大数据平台后端一些开发规范
Posted 脚丫先生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据平台后端一些开发规范相关的知识,希望对你有一定的参考价值。
大家好,我是脚丫先生 (o^^o)
集团大数据平台之流批一体的建设之后。
一直想着能研发一套自己沉淀的小型大数据平台项目。
之后能与小伙伴们多多交流。
在研发的过程中,总结一些开发规范(参考全网),希望可以帮助到小伙伴们。
一、编程规范
1.1 好代码的原则
参考 Kent Beck 的简单设计四原则来指导我们的如何写出优秀的代码,如何有效地判断我们的代码是优秀的。
(1)通过所有测试(Passes its tests):强调的是外部需求,这是代码实现最重要的。
(2)尽可能消除重复 (Minimizes duplication):代码的模块架构设计,保证代码的正交性,保证代码更容易修改。
(3)尽可能清晰表达 (Maximizes clarity):代码的可阅读性,保证代码是容易阅读的。
(4)更少代码元素 (Has fewer elements):保证代码是简洁的,在简洁和表达力之间,我们更看重表达力。
以上四个原则的重要程度依次降低, 这组定义被称做简单设计原则。
1.2 命名风格
(1)代码中的命名均不能以下划线或美元符号开始,也不能以下划线或美元符号结束。
反例:_name / name / n a m e / n a m e / n a m e name / name_ / name name/name/name / name
(2)代码中的命名严禁使用拼音与英文混合的方式,更不允许直接使用中文的方式。
(3)类名使用 UpperCamelCase 风格,但以下情形例外:DO / BO / DTO / VO / AO / PO / UID 等。
正例:JavaServerlessPlatform / UserDO / XmlService / TcpUdpDeal / TaPromotion
反例:javaserverlessplatform / UserDo / XMLService / TCPUDPDeal / TAPromotion
(4) 方法名、参数名、成员变量、局部变量都统一使用 lowerCamelCase 风格,必须遵从驼峰形式。
正例: localValue / getHttpMessage() / inputUserId
(5)常量命名全部大写,单词间用下划线隔开,力求语义表达完整清楚,不要嫌名字长。
正例:MAX_STOCK_COUNT / CACHE_EXPIRED_TIME
(6)抽象类命名使用 Abstract 或 Base 开头;异常类命名使用 Exception 结尾;测试类命名以它要测试的类的名称开始,以 Test 结尾。
(7)包名统一使用小写,点分隔符之间有且仅有一个自然语义的英语单词。
正例:应用工具类包名为 com.alibaba.ai.util、类名为 MessageUtils(此规则参考 spring 的框架结构)
(8)避免在子父类的成员变量之间、或者不同代码块的局部变量之间采用完全相同的命名,使可读性降低。
反例:
public class ConfusingName
public int age;
// 非 setter/getter 的参数名称,不允许与本类成员变量同名
public void getData(String alibaba)
if(condition)
final int money = 531;
// ...
for (int i = 0; i < 10; i++)
// 在同一方法体中,不允许与其它代码块中的 money 命名相同
final int money = 615;
// ...
class Son extends ConfusingName
// 不允许与父类的成员变量名称相同
public int age;
(9) 在常量与变量的命名时,表示类型的名词放在词尾,以提升辨识度。
正例:startTime / workQueue / nameList / TERMINATED_THREAD_COUNT
反例:startedAt / QueueOfWork / listName / COUNT_TERMINATED_THREAD
(10) 接口类中的方法和属性不要加任何修饰符号(public 也不要加),保持代码的简洁性,并加上有效的 Javadoc 注释。尽量不要在接口里定义变量,如果一定要定义变量,肯定是与接口方法相关,并且是整个应用的基础常量。
正例:接口方法签名 void commit();
接口基础常量 String COMPANY = “alibaba”;
反例:接口方法定义 public abstract void f();
(11) 枚举类名带上 Enum 后缀,枚举成员名称需要全大写,单词间用下划线隔开。
正例:枚举名字为 ProcessStatusEnum 的成员名称:SUCCESS / UNKNOWN_REASON。
1.3 项目命名规范
全部采用小写方式, 以中划线分隔。
正例:mall-management-system / order-service-client / user-api
反例:mall_management-system / mallManagementSystem / orderServiceClient
1.4 方法参数规范
无论是 controller,service,manager,dao 亦或是其他的代码,每个方法最多 3 个参数,如果超出 3 个参数的话,要封装成 javabean 对象。
(1) 方便他人调用,降低出错几率。尤其是当参数是同一种类型,仅仅依靠顺序区分,稍有不慎便是灾难性后果,而且排查起来也极其恶心。
(2) 保持代码整洁、清晰度。当一个个方法里充斥着一堆堆参数的时候,再坚强的人,也会身心疲惫。
反例:
/**
* 使用证书加密数据工具方法
*
* @param param
* @param password 加密密码
* @param priCert 私钥
* @param pubCert 公钥
* @return 返回加密后的字符串
*/
public String signEnvelop(JdRequestParam param, String password, String priCert, String pubCert)
二、项目规范
2.1 1、代码目录结构
统一的目录结构是所有项目的基础。
src 源码目录
|-- common 各个项目的通用类库
|-- config 项目的配置信息
|-- constant 全局公共常量
|-- handler 全局处理器
|-- interceptor 全局连接器
|-- listener 全局监听器
|-- module 各个业务
|-- |--- employee 员工模块
|-- |--- role 角色模块
|-- |--- login 登录模块
|-- third 三方服务,比如redis, oss,微信sdk等等
|-- util 全局工具类
|-- Application.java 启动类
2.1.2 common 目录规范
common 目录用于存放各个项目通用的项目,但是又可以依照项目进行特定的修改。
src 源码目录
|-- common 各个项目的通用类库
|-- |--- anno 通用注解,比如权限,登录等等
|-- |--- constant 通用常量,比如 ResponseCodeConst
|-- |--- domain 全局的 javabean,比如 BaseEntity,PageParamDTO 等
|-- |--- exception 全局异常,如 BusinessException
|-- |--- json json 类库,如 LongJsonDeserializer,LongJsonSerializer
|-- |--- swagger swagger 文档
|-- |--- validator 适合各个项目的通用 validator,如 CheckEnum,CheckBigDecimal 等
2.1.3 config 目录规范
config 目录用于存放各个项目通用的项目,但是又可以依照项目进行特定的修改。
src 源码目录
|-- config 项目的所有配置信息
|-- |--- MvcConfig mvc的相关配置,如interceptor,filter等
|-- |--- DataSourceConfig 数据库连接池的配置
|-- |--- MybatisConfig mybatis的配置
|-- |--- .... 其他
2.1.4 module 目录规范
module 目录里写项目的各个业务,每个业务一个独立的顶级文件夹,在文件里进行 mvc 的相关划分。
其中,domain 包里存放 entity, dto, vo,bo 等 javabean 对象
src
|-- module 所有业务模块
|-- |-- role 角色模块
|-- |-- |--RoleController.java controller
|-- |-- |--RoleConst.java role相关的常量
|-- |-- |--RoleService.java service
|-- |-- |--RoleDao.java dao
|-- |-- |--domain domain
|-- |-- |-- |-- RoleEntity.java 表对应实体
|-- |-- |-- |-- RoleDTO.java dto对象
|-- |-- |-- |-- RoleVO.java 返回对象
|-- |-- employee 员工模块
|-- |-- login 登录模块
|-- |-- email 邮件模块
|-- |-- .... 其他
2.1.5 domain 包中的 javabean 命名规范
建议对象使用 lombok 的 @Builder ,@NoArgsConstructor,同时使用这两个注解,简化对象构造方法以及set方法。
正例:
@Builder
@NoArgsConstructor
@Data
public class DemoDTO
private String name;
private Integer age;
// 使用示例:
DemoDTO demo = DemoDTO.builder()
.name("yeqiu")
.age(66)
.build();
2.1.6 数据对象;XxxxEntity,要求:
(1) 以 Entity 为结尾(阿里是为 DO 为结尾)
(2) Xxxx 与数据库表名保持一致
(3) 类中字段要与数据库字段保持一致,不能缺失或者多余
(4) 类中的每个字段添加注释,并与数据库注释保持一致不允许有组合
项目内的日期类型必须统一,建议使用 java.util.Date,java.sql.Timestamp,java.time.LocalDateTime 其中只一。
三、MVC 规范
3.1 整体分层
controller 层
service 层
impl 层
dao 层
3.2 controller 层规范
(1) 只允许在 method 上添加 RequestMapping 注解,不允许加在 class 上(为了方便的查找 url,放到 url 不能一次性查找出来)
正例:
@RestController
public class DepartmentController
@GetMapping("/department/list")
public ResponseDTO<List<DepartmentVO>> listDepartment()
return departmentService.listDepartment();
反例
@RequestMapping ("/department")
public class DepartmentController
@GetMapping("/list")
public ResponseDTO<List<DepartmentVO>> listDepartment()
return departmentService.listDepartment();
(2) 不推荐使用 rest 命名 url, 只能使用 get/post 方法。url 命名上规范如下:
/业务模块/子模块/动作
正例:
GET /department/get/id 查询某个部门详细信息
POST /department/query 复杂查询
POST /department/add 添加部门
POST /department/update 更新部门
GET /department/delete/id 删除部门
(3) 每个方法必须添加 swagger 文档注解 @ApiOperation ,并填写接口描述信息,描述最后必须加上作者信息 @author 作者 。
正例:
@ApiOperation("更新部门信息 @author 作者")
@PostMapping("/department/update")
public ResponseDTO<String> updateDepartment(@Valid @RequestBody DeptUpdateDTO deptUpdateDTO)
return departmentService.updateDepartment(deptUpdateDTO);
(4) controller 负责协同和委派业务,充当路由的角色,每个方法要保持简洁:
不做任何的业务逻辑操作
不做任何的参数、业务校验,参数校验只允许使用@Valid 注解做简单的校验
不做任何的数据组合、拼装、赋值等操作
正例:
@ApiOperation("添加部门 @author 哪吒")
@PostMapping("/department/add")
public ResponseDTO<String> addDepartment(@Valid @RequestBody DepartmentCreateDTO departmentCreateDTO)
return departmentService.addDepartment(departmentCreateDTO);
(5) 只能在 controller 层获取当前请求用户,并传递给 service 层。
正例
@ApiOperation("添加员工 @author yandanyang")
@PostMapping("/employee/add")
public ResponseDTO<String> addEmployee(@Valid @RequestBody EmployeeAddDTO employeeAddDTO)
LoginTokenBO requestToken = SmartRequestTokenUtil.getRequestUser();
return employeeService.addEmployee(employeeAddDTO, requestToken);
3.3 service 层规范
(1) 合理拆分 service 文件,如果业务较大,请拆分为多个 service
如订单业务,所有业务都写到 OrderService 中会导致文件过大,故需要进行拆分如下:
OrderQueryService 订单查询业务
OrderCreateService 订单新建业务
OrderDeliverService 订单发货业务
OrderValidatorService 订单验证业务
3.4 iml层规范一些开发规范
(1) 封装业务逻辑
如果你看过“屎山”你就会有深刻的感触,这特么一个方法能写几千行代码,还无任何规则可言…往往负责的人会说,这个业务太复杂,没有办法改善,实际上这都是懒的借口。不管业务再复杂,我们都能够用合理的设计、封装去提升代码可读性。下面贴两段高级开发(假装自己是高级开发)写的代码
正例 1:
@Transactional
public ChildOrder submit(Long orderId, OrderSubmitRequest.Shop shop)
ChildOrder childOrder = this.generateOrder(shop);
childOrder.setOrderId(orderId);
//订单来源 APP/微信小程序
childOrder.setSource(userService.getOrderSource());
// 校验优惠券
orderAdjustmentService.validate(shop.getOrderAdjustments());
// 订单商品
orderProductService.add(childOrder, shop);
// 订单附件
orderAnnexService.add(childOrder.getId(), shop.getOrderAnnexes());
// 处理订单地址信息
processAddress(childOrder, shop);
// 最后插入订单
childOrderMapper.insert(childOrder);
this.updateSkuInventory(shop, childOrder);
// 发送订单创建事件
applicationEventPublisher.publishEvent(new ChildOrderCreatedEvent(this, shop, childOrder));
return childOrder;
正例 2:
@Transactional
public void clearBills(Long customerId)
// 获取清算需要的账单、deposit等信息
ClearContext context = getClearContext(customerId);
// 校验金额合法
checkAmount(context);
// 判断是否可用优惠券,返回可抵扣金额
CouponDeductibleResponse deductibleResponse = couponDeducted(context);
// 清算所有账单
DepositClearResponse response = clearBills(context);
// 更新 l_pay_deposit
lPayDepositService.clear(context.getDeposit(), response);
// 发送还款对账消息
repaymentService.sendVerifyBillMessage(customerId, context.getDeposit(), EventName.DEPOSIT_SUCCEED_FLOW_REMINDER);
// 更新账户余额
accountService.clear(context, response);
// 处理清算的优惠券,被用掉或者解绑
couponService.clear(deductibleResponse);
// 保存券抵扣记录
clearCouponDeductService.add(context, deductibleResponse);
这段两代码里面其实业务很复杂,内部估计保守干了五万件事情,但是不同水平的人写出来就完全不同,不得不赞一下这个注释,这个业务的拆分和方法的封装。一个大业务里面有多个小业务,不同的业务调用不同的 service 方法即可,后续接手的人即使没有流程图等相关文档也能快速理解这里的业务,而很多初级开发写出来的业务方法就是上一行代码是 A 业务的,下一行代码是 B业务的,在下面一行代码又是 A 业务的,业务调用之间还嵌套这一堆单元逻辑,显得非常混乱,代码还多。
(2) 判断集合类型不为空的正确方式
很多人喜欢写这样的代码去判断集合
if (list == null || list.size() == 0)
return null;
当然你硬要这么写也没什么问题…但是不觉得难受么,现在框架中随便一个 jar 包都有集合工具类,比如
org.springframework.util.CollectionUtils、com.baomidou.mybatisplus.core.toolkit.CollectionUtils 。
以后请这么写
if (CollectionUtils.isEmpty(list) || CollectionUtils.isNotEmpty(list))
return null;
(3) 集合类型返回值不要 return null
当你的业务方法返回值是集合类型时,请不要返回 null,正确的操作是返回一个空集合。你看 mybatis 的列表查询,如果没查询到元素返回的就是一个空集合,而不是 null。否则调用方得去做 NULL 判断,多数场景下对于对象也是如此。
(4) 映射数据库的属性尽量不要用基本类型
我们都知道 int/long 等基本数据类型作为成员变量默认值是 0。现在流行使用 mybatisplus 、mybatis 等 ORM 框架,在进行插入或者更新的时候很容易会带着默认值插入更新到数据库。我特么真想砍了之前的开发,重构的项目里面实体类里面全都是基本数据类型。
(5)封装判断条件
反例:
public void method(LoanAppEntity loanAppEntity, long operatorId)
if (LoanAppEntity.LoanAppStatus.OVERDUE != loanAppEntity.getStatus()
&& LoanAppEntity.LoanAppStatus.CURRENT != loanAppEntity.getStatus()
&& LoanAppEntity.LoanAppStatus.GRACE_PERIOD != loanAppEntity.getStatus())
//...
return;
这段代码的可读性很差,这 if 里面谁知道干啥的?我们用面向对象的思想去给 loanApp 这个对象里面封装个方法不就行了么?
public void method(LoanAppEntity loan, long operatorId)
if (!loan.finished())
//...
return;
LoanApp 这个类中封装一个方法,简单来说就是这个逻辑判断细节不该出现在业务方法中。
/**
* 贷款单是否完成
*/
public boolean finished()
return LoanAppEntity.LoanAppStatus.OVERDUE != this.getStatus()
&& LoanAppEntity.LoanAppStatus.CURRENT != this.getStatus()
&& LoanAppEntity.LoanAppStatus.GRACE_PERIOD != this.getStatus();
(6) 参数传递不要使用Map、JSONObject或者实体类,使用DTO传递

使用Map或者JSONObject传递,后面维护的人员不知道传递的参数是什么,还要一一和前端核实,非常麻烦;实体类是用来封装数据的,而不是用来传递数据的,不能将它们两个混着使用,代码会很乱
(7)for里不建议写io。io包括:数据库、缓存,文件读写等
对数据库的操作是操作IO的,频繁的操作IO是非常耗性能的,因此代码当中,要杜绝编写循环操作数据库的代码,这里举个例子。
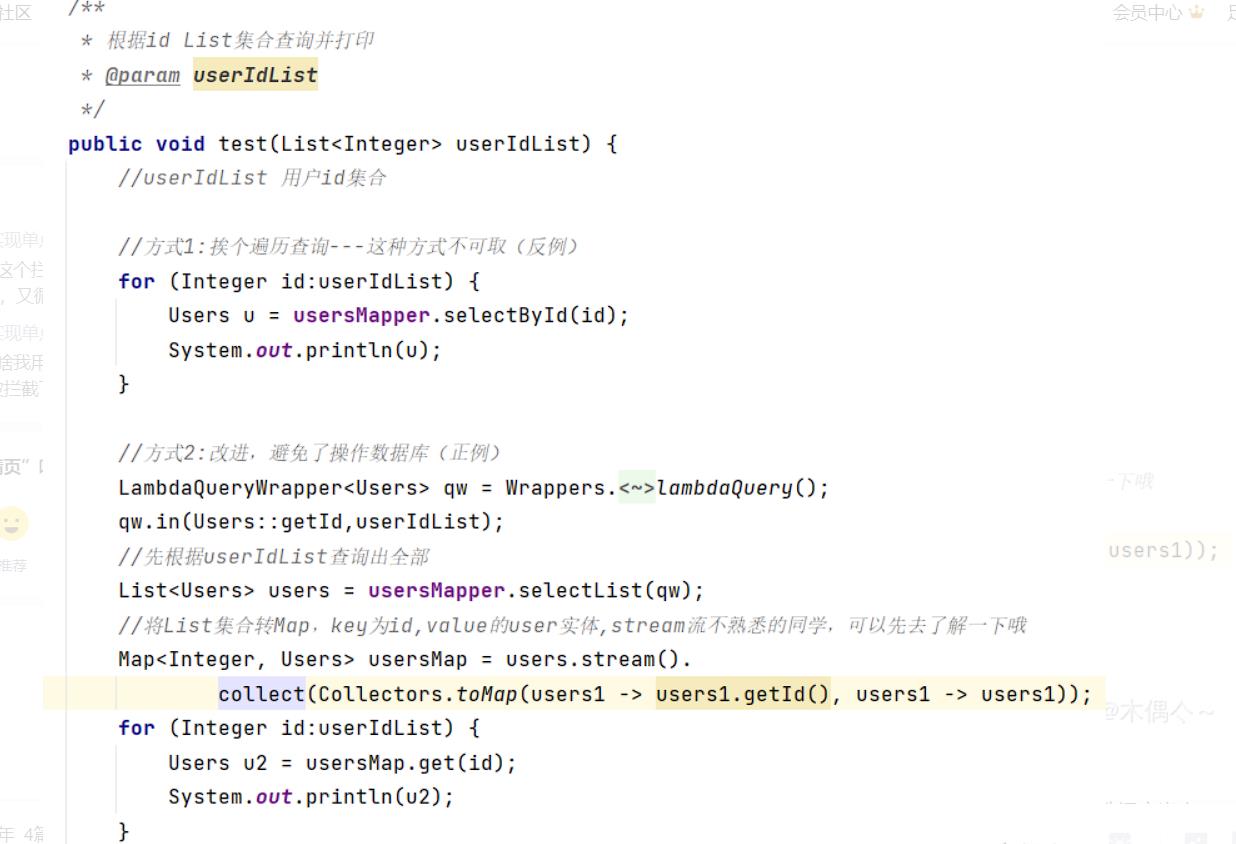
上图,改进后的代码虽然变多了一些,但是,避免了循环操作数据库,特别是当userIdList数据比较多或者数据库当中users表数据量比较大的时候,方式2的速度相比方式1肉眼可见的快。
(8) 禁止使用魔法值
反例
if (users.getType()==1)
正例: 定义一个枚举
@AllArgsConstructor
@Getter
public enum UserTypeEnum
ADMIN(1,"管理员"),
TEACHER(2,"老师"),
STUDENT(3,"学生");
private Integer type;
private String desc;
然后再使用
if (users.getType()== UserTypeEnum.ADMIN.getType())
(9) 异常处理
捕获异常是为了处理它,不要捕获了却什么都不处理而抛弃之,如果不想处理它,请 将该异常抛给它的调用者。最外层的业务使用者,必须处理异常,将其转化为用户可以理解的内容。
大量try catch 对代码阅读性和性能解析都不太友好
反例:
@GetMapping("/list")
public Result<Map<String, Object>> getPerformanceList(AdminPerformanceSearchVO searchVO, PageVO pageVO,
HttpServletRequest request)
logger.info("PC端订单查询请求参数:"+searchVO.toString());
UserDO user = ShiroUtils.getUser();
Query query = new Query(pageVO);
Map<String, Object> params = MapperUtils.obj2Map(searchVO);
query.putAll(params);
try
formatParams(query);
catch (DataFormatException e)
e.printStackTrace();
logger.error(e.getMsg());
return new ResultUtil<Map<String, Object>>().setErrorMsg(e.getMsg());
Map<String, Object> map = null;
try
map = adminAlyPerformanceService.getList(query, user);
catch (BusinessException e)
e.printStackTrace();
logger.error(e.getMessage());
return new ResultUtil<Map<String, Object>>().setErrorMsg(e.getMessage());
return new ResultUtil<Map<String, Object>>().setData(map);
正例:采用全局统一异常处理
全局统一异常
@RestControllerAdvice
@Slf4j
public class GlobalExceptionHandler
@ExceptionHandler(value = DataFormatException.class)
public Result<?> validationExceptionHandler(DataFormatException e)
log.error("系统异常DataFormatException:",e);
BindingResult bindingResult = e.getBindingResult();
String errorMessage = bindingResult.getFieldErrors().get(0).getDefaultMessage();
return Result.failure(errorMessage);
@ExceptionHandler(value = BusinessException.class)
public Result<?> validationExceptionHandler(BusinessException e)
log.error("系统异常BusinessException:",e);
BindingResult bindingResult = e.getBindingResult();
String errorMessage = bindingResult.getFieldErrors().get(0).getDefaultMessage();
return Result.failure(errorMessage);
然后使用:
@GetMapping("/list")
public Result<Map<String, Object>> getPerformanceList(AdminPerformanceSearchVO searchVO, PageVO pageVO,
HttpServletRequest request)
UserDO user = ShiroUtils.getUser();
Query query = new Query(pageVO);
Map<String, Object> params = MapperUtils.obj2Map(searchVO);
query.putAll(params);
formatParams(query);
Map<String, Object> map map = adminAlyPerformanceService.getList(query, user);
return new ResultUtil<Map<String, Object>>().setData(map);
3.5 dao 层规范
(1) 优先使用 mybatis-plus 框架。如果需要多个数据源操作的,可以选择使用 SmartDb 框架。
1)所有 Dao 继承自 BaseMapper
2)禁止使用 Mybatis-plus 的 Wrapper 条件构建器
3)禁止直接在 mybatis xml 中写死常量,应从 dao 中传入到 xml 中
4)建议不要使用星号 * 代替所有字段
正例:
NoticeDao.java
Integer noticeCount(@Param("sendStatus") Integer sendStatus);
---------------------------------------------
NoticeMapper.xml
<select id="noticeCount" resultType="integer">
select
count(1)
from t_notice
where
send_status = #sendStatus
</select>
反例:
NoticeDao.java
Integer noticeCount();
---------------------------------------------
NoticeMapper.xml
<select id="noticeCount" resultType="integer">
select
count(1)
from t_notice
where
send_status = 0
</select>
(2) dao层方法命名规范
获取单个对象的方法用 get 做前缀。
获取多个对象的方法用 list 做前缀。
获取统计值的方法用 count 做前缀。
插入的方法用 save/insert 做前缀。
删除的方法用 remove/delete 做前缀。
修改的方法用 update 做前缀。
建议:dao层方法命名尽量以sql语义命名,避免与业务关联。
正例:
List<PerformanceDTO> listByMonthAndItemId(@Param("month") String month, @Param("itemId") Integer itemId);
反例:
List<PerformanceDTO> getInternalData(@Param("month") String month, @Param("itemId") Integer itemId);
反例中出现的不规范操作:
get代表单个查询,批量查询的应该 list 开头。
命名与业务关联,局限了dao方法的使用场景和范围,降低了方法的复用性,造成他人困惑以及重复造轮子。
四 数据库 规范
4.1 建表规范
表必备三字段:id, create_time, update_time
id 字段 Long 类型,单表自增,自增长度为 1
create_time 字段 datetime 类型,默认值 CURRENT_TIMESTAMP
update_time 字段 datetime 类型,默认值 CURRENT_TIMESTAMP, On update CURRENT_TIMESTAMP
4.2 枚举类表字段注释需要将所有枚举含义进行注释
修改或增加字段的状态描述,必须要及时同步更新注释。
如下表的 sync_status 字段 同步状态 0 未开始 1同步中 2同步成功 3失败。
正例:
CREATE TABLE `t_change_data` (
`id` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT,
`sync_status` TINYINT(3) UNSIGNED NOT NULL DEFAULT '0' COMMENT '同步状态 0 未开始 1同步中 2同步成功 3失败',
`sync_time` DATETIME NULL DEFAULT NULL COMMENT '同步时间',
`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` DATETIME NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`change_data_id`)
)
反例:
CREATE TABLE `t_change_data` (
`id` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT,
`sync_status` TINYINT(3) UNSIGNED NOT NULL DEFAULT '0' COMMENT '同步状态 ',
`sync_time` DATETIME NULL DEFAULT NULL COMMENT '同步时间',
`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` DATETIME NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`change_data_id`)
)
4.3 合理结合业务给表字段添加索引和唯一索引
具体索引规范请参照《阿里巴巴 Java 开发手册》索引规约
4.4 数据库常用
(1)命名风格:小写字母,下划线命名风格
(2)数据库参数
数据库引擎:InnoDB;
字符集:utf8;
字符校对集:generic_utf8_ci
(3)数据库表
表名:前缀为项目名称首字母缩写,单词之间用下划线分割,单数形式;
必备三字段:id,create_time,update_time
id:逻辑主键
create_time:创建时间
update_time:更新时间
(4)主键
逻辑主键:无实际含义,用于唯一标识每个记录
业务主键:有实际含义
(5)属性类型
逻辑主键:bigint,无符号自增
业务主键:varchar,后端生成随机uuid
逻辑值:tinyint
日期:date
时间:timestamp(时间戳)
字符串:varchar,需要指定长度(字段长度应该统一并且适当大一点,否则未知的变化会导致前后端的频繁修改)。
好了,今天就聊到这里,祝各位终有所成,收获满满!
我是脚丫先生,我们下期见~
以上是关于大数据平台后端一些开发规范的主要内容,如果未能解决你的问题,请参考以下文章