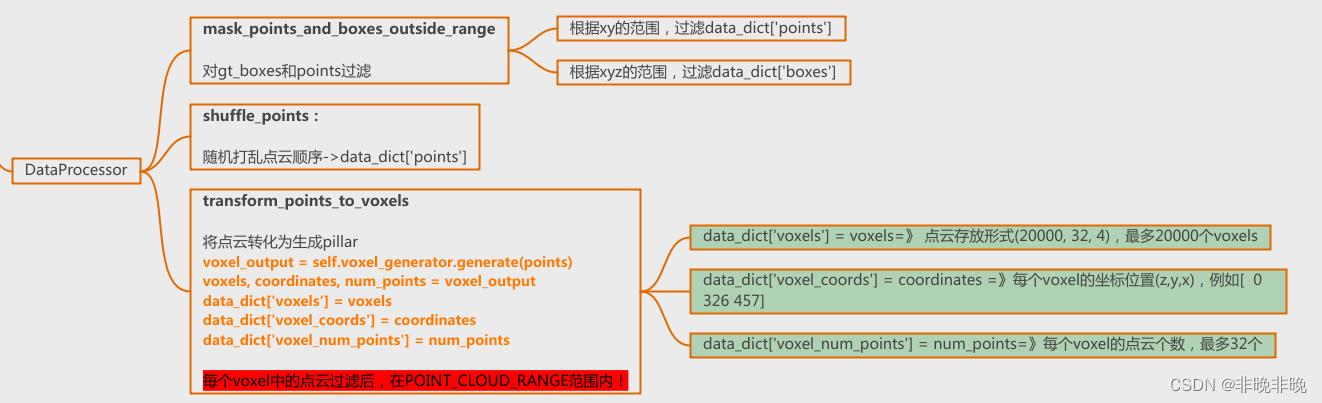
这部分的代码位于:pcdet/datasets/processor/data_processor.py
class DataProcessor(object):
def __init__(self, processor_configs, point_cloud_range, training, num_point_features):
self.point_cloud_range = point_cloud_range #数据范围
self.training = training
#给定每个点云的特征维度,这里是x,y,z,r 其中r是激光雷达反射强度
self.num_point_features = num_point_features
self.mode = 'train' if training else 'test'
#grid或voxel或pillar的size
self.grid_size = self.voxel_size = None
self.data_processor_queue = []
self.voxel_generator = None
#依次加入三个数据处理
for cur_cfg in processor_configs:
cur_processor = getattr(self, cur_cfg.NAME)(config=cur_cfg)
self.data_processor_queue.append(cur_processor)
2.1 数据范围限制
点云的mask和box的mask是分别制作的。
def mask_points_and_boxes_outside_range(self, data_dict=None, config=None):
if data_dict is None:
return partial(self.mask_points_and_boxes_outside_range, config=config)
if data_dict.get('points', None) is not None:
#根据配置文件的范围,做一个点云mask
mask = common_utils.mask_points_by_range(data_dict['points'], self.point_cloud_range)
data_dict['points'] = data_dict['points'][mask]
if data_dict.get('gt_boxes', None) is not None and config.REMOVE_OUTSIDE_BOXES and self.training:
#根据配置文件的范围,做一个gt_box的mask
mask = box_utils.mask_boxes_outside_range_numpy(
data_dict['gt_boxes'], self.point_cloud_range, min_num_corners=config.get('min_num_corners', 1)
)
data_dict['gt_boxes'] = data_dict['gt_boxes'][mask]
return data_dict
#制作点云的mask的函数
def mask_points_by_range(points, limit_range):
mask = (points[:, 0] >= limit_range[0]) & (points[:, 0] <= limit_range[3]) \\
& (points[:, 1] >= limit_range[1]) & (points[:, 1] <= limit_range[4])
return mask
# gt_box的mask函数
def mask_boxes_outside_range_numpy(boxes, limit_range, min_num_corners=1):
"""
Args:
boxes: (N, 7) [x, y, z, dx, dy, dz, heading, ...], (x, y, z) is the box center
limit_range: [minx, miny, minz, maxx, maxy, maxz]
min_num_corners:
Returns:
"""
if boxes.shape[1] > 7:
boxes = boxes[:, 0:7]
corners = boxes_to_corners_3d(boxes) # (N, 8, 3)
mask = ((corners >= limit_range[0:3]) & (corners <= limit_range[3:6])).all(axis<以上是关于openpcdet之pointpillar代码阅读——第一篇:数据增强与数据处理的主要内容,如果未能解决你的问题,请参考以下文章