VRP基于matlab遗传算法求解多中心车辆路径规划问题含Matlab源码 1965期
Posted 海神之光
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了VRP基于matlab遗传算法求解多中心车辆路径规划问题含Matlab源码 1965期相关的知识,希望对你有一定的参考价值。
一、VRP简介
1 遗传算法基本原理
遗传算法 (Genetic Algorithm, GA) 是由美国密歇根大学的John Holland教授首先提出的, 它基于达尔文的进化论和孟德尔的遗传学说, 模拟生物在自然环境中的遗传和进化过程而形成的一种自适应全局优化的概率搜索算法[2]。遗传算法从一组随机产生的种群开始, 经过选择、杂交和变异3个遗传操作算子使目标函数向着最优解进化, 使遗传算法具有了其他传统方法所没有的特性。
遗传算法首先将问题可能的解按某种形式进行编码, 编码后的解称为染色体 (个体) 。随机选取N个染色体构成初始群种, 再根据预定的评价函数对每个染色体计算适应度, 使得性能较好的染色体具有较高的适应度。选择适应度高的染色体进行复制, 通过遗传算子 (选择、交叉 (重组) 、变异) 来产生一群新的更适应环境的染色体, 形成新的种群。按照适者生存和优胜劣汰的原理逐代演化产生出越来越好的近似解, 在每一代, 根据问题域中个体的适应度大小选择个体, 并借助于自然遗传学的遗传算子进行组合交叉和变异, 产生出代表新的解集的种群。这个过程将导致种群像自然进化一样的后生代种群比前代更加适应于环境, 末代种群中的最优个体经过解码, 可以作为问题近似最优解。
遗传算法流程图如图1所示:

图1 遗传算法流程图
2 物流多配送中心的运输问题描述与数学建模
多配送中心的运输问题形式化描述为:某产品有n个生产地S (S1, S2, …, Sn) , 有m个销售地E (e1, e2, ……, em) , 其中Sn代表第n个生产地, em表示第m个销售地。n个生产地的产量为P (p1, p2, …pn) , m个销售地的所需销售量T (t1, t2…tm) , 从的运输费用为c (si, ej) 元/吨。Wr为总的运输费用。
物流多配送中心的运输问题的数学模型如下所示:
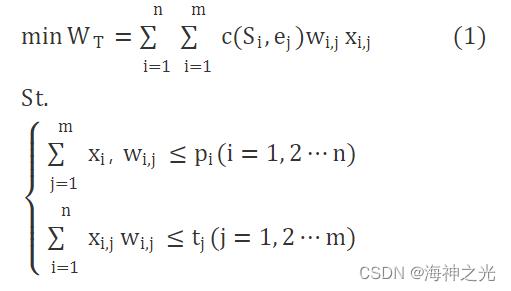
其中, 式 (1) 为物流多配送中心的运输问题的目标函数, 表示为产品总的运输费用最小化;式 (2) 和 (3) 表示约束条件, 式 (2) 表示生产地实际运输出的产品总量必须不超过其生产量, 式 (3) 表示销售地实际获得的产品总量必须不超过其需求量。
xi, j=0, 1决策变量, 其描述意义如表1所示。
表1 决策变量的描述意义

3 基于遗传算法的物流多配送中心的运输调度
3.1 编码
本文采用基于自然数的编码方式, 由于产品的生产地S (S1, S2, …Sn) 和销售地E (e1, e2, em) 已知, 故将每一个si→ej是否运送产品编为基因, 也即xi, j, 如wi, j, 则编为1, 如wi, j, 则编为0。
染色体为 (x1, 1, x1, 2, 。。。, x1, m, x2, 1, x2, 2, 。。。, x2, m, 。。。, xn, 1, xn, 2, 。。。xn, m, ) , 其中xi, j表示产地si是否向销售地ej运送产品, 染色体的长度为n×m[5]。
不考虑基因在染色体中的位置, 将染色体中基因之间有逻辑、关联等关系的基因归类。例如, “x1, 1, x1, 2, 。。。, x1, m”都是通过生产地派生的编码, 可以将这m个基因定义为行基因群;“x1, 1, x2, 1。。。xn, 1, ”中的基因都是通过销售地派生的编码, 尽管在染色体中的位置不在一起, 依旧可以定义为列基因群。基因群在编码过程中对模型解的寻优有很大的帮助。
考虑到解的非法性和寻优的区域性, 在编码过程中应该注意两点:①在线性规划中, 最优解是存在于基可行解中, 而基可行解中基变量的个数为n+m-1个, 故染色体中基因为1的个数应该也n+m-1个;②考虑到一个产地给所有销售地运送物资以及一个销售地必须由所有生产地运送物资一般不会是最优解, 在使用遗传算子进行搜索过程中, 最优出现在某行基因群全为1以及某列基因群全为1染色体的可能性较小。
3.2 约束的处理
数学模型的约束复杂, 用遗传算法求解时, 只能目标函数, 故采用惩罚的方法来处理约束, 将约束条件转换为目标函数的一部分, 以保证种群中染色体的多样性, 使得遗传算法的搜索能够继续下去。
使用如下变换将约束条件, 式 (2) 变为目标函数的一部分:

3.3 适应度转换
遗传算法中, 要求适应度函数非负。因为物流多配送中心的运输模型的目标函数为正数, 为简单起见, 这里我们直接取目标函数的倒数作为适应度函数, 即fi=1/Zi。其中fi为染色体i的适应度, Zi为染色体i对应的经过约束处理后的目标函数值, 即染色体i对应的总运输成本+违反约束处以的惩罚值。
3.4 遗传算子
- 交叉算子
①部分匹配交叉
在两个父代个体中随机选取两个交叉点, 确定一个匹配段, 根据选定的匹配段定义一系列映射关系。首先, 交换两个父个体的匹配段, 然后对匹配段之外的其他基因位, 使用最初的父码, 按照映射关系经过交换得到相应位上的码值。
②顺序交叉
两个父个体交叉时, 通过保留一个父个体的一段子序列和另一个父个体的相对顺序生成子个体。首先, 随机选取两个交叉点, 父个体1两个交叉点中间的子序列保留不变, 对父个体2从第二个交叉点开始倒序重排, 去掉父个体1中已有的码值, 再将这个排列从第二个交叉点位置处开始复制给父个体1, 这样就生成了父个体1对应的子个体。
- 变异算子
变异算子包括倒位变异和交换变异。倒位变异是指随机选取一段子序列, 把该序列中的元素进行倒排, 即得到变异后的个体;交换变异是指在一个个体中随机选取两位, 并交换它们的位置, 即得到变异后的个体。
例如:染色体 (1, 0, 1, ︳0, 0, 1︳, 1, 1, 0) , 对中间的一段子序列进行倒排得到 (1, 0, 1, ︳1, 0, 0︳, 1, 1, 0) , 这就称为倒位变异;而对于染色体 (0, 1, 1, 0, 1, 0, 1, 1, 0) , 交换第一位“0”和第二位“1”, 得到染色体 (1, 0, 1, 0, 1, 0, 1, 1, 0) , 则为变换变异。
3.5 算法步骤
Step1:设置遗传算法的参数, 如主要有交叉率Pc, 变异率Pm和种群规模TotalPop, 算法进行代数Generation;
Step2:gen=0;使用自然数编码方式, 随机产生个体数为TotalPop的初始种群;
Step3:解码工作, 把染色体译成运输成本, 这里的运输成本为总运输费用+总惩罚值, 并计算各染色体的适应值;
Step4:gen=gen+1;如gen>Generation, 算法结束, 否则继续;
Step5:进行交叉和变异工作, 交叉算子采用部分匹配与顺序交叉, 而变异则采用倒位变异和交换变异;
Step6:把第 (gen-1) 代和第gen代的染色体合并, 解码计算它们各自的适应值;并按适应值由大到小的顺序重新排列染色体;
Step7:根据适应值由大到小的顺序, 从合并的这些数目为2*TotalPop个染色体中选取前TotalPop个染色体作为下一代的父代, 转Step4;
二、部分源代码
clear;
clc
%W=80; %每辆车的载重量
%Citynum=50; %客户数量
%Stornum=4;%仓库个数
%C %%第二三列 客户坐标,第四列 客户需求 51,52,53,54为四个仓库
%load('p01-n50-S4-w80.mat'); %载入测试数据,n客户服务点数,S仓库个数,w车辆载重量
%load('p02-n50-S4-w160.mat');
%load('p04-n100-S2-w100.mat');
%load('p05-n100-S2-w200.mat');
load('p06-n100-S3-w100.mat');
%load('p12-n80-S2-w60.mat');
% load('ppp-n30-s3-w-60.mat')
%load('ppp-n25-s3-w-50.mat')
w=[];%存储每代的最短总路径
G=100;%种群大小
v1=60;
v2=300;
[dislist,Clist]=vrp(C);%dislist为距离矩阵 ,Clist为点坐标矩阵及客户需
L=[];%存每个种群的回路长度
for i=1:G
Parent(i,:)=randperm(Citynum);%随机产生路径
L(i,1)=curlist(Citynum,Clist(:,4),W,Parent(i,:),Stornum,dislist);
end
Pc=0.8;%交叉比率
Pm=0.3;%变异比率
species=Parent;%种群
children=[];%子代
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
disp('正在运行,时间比较长,请稍等.........')
g=50;
for generation=1:g
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
tic
fprintf('\\n正在进行第%d次迭代,共%d次..........',generation,g);
Parent=species;%子代变成父代
children=[];%子代
Lp=L;
%选择交叉父代
[n m]=size(Parent);
%交叉,代处理
for i=1:n
for j=i:n
if rand<Pc
crossover
end
end
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
[n m]=size(Parent);
for i=1:n
if rand<Pm
parent=Parent(i,:);%变异个体
X=floor(rand*Citynum)+1;
Y=floor(rand*Citynum)+1;
Z=parent(X);
parent(X)=parent(Y);
parent(Y)=Z; %基因交换变异
children=[children;parent];
end
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%计算子代适应值(即路径长度) (这块用时比较长)
[m n]=size(children);
Lc=zeros(m,1);%子代适应值
for i=1:m
Lc(i,1)=curlist(Citynum,Clist(:,4),W,children(i,:),Stornum,dislist);
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%淘汰子代 剩余前G个最优解
[m n]=size(children);
if(m>G)
[m n]=sort(Lc);
children=children(n(1:G),:);
Lc=Lc(n(1:G));
end
%淘汰种群
species=[children;Parent];
L=[Lc;Lp];
[m n]=sort(L);
species=species(n(1:G),:); %更新世代
L=L(n(1:G));
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%加入Opt优化
%分配仓库进行opt
temp=initialStor(Citynum,Clist(:,4),W,species(1,:),Stornum,dislist);%存储分配仓库后的结果【52 14 5 52 53 6 9 8 53......】
Rbest=temp;
L_best=L(1);
[m n]=size(temp);
start=1;
car=[];%存放opt优化后的结果
i=2;
while (i<n+1)
if (temp(i)>Citynum)
cur=[]路径规划基于遗传算法求解多中心VRP问题matlab源码
配送路径规划基于matlab遗传算法求解单配送中心多客户多车辆最短路径规划问题含Matlab源码 1602期
VRP问题基于遗传算法求解带有时间窗车载容量限制多车辆单配送中心路径优化VRPTW(多约束)matlab源码