双目视觉深度——基于Correlation的方法(DispNet / iResNet / AANet)
Posted Leo-Peng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了双目视觉深度——基于Correlation的方法(DispNet / iResNet / AANet)相关的知识,希望对你有一定的参考价值。
双目视觉深度—— 基于Correlation的方法(DispNet / iResNet / AANet)
双目视觉深度——基于Correlation的方法(DispNet / iResNet / AANet)
在Stereo Depth算法中一类方法是基于Cost Volume估计视差,这类方法可以参考双目视觉深度——基于Cost Volume的方法(GC-Net / PSM-Net / GA-Net),另外一类就是本文要介绍的介于Correlation的方法,相比于基于Cost Volume的方法,基于Correlation的方法计算量小,但是准确率也相对较低 (最新提出的AANet已经达到了一个较高水平),下面就这类方法进行一个简单总结:
1. DispNet
DispNet发表于2016年,原论文名为《A Large Dataset to Train Convolutional Networks for Disparity, Optical Flow, and Scene Flow Estimation》,这篇论文的作者和端到端做光流估计的FlowNet的作者是同一人,这篇论文主要也就是印证了类似于FlowNet这样的框架也可以用于进行视差估计,于是作者在FlowNet的基础上做了一些细微改动就得到了DispNet。因此这里我们主要介绍FlowNet的网络结构:
1.1 网络结构
FlowNet的网络结构一共两种类型——FlowNetS和FlowNettC,S指的是Simple的意思,C指的是Correlation的意思,Encoder部分如下图所示:
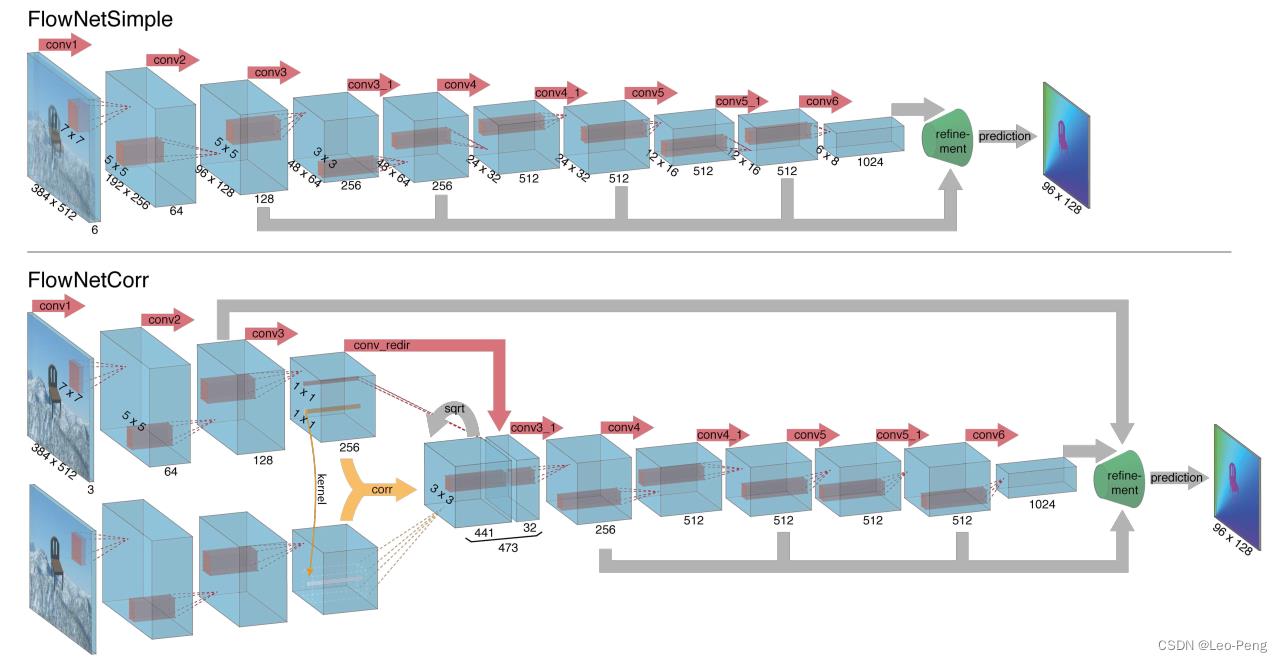
其中FlowNetS是将图片Concat到一起然后经过一系列卷积,FlowNetC则是先用卷积对各个图片进行特征提取,然后用提取的特征进行Correlation,然后再进一步提取特征,这里我们主要关注FlowNetC的结构,中间比较特殊的部分就是Correlation操作(黄色箭头部分),Correlation其实就是分别从两张特征图中各取一个patch进行卷积,具体的计算公式为:
c
(
x
1
,
x
2
)
=
∑
o
∈
[
−
k
,
k
]
×
[
−
k
,
k
]
⟨
f
1
(
x
1
+
o
)
,
f
2
(
x
2
+
o
)
⟩
c\\left(\\mathbfx_1, \\mathbfx_2\\right)=\\sum_\\mathbfo \\in[-k, k] \\times[-k, k]\\left\\langle\\mathbff_1\\left(\\mathbfx_1+\\mathbfo\\right), \\mathbff_2\\left(\\mathbfx_2+\\mathbfo\\right)\\right\\rangle
c(x1,x2)=o∈[−k,k]×[−k,k]∑⟨f1(x1+o),f2(x2+o)⟩其中
⟨
⟩
\\left\\langle\\right\\rangle
⟨⟩为卷积符号,
f
1
\\mathbff_1
f1和
f
2
\\mathbff_2
f2分别为进行Correlation的两张特征图,
x
1
\\mathbfx_1
x1和
x
2
\\mathbfx_2
x2分别为进行Correlation的两个Patch的中心坐标。我们知道,大小为
H
×
W
×
(
2
k
+
1
)
H \\times W \\times (2k +1)
H×W×(2k+1)的两个Patch卷积后大小为
H
×
W
×
(
2
k
+
1
)
2
H \\times W \\times (2k +1)^2
H×W×(2k+1)2,由于在论文中
k
k
k取的是10,因此在上图中经过Correlation后的特征图的Channel数为
(
2
∗
10
+
1
)
×
(
2
∗
10
+
1
)
=
441
(2 * 10 + 1) \\times (2 * 10 + 1)=441
(2∗10+1)×(2∗10+1)=441,在Pytorch的实现里面这一步好像是直接调用了一个CUDA的算子:
import torch
from torch.nn.modules.module import Module
from torch.autograd import Function
import correlation_cuda
class CorrelationFunction(Function):
@staticmethod
def forward(ctx, input1, input2, pad_size=3, kernel_size=3, max_displacement=20, stride1=1, stride2=2, corr_multiply=1):
ctx.save_for_backward(input1, input2)
ctx.pad_size = pad_size
ctx.kernel_size = kernel_size
ctx.max_displacement = max_displacement
ctx.stride1 = stride1
ctx.stride2 = stride2
ctx.corr_multiply = corr_multiply
with torch.cuda.device_of(input1):
rbot1 = input1.new()
rbot2 = input2.new()
output = input1.new()
correlation_cuda.forward(input1, input2, rbot1, rbot2, output,
ctx.pad_size, ctx.kernel_size, ctx.max_displacement, ctx.stride1, ctx.stride2, ctx.corr_multiply)
return output
@staticmethod
def backward(ctx, grad_output):
input1, input2 = ctx.saved_tensors
with torch.cuda.device_of(input1):
rbot1 = input1.new()
rbot2 = input2.new()
grad_input1 = input1.new()
grad_input2 = input2.new()
correlation_cuda.backward(input1, input2, rbot1, rbot2, grad_output, grad_input1, grad_input2,
ctx.pad_size, ctx.kernel_size, ctx.max_displacement, ctx.stride1, ctx.stride2, ctx.corr_multiply)
return grad_input1, grad_input2, None, None, None, None, None, None
class Correlation(Module):
def __init__(self, pad_size=0, kernel_size=0, max_displacement=0, stride1=1, stride2=2, corr_multiply=1):
super(Correlation, self).__init__()
self.pad_size = pad_size
self.kernel_size = kernel_size
self.max_displacement = max_displacement
self.stride1 = stride1
self.stride2 = stride2
self.corr_multiply = corr_multiply
def forward(self, input1, input2):
result = CorrelationFunction.apply(input1, input2, self.pad_size, self.kernel_size, self.max_displacement, self.stride1, self.stride2, self.corr_multiply)
return result
在进行Correlation之后,网络还将其中一路的数据进行卷积后Concat到Correlation后的特征图上,也就是图中的conv_redir的操作,我理解这一步应该就是为了保留更多的原始结构的信息,使得输出的光流或者视差更加稳定。FlowNetS和FlowNettC的Decode部分是一致的,结构如下图所示:

在Decoder之后网络不需要做Argmax的操作,而是直接通过L1或者L2损失回归出光流或者视差的大小,网络整体的代码如下图所示:
class FlowNetC(nn.Module):
def __init__(self,args, batchNorm=True, div_flow = 20):
super(FlowNetC,self).__init__()
self.batchNorm = batchNorm
self.div_flow = div_flow
self.conv1 = conv(self.batchNorm, 3, 64, kernel_size=7, stride=2)
self.conv2 = conv(self.batchNorm, 64, 128, kernel_size=5, stride=2)
self.conv3 = conv(self.batchNorm, 128, 256, kernel_size=5, stride=2)
self.conv_redir = conv(self.batchNorm, 256, 32, kernel_size=1, stride=1)
if args.fp16:
self.corr = nn.Sequential(
tofp32(),
Correlation(pad_size=20, kernel_size=1, max_displacement=20, stride1=1, stride2=2, corr_multiply=1),
tofp16())
else:
self.corr = Correlation(pad_size=20, kernel_size=1, max_displacement=20, stride1=1, stride2=2, corr_multiply=1)
self.corr_activation = nn.LeakyReLU(0.1,inplace=True)
self.conv3_1 = conv(self.batchNorm, 473, 256)
self.conv4 = conv(self.batchNorm, 256, 512, stride=2)
self.conv4_1 = conv(self.batchNorm, 512, 512)
self.conv5 = conv(self.batchNorm, 512, 512, stride=2)
self.conv5_1 = conv(self.batchNorm, 512, 512)
self.conv6 = conv(self.batchNorm, 512, 1024, stride=2)
self.conv6_1 = conv(self.batchNorm,1024, 1024)
self.deconv5 = deconv(1024,512)
self.deconv4 = deconv(1026,256)
self.deconv3 = deconv(770,128)
self.deconv2 = deconv(386,64)
self.predict_flow6 = predict_flow(1024)
self.predict_flow5 = predict_flow(1026)
self.predict_flow4 = predict_flow(770)
self.predict_flow3 = predict_flow(386)
self.predict_flow2 = predict_flow(194)
self.upsampled_flow6_to_5 = nn.ConvTranspose2d(2, 2, 4, 2, 1, bias=True)
self.upsampled_flow5_to_4 = nn.ConvTranspose2d(2, 2, 4, 2, 1, bias=True)
self.upsampled_flow4_to_3 = nn.ConvTranspose2d(2, 2, 4, 2, 1, bias=True)
self.upsampled_flow3_to_2 = nn.ConvTranspose2d(2, 2, 4, 2, 1, bias=True)
for m in self.modules():
if isinstance(m, nn.Conv2d):
if m.bias is not None:
init.uniform_(m.bias)
init.xavier_uniform_(m.weight)
if isinstance(m, nn.ConvTranspose2d):
if m.bias is not None:
init.uniform_(m.bias)
init.xavier_uniform_(m.weight)
# init_deconv_bilinear(m.weight)
self.upsample1 = nn.Upsample(scale_factor=4, mode='bilinear')
def forward(self, x):
x1 = x[:,0:3,:,:]
x2 = x[:,3::,:,:]
out_conv1a = self.conv1(x1)
out_conv2a = self.conv2(out_conv1a)
out_conv3a = self.conv3(out_conv2a)
# FlownetC bottom input stream
out_conv1b = self.conv1(x2)
out_conv2b = self.conv2(out_conv1b)
out_conv3b = self.conv3(out_conv2b)
# Merge streams
out_corr = self.corr(out_conv3a, out_conv3b) # False
out_corr = self.corr_activation(out_corr)
# Redirect top input stream and concatenate
out_conv_redir = self.conv_redir(out_conv3a)
in_conv3_1 = torch.cat((out_conv_redir, out_corr), 1)
# Merged conv layers
out_conv3_1 = self.conv3_1(in_conv3_1)
out_conv4 = self.conv4_1(self.conv4(out_conv3_1))
out_conv5 = self.conv5_1(self.conv5(out_conv4))
out_conv6 = self.conv6_1(self.conv6(out_conv5))
flow6 = self.predict_flow6(out_conv6)
flow6_up = self.upsampled_flow6_to_5(flow6)
out_deconv5 = self.deconv5(out_conv6)
concat5 = torch.cat((out_conv5,out_deconv5,flow6_up),1)
flow5 = self.predict_flow5(concat5)
flow5_up = self.upsampled_flow5_to_4(flow5)
out_deconv4 = self.deconv4(concat5)
concat4 = torch.cat((out_conv4,out_deconv4,flow5_up),1)
flow4 = self.predict_flow4(concat4)
flow4_up = self.upsampled_flow4_to_3(flow4)
out_deconv3 = self.deconv3(concat4)
concat3 = torch.cat((out_conv3_1,out_deconv3,flow4_up),1)
flow3 = self.predict_flow3(concat3)
flow3_up = self.upsampled_flow3_to_2(flow3)
out_deconv2 = self.deconv2(concat3)
concat2 = torch.cat((out_conv2a,out_deconv2,flow3_up),1)
flow2 = self.predict_flow2(concat2)
if self.training:
return flow2,flow3,flow4,flow5,flow6
else:
return flow2,
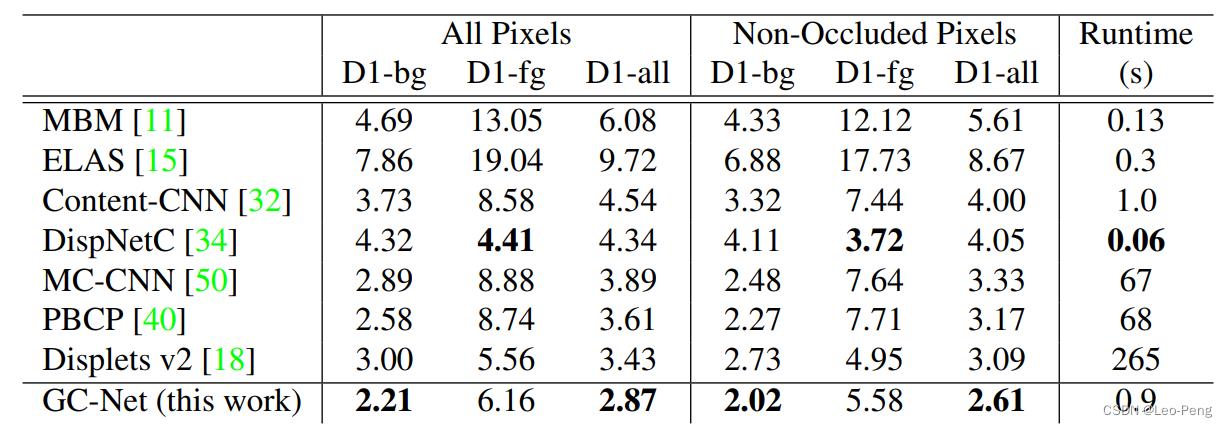
可以看到,DispNet的结构是非常简单的,与结构同样非常简单的GC-Net相比较,速度相对较快,但是准确率相对较低:
2. iResNet
iResNet发表于CVPR2018,原论文名为《Learning for Disparity Estimation through Feature Constancy》,iResNet其实是在另外一篇名为CRL的论文《Cascade Residual Learning: A Two-stage Convolutional Neural Network for Stereo Matching》上进行的优化,CRL的网络结构如下图所示: 以上是关于双目视觉深度——基于Correlation的方法(DispNet / iResNet / AANet)的主要内容,如果未能解决你的问题,请参考以下文章
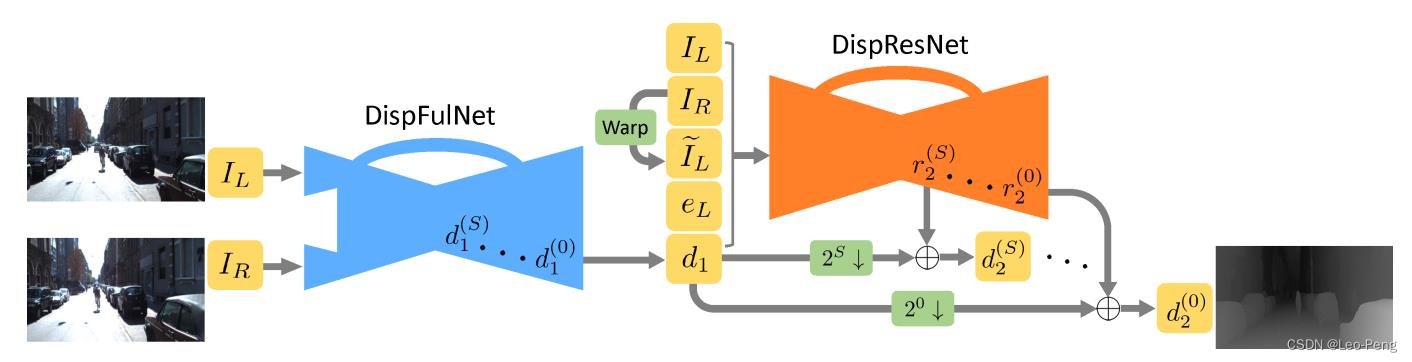
其实就是做两层DispNet,第一层DispNet输出的为初始的视差估计结果,在第二层DispNet的输入为Concat的
I
L
,
I
R
,
d
1
,
I