一文搞定JVM的内存结构
Posted 纵横千里,捭阖四方
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文搞定JVM的内存结构相关的知识,希望对你有一定的参考价值。
目录
1.简介
本章是JVM的框架和最重要的内容,主要解决的问题是我们创建的对象里到底有什么 ,在JVM中是怎么存储和使用的问题。例如当我们写了这么一行代码:
Person person=new Person();这行代码具体是如何一步步创建、存储和执行的呢?
在前面我们介绍了类装载的基本过程:加载 --> 验证 --> 准备 --> 解析 --> 初始化,这几个阶段完成后,对象就会被安排进内存中,等待执行引擎使用。内存是非常重要的系统资源,是硬盘和CPU的中间仓库及桥梁,承载着操作系统和应用程序的实时运行。JVM内存布局规定了Java在运行过程中内存申请、分配、管理的策略,保证了JVM的高效稳定运行。不同的JVM对于内存的划分方式和管理机制存在差异。而执行引擎可以理解为汽车的发动机,它需要输入油料、空气、冷却剂,排出废气,还要输出功率, 但是执行引擎输入和输出的内容全在内存中。
本章结合JVM虚拟机规范,来探讨一下经典的JVM内存结构。Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域。这些区域有各自的用途,以及创建和销毁的时间,有的区域随着虚拟机进程的启动而一直存在,有些区域则依赖用户线程的启动和结束而建立和销毁。根据《Java虚拟机规范》的规定,Java虚拟机所管理的内存将会包括以下几个运行时数据区域。当然不同的虚拟机会略有差异,下图是hotspot的内存结构:
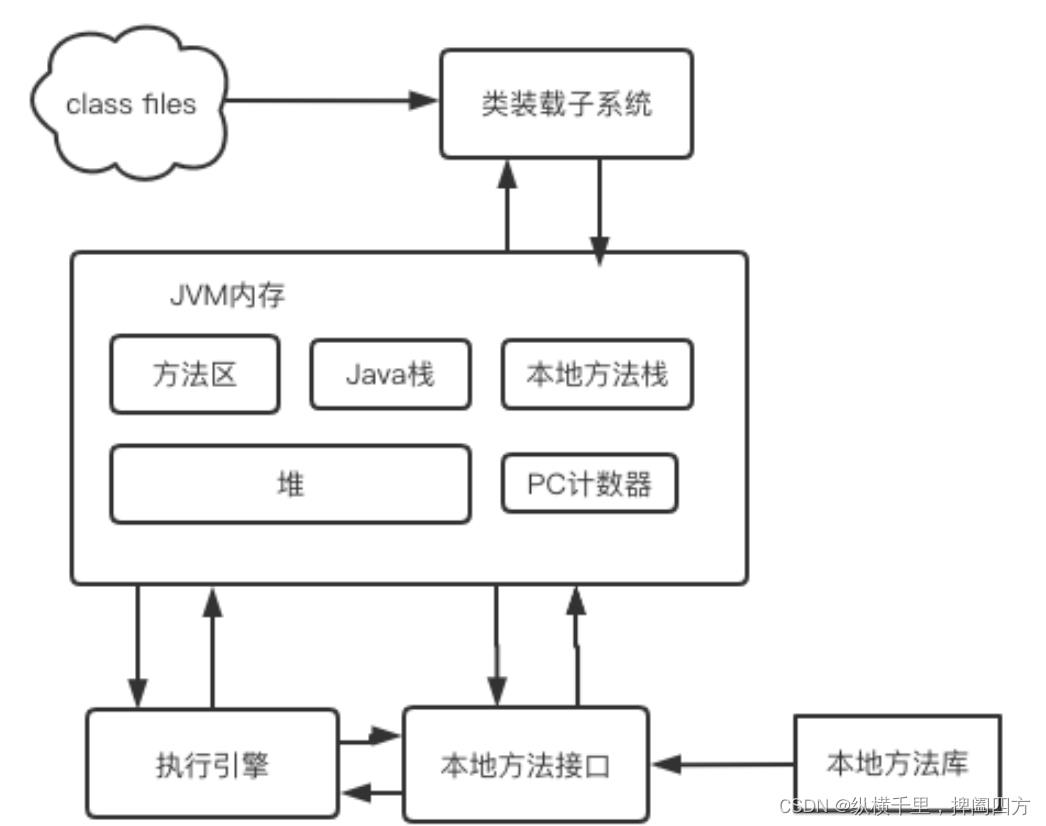
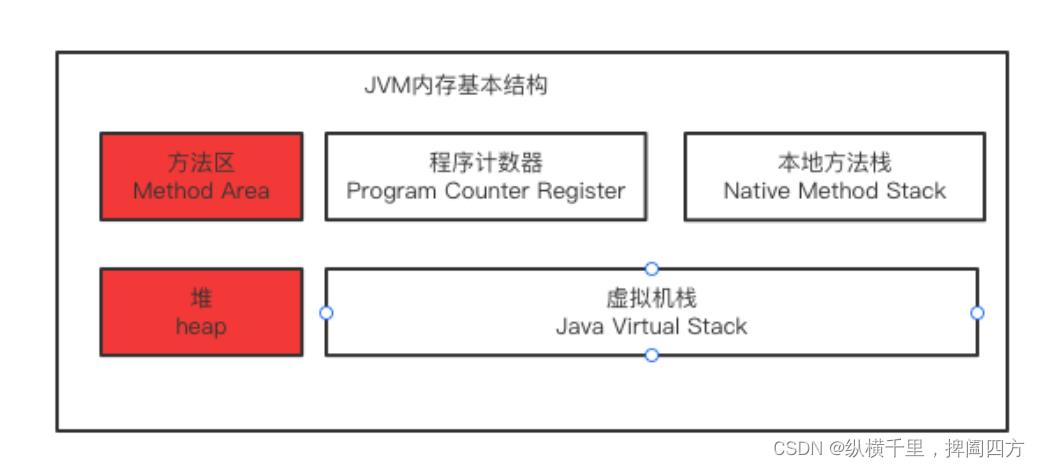
具体的细节我们后面详细展开,我们现在需要注意的是,虽然Java虚拟机定义了若干种程序运行期间会使用到的区域,但是其中有一些会随着虚拟机启动而创建,随着虚拟机退出而销毁。另外一些则是与线程一一对应的,这些与线程对应的数据区域会随着线程开始和结束而创建和销毁。其中白色的为单独线程私有的,红色的为多个线程共享的,即:
-
每个线程独有:独立包括程序计数器、栈、本地方法栈。
-
线程间共享:堆、堆外内存(永久代或元空间、代码缓存),可以理解为有一个虚拟机就有一组这样的结构。
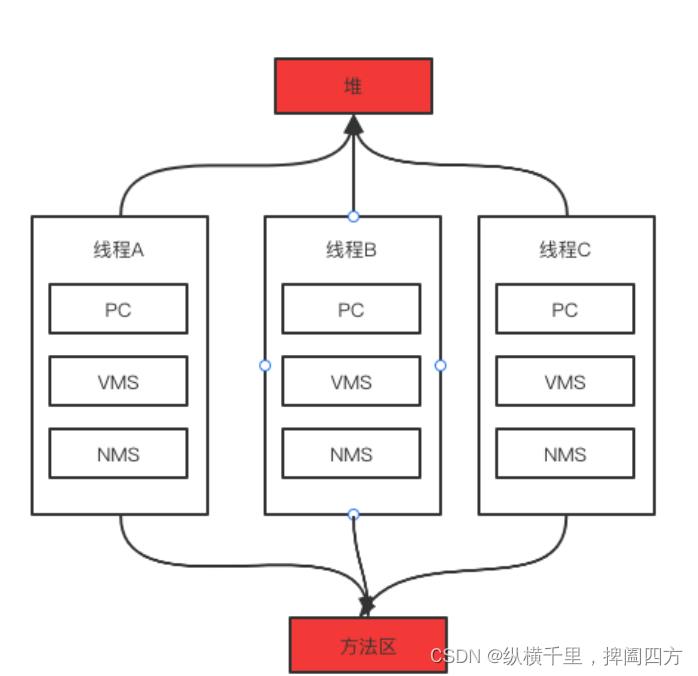
堆区和方法区是各个线程共享的,因此随着程序的执行就会产生一定的垃圾内容,这些垃圾信息90%以上是在堆区里,因此需要比较复杂的垃圾回收策略,这也是我们后面研究的重点。而其他区域有些也会产生少量的垃圾,其垃圾回收策略也相对简单。
接下来我们详细看一下各个结构的作用、结构、工作过程和其他重要问题。
2.程序计数器(PC寄存器)
JVM中的程序计数寄存器(Program Counter Register)中,Register的命名源于CPU的寄存器,寄存器存储指令相关的现场信息。CPU只有把数据装载到寄存器才能够运行。但是这里并非是广义上所指的物理寄存器,在JVM中只是对PC寄存器的一种模拟,用来处理当前线程相关指令的计数器。
有一点与CPU的寄存器是类似的,那就是占用空间小,但运行速度最快。字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,因此它是程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
在JVM规范中,每个线程都有它自己的程序计数器,而且是私有的,生命周期也与线程的生命周期一致。任何时间一个线程都只有一个方法在执行,也就是所谓的当前方法。程序计数器会存储当前线程正在执行的Java方法的JVM指令地址。
需要注意的是PC区是唯一一个没有OutofMemoryError情况的区域。而本地栈等结构没有垃圾回收,但是有可能溢出。
2.1 功能演示
public class PCRegisterTest
public static void main(String[] args)
int i = 10;
int j = 20;
int k = i + j;
编译之后,执行javap -v PCRegisterTest.class,查看字节码,其中与PC有关的是:
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=4, args_size=1
0: bipush 10
2: istore_1
3: bipush 20
5: istore_2
6: iload_1
7: iload_2
8: iadd
9: istore_3
10: return上面的竖排0 到10,就可以理解为PC计数器,而右侧的istore_1等就是操作指令,如下图。

执行的时候如果PC发出的指令序号是5,那么这里就会执行存储操作,然后会执行操作局部变量表,操作数栈等等,最后还要再转换成机器指令给CPU来执行。
如果我们增加代码,会发现上面的Code下的指令会持续增加,对应的就是将每条语句都处理成了能够执行的执行。
2.2 关于PC的面试题
问题1: 使用PC寄存器存储字节码指令地址有什么用呢?
这是因为CPU需要不停的切换各个线程,这时候切换回来以后,就得知道接着从哪开始继续执行。具体来说就是JVM的字节码解释器就需要通过改变PC寄存器的值来明确下一条应该执行什么样的字节码指令。
2.PC寄存器为什么被设定为私有的?
所谓的多线程在一个特定的时间段内只会执行其中某一个线程的方法,CPU会不停地做任务切换,这样必然导致经常中断或恢复,为了能够准确地记录各个线程正在执行的当前字节码指令地址,最好的办法自然是为每一个线程都分配一个PC寄存器,这样一来各个线程之间便可以进行独立计算,从而不会出现相互干扰的情况。
3.虚拟机栈
3.1 初识虚拟机栈
虚拟机栈主要是管理方法调用的。当我们写一个方法的时候,例如:
public void function()
int a=0;
function1(a);
我们经常说方法要执行方法调用时,例如上面要执行function1(a)时会先将function()的信息保存到栈中,完成之后再继续执行function(),那JVM具体是怎么保存的呢?就是以栈桢为单位保存的,每执行一次方法调用就会创建一个栈桢。
虚拟机栈是在创建线程时同步创建的,是线程私有的,生命周期也与线程一致,主要作用是管理Java的运行,包括保存方法的局部变量、部分结果,并且参与方法的调用与返回。其内部保存了一个个的栈桢,对应的就是线程每次进行的方法调用,因此栈桢可以理解为方法调用的操作单位。
栈是一个快速有效的分配存储方式,访问速度仅次于程序计数器,但是JVM对Java栈的操作只有两个:执行方法时入栈,完成方法后出栈。对于一个线程,在同一个时刻,只会有一个栈桢在活动,也即只有当前正在执行的方法对应的栈桢是有效的。这个帧也成为当前帧(current Frame),与当前栈桢想对应的就是当前方法(Current Method),定义这个方法的类就是当前类(Current Class)。我们后面要介绍的执行引擎运行的所有字节码指令都是只针对当前栈桢进行操作的。
如果在某个方法中又调用了其他的方法,此时就会为新的方法创建新的栈桢放在栈顶,成为新的当前帧,而之前的帧就会将信息保存一下等待当前帧执行完之后再继续执行。

如果当前方法调用了其他方法,方法返回时会就将执行结果一起回传,然后虚拟机会丢弃当前栈帧,使得栈中的后序帧成为新的当前栈桢。该过程与栈的操作是过程是一致的。
思考 栈中可能出现什么异常
从上面的分析可以看到,栈可以自动进行空间的管理,不存在垃圾回收问题,那常见的"StackOverflowError"又是怎么回事呢?
JVM规范允许Java栈的大小是动态的或者是固定不变的,如果是固定大小的,那么一个线程的Java虚拟机容量可以在线程创建的时候独立选定。如果线程请求分配的栈容量超过Java虚拟机栈允许的最大容量,就会抛出StackOverflowError异常。
那栈一定不会出现内存溢出的问题吗?不是的,如果Java虚拟机栈可以动态扩展,并且扩展的时候无法申请到足够的内存,或者在创建新的线程时没有足够的内存去创建对应的虚拟机栈,那Java虚拟机就会抛出OutOfMemoryError异常。
例如下面的代码就会抛出“StackOverflowError”:
public class StackOverFlowTest
public static void main(String[] args)
test();
public static void test()
test();
3.2 栈帧的内部结构
栈帧的内部包括局部变量表、操作数栈、动态链接和方法返回地址等结构。

3.2.1 局部变量表
局部变量表(Local variables)也称为局部变量表或者本地变量表,主要用于存储方法的参数和定义在方法体中的局部变量。这些数据类型包括各类型基础数据类型、对象引用(reference),以及returnAddress类型。
局部变量表其实就是一个数组数组,假如其长度为length,参数以索引为0的位置Index0开始存放,到length-1的位置结束。这length个单元有一个专门的名字:槽 slot,因此槽的个数就是局部变量表的长度。
局部变量表中存放的是编译期可知的各种基本数据类型(Integer、Char等8大包装类),引用类型(reference),returnAddress类型的变量。局部变量表所需的容量大小是在编译器确定下来的,并保存在方法的Code属性的maximum local variables数据项中,因此,在方法运行期间不会改变局部变量表的大小。
在局部变量表里,32位以内的类型只占用一个slot(包括returnAddress类型),64位的类型(long和double)占用两个slot。其中byte、short、char和boolean都会先转成int,因此也会占用一个槽。
为了提高访问效率,JVM会为局部变量表中每个slot分配一个索引,通过这个索引即可成功访问到局部变量表中的局部变量值,而不用从头开始查找,如下图:

静态变量和局部变量的对比 参数表分配完毕之后,再根据方法体内定义的变量的顺序和作用域分配。
我们知道类变量表有两次初始化的机会,第一次是在“准备阶段”,执行系统初始化,对类变量设置零值,另一次则是在“初始化”阶段,赋予程序员在代码中定义的初始值。
和类变量初始化不同的是,局部变量表不存在系统初始化的过程,这意味着一旦定义了局部变量则必须人为的初始化,否则无法使用。
public void test()
int i;
System. out. println(i);
这样的代码是错误的,没有赋值不能够使用。
另外,局部变量表中的变量也是重要的垃圾回收的根节点 ,只要被局部变量表中直接或者简介引用的对象都不会被回收。
3.2.2 操作数栈
每一个独立的栈桢中出了包含局部变量表以外,还包含一个后进先出的操作数栈,也可以称为表达式栈,其功能说白了就是为了计算表达式了,例如要计算8+5=13。操作数栈在方法执行过程中,根据字节码指令,往栈中写入数据或弹出数据。例如:
public class TestAddOperation
public static void main(String[] args)
byte i = 15;
int j = 8;
int k = i + j;
编译之后,通过javap命令,我们可以见到如下的字节码执行信息,其中我们可以看到bipush等字样,这就是操作表达式栈。
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=4, args_size=1
0: bipush 15
2: istore_1
3: bipush 8
5: istore_2
6: iload_1
7: iload_2
8: iadd
9: istore_3
10: return表达式栈主要用于保存计算过程的中间结果,同时作为计算过程中变量临时的存储空间。操作数栈就是JVM执行引擎的一个工作区,当一个方法刚开始执行的时候,一个新的栈帧会随之创建。如果被调用的方法带有返回值,其返回值将会被压入当前栈桢的操作数栈中,并更新PC寄存器中下一条所需要执行的字节码指令。

操作数栈中元素的数据类型必须与字节码指令的序列严格匹配。这有编译器再编译期间进行验证,同时在类加载过程中的类检验阶段的数据流分析阶段要再次验证。
我们有时候会看到说Java虚拟机的解释引擎是基于栈的执行引擎,其中的栈指的就是操作数栈。
3.2.3 链接简介
在JVM中,将符号转换为调用方法的直接引用与方法的绑定机制相关,其中主要有静态链接和动态链接两种方式。
静态链接就是当一个字节码文件被装载进JVM内部时,如果被调用的目标方法在编译器可知,且运行期保持不变时,这种情况下将调用方法的符号引用转换为直接引用的过程称为静态链接。
动态链接就是如果被调用的方法在编译器无法被确定下来,也就是说,只能再程序运行期将调用方法的符号引用转换为直接引用,由于这种引用转换过程具备动态性,因此也就被称为动态链接。
为什么会有这两种方式呢?因为有些场景是无法将所有方法都确定下来的。我们同样做个类比。我们知道汽车都有油箱,没油就去加,这就是动态链接。而火箭发射时必须将所有油料全部准备好,这就是静态链接。我们知道汽车比较小巧,一直加油可以用很多年,但是上千吨的火箭往往只能运送几吨的载荷,这是因为大部分空间都被油料和氧气占满了。事实上静态链接的操作执行速度快,但是比较笨重,而动态链接则恰好相反。
与静态链接和动态链接对应的就是早起绑定和晚期绑定。 早起绑定,就是被调用的目标方法如果在编译期可知,且运行期保持不变时,即可将这个方法与所属的类型进行绑定,这样一来,由于明确了被调用的目标方法究竟是哪一个,因此也就可以使用静态链接的方式将符号引用转换为直接引用。晚期绑定,如果被调用的方法无法再编译期确定下来,只能再程序运行期根据实际的类型绑定相关的方法,这种绑定方式也就称为晚期绑定。Java语言支持封装、继承和多态特征,这就需要早期绑定和晚期绑定两种方式。
3.2.4 方法返回地址
方法返回地址returnAddress存放调用该方法的PC寄存器的值,正常执行完成或者出现异常都将导致一个方法的结束,无论通过哪种方式退出,在方法退出后都返回到该方法被调用的位置。方法正常退出时,调用者的PC计数器的值作为返回地址,即调用该方法的指令的下一条指令的地址。而通过异常退出的,返回地址是要通过异常表来确定,栈桢中一般不会保存这部分信息。
本质上,方法的退出就是当前栈桢出栈的过程,此时需要恢复上层方法的局部变量表、操作数栈、将返回值压入调用者栈桢的操作数栈、设置PC寄存器,让调用者继续执行下去。如果抛异常的话,就不会抛异常给上层调用者。
3.3 栈的常见面试题
1.举例栈溢出的情况?(Stack OverflowError)
通过 -Xss设置栈的大小:OOM
2.调整栈的大小能保证不出现溢出吗?不能
3.分配的栈内存越大越好吗?不是!
4.垃圾回收是否会涉及到虚拟机栈?不会的!
5.方法中定义的局部变量是否线程安全?具体情况具体分析
4.本地方法接口和本地方法栈
4.1 本地方法
简单讲,本地方法(Native Method)就是一个Java调用非Java代码实现的接口,比如C语言等等。其实很多语言都有这样的特性,例如在C++中可以使用extern "C"告知C++编译器去调用一个C的函数。本地接口的初衷是为了融合C/C++程序,后来逐步演变成能融合不同的编程语言为Java所用。
标识符native可以与其它java标识符连用,但是abstract除外。在定义一个native method时,并不提供实现体(有些像定义一个Java interface),因为其实现体是由非java语言在外面实现的,只要标记清楚方法即可,例如:
public class IHaveNatives
public native void Native1(int x);
public native static long Native2();
private native synchronized float Native3(Object o);
native void Native4(int[] ary) throws Exception;
为什么要使用 Native Method呢?虽然Java使用起来非常方便,然而有些任务用Java实现起来不容易,或者我们对程序的效率很在意时,问题就来了,常见的场景有:
1.有时Java应用需要与Java外面的硬件环境交互,这是本地方法存在的主要原因。Java需要与一些底层系统,如操作系统或某些硬件交换信息时的情况。本地方法正提供了这样一种交流机制:它为我们提供了一个非常简洁的接口,而且我们无需去了解Java应用之外的繁琐的细节。
2.与操作系统的交互。Java语言需要经过JVM处理才能被操作系统执行,JVM支持着Java语言本身和运行时库,它是Java程序赖以生存的平台。然而不管怎样,它毕竟不是一个完整的系统,很多还是要依赖操作系统的支持。通过使用本地方法,我们得以用Java实现了jre的与底层系统的交互,甚至JVM的一些部分就是用C写的。
例如多线程代码底层就使用了很多这种方法,例如Thread底层就有这样的方法:
private native void start0();不过,目前该方法使用的越来越少了,除非是与硬件有关的应用,比如通过Java程序驱动打印机或者Java系统管理生产设备,在企业级应用中已经比较少见。因为现在的异构领域间的通信很发达,比如可以使用网络协议实现相互通信而不必集成到一起。
4.2本地方法栈
Java虚拟机栈于管理Java方法的调用,而本地方法栈用于管理本地方法的调用。本地方法栈,也是线程私有的。本地方法一般是使用C语言或C++语言实现的。
本地方法栈允许被实现成固定或者是可动态扩展的内存大小(在内存溢出方面和虚拟机栈相同):
-
如果线程请求分配的栈容量超过本地方法栈允许的最大容量,Java虚拟机将会抛出一个stackoverflowError 异常。
-
如果本地方法栈可以动态扩展,并且在尝试扩展的时候无法申请到足够的内存,或者在创建新的线程时没有足够的内存去创建对应的本地方法栈,那么Java虚拟机将会抛出一个outofMemoryError异常。
当某个线程调用一个本地方法时,它就进入了一个全新的并且不再受虚拟机限制的世界。它和虚拟机拥有同样的权限。本地方法可以通过本地方法接口来访问虚拟机内部的运行时数据区,甚至可以直接使用本地处理器中的寄存器,还可以直接从本地内存的堆中分配任意数量的内存。
不过,并不是所有的JVM都支持本地方法。因为Java虚拟机规范并没有明确要求本地方法栈的使用语言、具体实现方式、数据结构等。如果JVM产品不打算支持native方法,也可以无需实现本地方法栈。在目前应用最多的Hotspot JVM中,直接将本地方法栈和虚拟机栈合二为一。
5.堆
5.1 堆初探
首先思考一个问题,什么是堆和栈?我们经常听到“堆栈”的概念,那两者是一回事吗?不是的,栈是运行时的单位,而堆是存储的单位。栈解决程序的运行问题,即程序如何执行,或者如何处理数据。而堆解决的是数据怎么存怎么放和怎么管理的问题。
比如我们定义了这样一个类:
class School
Student student;
Teacher teacher;
我们经常说这里的student和teacher是对象的引用,其实就是说我们执行时如果用到了school对象,里面会有两个地址,这两个地址指向的就是堆中实际存储student和teacher的地址。
在我们的应用中,数组和对象可能永远不会存储在栈上,因为栈帧中保存引用,这个引用指向对象或者数组在堆中的位置。这也意味着,在方法结束后,堆中的对象不会马上被移除,仅仅在垃圾收集的时候才会被移除,因此堆也是执行垃圾回收的重点区域。
堆针对一个JVM进程来说是唯一的,是所有线程共用的,一个JVM实例中就有一个运行时数据区,一个运行时数据区只有一个堆和一个方法区。而且这个堆区是在JVM启动的时候即被创建,其空间大小也就确定了,堆是JVM管理的最大一块内存空间,并且堆内存的大小是可以调节的。
《Java虚拟机规范》规定,堆可以处于物理上不连续的内存空间中,但在逻辑上它应该被视为连续的。并且规定所有的对象实例以及数组都应当在运行时分配在堆上。
public class SimpleHeap
private int id;//属性、成员变量
public SimpleHeap(int id)
this.id = id;
public void show()
System.out.println("My ID is " + id);
public static void main(String[] args)
SimpleHeap sl = new SimpleHeap(1);
SimpleHeap s2 = new SimpleHeap(2);
int[] arr = new int[10];
Object[] arr1 = new Object[10];
现代垃圾收集器大部分都基于分代收集理论设计,堆空间细分为:
-
Java7 及之前堆内存逻辑上分为三部分:新生区+养老区+永久区
-
Young Generation Space 新生区 Young/New
-
又被划分为Eden区和Survivor区
-
-
Old generation space 养老区 Old/Tenure
-
Permanent Space 永久区 Perm
-
-
Java 8及之后堆内存逻辑上分为三部分:新生区+养老区+元空间
-
Young Generation Space 新生区,又被划分为Eden区和Survivor区
-
Old generation space 养老区
-
Meta Space 元空间 Meta
-
有时候,我们会看到非常类似的名字,例如新生区、 新生代和 年轻代是一个东西 ; 养老区、 老年区和老年代是一个东西; 永久区 和永久代也是一样的东西。
-
堆空间内部结构,JDK1.8之前从永久代 替换成 元空间
5.2 堆内存分配策略
5.2.1 堆空间分代思想
Java中的堆是分成多种类型的,也称为代,为什么分代呢,为什么要这么复杂呢?不分代就不能正常工作了吗?其实不分代完全可以,那所有的对象都在一块,GC的时候要找到哪些对象没用,这样就会对堆的所有区域进行扫描,因此性能不高。这就如同把一个学校的所有人不管年级和上什么课科,全都在一个教室进行,想象一下这是什么场景。
经研究,不同对象的生命大小不同,产生和消亡的时间不一样,因此执行一段时间之后,内容空间会变得支离破碎,例如windows自带的机械硬盘自带的磁盘整理会显示如下的问题。
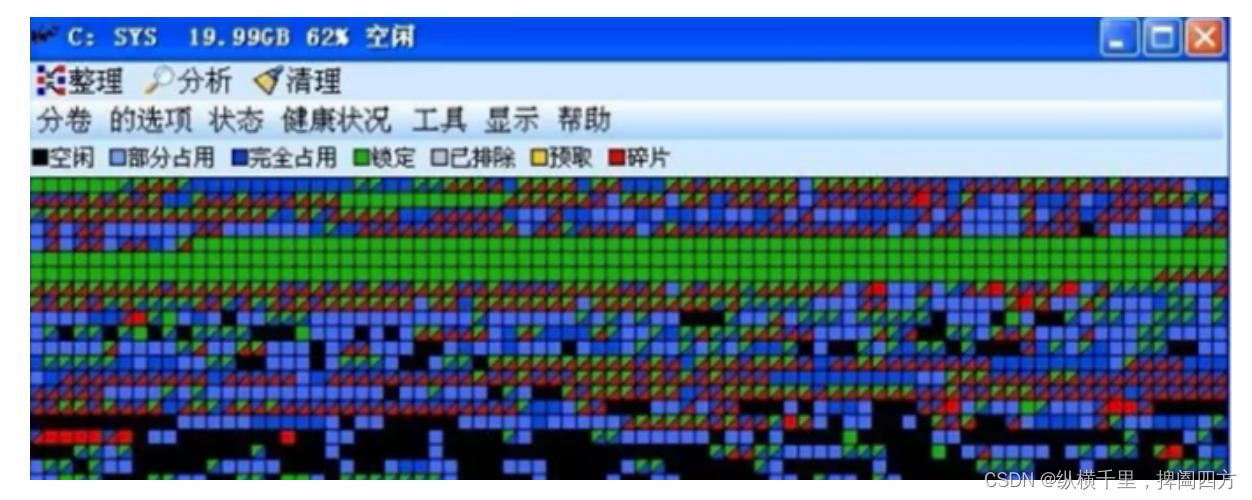
另外,虽然不同对象的周期不同,但是70%-99%的对象是临时对象,也就是很多对象都是朝生夕死的,如果分代的话,把新创建的对象放到某一地方,当GC的时候先把这块存储“朝生夕死”对象的区域进行回收,这样就会腾出很大的空间出来。如果多回收新生代,少回收老年代,性能会提高很多。
5.2.2 图解对象分配过程
为新对象分配内存是一件非常严谨和复杂的任务,JVM的设计者们不仅需要考虑内存如何分配、在哪里分配等问题,并且由于内存分配算法与内存回收算法密切相关,所以还需要考虑GC执行完内存回收后是否会在内存空间中产生内存碎片。
具体过程可以先看下图,其中Survivor区比较复杂,后面详细讨论:
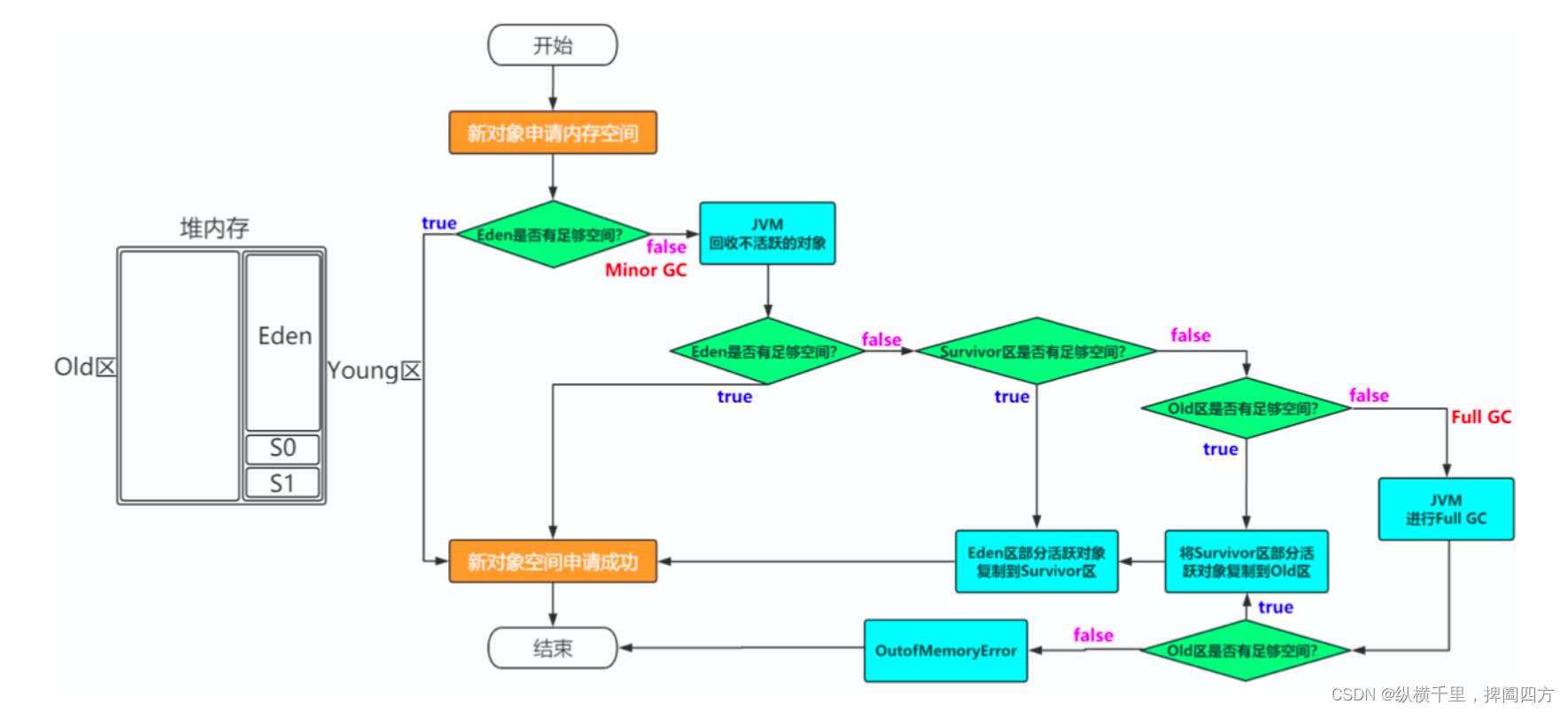
具体过程是:
-
new的对象先放Eden区,此区有大小限制。
-
当Eden的空间填满时,程序又需要创建对象,JVM的垃圾回收器将对Eden区进行垃圾回收(MinorGC),Eden区中不再被其他对象引用的对象就是要被清理的,但是此时仍然有仍然在使用的,此时会将活的对象整理都移动到Survivor0区,之后Eden区就完全清空,可以继续存放新的对象了。
-
如果Eden区再次被放满了,则要再次执行垃圾回收,在此期间Survivor0区里有些对象也变成垃圾了。也就是Eden区和Survivor0区分别都有垃圾对象和存活对象。此时会将两者存活的对象都移动到Survivor1区。 这里为什么要移动到S1区呢?我们后面再解释。
-
上面S1区放入对象之后就变成S0区了,而原来的S0区会被全部抹掉,并变成S1区,然后会不断重复上述几个步骤。为什么会样我们也在后面详细解释。
-
S0区活的对象会在S0和S1之间反复啥时候能去养老区呢?可以设置次数,默认是15次。可以设置新生区进入养老区的年龄限制,设置 JVM 参数:-XX:MaxTenuringThreshold=N 进行设置。如果一个对象在s0和s1区之间反复移动15次都未被清楚,则会被移动到老年区。
-
在老年区,相对悠闲。当老年区内存不足时,再次触发GC:Major GC,进行老年区的内存清理。若老年区执行了Major GC之后,发现依然无法进行对象的保存,就会产生OOM异常。
在上面的步骤中,虽然Eden区、Survivor区和老年区都有垃圾回收,但是具体的执行策略、效率和方法是不一样的,我们到后面垃圾回收章节再详细看。
现在开始解释上面第2~4步,Survivor区是怎么进行垃圾回收的,以及为什么要反复移动。
1、我们创建的对象,一般都是优先放在Eden区的,当我们Eden区满了后,就会触发GC操作,一般被称为 YGC / Minor GC操作。例如下图中Eden已经满了,红色是我们要被回收的垃圾对象,而绿色是仍然可以使用的对象。此时我们将1和5移动到S0区,而且此时1和5是紧密排列在一起的,没有间隙,这就避免了碎片问题。
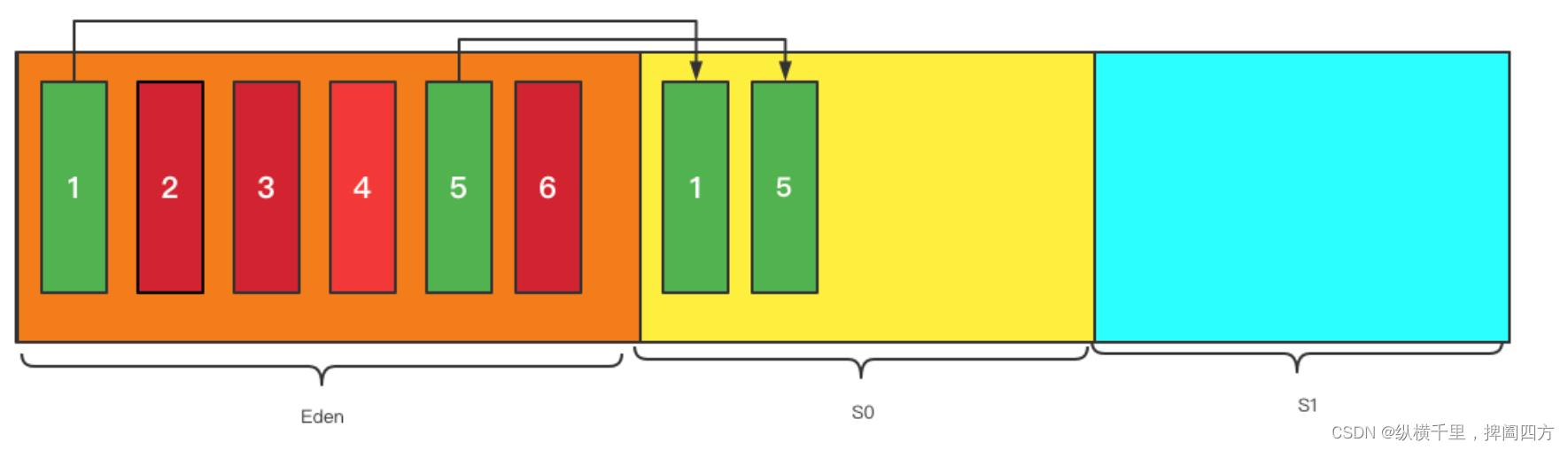
在移动元素时,我们还给每个对象设置了一个年龄计数器,经过一次回收后还存在的对象,将其年龄加 1。完成该步骤之后相当于Eden区已经完全释放干净了,都可以存放新对象了。
2.随着JVM执行新程序,Eden区可能再次存满,此时又会触发MinorGC操作,此时GC将会把 Eden和Survivor From中的对象进行一次垃圾收集,把存活的对象放到 Survivor To(S1)区,同时让存活的对象年龄 + 1。

在上面操作的时候,当把对象从S0移动到S1之后,S0就被格式化了,变成S1,而上图中的S1则成为下一个S0,也就是说s0区和s1区在互相转换,而且只是变了一下名字,有对象的区域都是S0区。
3、我们继续不断的进行对象生成和垃圾回收,当Survivor中的对象的年龄达到15的时候,将会触发一次 Promotion 晋升的操作,也就是将年轻代中的对象晋升到老年代中。
关于垃圾回收:频繁在新生区收集,很少在养老区收集,几乎不在永久区/元空间收集。
为什么要设置两个Survivor区
这里可能感觉奇怪的是为什么要有两个S区,执行垃圾回收的时候时候为什么要移到另外一个,而不是清理自己呢?我们可以通过淘金的例子来解释,假如你要在沙漠里淘金,假如只有一个框,你只能将框的一角的沙子清理干净,然后放分离出来的金子。第二种是准备两个框,一个用来铲沙子,检出来的金子都放到另外一个框里,你觉得哪种更高效?自然是后者。
设置两个Survivor区还有一个很大的好处就是解决了碎片化,碎片化带来的风险是极大的,严重影响Java程序的性能。堆空间被散布的对象占据不连续的内存,最直接的结果就是堆中没有足够大的连续内存空间,接下去如果程序需要给一个内存需求很大的对象分配内存就会变得非常困难。这就好比我们爬山的时候,背包里所有东西紧挨着放,最后就可能省出一块完整的空间放相机。如果每件行李之间隔一点空隙乱放,很可能最后就没法装相机了。而我们打包行李一般都是先将大的放好,最后在将小的放到缝隙里去,实在不行就将所有东西倒出来重新摆。这就是要解决碎片化问题,而设置两个Survivor区就是为了实现这种效果。
这里先介绍一下几种空间的大小关系,其中一般情况下的分区情况是:新生代和老年代各占1/3和2/3的堆空间。而新生代的from、to和Eden区在新生代的比例一般为1:1:8,但是该参数也是可以调整的:默认-XX:NewRatio=2,表示新生代占1,老年代占2,新生代占整个堆的1/3。可以修改-XX:NewRatio=4,表示新生代占1,老年代占4,新生代占整个堆的1/5。
5.3 堆空间实战
java提供了很多工具来辅助我们监控和设置堆等空间,例如:
-
JDK命令行
-
Eclipse:Memory Analyzer Tool
-
Jconsole
-
Visual VM(实时监控,推荐)
-
Jprofiler(IDEA插件)
-
Java Flight Recorder(实时监控)
-
GCViewer
-
GCEasy
我们在后续内容中会逐步学习和使用,接下来我们就学习几种常见工具的使用
5.3.1 使用 JVisualVM查看堆内存
我们现在写一个例子查看一下堆的分配情况,运行下面代码
public class HeapDemo
public static void main(String[] args)
System.out.println("start...");
try
TimeUnit.MINUTES.sleep(30);
catch (InterruptedException e)
e.printStackTrace();
System.out.println("end...");
我们找到安装java的目录,windows系统如下,而mac系统一般是/usr/bin下,我们找到jvisualvm程序,并打开,如下图所示。
1、双击jdk目录下的这个文件
除此打开时需要安装一下GC的插件,方法是选择工具 -> 插件 -> 安装Visual GC插件,安装之后重启即可。

然后我们运行上面的代码,可以看到如下的内容:
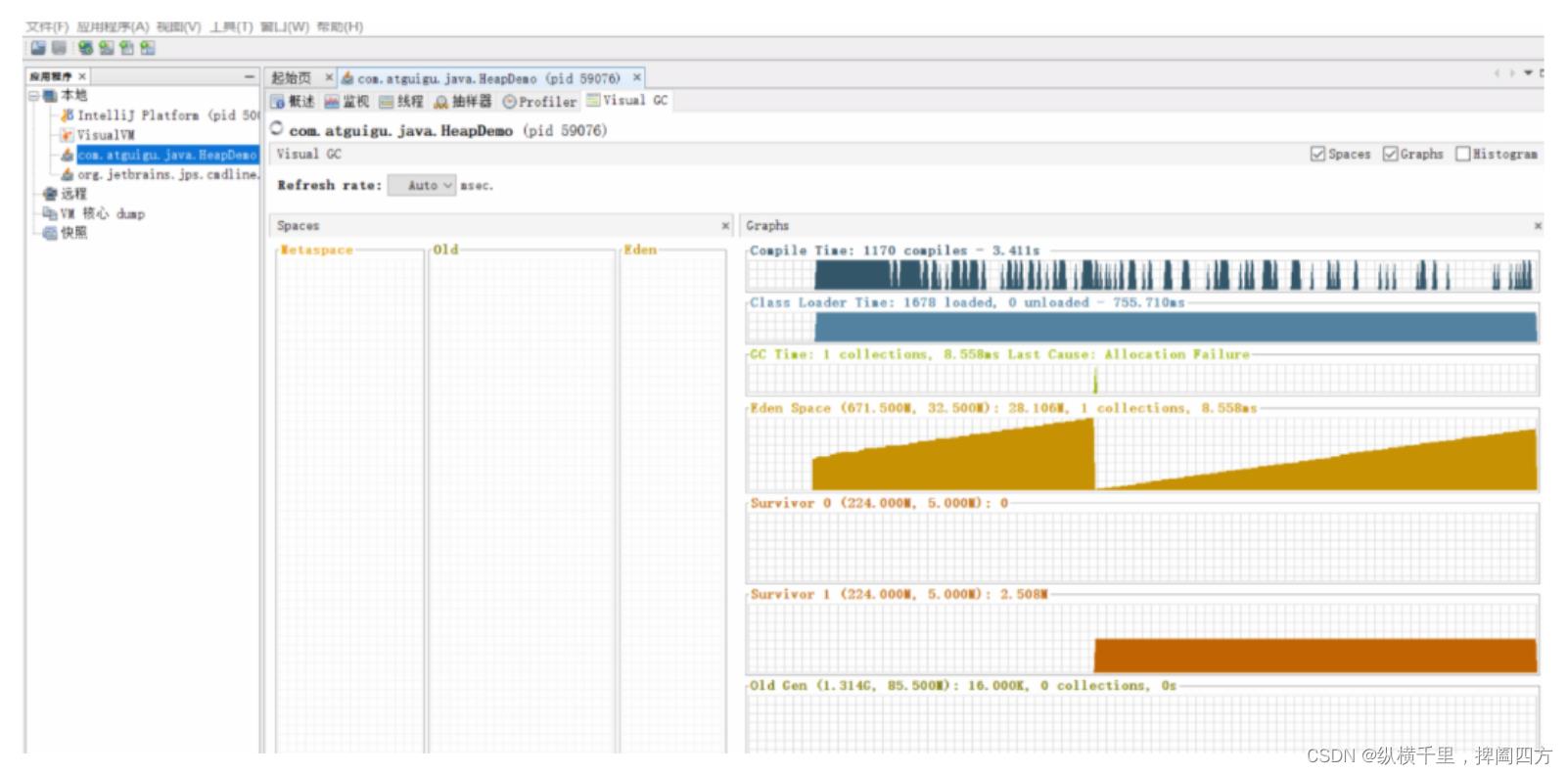
这样我们就看到了基本的堆空间信息了。
5.3.2 通过PrintGCDetails命令查看堆信息
除了使用jvisualvm查看堆信息,我们可以在idea中直接输出相关的信息。方法是打开“运行/调试配置”,在虚拟机选项位置添加参数"-XX:+PrintGCDetails",然后保存退出,重新运行HeapDemo程序。
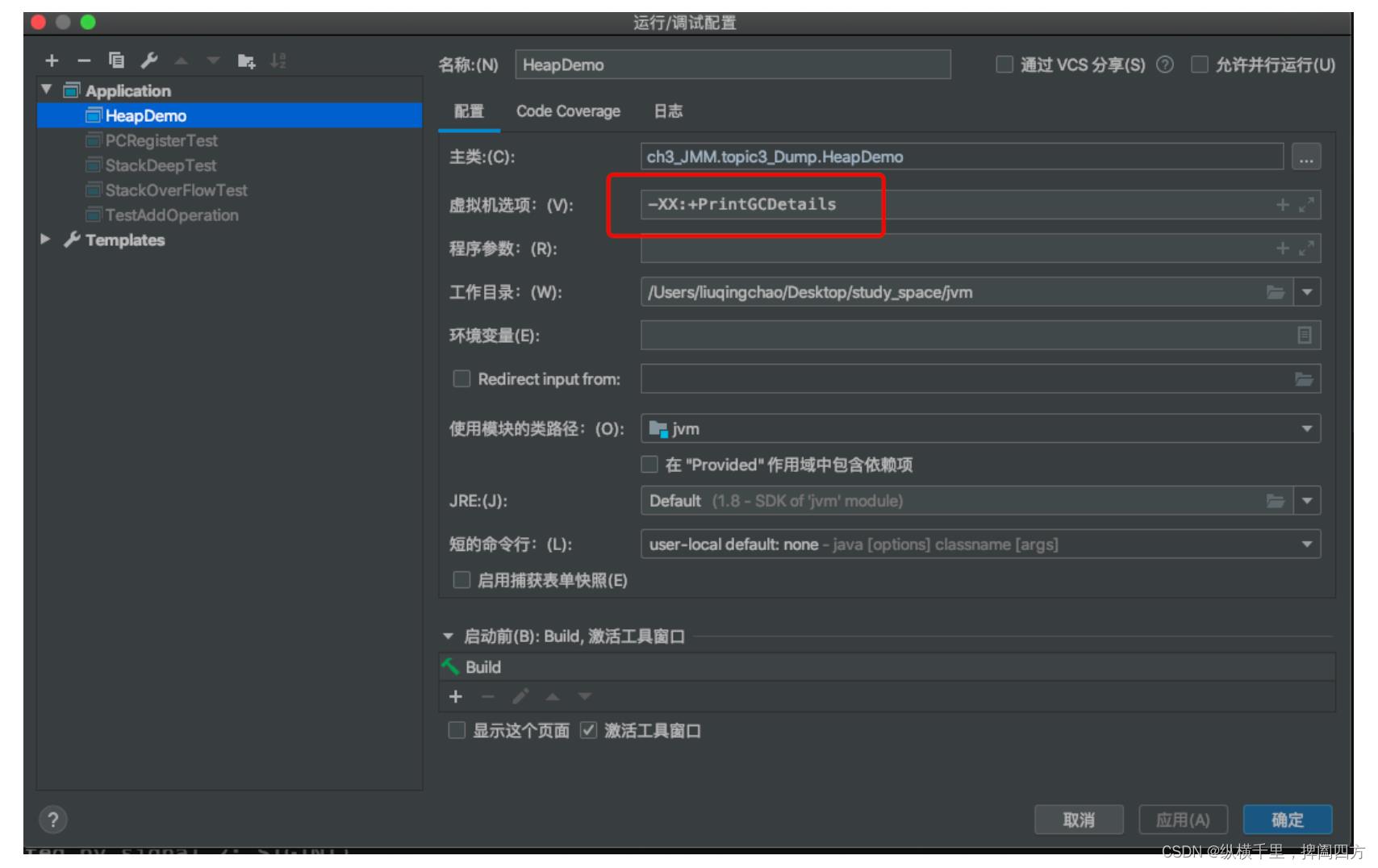
此时运行时控制台会什么都没有,我们将其终止的时候会输出如下内容:
Heap
PSYoungGen total 76288K, used 9181K [0x000000076ab00000, 0x0000000770000000, 0x00000007c0000000)
eden space 65536K, 14% used [0x000000076ab00000,0x000000076b3f75e8,0x000000076eb00000)
from space 10752K, 0% used [0x000000076f580000,0x000000076f580000,0x0000000770000000)
to space 10752K, 0% used [0x000000076eb00000,0x000000076eb00000,0x000000076f580000)
ParOldGen total 175104K, used 0K [0x00000006c0000000, 0x00000006cab00000, 0x000000076ab00000)
object space 175104K, 0% used [0x00000006c0000000,0x00000006c0000000,0x00000006cab00000)
Metaspace used 3836K, capacity 4568K, committed 4864K, reserved 1056768K
class space used 430K, capacity 460K, committed 512K, reserved 1048576K这便是程序从运行到结束时使用的堆信息。
5.3.3 设置堆内存
Java堆区用于存储Java对象实例,而且堆的大小在JVM启动时就已经设定好了,我们可以通过选项"-Xms"和"-Xmx"来进行设置。
-
-Xms用于表示堆区的起始内存,等价于-XX:InitialHeapSize
-
-Xmx则用于表示堆区的最大内存,等价于-XX:MaxHeapSize
默认情况下,初始内存和最大内存的大小都是物理电脑内存大小/4 。一旦堆区中的内存大小超过“-Xmx"所指定的最大内存时,将会抛出OutofMemoryError异常。
我们一般会将将-Xms和-Xmx两个参数配置相同的值,这是因为假设两个不一样,初始内存小,最大内存大。在运行期间如果堆内存不够用了,会执行扩容操作,一直扩到最大内存。如果内存够用且多了,也会不断的缩容释放。频繁的扩容和释放造成不必要的压力,避免在GC之后调整堆内存给服务器带来压力。如果两个设置一样的就少了频繁扩容和缩容的步骤。
我们如果将HeapDemo的虚拟机参数做如下设置:"-Xms10m -Xmx10m -XX:+PrintGCDetails",此时运行时会出现如下错误,说明空间不够了。
[GC (Allocation Failure) [PSYoungGen: 2048K->496K(2560K)] 2048K->648K(9728K), 0.0017097 secs] [Times: user=0.01 sys=0.00, real=0.00 secs] 我们可以通过Runtime提供的方法来获取当前使用的内存大小,代码如下:
public class HeapSpaceInitial
public static void main(String[] args)
//返回Java虚拟机中的堆内存总量
long initialMemory = Runtime.getRuntime().totalMemory() / 1024 / 1024;
//返回Java虚拟机试图使用的最大堆内存量
long maxMemory = Runtime.getRuntime().maxMemory() / 1024 / 1024;
System.out.println("-Xms : " + initialMemory + "M");
System.out.println("-Xmx : " + maxMemory + "M");
System.out.println("系统原始内存大小为:" + initialMemory * 64.0 / 1024 + "G");
System.out.println("系统内存大小为:" + maxMemory * 4.0 / 1024 + "G");
try
Thread.sleep(1000000);
catch (InterruptedException e)
e.printStackTrace();
输出结果:
-Xms : 245M
-Xmx : 3641M
系统原始内存大小为:15.3125G
系统内存大小为:14.22265625G我们可以将虚拟机选项修改一下"-Xms100m -Xmx100m -XX:+PrintGCDetails"再看:

此时输出的结果为:
-Xms : 96M
-Xmx : 96M
系统内存大小为:6.0G
系统内存大小为:0.375G
Heap
PSYoungGen total 29696K, used 4613K [0x00000007bdf00000, 0x00000007c0000000, 0x00000007c0000000)
eden space 25600K, 18% used [0x00000007bdf00000,0x00000007be381548,0x00000007bf800000)
from space 4096K, 0% used [0x00000007bfc00000,0x00000007bfc00000,0x00000007c0000000)
to space 4096K, 0% used [0x00000007bf800000,0x00000007bf800000,0x00000007bfc00000)
ParOldGen total 68608K, used 0K [0x00000007b9c00000, 0x00000007bdf00000, 0x00000007bdf00000)
object space 68608K, 0% used [0x00000007b9c00000,0x00000007b9c00000,0x00000007bdf00000)
Metaspace used 3860K, capacity 4572K, committed 4864K, reserved 1056768K
class space used 429K, capacity 460K, committed 512K, reserved 1048576K
进程已结束,退出代码 130 (interrupted by signal 2: SIGINT)为什么会少了4M呢?根据上面Heap打印出来的结果,可以看到from space和to space的大小都是4M,而同一个时刻只有一个会被使用,另外一个空着,所以有效空间就是100M-4M=96M。
5.3.4 通过jsp+jstat 查看进程的堆分配
要检查堆的分配情况, 我们除了上面的两种方式 ,还可以使用jsp+jstat 组合命令来查看。
jps:查看java进程 jstat:查看某进程内存使用情况
首先,启动程序HeapSpaceInitial之后,我们在终端输入 jps命令,可以看到当前正在执行的进程,例如我的电脑可以看到:
可以看到HeapSpaceInitial对应的进程号是27005。然后使用命令 jstat -gc 进程id,就可以看到堆的使用情况:

上述数字的单位都是KB,其中每个选型的含义是:
SOC: S0区总共容量
S1C: S1区总共容量
S0U: S0区使用的量
S1U: S1区使用的量
EC: 伊甸园区总共容量
EU: 伊甸园区使用的量
OC: 老年代总共容量
OU: 老年代使用的量5.3.5 制造一个堆溢出问题
我们接下来通过一个例子制造出堆溢出的问题
public class OOMTest
public static void main(String[] args)
ArrayList<Picture> list = new ArrayList<>();
while(true)
try
Thread.sleep(20);
catch (InterruptedException e)
e.printStackTrace();
list.add(new Picture(new Random().nextInt(1024 * 1024)));
class Picture
private byte[] pixels;
public Picture(int length)
this.pixels = new byte[length];
上面代码执行一段时间之后就会输出如下的错误信息:
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at ch3_JMM.topic3_Dump.Picture.<init>(OOMTest.java:27)
at ch3_JMM.topic3_Dump.OOMTest.main(OOMTest.java:18)我们再次通过jvisualvm来看一下堆内存变化图:

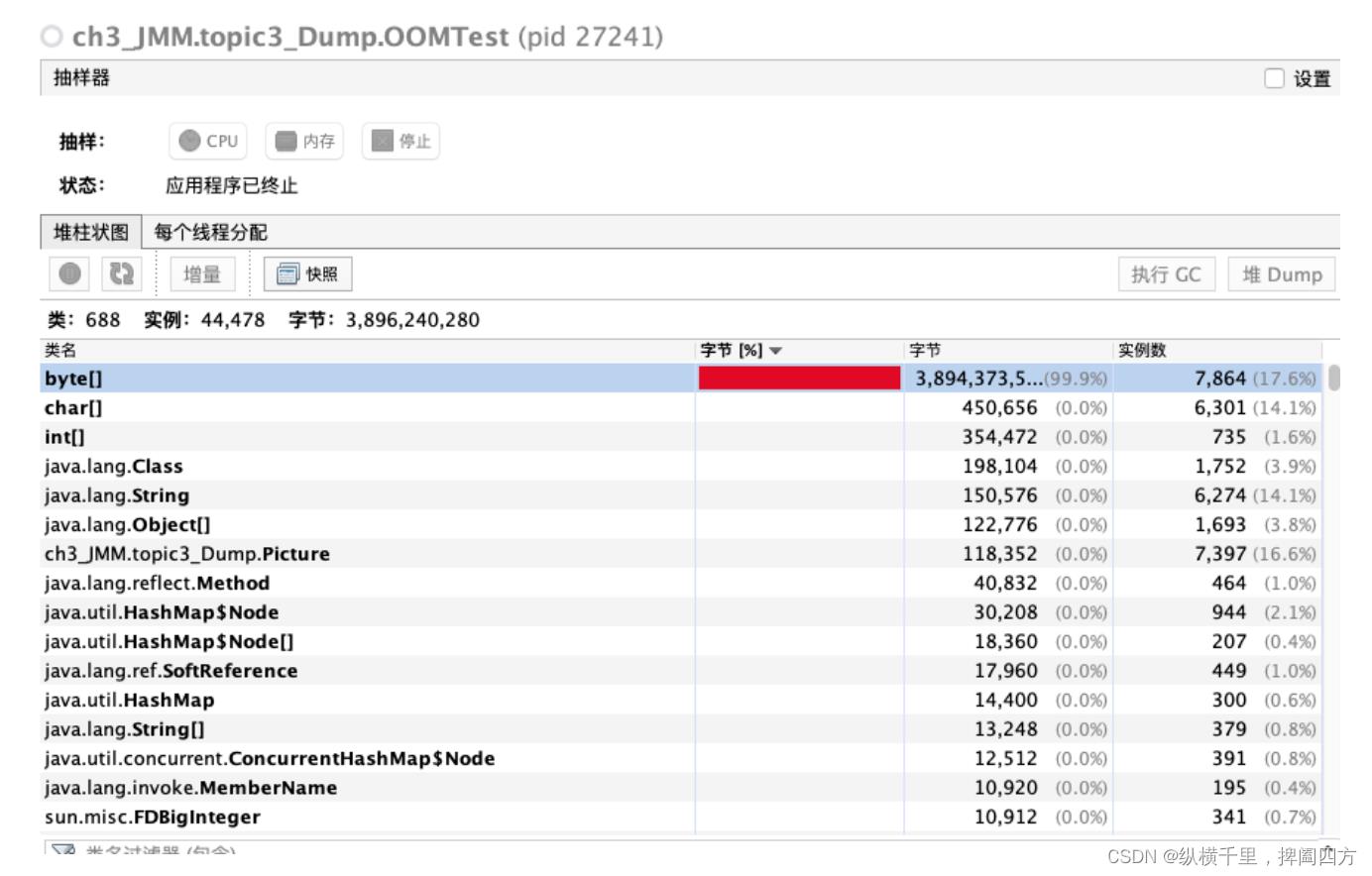
可以看到Old位置的内容在不断增加,当满之后就报出上面的“Java heap space”异常。
如果打开抽样器,并选择“内存”,可以看到byte[]占用了99.9%的空间,这就是我们创建了过多的大对象导致堆内存溢出。
5.3.6 堆空间常见参数设置
官方文档:https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html。其中几个常用的如下:
// 详细的参数内容会在JVM下篇:性能监控与调优篇中进行详细介绍,这里先熟悉下 -XX:+PrintFlagsInitial //查看所有的参数的默认初始值 -XX:+PrintFlagsFinal //查看所有的参数的最终值(可能会存在修改,不再是初始值) -Xms //初始堆空间内存(默认为物理内存的1/64) -Xmx //最大堆空间内存(默认为物理内存的1/4) -Xmn //设置新生代的大小。(初始值及最大值) -XX:NewRatio //配置新生代与老年代在堆结构的占比 -XX:SurvivorRatio //设置新生代中Eden和S0/S1空间的比例 -XX:MaxTenuringThreshold //设置新生代垃圾的最大年龄 -XX:+PrintGCDetails //输出详细的GC处理日志 //打印gc简要信息:①-Xx:+PrintGC ② - verbose:gc -XX:HandlePromotionFalilure://是否设置空间分配担保
这里再做几个说明,在发生Minor GC之前,虚拟机会检查老年代最大可用的连续空间是否大于新生代所有对象的总空间。
-
如果大于,则此次Minor GC是安全的
-
如果小于,则虚拟机会查看-XX:HandlePromotionFailure设置值是否允担保失败。
-
如果HandlePromotionFailure=true,那么会继续检查老年代最大可用连续空间是否大于历次晋升到老年代的对象的平均大小。
-
如果大于,则尝试进行一次Minor GC,但这次Minor GC依然是有风险的;
-
如果小于,则进行一次Full GC。
-
-
如果HandlePromotionFailure=false,则进行一次Full GC。
-
-
在JDK6 Update 24之后,HandlePromotionFailure参数不会再影响到虚拟机的空间分配担保策略,观察openJDK中的源码变化,虽然源码中还定义了HandlePromotionFailure参数,但是在代码中已经不会再使用它。
-
JDK6 Update 24之后的规则变为只要老年代的连续空间大于新生代对象总大小或者历次晋升的平均大小就会进行Minor GC,否则将进行Full GC,即 HandlePromotionFailure=true
5.4 代码优化简介
随着JIT编译期的发展与逃逸分析技术逐渐成熟,栈上分配、标量替换优化技术将会导致一些微妙的变化,所有的对象都分配到堆上也渐渐变得不那么“绝对”了。
在Java虚拟机中,对象是在Java堆中分配内存的,这是一个普遍的常识。但是,有一种特殊情况,那就是如果经过逃逸分析(Escape Analysis)后发现,一个对象并没有逃逸出方法的话,那么就可能被优化成栈上分配。这样就无需在堆上分配内存,也无须进行垃圾回收了,这也是最常见的堆外存储技术。
此外,基于OpenJDK深度定制的TaoBao VM,其中创新的GCIH(GC invisible heap)技术实现off-heap,将生命周期较长的Java对象从heap中移至heap外,并且GC不能管理GCIH内部的Java对象,以此达到降低GC的回收频率和提升GC的回收效率的目的。
使用逃逸分析手段,可以将堆上的对象分配到栈。这样可以有效减少Java程序中同步负载和内存堆分配压力的跨函数全局数据流分析算法。通过逃逸分析,Java Hotspot编译器能够分析出一个新的对象的引用的使用范围从而决定是否要将这个对象分配到堆上。
逃逸分析的基本行为就是分析对象动态作用域:当一个对象在方法中被定义后,对象只在方法内部使用,则认为没有发生逃逸。当一个对象在方法中被定义后,它被外部方法所引用,则认为发生逃逸。例如作为调用参数传递到其他地方中。
逃逸分析举例
1、没有发生逃逸的对象,则可以分配到栈(无线程安全问题)上,随着方法执行的结束,栈空间就被移除(也就无需GC)
W w=new W
public void my_method()
V v = new V();
// use v
// ....
v = null;
2、下面代码中, StringBuffer 类型的变量sb要被调用createStringBuffer()方法的地方使用,因此发生了逃逸,不能在栈上分配
public static StringBuffer createStringBuffer(String s1, String s2)
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb;
如果想要StringBuffer sb不发生逃逸,可以这样写。这里的sb.toString()相当于创建了一个新的对象,sb对象仅在createStringBuffer方法里被使用,因此就可以进行栈上分配。
public static String createStringBuffer(String s1, String s2)
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb.toString();
开发中能使用局部变量的,就不要使用在方法外定义,这种优化也称为”栈上分配“。
6.方法区
6.1 栈、堆、方法区的交互关系
当我们写出如下的代码:
Person person=new Person();
这里Person是我们生成的字节码,也就是.class文件,此时JVM到底是怎么存的呢?

方法区主要存放的是 Class,而堆中主要存放的是实例化的对象,而栈里存的是堆中对象的地址,针对上面的例子,具体的存储策略是:
-
Person 类的 .class 信息存放在方法区中
-
真正创建的 person 对象存放在 Java 堆中
-
person 变量存放在 Java 栈的局部变量表中,就是常见的reference字段。其实就是堆中person对象的地址。
-
在 person 对象中,有个指针指向方法区中的 Person 类型数据,表明这个 person 对象是用方法区中的 Person 类 new 出来的。
堆和栈的问题,我们已经介绍过,接下来我们详细介绍方法区相关内容。
首先,方法区在哪里呢?对于不同的虚拟机是略有不同,对于HotSpotJVM而言,方法区还有一个别名叫做Non-Heap(非堆),目的就是要和堆分开。所以,方法区可以看作是一块独立于Java堆的内存空间。
方法区(Method Area)与Java堆一样,是各个线程共享的内存区域。多个线程同时加载统一个类时,只能有一个线程能加载该类,其他线程只能等待该线程加载完毕,然后直接使用该类,即类只能加载一次。
方法区在JVM启动的时候被创建,并且它的实际的物理内存空间中和Java堆区一样都可以是不连续的。而且方法区的大小,跟堆空间一样,可以选择固定大小或者可扩展。方法区的大小决定了系统可以保存多少个类,如果系统定义了太多的类,导致方法区溢出,虚拟机同样会抛出内存溢出错误:java.lang.OutofMemoryError:PermGen space或者java.lang.OutOfMemoryError:Metaspace。常见的问题有如下几种情况:加载大量的第三方的jar包、Tomcat部署的工程过多(30~50个)或者大量动态的生成反射类。
执行一个程序需要加载的类数量可能远超我们的想象,例如下面这个简单的类:
public class MethodAreaDemo
public static void main(String[] args)
System.out.println("start...");
try
Thread.sleep(1000000);
catch (InterruptedException e)
e.printStackTrace();
System.out.println("end...");
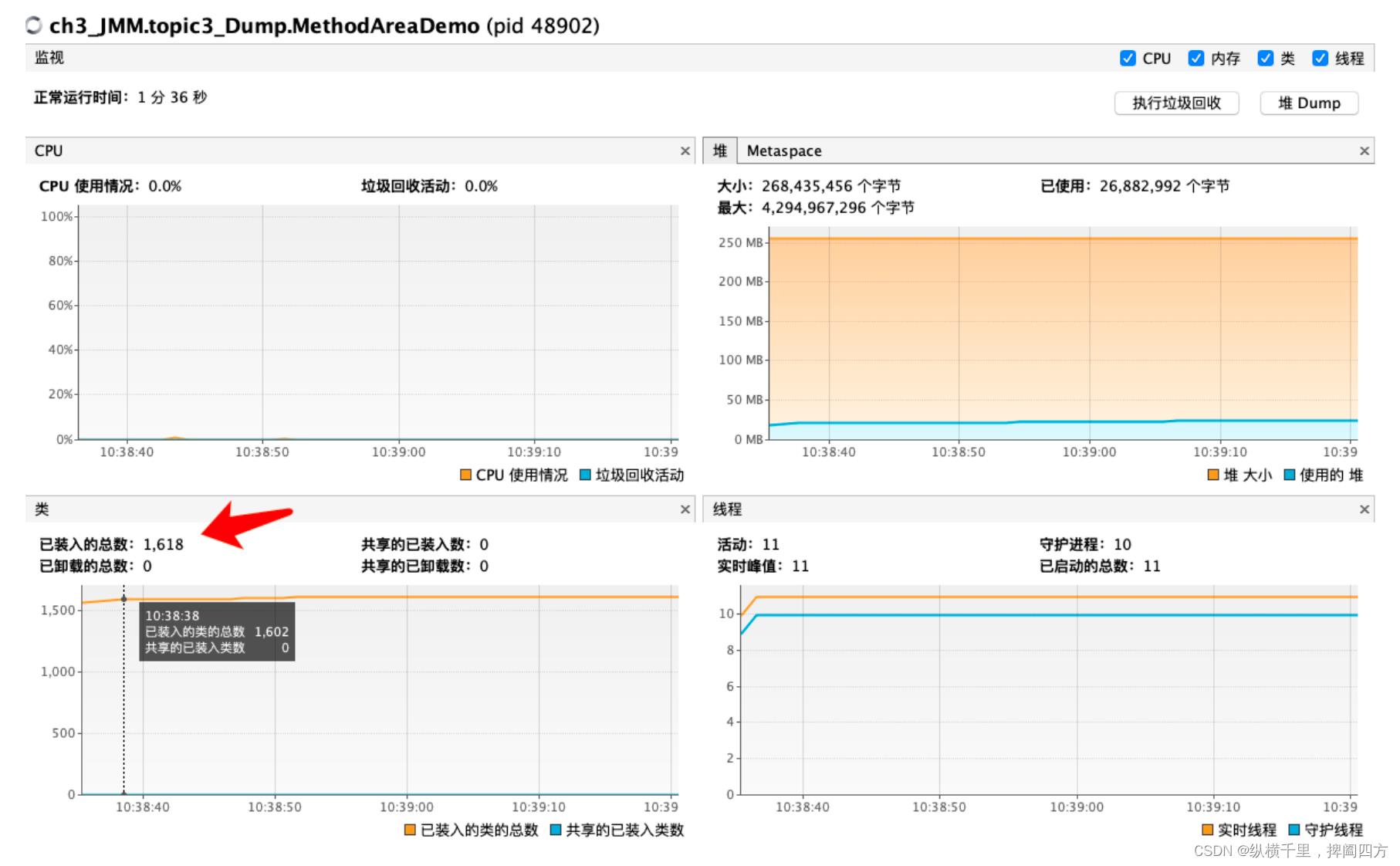
执行时,通过jvisualvm观察,可以发现其加载了1600多个类。
方法区与永久代、元空间的关系
在 JDK7 及以前习惯上把方法区称
以上是关于一文搞定JVM的内存结构的主要内容,如果未能解决你的问题,请参考以下文章