从实践到原理掌握 GDB
Posted 凌桓丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从实践到原理掌握 GDB相关的知识,希望对你有一定的参考价值。
文章目录
基本概念
什么是 GDB?

GDB(GNU Debugger),是一个由 GNU 开源组织发布的、UNIX/LINUX 操作系统下的、基于命令行的、功能强大的程序调试工具;GDB 支持断点、单步执行、打印变量、观察变量、查看寄存器、查看堆栈等调试手段;GDB 支持调试多种编程语言编写的程序,包括 C、C++、Go、Objective-C、OpenCL、Ada 等。实际场景中,GDB 更常用来调试 C 和 C++ 程序。
GDB 可以用来做些什么?
一般来说,借助 GDB 调试器可以实现以下几个功能:
- 程序启动时,可以按照我们自定义的要求运行程序,例如设置参数和环境变量。
- 可使被调试程序在指定代码处暂停运行,并查看当前程序的运行状态(例如当前变量的值,函数的执行结果等),即支持断点调试。
- 程序执行过程中,可以改变某个变量的值,还可以改变代码的执行顺序,从而尝试修改程序中出现的逻辑错误。
调试模型
根据 GDB 程序与被调试程序是否运行在同一台机器中,可以把 GDB 的调试模型分为以下两种:
- 本地调试
- 远程调试
本地调试
本地调试指的是调试程序和被调试程序运行在同一台机器中,如下图所示:
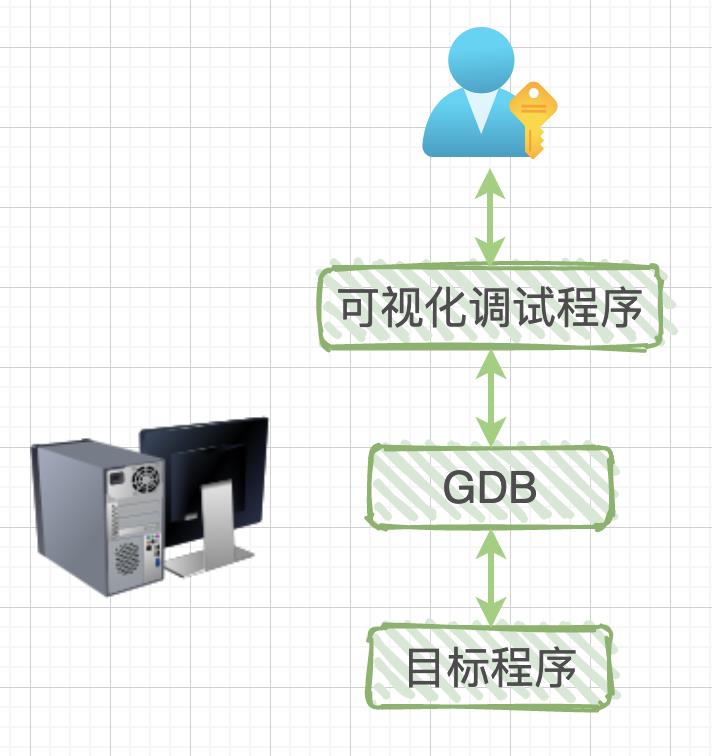
可视化调试程序只是对 GDB 操作的一层封装,例如 Visual Studio、CLion 等 IDE 中的可视化调试。当然我们也可以直接通过 bash 来手动输入调试命令。
远程调试
调试程序运行在一台机器中,被调试程序运行在另一台机器中,如下图所示:
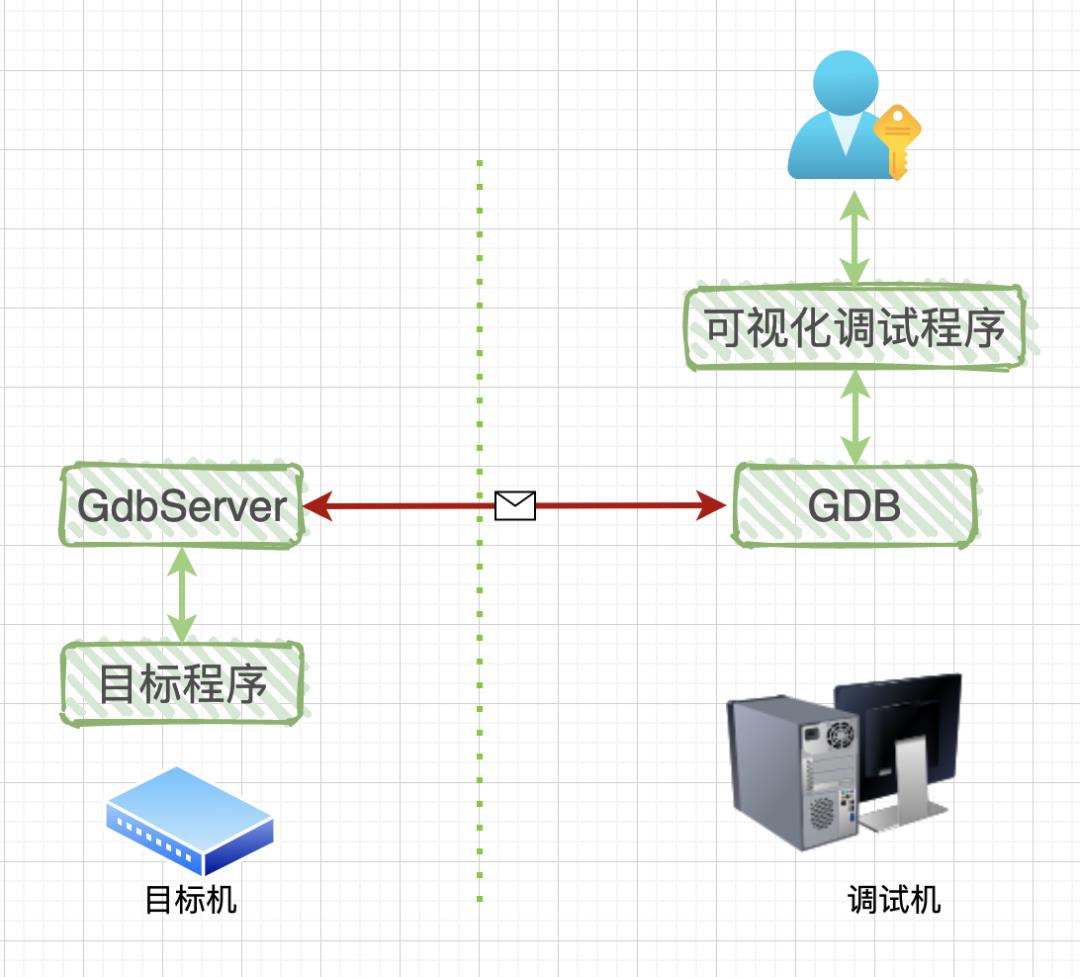
GdbServer 的主要工作是负责完成 GDB 与目标程序之间的通信,其采用了 RSP(GDB Remote Serial Protocol) 协议。
安装 GDB
这里以 CentOS 8 举例,来演示 GDB 的安装。
首先查看当前机器中是否存在 GDB:
gdb -v
如果提示 bash: gdb: command not found,则说明当前机器没有,继续执行下面的步骤,反之则无需安装。
通过 yum 安装 GDB:
sudo yum -y install gdb
如果使用的是官方的 yum 下载源,这里就会报错 Error: Failed to download metadata for repo 'appstream': Cannot prepare internal mirrorlist: No URLs in mirrorlist,这主要是因为在 2021 年底官方就停止对 CentOS 8 提供服务,这时我们就需要将 yum 源切换为国内的:
# 进入yum的repos目录
cd /etc/yum.repos.d/
# 修改所有的CentOS文件内容
sed -i 's/mirrorlist/#mirrorlist/g' /etc/yum.repos.d/CentOS-*
sed -i 's|#baseurl=http://mirror.centos.org|baseurl=http://vault.centos.org|g' /etc/yum.repos.d/CentOS-*
# 更新yum源为阿里镜像
wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-vault-8.5.2111.repo
yum clean all
yum makecache
这时候重新通过 yum 安装即可。
实战
启动调试
GDB 的使用前提:需要在编译时加上-g 参数,保留调试信息,否则会提示 no debugging symbols found,无法使用 GDB 进行调试。
调试未运行的程序
无参数
使用 GDB 可执行程序名 开启调试,输入 run 命令运行程序:
gdb test1
(gdb) run
有参数
直接在 run 后面跟上参数:
gdb test1
(gdb) run "hello world"
也可以通过 set args 命令指定参数列表:
gdb test1
(gdb) set args "hello world"
(gdb) show args # 查看参数列表
(gdb) run
调试运行中的程序
如果程序已经处于运行中的状态,那我们该如何对其进行调试呢?
已生成调试信息
对于已生成调试信息的,我们只需要找到它的进程 id,再使用 attach 命令绑定进程即可:
# 步骤一:找到进程id
ps -ef|grep 进程名
# 或者
pidof 进程名
# 步骤二:开启GDB调试
gdb
# 步骤三:attach绑定对应的进程id
attach [进程id]
# 或者在启动时直接指定程序名与进程id
gdb [程序名] --pid [进程id]
未生成调试信息
对于已运行且未生成调试信息的程序,我们可以重新编译出一个带调试信息的版本,再使用 file 命令将这个版本的符号表读取出来,此时我们再次 attach 程序,就能够进行调试了,并且不需要重新启动程序:
# 步骤一:重新编译一个带调试信息的版本
# 步骤二:使用file加载这个版本的符号表
file [程序名]
# 接下来的步骤与已生成调试信息的一样
调试 core 文件
当一个程序因为出错而导致异常中断的时候,操作系统会将程序当前的状态(如程序运行时的内存,寄存器状态,堆栈指针,内存管理信息)保存为一个 core 文件。我们可以通过使用 GDB 来调试这个文件,来迅速定位导致程序出错的问题。
配置 core 文件生成
首先我们需要使用 ulimit -a 命令查看系统有没有限制 core 文件的生成:
ulimit -c
unlimited # 代表没有限制
0 # 如果结果为零则代表无法生成,如果为其他数字则代表限制生成的个数
配置 coredump 生成,有临时配置和永久配置两种。
-
临时配置:只需要简单的命令即可,但是退出 bash 后就会失效。
-
$ ulimit -c unlimited #表示不限制core文件大小 $ ulimit -c n #n为数字,表示core文件大小上限,单位为块,一块默认为512字节
-
-
永久配置:需要修改内核参数,指定 core 文件名、存放路径与永久配置。
-
mkdir -p /www/coredump/ chmod 777 /www/coredump/ /etc/profile ulimit -c unlimited /etc/security/limits.conf * soft core unlimited echo "/www/coredump/core-%e-%p-%h-%t" > /proc/sys/kernel/core_pattern
-
调试 core 文件
这里以一个简单的访问空指针的示例来演示:
#include <stdio.h>
void fault_test(void)
*((int *)NULL) = 100; //解引用空指针并尝试修改它的值
int main()
fault_test();
return 0;
当我们编译后执行程序时,此时就会因为访问空指针而导致段错误:
gcc -g -o test_coredump test_coredump.c
./test_coredump
Segmentation fault (core dumped)
此时查看 core 文件的位置:
cat /proc/sys/kernel/core_pattern
|/usr/lib/systemd/systemd-coredump %P %u %g %s %t %c %h %e
这时我们发现这个路径下并没有 core 文件,上述信息表明了 core 文件已经被系统转储,此时有两种方法获取到 core 文件:
-
修改生成路径:
-
# 直接在程序所在目录生成core文件 echo "core-%e-%p-%t" > /proc/sys/kernel/core_pattern
-
-
取出 core 文件:
- 执行
coredumpctl命令,查看所有 coredump 的程序,找到我们需要调试的那个。 - 执行
coredumpctl -o 自定义core文件名 dump Pid取回 core 文件。
- 执行
当生成完毕 core 文件后,执行以下命令开始调试:
gdb 程序名 core文件名
此时我们就能够看到 coredump 的原因:
[New LWP 1065384]
Core was generated by `./test_coredump'.
Program terminated with signal SIGSEGV, Segmentation fault.
#0 fault_test () at test_coredump.c:4
4 *((int *)NULL) = 100;
接着执行 where 命令就能够查看调用堆栈:
(gdb) where
#0 fault_test () at test_coredump.c:4
#1 0x0000000000400551 in main () at test_coredump.c:8
常用命令
在 GDB 中,最常用的命令有以下这些:
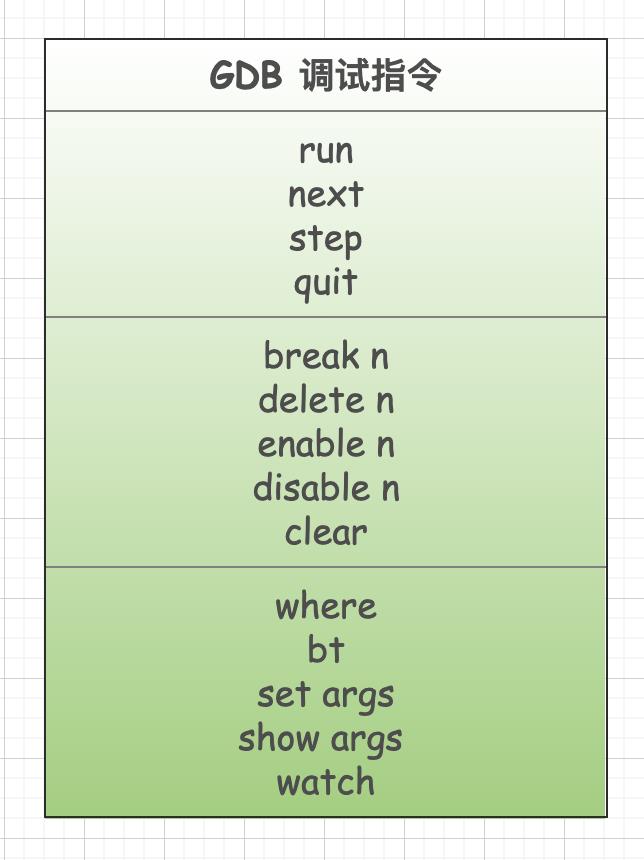
下面就来详细的介绍这些命令。
断点
断点是最常用的调试功能之一,它可以让程序中断在需要的地方,从而方便我们对程序分析。GDB 中断点主要分为以下三类:
- breakpoint。
- watchpoint。
- catchpoint。
breakpoint
可以根据行号、函数、条件生成断点,下面是相关命令以及对应的作用说明:
| 命令 | 作用 |
|---|---|
| break [file]:function | 在文件file的function函数入口设置断点 |
| break [file]:line | 在文件file的第line行设置断点 |
| info breakpoints | 查看断点列表 |
| break [±]offset | 在当前位置偏移量为[±]offset处设置断点 |
| break *addr | 在地址addr处设置断点 |
| break … if expr | 设置条件断点,仅仅在条件满足时 |
| ignore n count | 接下来对于编号为n的断点忽略count次 |
| clear | 删除所有断点 |
| clear function | 删除所有位于function内的断点 |
| delete n | 删除指定编号的断点 |
| enable n | 启用指定编号的断点 |
| disable n | 禁用指定编号的断点 |
| save breakpoints file | 保存断点信息到指定文件 |
| source file | 导入文件中保存的断点信息 |
| break | 在下一个指令处设置断点 |
| clear [file:]line | 删除第line行的断点 |
watchpoint
watchpoint 是一种特殊类型的断点,其类似于一个表达式的监视器,即当某个表达式改变了值时,它就会让 GDB 发出暂停执行的命令。
| 命令 | 作用 |
|---|---|
| watch variable | 设置变量数据断点 |
| watch var1 + var2 | 设置表达式数据断点 |
| rwatch variable | 设置读断点,仅支持硬件实现 |
| awatch variable | 设置读写断点,仅支持硬件实现 |
| info watchpoints | 查看数据断点列表 |
| set can-use-hw-watchpoints 0 | 强制基于软件方式实现 |
使用数据断点时,需要注意:
- 当监控变量为局部变量时,一旦局部变量失效,数据断点也会失效
- 如果监控的是指针变量
p,则watch *p监控的是p所指内存数据的变化情况,而watch p监控的是p指针本身有没有改变指向
最常见的数据断点应用场景:定位堆上的结构体内部成员何时被修改。由于指针一般为局部变量,为了解决断点失效,一般有两种方法。
| 命令 | 作用 |
|---|---|
| print &variable | 查看变量的内存地址 |
| watch *(type *)address | 通过内存地址间接设置断点 |
| watch -l variable | 指定location参数 |
| watch variable thread 1 | 仅编号为1的线程修改变量var值时会中断 |
catchpoint
catchpoint 是捕获断点,其主要监测信号的产生。
| 命令 | 含义 |
|---|---|
| catch fork | 程序调用fork时中断 |
| tcatch fork | 设置的断点只触发一次,之后被自动删除 |
| catch syscall ptrace | 为ptrace系统调用设置断点 |
调用栈
| 命令 | 作用 |
|---|---|
| backtrace [n] | 打印栈帧 |
| frame [n] | 选择第n个栈帧,如果不存在,则打印当前栈帧 |
| up n | 选择当前栈帧编号+n的栈帧 |
| down n | 选择当前栈帧编号-n的栈帧 |
| info frame [addr] | 描述当前选择的栈帧 |
| info args | 当前栈帧的参数列表 |
| info locals | 当前栈帧的局部变量 |
输出
变量信息
| 命令 | 作用 |
|---|---|
| whatis variable | 查看变量的类型 |
| ptype variable | 查看变量详细的类型信息 |
| info variables var | 查看定义该变量的文件,不支持局部变量 |
字符串
| 命令 | 作用 |
|---|---|
| x/s str | 打印字符串 |
| set print elements 0 | 打印不限制字符串长度/或不限制数组长度 |
| call printf(“%s\\n”,xxx) | 这时打印出的字符串不会含有多余的转义符 |
| printf “%s\\n”,xxx | 同上 |
数组
| 命令 | 作用 |
|---|---|
| print *array@10 | 打印从数组开头连续10个元素的值 |
| print array[60]@10 | 打印array数组下标从60开始的10个元素,即第60~69个元素 |
| set print array-indexes on | 打印数组元素时,同时打印数组的下标 |
指针
| 命令 | 作用 |
|---|---|
| print ptr | 查看该指针指向的类型及指针地址 |
| print *(struct xxx *)ptr | 查看指向的结构体的内容 |
内存地址
使用 x 命令来打印内存的值,格式为 x/nfu addr,以 f 格式打印从 addr 开始的 n 个长度单元为 u 的内存值。
n:输出单元的个数f:输出格式,如x表示以16进制输出,o表示以8进制输出,默认为xu:一个单元的长度,b表示1个byte,h表示2个byte(half word),w表示4个byte,g表示8个byte(giant word)
| 命令 | 作用 |
|---|---|
| x/8xb array | 以16进制打印数组array的前8个byte的值 |
| x/8xw array | 以16进制打印数组array的前16个word的值 |
局部变量
| 命令 | 作用 |
|---|---|
| info locals | 打印当前函数局部变量的值 |
| backtrace full | 打印当前栈帧各个函数的局部变量值,命令可缩写为bt |
| bt full n | 从内到外显示n个栈帧及其局部变量 |
| bt full -n | 从外向内显示n个栈帧及其局部变量 |
结构体
| 命令 | 作用 |
|---|---|
| set print pretty on | 每行只显示结构体的一名成员 |
| set print null-stop | 不显示’\\000’这种 |
函数跳转
| 命令 | 作用 |
|---|---|
| set step-mode on | 不跳过不含调试信息的函数,可以显示和调试汇编代码 |
| finish | 执行完当前函数并打印返回值,然后触发中断 |
| return 0 | 不再执行后面的指令,直接返回,可以指定返回值 |
| call printf(“%s\\n”, str) | 调用printf函数,打印字符串(可以使用call或者print调用函数) |
| print func() | 调用func函数(可以使用call或者print调用函数) |
| set var variable=xxx | 设置变量variable的值为xxx |
| set typeaddress = xxx | 给存储地址为address,类型为type的变量赋值 |
| info frame | 显示函数堆栈的信息(堆栈帧地址、指令寄存器的值等) |
多线程、多进程
多进程
GDB 在调试多进程程序(程序含 fork 调用)时,默认只追踪父进程。可以通过命令设置,实现只追踪父进程或子进程,或者同时调试父进程和子进程。
| 命令 | 作用 |
|---|---|
| info inferiors | 查看进程列表 |
| attach pid | 绑定进程id |
| inferior num | 切换到指定进程上进行调试 |
| print $_exitcode | 显示程序退出时的返回值 |
| set follow-fork-mode child | 追踪子进程 |
| set follow-fork-mode parent | 追踪父进程 |
| set detach-on-fork on | fork调用时只追踪其中一个进程 |
| set detach-on-fork off | fork调用时会同时追踪父子进程 |
在调试多进程程序时候,默认情况下,除了当前调试的进程,其他进程都处于挂起状态,所以,如果需要在调试当前进程的时候,其他进程也能正常执行,那么通过设置 set schedule-multiple on 即可。
在默认情况下,GDB 只支持调试主进程(即 main),只有在 GDB 7.0 后才支持单独调试(调试父进程或者子进程)和同时调试多个进程。
多线程
默认调试多线程时,一旦程序中断,所有线程都将暂停。如果此时再继续执行当前线程,其他线程也会同时执行。
| 命令 | 作用 |
|---|---|
| info threads | 查看线程列表 |
| thread [thread_id] | 切换进该线程 |
| print $_thread | 显示当前正在调试的线程编号 |
| set scheduler-locking on | 调试一个线程时,其他线程暂停执行 |
| set scheduler-locking off | 调试一个线程时,其他线程同步执行 |
| set scheduler-locking step | 仅用step调试线程时其他线程不执行,用其他命令如next调试时仍执行 |
如果只关心当前线程,建议临时设置 scheduler-locking 为 on,避免其他线程同时运行,导致命中其他断点分散注意力。
其他
图形化
tui为terminal user interface的缩写,在启动时候指定-tui参数,或者调试时使用ctrl+x+a组合键,可进入或退出图形化界面。
| 命令 | 含义 |
|---|---|
| layout src | 显示源码窗口 |
| layout asm | 显示汇编窗口 |
| layout split | 显示源码 + 汇编窗口 |
| layout regs | 显示寄存器 + 源码或汇编窗口 |
| winheight src +5 | 源码窗口高度增加5行 |
| winheight asm -5 | 汇编窗口高度减小5行 |
| winheight cmd +5 | 控制台窗口高度增加5行 |
| winheight regs -5 | 寄存器窗口高度减小5行 |
汇编
| 命令 | 含义 |
|---|---|
| disassemble function | 查看函数的汇编代码 |
| disassemble /mr function | 同时比较函数源代码和汇编代码 |
其他工具
pstack
pstack 是一个 shell 脚本,用于打印正在运行的进程的栈跟踪信息。pstack 命令必须由相应进程的属主或 root 运行。可以使用 pstack 来确定进程挂起的位置。
使用方式如下:
pstack [pid]
ldd
当我们编译链接时找不到静态库而导致链接失败,又或者是编译成功,在运行时加载动态库失败时,我们可以使用 ldd 命令来分析该程序依赖了哪些库以及这些库所在的路径,从而解程序因缺少某个库文件而不能运行的一些问题。使用方式如下:
ldd 程序名
例如:
ldd test
linux-vdso.so.1 (0x00007ffeefb2f000)
libstdc++.so.6 => /lib64/libstdc++.so.6 (0x00007fa30f54a000)
libm.so.6 => /lib64/libm.so.6 (0x00007fa30f1c8000)
libgcc_s.so.1 => /lib64/libgcc_s.so.1 (0x00007fa30efb0000)
libc.so.6 => /lib64/libc.so.6 (0x00007fa30ebeb000)
/lib64/ld-linux-x86-64.so.2 (0x00007fa30f8df000)
其中每一行的第一个参数程序依赖的库名,第二个则是系统所提供的对应的库(如果系统找不到,则会显示 not found),第三个是库加载的起始地址。
strings、c++filt
C++ 为了支持函数重载功能,需要编译器在使用 name mangling 机制将符号表中的函数进行重命名,而我们使用 strings 就可以查看到重命名后的函数名:
strings 程序名
如果使用 c++filt 工具,就可以根据符号表中的函数名,还原为原始的函数定义:
c++filt 重命名后的函数名
原理
调试原理
当我们开始使用 GDB 开始调试时,系统首先会启动一个 GDB 进程,紧接着这个进程会 fork 出一个子进程来控制被调试程序,它会执行以下操作:
- 调用
ptrace(PTRACE_TRACEME)来让 GDB 进程接管本进程的执行。 - 通过
execv来将被调试程序替换到子进程中。
详细流程如下图所示:
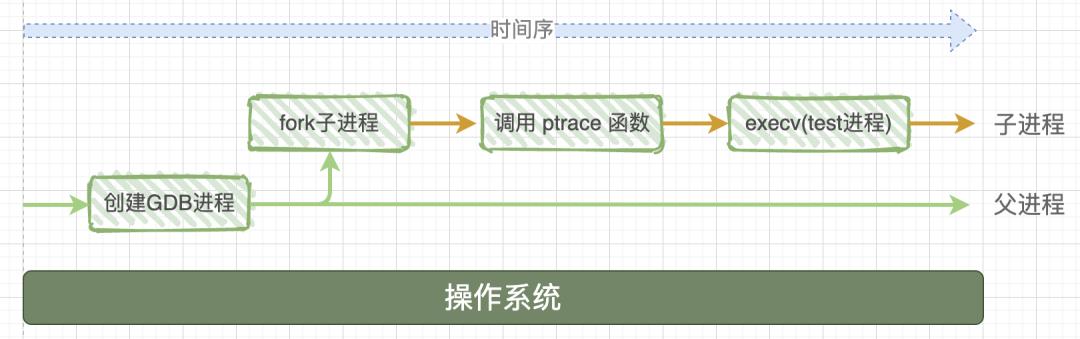
接下来就介绍里面最关键的 ptrace。
ptrace
ptrace 是 Linux 内核提供的一个用于进程跟踪的系统调用,通过它,一个进程(GDB)可以读写另外一个进程(被调试进程)的指令空间、数据空间、堆栈和寄存器的值,并且 GDB 进程接管了被调试进程的所有信号,这样一来,被调试进程的执行就被 GDB 控制,从而达到调试的目的。
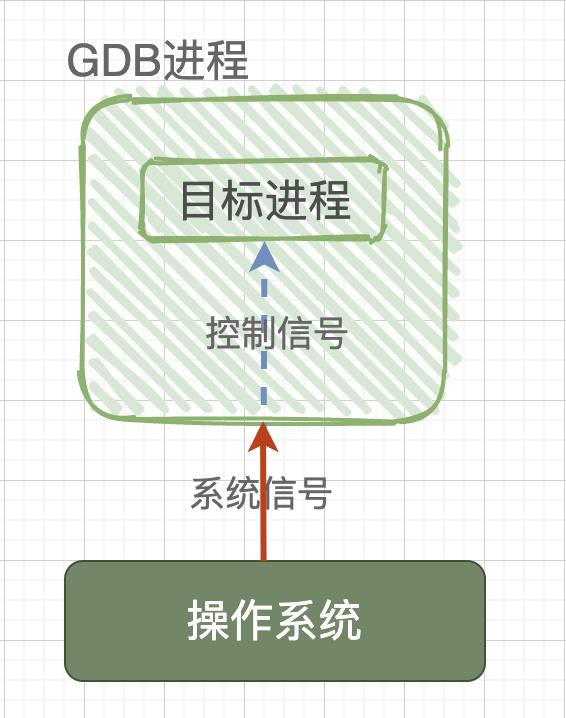
ptrace 的定义如下:
#include <sys/ptrace.h>
long ptrace(enum __ptrace_request request, pid_t pid, void *addr, void *data)
- enum __ptrace_request request:指示了
ptrace要执行的命令。 - pid_t pid:指示 ptrace 要跟踪的进程
- void *addr:指示要监控的内存地址
- void *data:存放读取出的或者要写入的数据。
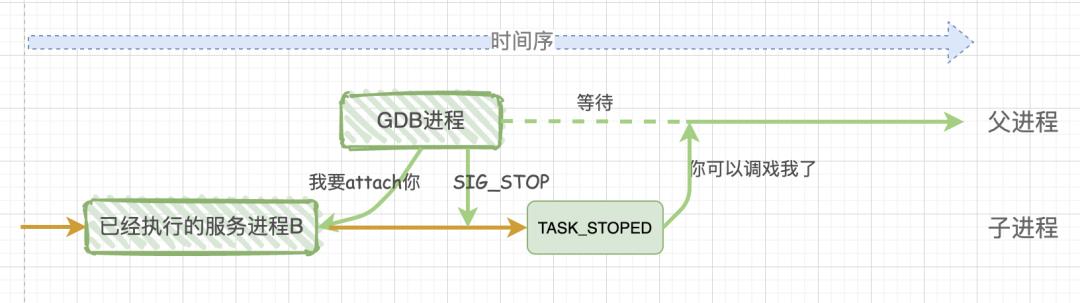
调试运行中程序
如果想要调试一个已经执行的进程,就需要在 GDB 进程中调用 ptrace(PTRACE_ATTACH,...),此时 GDB 进程会 attach 已经执行的被调试进程,将其收养为自己的子进程,接着会向被调试进程发送一个 SIGSTO 信号,当被调试进程接收到这个信号时,就会暂时执行并进入 TASK_STOPED 状态,表示其已经准备好接受调试。
attach的一些限制:不予许attach自己;不允许多次attach到同一个进程;不允许attach1 号进程;
断点 break
当我们使用 break 命令设置断点的时候,GDB 首先会将原来的汇编代码存储到一个断点链表中,接着会在对应的汇编代码的位置插入一个 INT3 中断指令。
当被调试的程序运行到这个位置时,就会执行 INT3 指令,此时会发生软中断,接着内核会向被调试进程发送一个 SIGTRAP 信号,由于当前 GDB 通过 ptrace 接管了被调试进程,所以这个信号自然又转发到了 GDB 进程中。GDB 此时会对比当前停止的位置和断点链表中存储的断点位置,将该位置的代码恢复成断点链表中存储的原来的代码,接着将程序计数器(pc 指针)回退一步,指向用户 break 的位置。
此时就达到了断点的目的,接着 GDB 会一直等待用户输入调试指令。
单步 next
当我们使用 next 执行单步命令时,此时 GDB 会控制其执行一行代码,它首先会计算出这一行代码所对应的汇编代码的位置,接着控制程序计数器一直往下执行,直到执行到这个位置时就会停下来,继续等待用户输入调试指令。
这个功能其实借助 ptrace 就可以直接实现,只需要在第一个参数中传递 PTRACE_SINGLESTEP 即可。
参考
以上是关于从实践到原理掌握 GDB的主要内容,如果未能解决你的问题,请参考以下文章