mongoDB副本集
Posted 我要出家当道士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mongoDB副本集相关的知识,希望对你有一定的参考价值。
目录
一、副本集架构
参考:Replica Set Members — MongoDB Manual

mongoDB 3 版本中副本集中最多支持 50 个节点,其中七个节点具备投票权。
1、primary
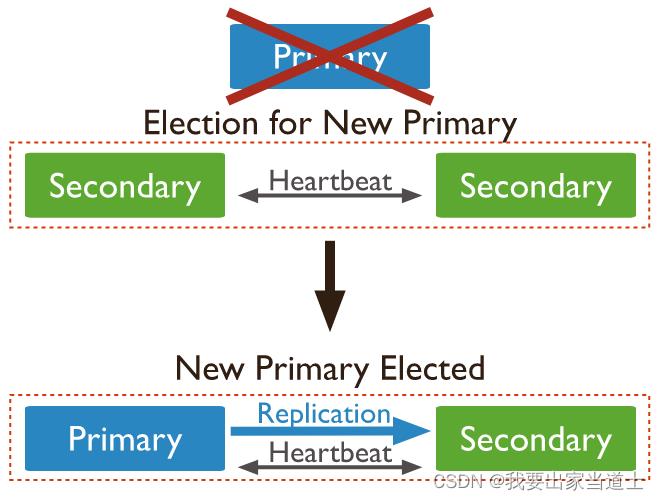
副本集中最多只能存在一个Primary节点。
面向用户,所有的数据写操作均作用于该节点。同时该节点也支持读操作,副本集中所有的节点都支持读操作,但用户读操作默认作用于Primary节点。
在该节点上左右的数据变动,均会产生 oplog(操作日志)。Secondary节点可以通过Primary的复制oplog同步数据。
2、secondary
维护与Primary相同的数据副本,支持提供读操作。同时还充当Primary候选节点,当Primary故障时可以根据身上状态自荐为Primary,之后各节点进行投票,选出Primary节点。注意,权重为 0 的节点无法被选举为Primary节点(权重为0的节点仍具备读与投票的功能)。
Secondary节点还可以进行隐藏设置。隐藏的Secondary,正常的同步Primary节点的数据,但其权重为 0,无法被选举为Primary节点(可以投票),而且对用户不可见(db.isMaster()不显示隐藏节点)。隐藏的Secondary节点可以用于执行一些专项任务(报告、备份等),除此之外不会存在其它通讯流量。

Secondary还可以设置延迟节点(delay node),延迟节点可以按设置的时间延迟备份Primary 的数据。如下如所示,延迟节点必须设置为隐藏的,且权重为 0。对于延迟节点的作用可能有点不好理解,为啥要延迟复制呢?其实延迟节点的数据相当于 Primary 节点过去某一个时间的数据快照。副本集中所有的 Secondary 节点都是于 Primary 数据同步的,但如果操作人员的一些失误使得整个集群中的数据都出错了,设置延迟节点可以将数据可以恢复到过去某一个时间。

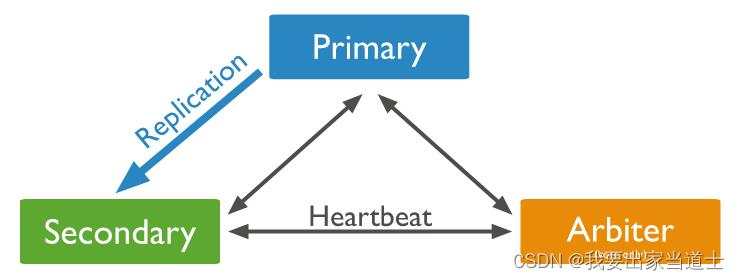
3、Arbiter
仲裁节点,不存储数据,也无法成为Primary节点,主要用于选举从Seconary节点中选举Primary节点。
二、oplog
副本集中所有的 Secondary 与 Primary 都是数据同步的(延迟节点除外),他们之间通过oplog 实现数据同步。oplog 是 Primary 节点上的数据操作日志,是幂等的(多次执行,结果一致),Secondary 依据 oplog 即可复现 Primary 节点的所有数据操作,实现数据同步。副本集内所有的节点都会在本地维护一个 oplog(lcoal.oplog.rs),用于记录维护数据的状态。
oplog 大小约束如下。

1、oplog 结构
可以使用mongodump导出oplog数据,查看结构。
由于mongodump导出数据为bson格式的,你可以使用bsondump转换为json格式。
| 属性 | 描述 | 取值 |
| ts | 时间戳。包含两个变量,前者表示操作发生的时间(单位:秒),后者表示相同时间内操作实现的顺序(默认从1开始) | (timestamp, count) |
| h | 唯一标识操作的ID | |
| t | ||
| v | 版本 | |
| op | i:insert,数据库插入操作 | |
| d:delete,数据库删除操作 | ||
| u:update,数据库更新操作 | ||
| c:command,数据库执行命令,如建集合 | ||
| n:none,空操作 | ||
| ns | 写操作 | db_name.collection_name |
| 数据库命令执行操作 | db_name.$cmd | |
| 空操作 | blank | |
| o | 初始化副本集 | "msg":"initiate set" |
| 选取主节点 | "msg": "new primary" | |
| 新增第一个从节点 | "msg": "Reconfig Set", "version":2 | |
| 新增第二个从节点 | "msg": "Reconfig Set", "version":3 | |
| 移除一个从节点 | "msg": "Reconfig Set", "version":4 | |
| 创建集合 | "create": "collection_name" | |
| 删除集合 | "drop": "collection_name" | |
| 删除数据库 | "dropDatabase" : 1 | |
| 插入或删除文档 | "_id":1, "Name":"ABC" | |
| 更新文档 | "$set": "Name":"MyTest" |
2、同步延迟
由于主节点执行所有的写操作,从节点可分担主节点读操作的负载压力。一般的业务场景下,也是写少读多,所以同步从节点和主节点的数据可以很好的减轻业务压力。而且当主节点发生故障后可以使用从节点的数据对主节点进行数据恢复。
当主节点发生数据写操作时,会生成一条或多条oplog日志。从主节点生成oplog日志,到从节点复制oplog到本地并复写oplog日志的这段时间就是同步延迟。这个延迟的影响因素有很多,网络,节点的工作负载都有可能影响。
3、oplog 的导入与导出
oplog的导入导出可以使用 mongodump 与 mongorestore 这两个工具。具体的参数解释可以参考官网的介绍。
有两点需要注意:
0、使用mongodump可以使用query参数执行json字符串进行数据过滤。
1、mongorestore 只支持插入,不支持覆盖操作。即在数据恢复的时候如果已经存在了相同ID的文档,则忽略掉。
2、mongorestore 在进行数据恢复时也会产生 oplog日志。
mongodump — MongoDB Manual https://www.mongodb.com/docs/v3.4/reference/program/mongodump/mongorestore — MongoDB Manualhttps://www.mongodb.com/docs/v3.4/reference/program/mongorestore/
https://www.mongodb.com/docs/v3.4/reference/program/mongodump/mongorestore — MongoDB Manualhttps://www.mongodb.com/docs/v3.4/reference/program/mongorestore/
以上是关于mongoDB副本集的主要内容,如果未能解决你的问题,请参考以下文章