16.内存使用与分段
Posted PacosonSWJTU
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了16.内存使用与分段相关的知识,希望对你有一定的参考价值。
【README】
1.本文内容总结自 B站 《操作系统-哈工大李治军老师》,内容非常棒,墙裂推荐;
【1】 内存使用
【1.1】程序加载到内存
1)内存使用:将程序放到内存中,PC寄存器指向开始地址;
2)把程序加载到内存;
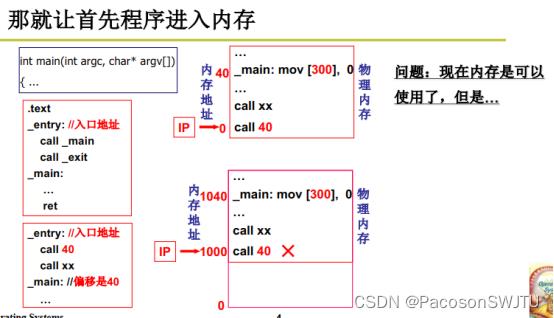
【图解】
- _entry入口程序的地址是0;
- Call 40 表示调用偏移量为40的函数;
问题:
- 上述代码是存储在磁盘上的;加载到内存后,call 40 如果还是调用偏移量为40的函数就是有问题的,因为操作系统程序在内存中从0地址开始,所以call 40调用会报错;
解决方法:
- call 40中的40是相对地址,需要修改为 call entry基址+40,如entry基址是1000,则修改为 call 1040 (以上修改程序中的内存地址的操作叫做重定位);
3)程序加载到内存的过程
需要找一段空闲内存,其基址为A,将磁盘上的程序加载到这段内存,执行重定位修改程序中的内存地址(重定位的具体做法是把载入的这段程序中的所有内存偏移量统统加上空闲内存的基址A);
然后程序取指执行,程序正常运行起来,内存也就被顺利使用了;
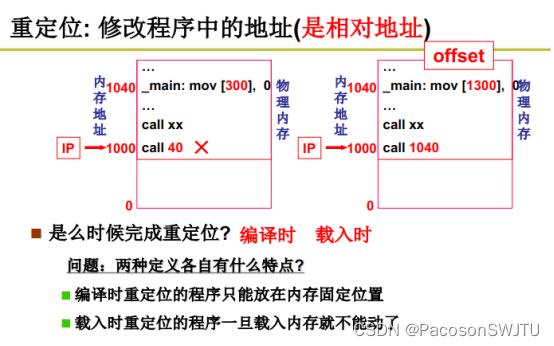
4)什么时候完成重定位?
- 1.编译时:对于嵌入式系统可以在编译时完成重定位,但不灵活;
- 2.载入时:程序加载到内存的时候,比较灵活(非嵌入式系统一般都采用载入时进行重定位); 如程序从磁盘载入到内存时,程序中的内存地址(地址偏移量)统统加上程序所在基址;
4.1)重定位优缺点:
- 编译时重定位的程序只能放在内存固定位置(死板,编译时需要确定存放程序的空闲内存的基址);
- 载入时重定位的程序一旦载入内存就不能动了(灵活,载入时才确定存放程序的空闲内存的基址);
补充:
- 补充1:40是逻辑内存地址,是内存相对地址,而1040是物理内存地址,是内存绝对地址;
- 补充2:无论编译时重定位还是载入时重定位,一旦重定位操作后,程序指令操作的内存地址偏移量是不能够修改的;
- 这又引入了新的问题: 很多时候程序载入内存后,还是会移动的;即业务场景是程序在运行过程中,其操作的内存地址偏移量需要变化的;如程序所在内存页的换入换出操作;
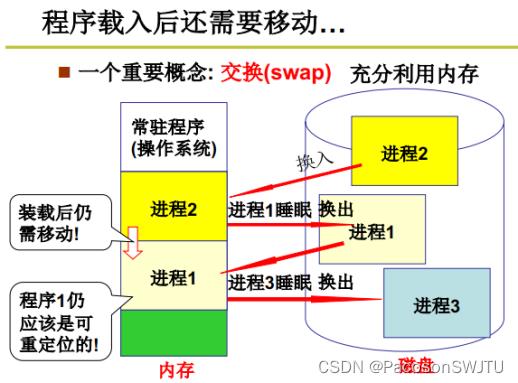
5)一个重要概念:交换swap
初始态:
| 内存基址 | 内存载入的进程 | 磁盘存储的进程 |
| 2000 | 进程2 | 进程3 |
| 1000 | 进程1 |
第1次Swap后:
| 内存基址 | 内存载入的进程 | 磁盘存储的进程 |
| 2000 | 进程2 | 进程1 |
| 1000 | 进程3 |
第2次Swap后:
| 内存基址 | 内存载入的进程 | 磁盘存储的进程 |
| 2000 | 进程1 | 进程2 |
| 1000 | 进程3 |
Swap的意思是:
- 内存空间小,磁盘空间大。当内存装不下进程3时,会先把进程1换出到磁盘,再把磁盘上的进程3换入内存;
- 简单说swap指的是进程在内存与磁盘间换入换出的操作;
- 对进程1的多次换出换入操作,其内存地址(或基址)肯定会发生改变,这就造成程序指令操作的内地地址也会发生改变,所以在编译时或载入时进行重定位会导致swap后的进程执行错误;
所以应该是运行时重定位,而不是编译时或载入时进行重定位;
【1.2】运行时重定位
1)运行时重定位定义:指的是 只有当执行指令的时候,才把指令的内存偏移量与基址相加得到操作数的内存地址;这样无论进行多少次swap,运行时重定位的内地地址都是正确的;
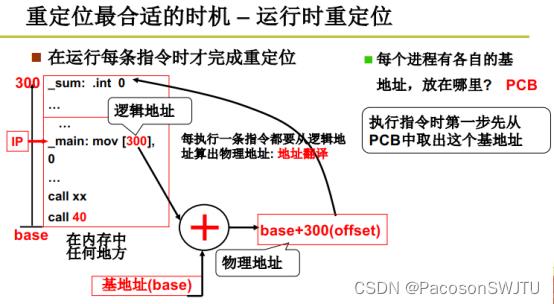
2)地址翻译(也叫重定位):
- 运行时重定位,也叫地址翻译;每执行一条指令都要从逻辑地址算出物理地址;
- 每次swap后,进程的内存基址都会修改,修改后的内存基址base存放在进程结构体PCB里面;即初始态下进程1的base等于1000,第2次swap后进程1的base等于2000;这样就能够正确计算指令中的内存地址偏移量对应的绝对物理地址;
- 补充:当进程运行时,pcb中存储的进程基址base会送入基址寄存器存储,以便后续计算;
3)小结:程序如何使用内存?
- 步骤1:在内存中找到一段空闲内存,并定位基址base(这段空闲内存的起始地址),并送入该进程pcb进行存储;
- 步骤2:把程序放入步骤1申请的空闲内存中,以base为起始地址;
- 步骤3:进程调度或上下文切换时,pcb里的base基址会送入基址寄存器存储;
- 步骤4:每执行一条指令的时候,都进行地址翻译(重定位),即把内存地址偏移量加上基址base得到实际的物理内存地址,这个物理内存地址或者存放了程序指令或者是程序操作数;
经过以上步骤,程序就执行起来了;
【例】多进程执行时基地址切换
- 步骤1:初始态, 进程1的基地址为2000,进程2的基地址为1000;
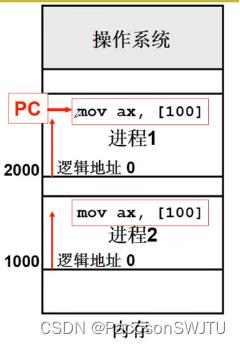
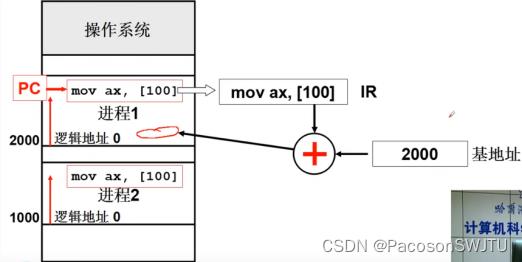
- 步骤2:cpu执行进程1,进程1的pcb存储的基址2000送入基址寄存器;PC寄存器寻址到指令 mov ax,[100]并送入IR寄存器;
- 步骤3:执行指令mov ax,[100]时,把100偏移量与基址2000相加得到操作数的物理内存地址(基址寻址);
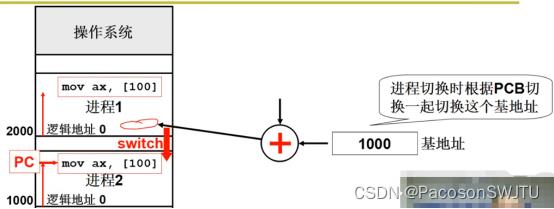
- 步骤4:cpu从进程1切换到进程2 (switch);
- 切换后,进程2的pcb存储的基地址1000送入基址寄存器;这样后面执行的指令的操作数地址的基址都修改为1000了,达到进程切换后 逻辑地址能够正确翻译为物理地址的目的;
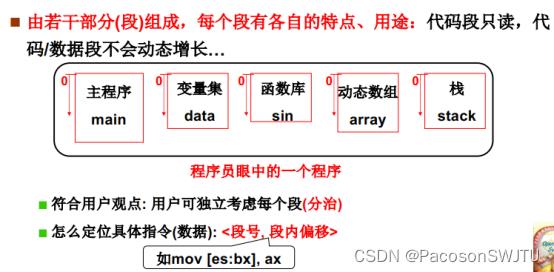
【2】内存分段
1)一个程序由若干部分(段)组成,每个段有各自的特点,如主程序,变量集,函数库,动态数组,栈等;
2)每个部分或段中程序的内存地址偏移量都是相对于所在段的段基址的相对地址;
3)如何定位具体指令或数据: <段号, 段内偏移>
【例】mov [es:bx], ax
需要把以es为段基址,bx为偏移量的逻辑地址翻译为物理内存地址;
4)程序分段对于存储的好处(分段存储采用的是分治思想)
- 好处1:不是将整个程序放入内存,而是将各段分别放入内存,提高内存利用率;
- 好处2:在做swap时,不是把整个进程换入或换出,而是把进程的某个段换入或换出,提高了swap效率;且减少了swap次数;
- 好处3: 程序段或代码段是只读的;(变量集)数据段是可写的;分段存储可以避免代码被误写的场景;
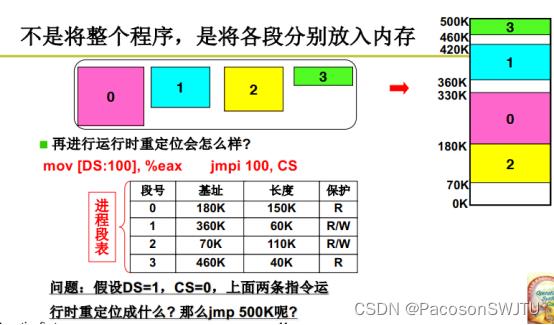
5)程序采用分段存储后,每个段都有自己的基址;
所以进程的pcb需要存储对应程序多个段的段基址;如进程段表所示:
表1 进程段表
| 段号 | 基址 | 长度 | 保护 |
| 0 | 180K | 150K | R |
| 1 | 360K | 60K | R/W |
| 2 | 70K | 110K | R/W |
| 3 | 460K | 40K | R |
补充:段0的偏移量30与段1的偏移量30翻译得到的物理内存地址是不一样,因为他们基址不一样;
6)GDT与LDT
可以把操作系统看做一个进程,其对应的段表叫做 GDT,结构同表1类似;
而每个进程也有自己的段表(用于存储程序多个段的基址),如表1所示,对应的结构体为LDT;
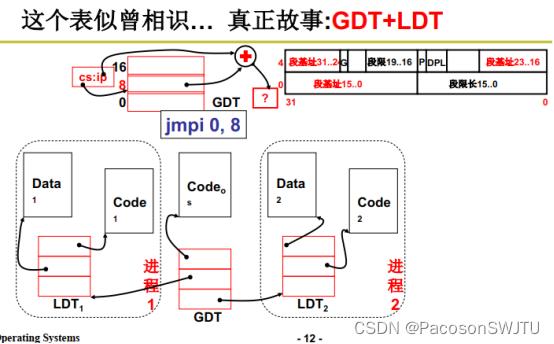
小结:在程序分段情况下使用内存的步骤;
- 步骤1:把程序分为多个段,包括代码段,数据段等;
- 步骤2:每个段在内存中找到一块空闲内存,并把这一段内存基址(起始地址)送入LDT表存储(如表1结构);LDT表就存储了该程序多个段的段基址;
- 步骤3:把LDT表赋值给对应进程的PCB; 至此程序已经被载入到内存中了;
- 最后:PC寄存器根据pcb设置初值,取指执行取指执行,在每执行一条指令的时候, 都查询LDT表找到段基址,并把该段基址加上地址偏移量得到物理内存地址,以进行后续的寻址操作;
- 补充: ldt表基址送入ldtr寄存器;
【例】基于段基址的地址翻译
1)进程1的LDT表数据
| 段序号 | 段基址 |
| 1 | 1000 |
| 0 | 3000 |
2)进程2的LDT表数据
| 段序号 | 段基址 |
| 1 | 7000 |
| 0 | 5000 |
3)指令
- 进程1的mov [cs:40], ax,其中cs代码段寄存器的值为0,即从ldt寻址下标为0的段基址(3000);所以cs:40得到的物理地址是3000+40=3040;
- 进程2的mov [cs:40], ax,其中cs代码段寄存器的值为0,即从ldt寻址下标为0的段基址(5000);所以cs:40得到的物理地址是5000+40=5040;
因为当cpu从进程1切换到进程2时,首先pcb从pcb1切换到pcb2,所以pcb存储的ldt基址也会切换到ldt2并送入ldtr寄存器存储;
所以一旦ldtr被赋予新值,则段基址就会从进程1修改为进程2的段基址,达到多进程切换运行的目的;
以上是关于16.内存使用与分段的主要内容,如果未能解决你的问题,请参考以下文章