openpcdet之pointpillar代码阅读——第二篇:网络结构
Posted 非晚非晚
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了openpcdet之pointpillar代码阅读——第二篇:网络结构相关的知识,希望对你有一定的参考价值。
文章目录
pointpillar相关的其它文章链接如下:
上一篇文章,我们梳理了数据增强和数据处理,并且得到了相应的pillar数据。下面我们继续讲pointpillar中的网络结构。
整体网络结构如下:
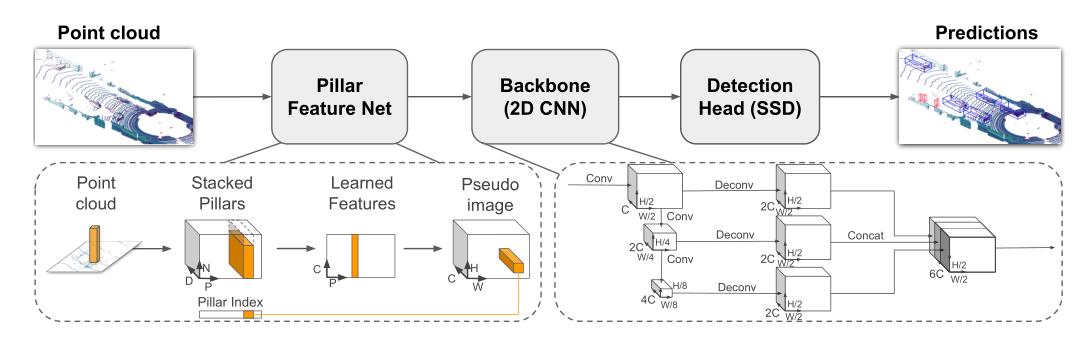
1. VFE
功能:这部分是简化版的pointnet网络,将经过数据增强和数据处理过后的pillar(N,4)数据,经过BN层、Relu激活层和max pool层得到(C, H, W)数据。
在VFE之前的data_dict的数据如下所示:
'''
batch_dict:
points:(N,5) --> (batch_index,x,y,z,r) batch_index代表了该点云数据在当前batch中的index
frame_id:(batch_size,) -->帧ID-->我们存放的是npy的绝对地址,batch_size个地址
gt_boxes:(batch_size,N,8)--> (x,y,z,dx,dy,dz,ry,class),
use_lead_xyz:(batch_size,) --> (1,1,1,1),batch_size个1
voxels:(M,32,4) --> (x,y,z,r)
voxel_coords:(M,4) --> (batch_index,z,y,x) batch_index代表了该点云数据在当前batch中的index
voxel_num_points:(M,):每个voxel内的点云
batch_size:batch_size大小
'''
随后经过VFE之后,就可以把原始的点云结构
(
N
∗
4
)
(N*4)
(N∗4)变换成了
(
D
,
P
,
N
)
(D,P,N)
(D,P,N),其中 D代表了每个点云的特征维度,也就是每个点云10个特征(论文中只有9维),P代表了所有非空的立方柱体,N代表了每个pillar中最多会有多少个点。具体操作以及说明如下:
- D ( x , y , z , x c , r , y c , z c , x p , y p , z p ) D(x,y,z, x_c ,r, y_c , z_c , x_p ,y_p,z_p) D(x,y,z,xc,r,yc,zc,xp,yp,zp):xyz表示点云的真实坐标,下标c代表了每个点云到该点所对应pillar中所有点平均值的偏移量,下标p表示该点距离所在pillar中心点的偏移量。
- P:代表了所有非空的立方柱体,yaml配置中有最大值MAX_NUMBER_OF_VOXELS。
- N:代表了每个pillar中最多会有多少个点,实际操作取32。
得到 ( D , P , N ) (D,P,N) (D,P,N)的张量后,接下来这里使用了一个简化版的pointnet网络对点云的数据进行特征提取(即将这些点通过MLP升维,然后跟着BN层和Relu激活层),得到一个 ( C , P , N ) (C,P,N) (C,P,N)形状的张量,之后再使用max pooling操作提取每个pillar中最能代表该pillar的点。那么输出会变成 ( C , P , N ) − > ( C , P ) − > ( C , H , W ) (C,P,N)->(C,P)->(C, H, W) (C,P,N)−>(C,P)−>(C,H,W)
这部分代码在:pcdet/models/backbones_3d/vfe/pillar_vfe.py,具体的注释代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
from .vfe_template import VFETemplate
class PFNLayer(nn.Module):
def __init__(self,
in_channels,
out_channels,
use_norm=True,
last_layer=False):
super().__init__()
self.last_vfe = last_layer
self.use_norm = use_norm
if not self.last_vfe:
out_channels = out_channels // 2
# x的维度由(M, 32, 10)升维成了(M, 32, 64),max pool之后32才去掉
if self.use_norm:
self.linear = nn.Linear(in_channels, out_channels, bias=False)
self.norm = nn.BatchNorm1d(out_channels, eps=1e-3, momentum=0.01)
else:
self.linear = nn.Linear(in_channels, out_channels, bias=True)
self.part = 50000
def forward(self, inputs):
if inputs.shape[0] > self.part:
# nn.Linear performs randomly when batch size is too large
num_parts = inputs.shape[0] // self.part
part_linear_out = [self.linear(inputs[num_part*self.part:(num_part+1)*self.part])
for num_part in range(num_parts+1)]
x = torch.cat(part_linear_out, dim=0)
else:
x = self.linear(inputs)
torch.backends.cudnn.enabled = False
#permute变换维度,(M, 64, 32) --> (M, 32, 64)
# 这里之所以变换维度,是因为BatchNorm1d在通道维度上进行,对于图像来说默认模式为[N,C,H*W],通道在第二个维度上
x = self.norm(x.permute(0, 2, 1)).permute(0, 2, 1) if self.use_norm else x
torch.backends.cudnn.enabled = True
x = F.relu(x)
# 完成pointnet的最大池化操作,找出每个pillar中最能代表该pillar的点
x_max = torch.max(x, dim=1, keepdim=True)[0]
if self.last_vfe:
return x_max
else:
x_repeat = x_max.repeat(1, inputs.shape[1], 1)
x_concatenated = torch.cat([x, x_repeat], dim=2)
return x_concatenated
class PillarVFE(VFETemplate):
def __init__(self, model_cfg, num_point_features, voxel_size, point_cloud_range, **kwargs):
super().__init__(model_cfg=model_cfg)
self.use_norm = self.model_cfg.USE_NORM
self.with_distance = self.model_cfg.WITH_DISTANCE
self.use_absolute_xyz = self.model_cfg.USE_ABSLOTE_XYZ
# num_point_features:10
num_point_features += 6 if self.use_absolute_xyz else 3
if self.with_distance:
num_point_features += 1
#[64]
self.num_filters = self.model_cfg.NUM_FILTERS
assert len(self.num_filters) > 0
# num_filters: [10, 64]
num_filters = [num_point_features] + list(self.num_filters)
pfn_layers = []
#len(num_filters) - 1 == 1
for i in range(len(num_filters) - 1):
in_filters = num_filters[i] # 10
out_filters = num_filters[i + 1] # 64
pfn_layers.append(
PFNLayer(in_filters, out_filters, self.use_norm, last_layer=(i >= len(num_filters) - 2))
)
#收集PFN层,在forward中执行
self.pfn_layers = nn.ModuleList(pfn_layers)
self.voxel_x = voxel_size[0]
self.voxel_y = voxel_size[1]
self.voxel_z = voxel_size[2]
self.x_offset = self.voxel_x / 2 + point_cloud_range[0]
self.y_offset = self.voxel_y / 2 + point_cloud_range[1]
self.z_offset = self.voxel_z / 2 + point_cloud_range[2]
def get_output_feature_dim(self):
return self.num_filters[-1]
def get_paddings_indicator(self, actual_num, max_num, axis=0):
'''
指出一个pillar中哪些是真实数据,哪些是填充的0数据
'''
actual_num = torch.unsqueeze(actual_num, axis + 1)
max_num_shape = [1] * len(actual_num.shape)
max_num_shape[axis + 1] = -1
max_num = torch.arange(max_num, dtype=torch.int, device=actual_num.device).view(max_num_shape)
paddings_indicator = actual_num.int() > max_num
return paddings_indicator
def forward(self, batch_dict, **kwargs):
'''
batch_dict:
points:(N,5) --> (batch_index,x,y,z,r) batch_index代表了该点云数据在当前batch中的index
frame_id:(batch_size,) -->帧ID-->我们存放的是npy的绝对地址,batch_size个地址
gt_boxes:(batch_size,N,8)--> (x,y,z,dx,dy,dz,ry,class),
use_lead_xyz:(batch_size,) --> (1,1,1,1),batch_size个1
voxels:(M,32,4) --> (x,y,z,r)
voxel_coords:(M,4) --> (batch_index,z,y,x) batch_index代表了该点云数据在当前batch中的index
voxel_num_points:(M,):每个voxel内的点云
batch_size:4:batch_size大小
'''
voxel_features, voxel_num_points, coords = batch_dict['voxels'], batch_dict['voxel_num_points'], batch_dict['voxel_coords']
#求每个pillar中所有点云的平均值,设置keepdim=True的,则保留原来的维度信息
points_mean = voxel_features[:, :, :3].sum(dim=1, keepdim=True) / voxel_num_points.type_as(voxel_features).view(-1, 1, 1)
#每个点云数据减去该点对应pillar的平均值,得到差值 xc,yc,zc
f_cluster = voxel_features[:, :, :3] - points_mean
# 创建每个点云到该pillar的坐标中心点偏移量空数据 xp,yp,zp
f_center = torch.zeros_like(voxel_features[:, :, :3])
'''
coords是每个网格点的坐标,即[432, 496, 1],需要乘以每个pillar的长宽得到点云数据中实际的长宽(单位米)
同时为了获得每个pillar的中心点坐标,还需要加上每个pillar长宽的一半得到中心点坐标
每个点的x、y、z减去对应pillar的坐标中心点,得到每个点到该点中心点的偏移量
'''
f_center[:, :, 0] = voxel_features[:, :, 0] - (coords[:, 3].to(voxel_features.dtype).unsqueeze(1) * self.voxel_x + self.x_offset)
f_center[:, :, 1] = voxel_features[:, :, 1] - (coords[:, 2].to(voxel_features.dtype).unsqueeze(1) * self.voxel_y + self.y_offset)
f_center[:, :, 2] = voxel_features[:, :, 2] - (coords[:, 1].to(voxel_features.dtype).unsqueeze(1) * self.voxel_z + self.z_offset)
#配置中使用了绝对坐标,直接组合即可。
if self.use_absolute_xyz:
features = [voxel_features, f_cluster, f_center] #10个特征,直接组合
else:
features = [voxel_features[..., 3:], f_cluster, f_center]
#距离信息,False
if self.with_distance:
points_dist = torch.norm(voxel_features[:, :, :3], 2, 2, keepdim=True)
features.append(points_dist)
features = torch.cat(features, dim=-1)
voxel_count = features.shape[1]
#mask中指明了每个pillar中哪些是需要被保留的数据
mask = self.get_paddings_indicator(voxel_num_points, voxel_count, axis=0)
mask = torch.unsqueeze(mask, -1).type_as(voxel_features)
#由0填充的数据,在计算出现xc,yc,zc和xp,yp,zp时会有值
#features中去掉0值信息。
features *= mask
#执行上面收集的PFN层,每个pillar抽象出64维特征
for pfn in self.pfn_layers:
features = pfn(features)
features = features.squeeze()
batch_dict['pillar_features'] = features
return batch_dict
2. MAP_TO_BEV
功能:将得到的pillar数据,投影至二维坐标中。
在经过简化版的pointnet网络提取出每个pillar的特征信息后,就需要将每个的pillar数据重新放回原来的坐标中,也就是二维坐标,组成 伪图像 数据。
对应到论文中就是stacked pillars,将生成的pillar按照坐标索引还原到原空间中。
这部分代码在:pcdet/models/backbones_2d/map_to_bev/pointpillar_scatter.py,具体的注释代码如下:
import torch
import torch.nn as nn
class PointPillarScatter(nn.Module):
def __init__(self, model_cfg, grid_size, **kwargs):
super().__init__()
self.model_cfg = model_cfg
self.num_bev_features = self.model_cfg.NUM_BEV_FEATURES #64
self.nx, self.ny, self.nz = grid_size # [432,496,1]
assert self.nz == 1
def forward(self, batch_dict, **kwargs):
'''
batch_dict['pillar_features']-->为VFE得到的数据(M, 64)
voxel_coords:(M,4) --> (batch_index,z,y,x) batch_index代表了该点云数据在当前batch中的index
'''
pillar_features, coords = batch_dict['pillar_features'], batch_dict['voxel_coords']
batch_spatial_features = []
# 根据batch_index,获取batch_size大小
batch_size = coords[:, 0].max().int().item() + 1
for batch_idx in range(batch_size):
# 创建一个空间坐标所有用来接受pillar中的数据
# spatial_feature 维度 (64,214272)
spatial_feature = torch.zeros(
self.num_bev_features,
self.nz * self.nx * self.ny,
dtype=pillar_features.dtype,
device=pillar_features.device)
batch_mask = coords[:, 0] == batch_idx #返回mask,[True, False...]
this_coords = coords[batch_mask, :] #获取当前的batch_idx的数
#计算pillar的索引,该点之前所有行的点总和加上该点所在的列即可
indices = this_coords[:, 1] + this_coords[:, 2] * self.nx + this_coords[:, 3]
indices = indices.type(torch.long) # 转换数据类型
pillars = pillar_features[batch_mask, :]
pillars = pillars.t()
# 在索引位置填充pillars
spatial_feature[:, indices] = pillars
# 将空间特征加入list,每个元素为(64, 214272)
batch_spatial_features.append(spatial_feature)
# 在第0个维度将所有的数据堆叠在一起
batch_spatial_features = torch.stack(batch_spatial_features, 0)
# reshape回原空间(伪图像) (4, 64, 214272)--> (4, 64, 496, 432)
batch_spatial_features = batch_spatial_features.view(batch_size, self.num_bev_features * self.nz, self.ny, self.nx)
batch_dict['spatial_features'] = batch_spatial_features
#返回数据
return batch_dict
3. BACKBONE_2D
功能:骨干网络,提取特征
经过上面的映射操作,将原来的pillar提取最大的数值后放回到相应的坐标后,就可以得到类似于图像的数据了;只有在有pillar非空的坐标处有提取的点云数据,其余地方都是0数据,所以得到的一个(batch_size,64, 432, 496)的张量还是很稀疏的。
BACKBONE_2D的输入特征维度(batch_size,64, 432, 496),输出的特征维度为[batch_size, 384, 248, 216]。
需要说明的是,主干网络构建了下采样和上采样网络,分别为加入到了blocks和deblocks中,上采样和下采样的具体操作可查看下列代码和注释。
这部分代码在:pcdet/models/backbones_2d/base_bev_backbone.py,具体的注释代码如下:
import numpy as np
import torch
import torch.nn as nn
class BaseBEVBackbone(nn.Module):
# input_channels = 64
def __init__(self, model_cfg, input_channels):
super()