MRS离线数据分析:通过Flink作业处理OBS数据
Posted 华为云开发者联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MRS离线数据分析:通过Flink作业处理OBS数据相关的知识,希望对你有一定的参考价值。
摘要:MRS支持在大数据存储容量大、计算资源需要弹性扩展的场景下,用户将数据存储在OBS服务中,使用MRS集群仅做数据计算处理的存算分离模式。
本文分享自华为云社区《【云小课】EI第47课 MRS离线数据分析-通过Flink作业处理OBS数据》,作者:Hello EI 。
MRS支持在大数据存储容量大、计算资源需要弹性扩展的场景下,用户将数据存储在OBS服务中,使用MRS集群仅做数据计算处理的存算分离模式。
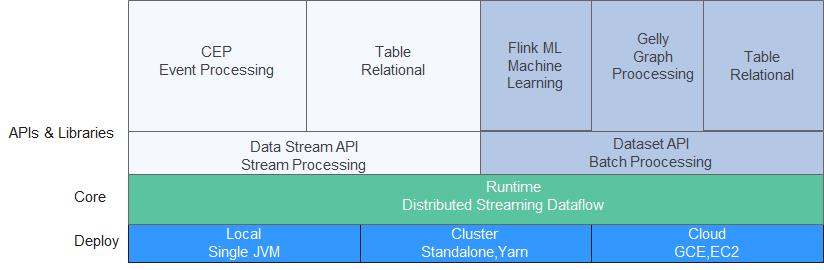
Flink是一个批处理和流处理结合的统一计算框架,其核心是一个提供了数据分发以及并行化计算的流数据处理引擎。它的最大亮点是流处理,是业界最顶级的开源流处理引擎。
本文将向您介绍如何在MRS集群中运行Flink作业来处理OBS中存储的数据。

Flink最适合的应用场景是低时延的数据处理(Data Processing)场景:高并发pipeline处理数据,时延毫秒级,且兼具可靠性。
在本示例中,我们使用MRS集群内置的Flink WordCount作业程序,来分析OBS文件系统中保存的源数据,以统计源数据中的单词出现次数。
当然您也可以获取MRS服务样例代码工程,参考Flink开发指南开发其他Flink流作业程序。
本案例基本操作流程如下所示:
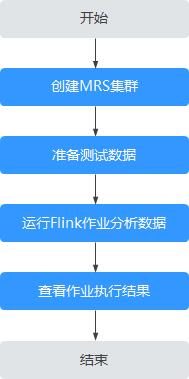
创建MRS集群
创建并购买一个包含有Flink组件的MRS集群,详情请参见购买自定义集群。
本文以购买MRS 3.1.0版本的集群为例,集群未开启Kerberos认证。
在本示例中,由于我们要分析处理OBS文件系统中的数据,因此在集群的高级配置参数中要为MRS集群绑定IAM权限委托,使得集群内组件能够对接OBS并具有对应文件系统目录的操作权限。
您可以直接选择系统默认的“MRS_ECS_DEFAULT_AGENCY”,也可以自行创建其他具有OBS文件系统操作权限的自定义委托。

集群购买成功后,在MRS集群的任一节点内,使用omm用户安装集群客户端,具体操作可参考安装并使用集群客户端。
例如客户端安装目录为“/opt/client”。
准备测试数据
在创建Flink作业进行数据分析前,我们需要在提前准备待分析的测试数据,并将该数据上传至OBS文件系统中。
1、本地创建一个“mrs_flink_test.txt”文件,例如文件内容如下:
This is a test demo for MRS Flink. Flink is a unified computing framework that supports both batch processing and stream processing. It provides a stream data processing engine that supports data distribution and parallel computing.2、在云服务列表中选择“存储 > 对象存储服务”,登录OBS管理控制台。
3、单击“并行文件系统”,创建一个并行文件系统,并上传测试数据文件。
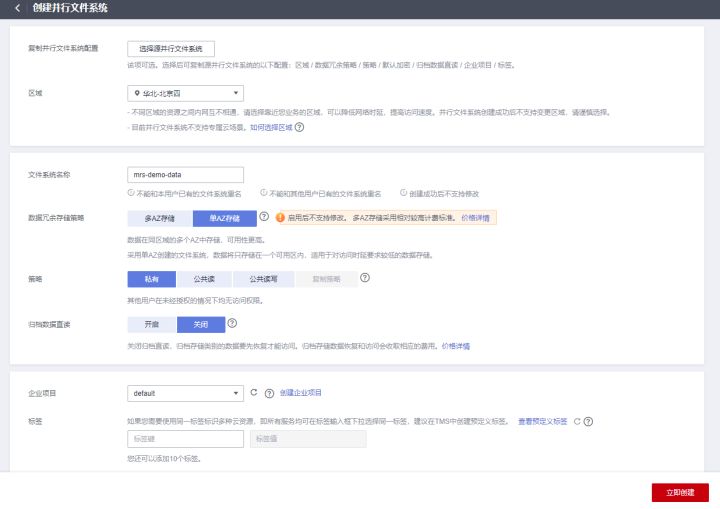
例如创建的文件系统名称为“mrs-demo-data”,单击系统名称,在“文件”页面中,新建一个文件夹“flink”,上传测试数据至该目录中。
则本示例的测试数据完整路径为“obs://mrs-demo-data/flink/mrs_flink_test.txt”。

4、上传数据分析应用程序。
使用管理台界面直接提交作业时,将已开发好的Flink应用程序jar文件也可以上传至OBS文件系统中,或者MRS集群内的HDFS文件系统中。
本示例中我们使用MRS集群内置的Flink WordCount样例程序,可从MRS集群的客户端安装目录中获取,即“/opt/client/Flink/flink/examples/batch/WordCount.jar”。
将“WordCount.jar”上传至“mrs-demo-data/program”目录下。
创建并运行Flink作业
方式1:在控制台界面在线提交作业。
- 登录MRS管理控制台,单击MRS集群名称,进入集群详情页面。
- 在集群详情页的“概览”页签,单击“IAM用户同步”右侧的“单击同步”进行IAM用户同步。
- 单击“作业管理”,进入“作业管理”页签。
- 单击“添加”,添加一个Flink作业。
- 作业类型:Flink
- 作业名称:自定义,例如flink_obs_test。
- 执行程序路径:本示例使用Flink客户端的WordCount程序为例。
- 运行程序参数:使用默认值。
- 执行程序参数:设置应用程序的输入参数,“input”为待分析的测试数据,“output”为结果输出文件。
例如本示例中,我们设置为“--input obs://mrs-demo-data/flink/mrs_flink_test.txt --output obs://mrs-demo-data/flink/output”。
-
- 服务配置参数:使用默认值即可,如需手动配置作业相关参数,可参考运行Flink作业。
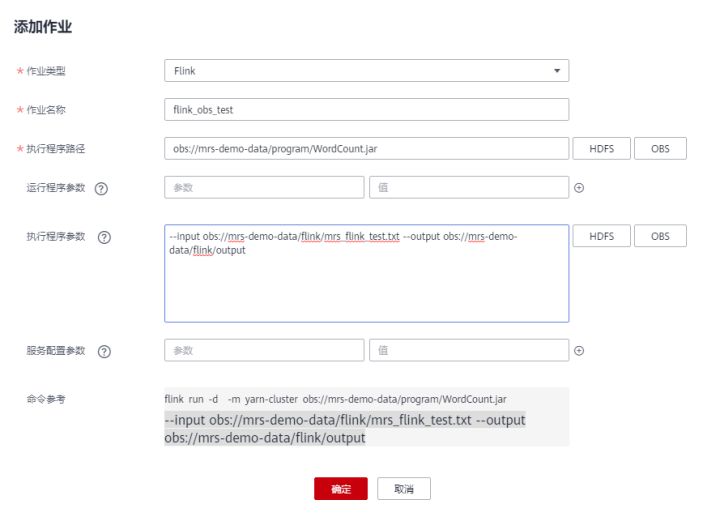
5.确认作业配置信息后,单击“确定”,完成作业的新增,并等待运行完成。

方式2:通过集群客户端提交作业。
1、使用root用户登录集群客户端节点,进入客户端安装目录。
su - omm
cd /opt/client
source bigdata_env2、执行以下命令验证集群是否可以访问OBS。
hdfs dfs -ls obs://mrs-demo-data/flink3、提交Flink作业,指定源文件数据进行消费。
flink run -m yarn-cluster /opt/client/Flink/flink/examples/batch/WordCount.jar --input obs://mrs-demo-data/flink/mrs_flink_test.txt --output obs://mrs-demo/data/flink/output2执行后结果类似如下:
...
Cluster started: Yarn cluster with application id application_1654672374562_0011
Job has been submitted with JobID a89b561de5d0298cb2ba01fbc30338bc
Program execution finished
Job with JobID a89b561de5d0298cb2ba01fbc30338bc has finished.
Job Runtime: 1200 ms查看作业执行结果
- 作业提交成功后,登录MRS集群的FusionInsight Manager界面,选择“集群 > 服务 > Yarn”。
- 单击“ResourceManager WebUI”后的链接进入Yarn Web UI界面,在Applications页面查看当前Yarn作业的详细运行情况及运行日志。
3.等待作业运行完成后,在OBS文件系统中指定的结果输出文件中可查看数据分析输出的结果。

下载“output”文件到本地并打开,可查看输出的分析结果。
a 3
and 2
batch 1
both 1
computing 2
data 2
demo 1
distribution 1
engine 1
flink 2
for 1
framework 1
is 2
it 1
mrs 1
parallel 1
processing 3
provides 1
stream 2
supports 2
test 1
that 2
this 1
unified 1使用集群客户端命令行提交作业时,若不指定输出目录,在作业运行界面也可直接查看数据分析结果。
Job with JobID xxx has finished.
Job Runtime: xxx ms
Accumulator Results:
- e6209f96ffa423974f8c7043821814e9 (java.util.ArrayList) [31 elements]
(a,3)
(and,2)
(batch,1)
(both,1)
(computing,2)
(data,2)
(demo,1)
(distribution,1)
(engine,1)
(flink,2)
(for,1)
(framework,1)
(is,2)
(it,1)
(mrs,1)
(parallel,1)
(processing,3)
(provides,1)
(stream,2)
(supports,2)
(test,1)
(that,2)
(this,1)
(unified,1)以上是关于MRS离线数据分析:通过Flink作业处理OBS数据的主要内容,如果未能解决你的问题,请参考以下文章
云小课|MRS数据分析-通过Spark Streaming作业消费Kafka数据