CVPR论文解读 | 弱监督的高保真服饰模特生成
Posted 阿里巴巴淘系技术团队官网博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CVPR论文解读 | 弱监督的高保真服饰模特生成相关的知识,希望对你有一定的参考价值。

本文在学术界率先提出,使用深度对抗生成网络拟合真实世界穿衣结果分布,设计投影算子来将服饰与人体粗略对齐结果投影至真实世界穿衣结果分布中,将此投影的结果作为虚拟试衣的预测结果。
虚拟试衣技术,是指由人物图片与服饰图片生成人物穿着该服饰图片的技术。随着互联网电商行业的发展,用户在线体验自身试衣效果的需求越来越旺盛,工业界对先进虚拟试衣技术也越发急需。然而,目前已有的传统虚拟试衣技术无论在效果上,还是实现方法的成本上都不尽令人满意。传统虚拟试衣技术大多深度依赖计算机图形学,通过物理建模仿真服饰形变过程,来渲染服饰穿着到人体的结果。服饰的建模通常通过上千乃至上万个精细的三角剖分来形成,然后使用弹簧质点系统计算这些三角剖分的形变以渲染服饰的形变。这样的过程在物理建模上极其复杂,因为服饰穿在人体上产生的形变并不由某一种明确的力场所引导,并且服饰的材质、款型对形变结果的影响极其难以统一建模。同时,这一过程所需的计算量也是相当庞大的。多数现有方法使用成对数据,即人物未穿着目标衣服与人物穿着目标的衣服的图片对,来训练一个神经网络预测引导三角剖分的力场。由于真实世界物理规则的复杂性,这样的方法往往存在严重的过拟合与极低的鲁棒性,当测试集与训练集稍有差异,结果便会大相径庭,严重限制了虚拟试衣算法在工业场景中的应用。同时,成对训练数据的收集是极其昂贵的,也几乎不可能大规模的在百万、亿万的量级收集,这使得这类方法难以在大规模场景中应用。在实践中,广大的中小型服饰经销商既无力提供3D服饰数据,又不可能构造大量成对训练数据针对自己售卖的商品类型进行训练,这导致已有方法暂时很难适应他们的现实需求。

图1:服饰模特图片自动生成示例
然而,在真实世界中,人类的大脑也能预测试穿衣服的结果,这种预测并不基于复杂的物理规则建模,而是更多的基于生活经验。通常,有经验的消费者将衣服粗略的对齐到自己的四肢,然后通过镜子中的影像就可以估计出穿着的效果。在这一过程中,人脑依据自己的大量生活中试穿的经验,根据衣服与四肢粗略的对齐关系,就可以“想象”出实际穿着的结果。这一过程并不依赖于复杂的物理公式演绎,而更接近一种在概率分布上的近似---人脑自动寻找在真实世界穿衣结果的分布中,与当前在镜子中看到的衣服与四肢粗略对齐结果最为接近的样本点。
受此启发,本文在学术界率先提出,使用深度对抗生成网络拟合真实世界穿衣结果分布,设计投影算子来将服饰与人体粗略对齐结果投影至真实世界穿衣结果分布中,将此投影的结果作为虚拟试衣的预测结果。首先,我们使用大量廉价的人物图片来训练一个生成对抗网络,这一网络能学习到真实世界中人们穿衣的结果分布。使用廉价的人物图片大大降低了训练成本,因为相比传统算法所需的成对训练数据,单独的人物图片是非常容易收集的。而后,我们设计了一个三层投影算子,将人物与衣服粗略对齐的结果投影到之前训练的对抗生成网络的生成样本空间中与此粗对齐结果最近的样本点。由于此样本点属于与训练的对抗生成网络的生成空间,因此它必然具备高清晰度、高逼真度,并符合真实世界的穿衣风格;又由于此样本点是距离粗对齐结果最近的点,其必然包含了最大量的原始人物和服饰的信息,包括人物的姿势、身材、肤色,服饰的款型、颜色、纹理和图案。显然,这一结果是一个合理的虚拟试衣预测结果。这一方法仅需要少数对服饰属性,如袖型、领型、服饰种类、衣长等的标注,这些标注在现实场景中都是易于获取的。因此,本文所提出的算法具有较大的潜在应用前景和商业价值。
同时,这一技术路线最大限度的规避了对复杂物理形变规则的依赖,从而达到1)摆脱了传统方法对昂贵的成对训练数据(同一模特未穿给定服饰与穿上给定服饰)的依赖,只需要收集成本极低的无监督数据,从而使得大规模的训练试衣算法成为可能;2)显著的提高了试衣结果的清晰度与逼真度,以及服饰图案花纹的保真度,远远超越同期SOTA算法;3)显著提高了对复杂衣服类型的鲁棒性,比如大衣、外套、连衣裙等,而传统方法大多只在简单衣物如T恤,衬衫等上有较好的效果。同时,这一技术路线也率先探索了,回避形变规则,完全基于深度对抗生成网络来进行虚拟试衣的技术路线,证明了虚拟试衣技术的发展不必依赖于代价昂贵的形变算法,具有重要的学术意义。
背景
已有的虚拟试衣方法可以分为两类:基于3D建模的试衣方法与基于2D图像的试衣方法。由于基于3D建模的试衣方法需要搜集复杂的3D数据进行渲染,基于2D图像的方法目前更为流行。多数已有的基于2D图像的试衣方法将虚拟试衣分成两步:一个服饰形变步与一个图像融合步。在服饰形变步,算法通过TPS等参数化形变算法预测服饰传到人体上的形变过程,而后形变后的服饰在图像融合步融合进原始模特图像中形成试衣结果。这一过程涉及到学习服饰形变中的复杂物理规律,因此往往需要大量的成对训练数据(服饰,模特穿着此服饰)来进行监督训练。同时,由于物理规则的复杂性,这样的监督训练在数据不足时容易产生过拟合,因而泛化性能较差。往往数据集发生变化时,原有的网络就不再有效,产生非常扭曲失真的结果。另一类基于2D图像的试衣方法依据StyleGAN的属性解耦,将服饰视为一种属性,从模特身上恢复出这种属性。然而,对于特定的服饰图案,比如文字、符号、图画,StyleGAN所存储的属性中显然无法包含这些复杂的高频信息,因此这类方法在处理服饰图案时往往无法精确重建。
本文所提出的算法通过三层不同粒度的投影算子,由粗略到精细的重构出服饰的类型、款式,局部语义(纹理、褶皱等),以及精确图案。即回避了直接建模复杂形变规则所带来的成对训练数据需求,又能高清晰度的重构图案的细节纹理。从而首次达成了商业化落地的两个基础条件:控制成本与高保真。
方法

图2:方法框架
我们首先将服饰从服饰白底图中裁剪出,并通过人体的四个关键点与模特身躯对齐得到粗对其图(a)(如果服饰涉及长袖,则会额外增加四个袖子关键点,并通过双调和形变对齐袖子与人的胳膊)。这一步作为算法的预处理输入。输入的粗对其图首先通过一个预训练的投影网络投射到StyleGAN的隐空间中,得到第一次投影点(b)。这次投影将重构出服饰的高阶语义,如颜色,基本款式,以及模特的身材、姿势等。而后,从第一次投影点(b)开始,我们通过投影梯度下降法求解其邻域内一个能更好重构服饰局部意义的隐变量,作为语义搜寻的结果(b)。最后,我们通过优化生成器的部分参数,获得一个能精确重构服饰图案的参数点,以此来生成最终穿衣结果,这一步称为图案搜寻(c)。图案搜寻结果即为算法输出结果。
图2简述了我们的算法基本框架。算法由四步骤构成,一个粗对其的预处理输入,以及后续的三层次语义搜寻。如前文所述,此过程是对人“想象试衣结果过程”的一个模仿。人在试穿衣物时,会将衣服的关键点与自身的关键点对齐,然后想象实际试穿的结果。粗对其模仿的就是人将衣服与自身关键点对齐的步骤,而后的三层次语义搜寻,则是模仿人依据自身经验想象穿衣结果的过程。
(a):粗对齐
我们首先通过预训练的服饰parsing网络将服饰从服饰白底图中裁剪出来。然后通过预训练的服饰关键点与人体关键点模型,简历四个服饰关键点与人体关键点的对应关系。通过这一对应关系,我们可以求解一个仿射变换,将服饰的四个关键点与人体的四个关键点对齐。由此得到了粗对齐结果。特别的,当服饰为长袖衣服时,单纯的仿射变换无法对齐袖子与人的手臂,必须要使用弹性形变。因此我们在此时额外采集袖子上的四个关键点与人手臂的四个关键点,进行双调和形变(BBW形变)。以使得服饰袖子与人手臂也保持大致对齐。
(b):投影步
我们在大量搜集到的无监督服饰模特数据上训练了一个StyleGAN与一个对应的投影子(Projector)。投影子的作用是将给定图片投影到StyleGAN的隐空间,并获得一个大致能重构出给定图片的隐变量。与一般的GAN inversion算法不同,投隐子会对输出进行截断,从而保证所求得得隐变量一定出于StyleGAN隐空间得高密度区域,以此获得一个对后续搜索性质友好得点。
(c):语义搜寻
获得了投影点后,我们需要精确重构服饰得语义,包括服饰得袖子款式,行政,纹理,领口款式等。这里我们通过求解如下限制最优化问题来获得语义搜寻结果:
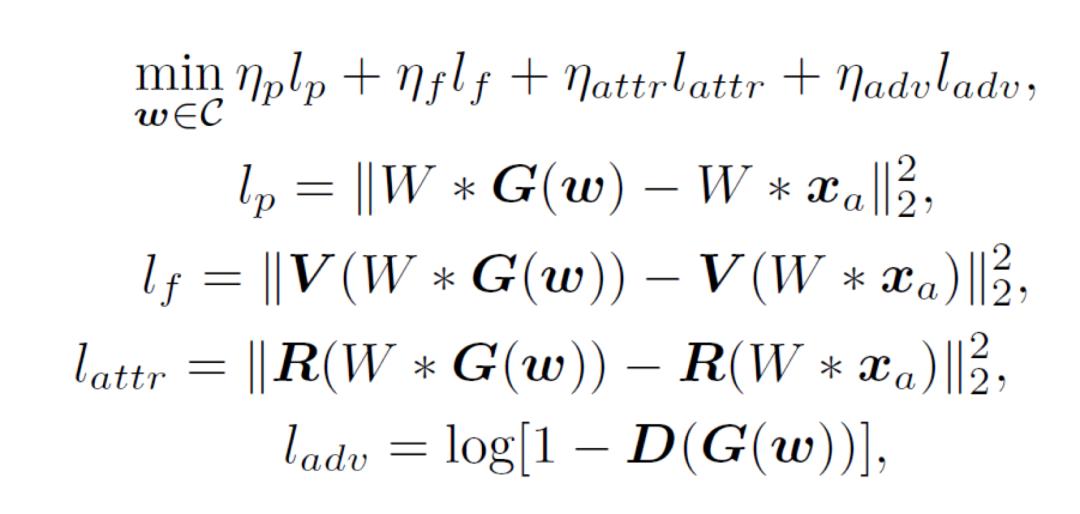
这里W是一个预定义图像mask,他通过简单得逻辑运算(图3)获得我们需要在语义搜寻中重点关注得区域,是预处理得到得粗对齐输入,G和D分别是StyleGAN得生成与鉴别器,R是预训练得服饰属性分类器得最后一层特征输出,而V是在ImageNet上预训练得VGG网络得最后一层卷积输出。C是上一步得到得投影点附近得一个球行邻域,用以约束搜索过程位于StyleGAN得高密度隐空间区域。求解时,我们将w得初始值设置为上一步求得的投影点,并使用投影梯度下降法(Projected Gradient Descent)。

图3:mask W的计算方式
(d)图案搜索:
语义搜素是在StyleGAN的隐空间完成的,因此语义搜索的结果时StyleGAN中已经存在的信息。而服饰的具体图案,如文字,符号,图画等,不可能预先存在于StyleGAN之中,因为这些极其特别的高频信息大概率也没有出现过在StyleGAN的训练数据之中。因此,必须使用更为广阔的空间才能搜索出这些信息。这里我们使用了StyleGAN生成器的参数空间。如果给与数据集,StyleGAN生成器理论上可以生成任何东西。因此,生成器的参数空间必然包含了能生成具体图案的参数点。依据此,我们在参数空间中对服饰具体图案进行重构,即求解如下问题
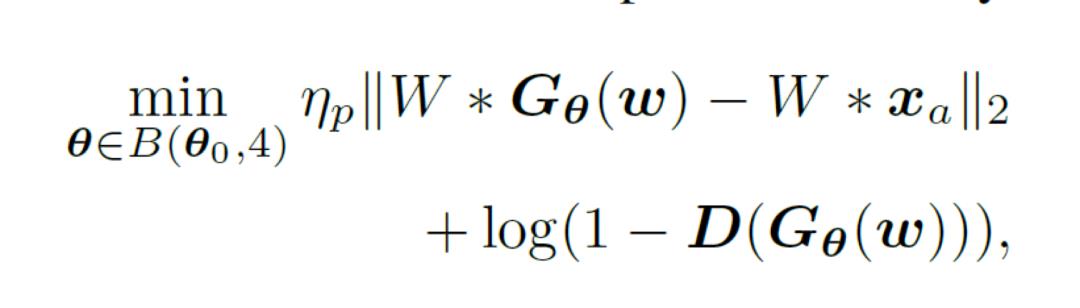
定性比较
我们与三个监督训练的SOTA算法进行比较,分别是ACGPN,VITON-HD,与PF-AFN。值得注意的是,这三个算法都是使用成对数据进行强监督训练的,而我们的DGP算法使用的是非成对无监督数据。测试数据集为我们主动搜集的CMI数据集,以及先前已经存在的MPV数据集。值得强调的是,MPV数据集与ACGPN,PF-AN,VITON-HD的训练数据集是近似同分布的,采样于同一个特定数据库。而DGP在训练阶段从未接触过CMI与MPV数据集,并且其训练集与这两个数据集也有很大不同。即便如此,我们依然可以发现DGP的结果要显著优于此前的三个SOTA算法。

图4:定性比较
定量比较
我们同时比较了DGP与三个SOTA算法的定量指标,如FID,SWD,以及用户满意度。我们发现DGP基本上在所有指标上都保持领先。这里依然需要强调的是,在计算FID与SWD指标时,我们使用的groundtruth是MPV数据集,即与ACGPN、PF-AFN、VITON-HD训练集分布极其相近的数据集,而DGP在训练中使用的数据集与之差异极大。因此这样的结果更加说明了DGP算法的优越。
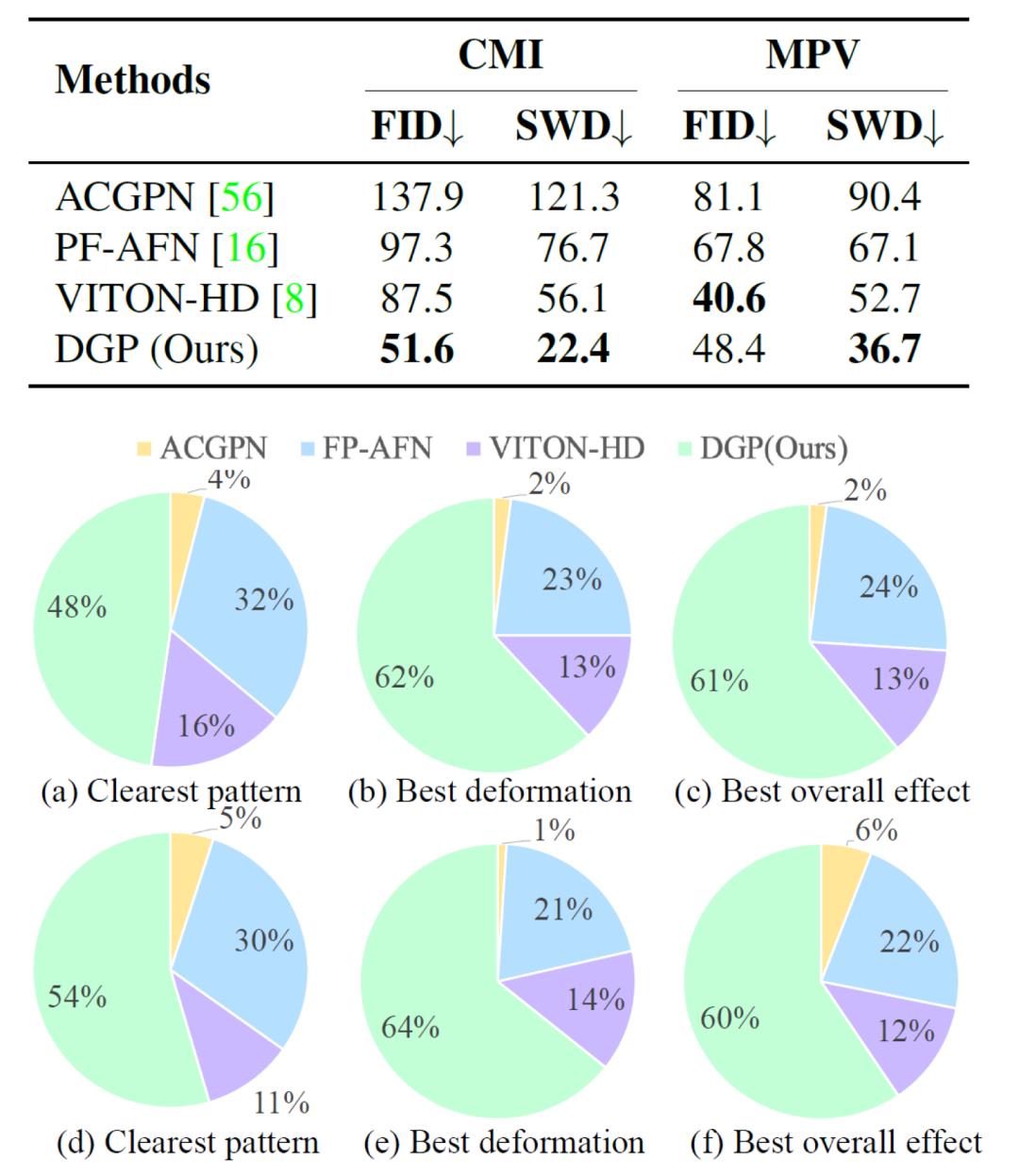
图5:数值指标与用户调查指标
鲁棒性
DGP算法对于预处理阶段的一些误差和扰动具有很强的鲁棒性,许多的瑕疵都可以在被算法自动纠正过来,这得益于投影子的强大能力,如图6所示。我们将这一能力与现有的SOTA GAN inversion算法pSp做对比,可以发现这一能力是投影子所独有的,如图7所示。

图6:投影子面对错误输入做出的自动纠正
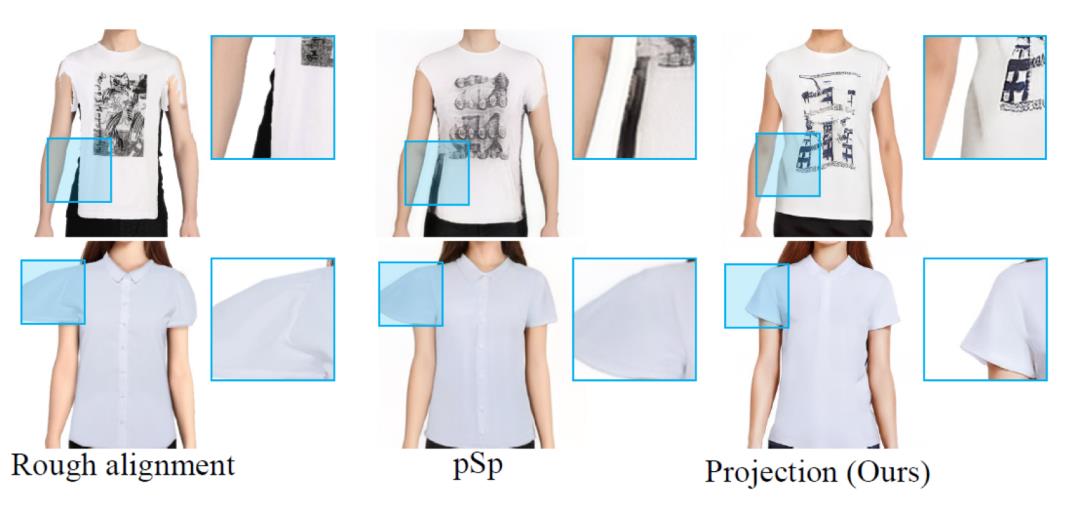
图7:投影子与pSp算法的鲁棒性对比
结论
本文提出了一种只使用若监督数据的服饰模特生成算法。相较于传统算法,本文提出的方法避免了使用代价高昂的成对训练数据,因而可以有效的扩展在大规模场景中。同时,本文提出的算法具有高鲁棒性、高清晰度、高准确度的特点,弥补了以往算法在面对域偏差时的性能严重下降,以及对服饰精细图案重构不精确的问题。
地址
Github地址:
https://github.com/RuiLiFeng/Deep-Generative-Projection
Project Page:
https://ruilifeng.github.io/Deep-Generative-Projection/
Pape地址:https://openaccess.thecvf.com/content/CVPR2022/papers/Feng_Weakly_Supervised_High-Fidelity_Clothing_Model_Generation_CVPR_2022_paper.pdf
✿ 拓展阅读


作者|艾尔
编辑|橙子君

以上是关于CVPR论文解读 | 弱监督的高保真服饰模特生成的主要内容,如果未能解决你的问题,请参考以下文章