深度学习基础:4.Pytorch搭建基础网络模型
Posted zstar-_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习基础:4.Pytorch搭建基础网络模型相关的知识,希望对你有一定的参考价值。
这个专栏停更了一段时间,现在重新开始,巩固基础才能看懂复杂代码。
Torch基本架构
使用Pytorch之前,首先要理清楚Pytorch基本架构。
Pytorch的核心库是torch,根据不同领域细分可以分成计算机视觉、自然语言处理和语音处理,这三个领域分别有自己对应的库,即torchvision、torchtext、torchaudio。
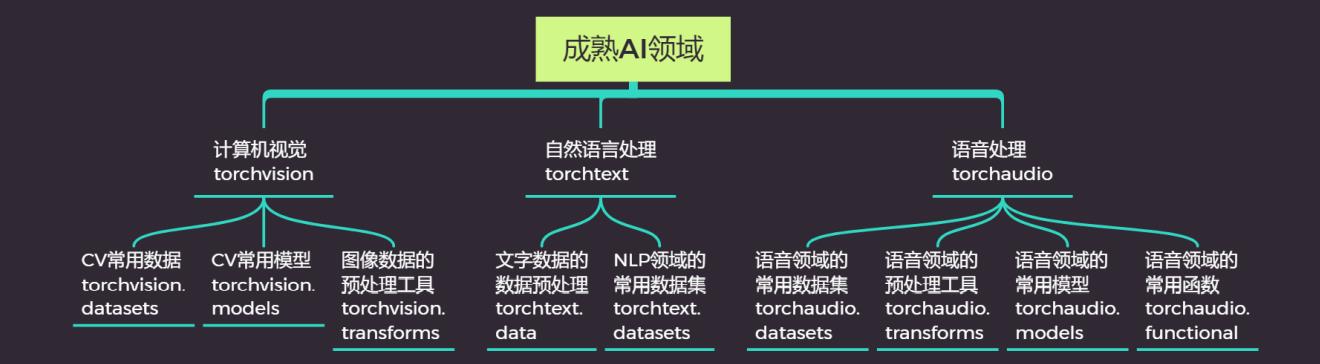
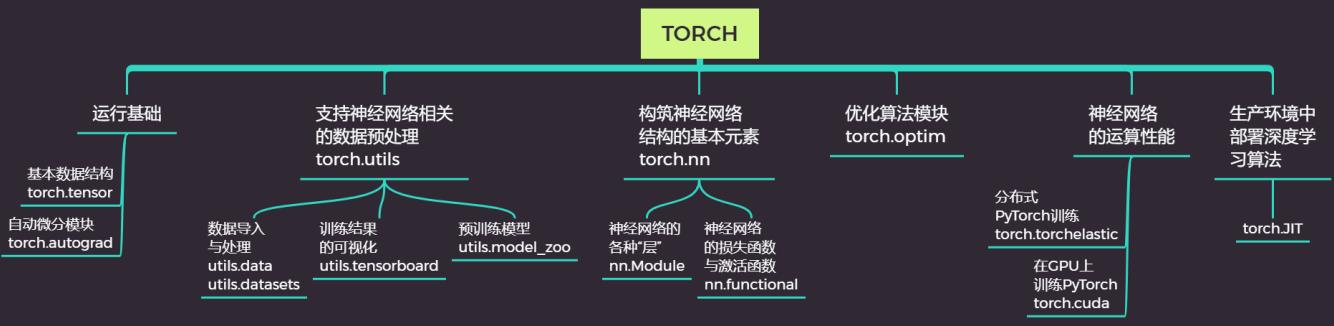
核心库Torch中,根据功能又可以细分成下面几个模块。
正向传播结构
下面就用Pytorch搭建一个简单的正向传播结构。
首先导库,这里需要三个库,torch基本库不必说,nn即neural network,包含了神经网络结构的基本元素。functional 包含了损失函数和激活函数。
import torch
import torch.nn as nn
from torch.nn import functional as F
之后进行数据生成
这里manual_seed是固定人为的随机种子,因为不固定该值,每次运行时神经网络各层的初始权重/偏置会进行随机初始化,导致结果不稳定。
X是生成(500,20)的数据,注意必须指定其数据格式为浮点型(float32),否则默认为整型。
y是随机生成500条(0,3]之间的数,注意y也是浮点型,因为在后面损失函数计算时需要浮点型数据。
torch.random.manual_seed(103)
X = torch.rand((500,20), dtype=torch.float32)
y = torch.randint(low=0,high=3,size=(500,1), dtype=torch.float32)
接下来就到了最核心的搭建网络结构模块
- 1、定义模型类,注意要继承于
nn.Module - 2、在初始化函数中继承父类的初始化函数
super(Model,self).__init__(),这是由于python的继承机制不会继承父类的__init__ - 3、指定输入输出神经元数目
in_features和out_features,这并不是必须的,但是如果把输入输出作为参数进行传递,会增强模型的通用性。 - 4、构造
Linear线性层,注意一个线性层输出和下一个线性层的输入个数需相等,否则无法计算(原理上就是矩阵相乘) - 5、构造
forward函数,实现前向传播过程,指定每一层的输入输出和激活函数。
class Model(nn.Module):
def __init__(self,in_features=10, out_features=2):
"""
in_features: 输入该神经网络的特征数目(输入层上的神经元的数目)
out_features:神经网络的输出的数目(输出层上的神经元的数目)
"""
super(Model,self).__init__()
self.linear1 = nn.Linear(in_features,13,bias=True)
self.linear2 = nn.Linear(13,8,bias=True)
self.output = nn.Linear(8,out_features,bias=True)
def forward(self,x): #神经网络的向前传播
z1 = self.linear1(x)
sigma1 = torch.relu(z1)
z2 = self.linear2(sigma1)
sigma2 = torch.sigmoid(z2)
z3 = self.output(sigma2)
sigma3 = F.softmax(z3,dim=1)
return sigma3
之后实例化网络,注意在此之前要限定输入输出的个数,这里选择输入即X的特征维度20,输出y不同的数值(假设为分类问题,输出不同的类别)
input_ = X.shape[1]
output_ = len(y.unique())
net = Model(in_features=input_, out_features = output_)
调用模型,实现正向传播有下面两种书写方式:
# 方式一
y_hat = net.forward(X)
# 方式二
y_hat = net(X)
两者的区别是方式一只会调用forward函数内容,方式二回调用除 __init__之外的所有函数内容,因此更推荐第一种写法。
这样执行之后,输入向量维度为(500,20),输出结果为(500,3),即对每一条数据都根据20个特征得到了分类结果。
除此之外,可以用下面的语句查看每一层的参数。比如,查看linear1层的权重和偏置。
# 查看权重
net.linear1.weight
# 查看偏置
net.linear1.bias
使用net.linear1.weight.shape查看linear1层的维度,输出为(13,20),然而linear1层的输入为20,输出为13,这是由于在公式计算中,权重w会被转置再进行矩阵乘法运算。
损失函数
有了正向传播结构之后,就自然需要计算损失,反向传播。在此之前,有必要先了解一些损失函数的API。
回归损失函数
对于回归问题,比较常见的损失函数是SSE和MSE,两者的公式如下:
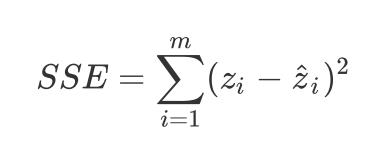
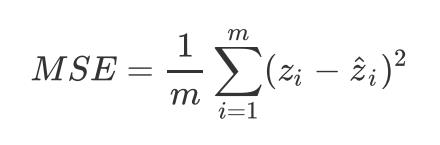
在Pytoch中,可以这样进行调用。
from torch.nn import MSELoss
# 生成随机数据
yhat = torch.randn(size=(50,),dtype=torch.float32)
y = torch.randn(size=(50,),dtype=torch.float32)
# SSE
criterion = MSELoss(reduction = "sum")
loss = criterion(yhat,y)
# MSE
criterion = MSELoss(reduction = "mean")
loss = criterion(yhat,y)
分类损失函数
对于分类问题,最常采用的是交叉熵损失,比如二分类交叉熵损失函数如下:
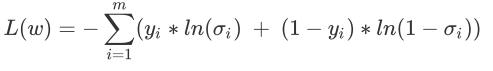
Pytorch中,BCELoss和BCEWithLogitsLoss均能实现此功能,但后者的精度更高,不过一般来说,BCELoss基本够用。
from torch.nn import BCELoss, BCEWithLogitsLoss
# 生成随机数据
yhat = torch.randint(low=0,high=2,size=(10,1),dtype=torch.float32)
y = torch.randint(low=0,high=2,size=(10,1),dtype=torch.float32)
# 方式一
criterion = BCELoss()
loss = criterion(yhat,y)
# 方式二
criterion = BCEWithLogitsLoss()
loss = criterion(yhat,y)
MSELoss类似,BCELoss也有sum、mean可选参数,功能和前面类似。
对于多分类问题,Pytorch提供了CrossEntropyLoss这个函数,使用实例如下:
from torch.nn import CrossEntropyLoss
# 生成随机数据
yhat = torch.randint(low=0,high=2,size=(10,2),dtype=torch.float32)
y = torch.randint(low=0,high=2,size=(10,),dtype=torch.float32)
# 多元交叉熵损失
criterion = CrossEntropyLoss()
loss = criterion(yhat, y.long())
使用注意:1、yhat必须>=2维,如果是1维数据会报错。2、CrossEntropyLoss计算时要求标签必须是整型数据,因此用y.long()将浮点型转换成整型。
实现反向传播
有了损失函数之后,在Pytorch中就可以用一行命令实现反向传播,即loss.backward()
把损失函数和反向传播添加到前向传播过程中,就形成了一轮简单的神经网络训练过程。
import torch
import torch.nn as nn
from torch.nn import functional as F
#确定数据
torch.random.manual_seed(103)
X = torch.rand((500,20), dtype=torch.float32)
y = torch.randint(low=0,high=3,size=(500,1), dtype=torch.float32)
input_ = X.shape[1]
output_ = len(y.unique())
class Model(nn.Module):
def __init__(self,in_features=10, out_features=2):
"""
in_features: 输入该神经网络的特征数目(输入层上的神经元的数目)
out_features:神经网络的输出的数目(输出层上的神经元的数目)
"""
super(Model,self).__init__()
self.linear1 = nn.Linear(in_features,13,bias=True)
self.linear2 = nn.Linear(13,8,bias=True)
self.output = nn.Linear(8,out_features,bias=True)
def forward(self,x): #神经网络的向前传播
z1 = self.linear1(x)
sigma1 = torch.relu(z1)
z2 = self.linear2(sigma1)
sigma2 = torch.sigmoid(z2)
z3 = self.output(sigma2)
sigma3 = F.softmax(z3,dim=1)
return sigma3
net = Model(in_features=input_, out_features = output_) # 实例化神经网络
y_hat = net.forward(X) # 向前传播
criterion = nn.CrossEntropyLoss()
loss = criterion(y_hat,y.reshape(500).long())
loss.backward()
# loss.backward(retain_graph=True)
注意:Pytorch的反向传播底层是基于一个动态的计算图,每次执行完backward之后,这个计算图会从内存中自动销毁,如果想要保留这张图,以便进行多次反向传播,可以设置参数retain_graph=True
上述模型计算图可视化如下:
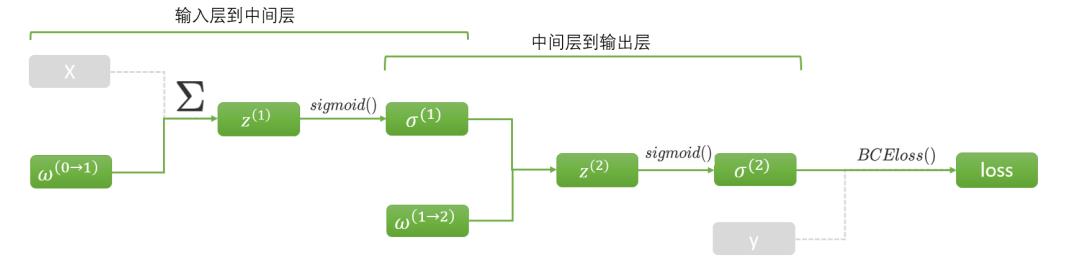
使用优化器
上面实现了一个最基本正向传播和反向传播的过程,然而,如果要应用更加复杂优化算法,直接手写就非常麻烦。Pytorch提供了一个优化器(optim),其内部封装了大量优化算法,可以方便开发者快速调用。
例如,实现随机梯度下降,可以调用optim的SGD接口,调用接口如下:
class torch.optim.SGD(params, lr=, momentum=0, dampening=0, weight_decay=0, nesterov=False)
相关参数解释:
| 参数 | 描述 |
|---|---|
| params (iterable) | 待优化参数的iterable或者是定义了参数组的dict |
| lr (float) | 学习率 |
| momentum (float, 可选) | 动量因子(默认:0,通常设置为0.9,0.8) |
| weight_decay (float, 可选) | 权重衰减(L2惩罚)(默认:0) |
| dampening (float, 可选) | 动量的抑制因子(默认:0) |
| nesterov (bool, 可选) | 使用Nesterov动量(默认:False |
optim更多接口参数解释,看到这篇博客记录比较详细,放置链接如下:
Link:https://blog.csdn.net/xq151750111/article/details/123602946
下面还是以之前的网络模型为例,实现一个带动量参数的SGD优化器
import torch
import torch.nn as nn
import torch.optim as optim
from torch.nn import functional as F
torch.manual_seed(103)
X = torch.rand((500,20),dtype=torch.float32) * 100
y = torch.randint(low=0,high=3,size=(500,),dtype=torch.float32)
lr = 0.1 # 学习率
gamma = 0.9 # 动量
class Model(nn.Module):
def __init__(self,in_features=10,out_features=2):
super(Model,self).__init__()
self.linear1 = nn.Linear(in_features,13,bias=True)
self.linear2 = nn.Linear(13,8,bias=True)
self.output = nn.Linear(8,out_features,bias=True)
def forward(self, x):
sigma1 = torch.relu(self.linear1(x))
sigma2 = torch.sigmoid(self.linear2(sigma1))
zhat = self.output(sigma2)
return zhat
input_ = X.shape[1] #特征的数目
output_ = len(y.unique()) #分类的数目
net = Model(in_features=input_, out_features=output_) #实例化网络
criterion = nn.CrossEntropyLoss() #定义损失函数
opt = optim.SGD(net.parameters(),lr = lr,momentum = gamma)
yhat = net.forward(X)
loss = criterion(yhat, y.long()) #计算损失函数
loss.backward()
opt.step() #走一步,更新权重w,更新动量v
opt.zero_grad() #清除原来储存好的,基于上一个坐标点计算的梯度,为下一次计算梯度腾出空间
这一段代码就是实现了梯度下降中的一步,加上循环,就形成了常见的深度学习过程。
数据加载器
在数据量少时,上面的代码能够完成训练。然而,当数据量变大时,就比较依赖硬件性能。比如,如果使用的CPU版本的Pytorch,数据会被加载进内存,如果内存无法容纳所有数据就会产生爆内存的问题,严重点可能会导致死机。如果使用GPU版本的Pytorch,数据可以选择加载进显存,如果显存不够大,会产生爆显存的Bug。
为了解决这个问题,可以将大批量的数据进行切分,每次只送一批数据到模型中进行训练,这批数据的大小就叫batch_size。
Pytorch为了数据切分提供了两个工具,TensorDataset和DataLoader。
之前输入模型的数据和标签是分开的,但是在后面的数据加载器DataLoader中,需要输入数据和标签的整体。python中的zip函数能够实现打包功能,Pytorch的TensorDataset函数功能也类似。不过对于tensor数据而言,pytorch提供的函数通常比python原生函数运算更快一些。
TensorDataset的使用示例如下:
from torch.utils.data import TensorDataset
a = torch.randn(500,3,4,5) #四维数据 - 图像
b = torch.randn(500,1) #二维数据 - 标签
c = TensorDataset(a,b)
直接打印c,不会输出具体的值,可以用下面的方式进行查看:
for x in c:
print(x)
break
输出c中的第一项如图所示:
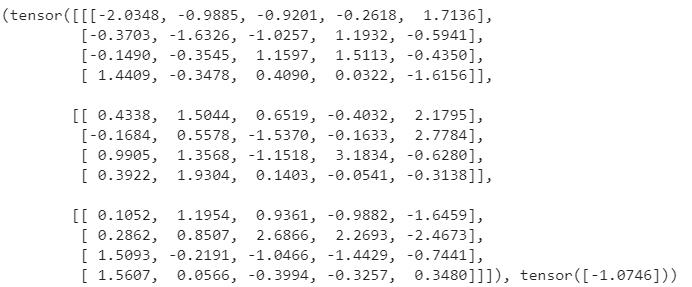
里面包含两个tensor,第一个是数据,第二个是标签。
有了tensor之后,就可以直接将数据输入到DataLoader之中。DataLoader是处理训练前的数据加载器,它可以接受任意形式的数组、张量作为输入,并把他们一次性转换为神经网络可以接入的tensor。
DataLoader有很多参数,这里使用三个:
- batch_size
指定每一批(batch)数据的大小 - shuffle
是否对数据进行打乱 - drop_last
是否将最后一批不满足batch_size大小的数据丢弃
from torch.utils.data import DataLoader
dataset = DataLoader(c
, batch_size = 120
, shuffle = True #随机打乱数据
, drop_last = True #是否舍弃最后一个batch
)
打印出每个TensorDataset大小查看:
for i in dataset:
print(i[0].shape) # i[0]是数据,i[1]是标签

如图所示,500条数据,每个batch_size为120并舍弃最后一个batch,因此输出四个batch。
在实际使用中,通常这样进行调用。
for batch_idx, (x,y) in enumerate(dataset):
yhat = net(x)
loss = criterion(yhat, y)
loss.backward()
opt.step()
opt.zero_grad()
以上是关于深度学习基础:4.Pytorch搭建基础网络模型的主要内容,如果未能解决你的问题,请参考以下文章