一文理解OpenStack网络
Posted 华为云开发者联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文理解OpenStack网络相关的知识,希望对你有一定的参考价值。
摘要:如果你能理解OpenStack的网络,那么对于其他云平台的网络,应该也可以通过分析后理解掌握了。
本文分享自华为云社区《《跟唐老师学习云网络》 - OpenStack网络实现》,作者: tsjsdbd 。
整体设计
首先,OpenStack是用来管理大量的VM的“上帝”。他的目的是要像掌控物理世界一样,去管理大量的VM。即:可以给VM分组,同一个组里面的VM,在同一个网络内,可以互通通信。不同组的VM,则相当于在不同的网络中,互相不能通信。
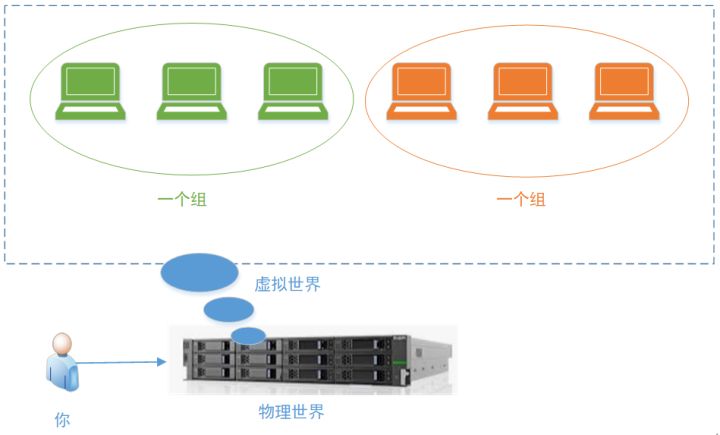
至于为什么要分组,
1、是跟物理服务器一样,那么多机器,按照不同机房的服务器,连到不同的网络。
2、是我可以把不同组的VM,卖给不同的“用户”,这样,组1的VM属于张三,组2的VM属于李四,这样他们俩互相隔离,互不感知。于是我就可以化身成为云厂商,对外提供云平台服务了。
- 当然你作为云厂商,也肯定要允许一个用户,可以拥有2个网络嘛。万一该客户人傻钱多,就是买了一堆VM,分着玩呢,是吧。
逻辑视图
现实中,2个机房的服务器,网络要想连通,是要靠路由器来帮忙的。在虚拟世界中也是类似的。
所以,逻辑上,VM世界的网络就是长这个样。
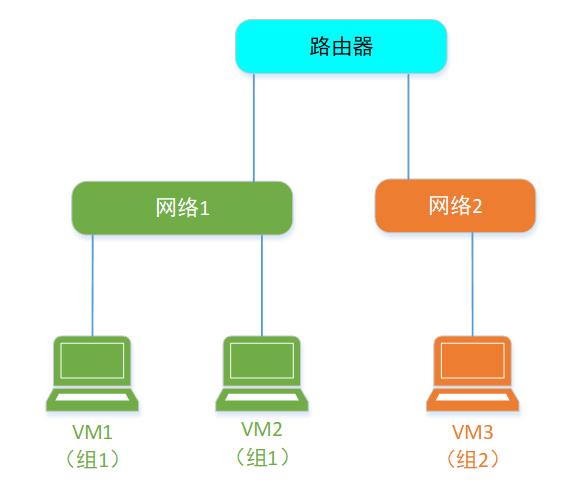
张三的VM的网络,要想和李四VM的网络 互通,或者张三自己的2个独立网络互通。就得通过一个叫做 Router 的“虚拟路由器”来完成。
物理视图
上面的逻辑视图,在物理上,则是这个样子的:
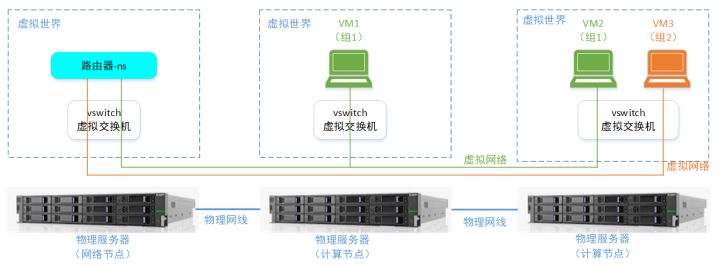
至于如何在一根网线上面,同时跑多个虚拟网络的报文。这个就是在一根网线上的报文,有不同门派的意思。具体的可以回去看VLAN/VxLAN章节。
另外,这里你可以看到,虚拟网络里面的一个“Router”,其实不是什么具体的虚拟路由器设备,而仅仅是一个“网络namespace+转发规则”就达成了,下面会细讲。
简单模型
假设现在你来设计OpenStack的网络实现。
那从我们之前学到的OVS章节,可以知道,为了达成上面提到的OpenStack的网络虚拟化目的。最简单的实现是给每个物理服务器上增加一个OVS虚拟交换机;然后每个VM都连到OVS端口上,每个端口则按照分组,打上对应的VLAN标签。就可以达成基本要求。
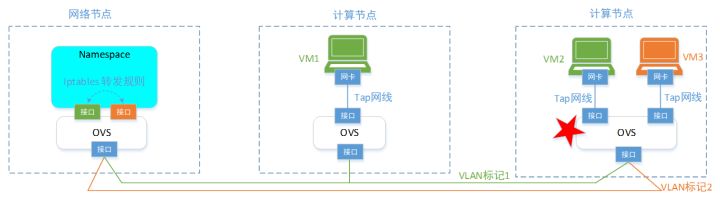
但是,这个初始1.0版本的实现,有个不牛批的地方,就是没法给VM设置安全组。你作为想成为云平台伟大目标,平台怎么能没有安全组这个能力呢(虽然,在VM里面,可以设置firewell或者iptables规则,但是VM里面,那是已经卖给用户的了,你跑人家房间里面,去设置规则并不合适,可能和用户自己的业务规则冲突)。
所以第2个版本,改进之。我们要在VM的外面设置安全组:
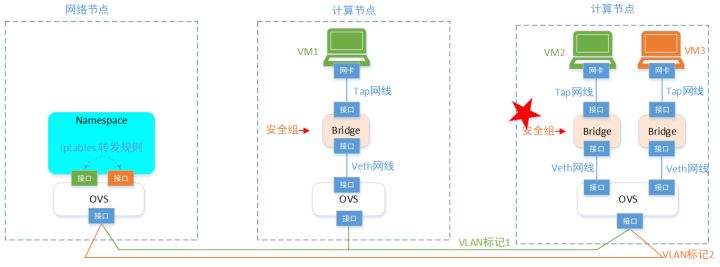
于是,我们在每个VM大门口,增加一个Bridge网桥,任何VM的流量,都会经过这个Bridge。这样,通过在Bridge上面,增加iptables规则,就可以达到给VM设置安全组的目的了。(注意,这个时候,VM的报文还没有到OVS,所以报文还是没有打VLAN标签的原始报文,所以iptables规则也好实现)。
这就是咱们的OpenStack网络2.0版本。
但是,在实践中,你发现这个独苗OVS,要设置端口转发规则有2部分:
- 上半部分。即:给VM设置Tag标签。
每增加一台VM时,就给这个端口打标签,插拔虚拟网线等配置动作。这一部分逻辑比较固定,不怎么变化。
- 下半部分。即:通过物理网线,怎么给报文打“门派”标记。
这一部分变化很大,有时候物理网络,咱得走GRE,有时候要走VLAN,有时候又得VxLAN。还有时候,得走专用的网络设备。平台得根据部署的机房网线,定制不同的规则。
这样这2类OVS的规则不好管(都放openflow的转发表里面),本着程序员的“分库分表”(或者咱们写代码时的,“抽取函数”的逻辑)的思路,咱们把1个独苗OVS,分成多个VOS。分别做不同的事情。
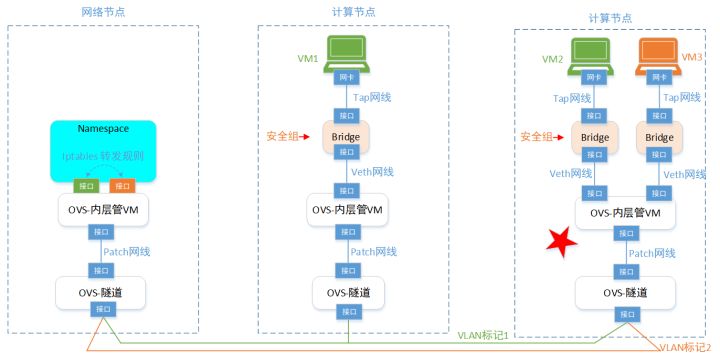
于是,咱们到了3.0版本,这个版本就比较通用了。基本可以和实际OpenStack的网络比较接近了。不过在网络节点部分,还得再增强一下。就是咱们的VM,除了互访之外(流量还在几台物理服务器之间转悠),还得访问外网呀(流量跑机房外部去)。 所以,还得继续增强一下VM访问外部网络的能力:
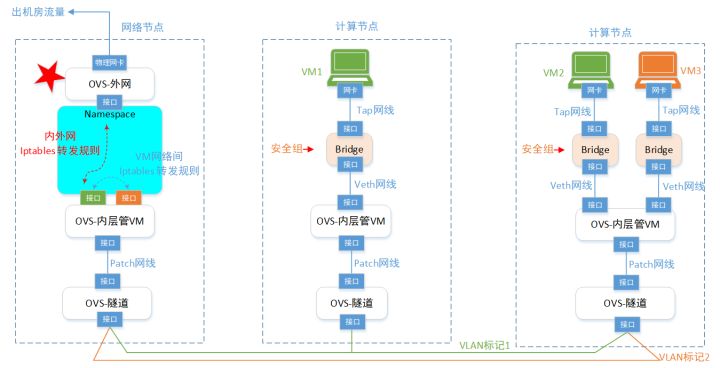
这么一来,就到了差不多4.0版本了。后面咱们介绍的OpenStack网络,就是照着这个版本来的。在OpenStack网络里面,对各种ovs,bridge,接口的命名,有一套自己的规范。不像上面这么随意的取名。
控制节点
有了上面这些给VM设置虚拟网络用的模型,那么要搞成自动化(即:每创建一个VM,给它设置好配套的虚拟网线连接)。 你得写个主控程序,用来控制这些计算节点上面的行为吧。如下:
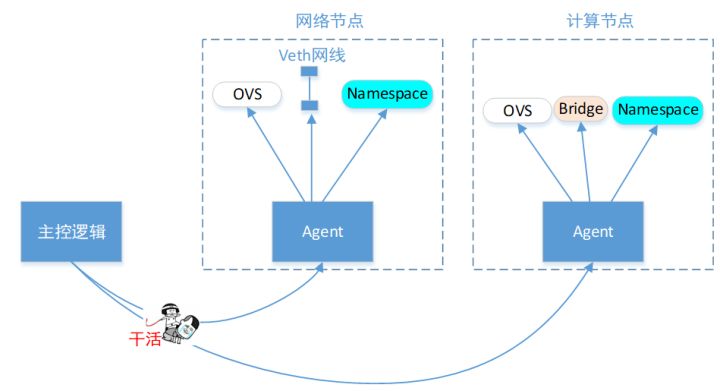
所以,按照OpenStack官方的架构,它需要有3种节点:管节点,计算节点,网络节点。
每个节点上面,部署了一堆agent,用来接收老大的控制命令。老大就是Master管理节点了。
注:之前章节也提过,分布式系统,可靠的控制都需要有个“代理商”,比如RabbitMQ(OpenStack选了这个),ETCD(Kubernetes选了这个),ZooKeeper(Hadoop选了这个)这种。
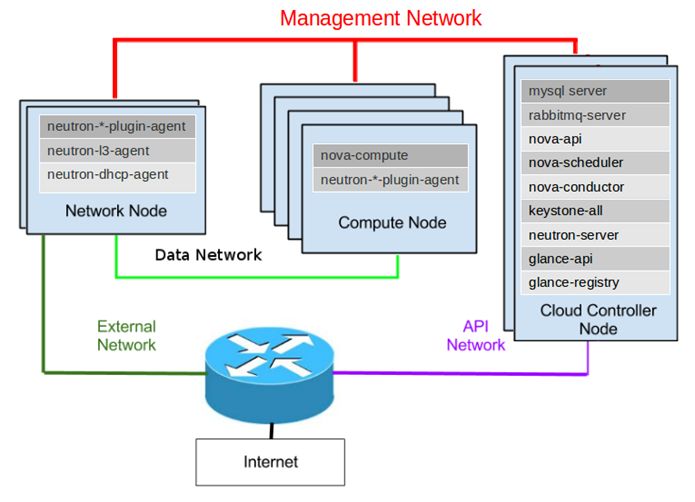
(1)首先是最上面红色的线,就是“主控逻辑”用来控制Agent干活的,简称管理面网络。
(2)然后是中间绿色的线,那就是VM们在这根网线上面,发送大量的“自己门派”的报文,即VM间互相通信,都要走的网络,数据量很大。简称数据面。
为了确保管理面和数据面隔离,互不影响(即:VM疯狂发包,别把管理命令的报文给冲没了)。每台物理服务器上面,得有2块网卡,一块用来走管理网线,一块用来走数据网线。
(3)接着就是左下角的墨绿色线,这个是VM们访问机房外部网络用的。只需要网络节点,有一个额外的网卡就行了。
(4)最后是紫色的线。你的主控逻辑,要不要包装成API接口,对外部暴露访问通道? 要的话,可以加上。不要的话,那就每次都登陆到主控节点里面,手动敲命令控制也行。
计算节点
这里咱们打开一个OpenStack的计算节点,看看它的网络构造,遥记当年(2013年,OpenStack版本Havana)我学OS网络的时候,看到一个资料,对我帮助很大,这里直接贴上来:
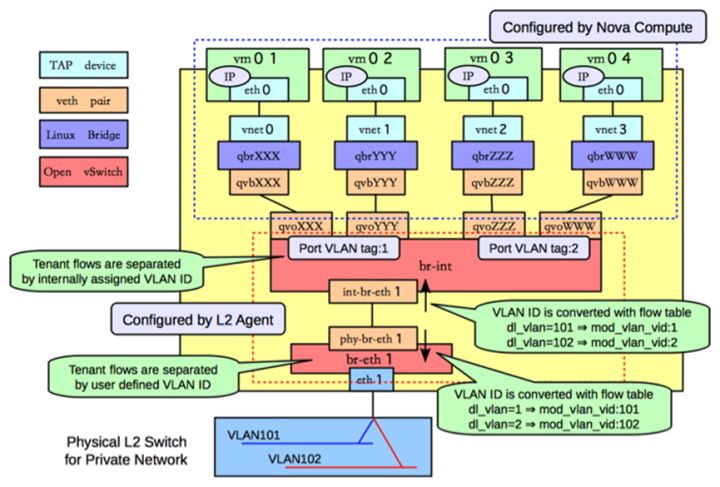
照着前文的“设计思路”,你应该可以看懂上图的网络逻辑了吧。命名上,一般内部的ovs叫 br-int。隧道的叫 br-tun。如果你有环境的话,在节点上面查询,使用各种网络命令(ip,ovs-vsctl,brctl等),你可以证实一下。
网络节点
同样,网络节点,网络组成如下:
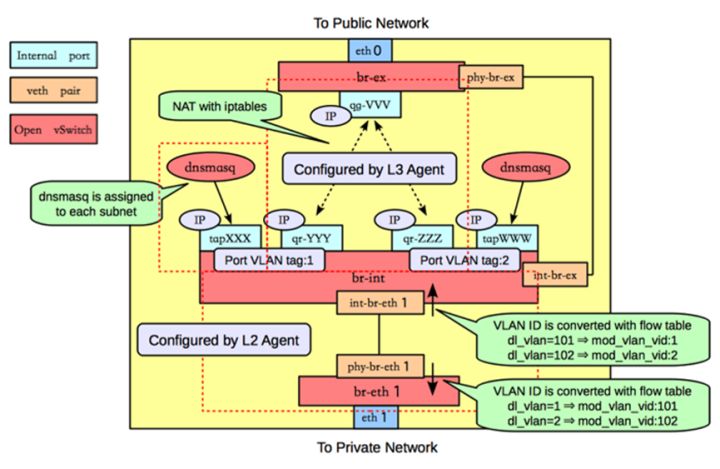
其中,上部的红色虚线,表示一个 网络namespace。dnsmasq是一个DHCP服务器(自动分配IP的程序,用来给VM分配IP地址)。
这个节点也使用各种网络命令来查询查看确认。
ps,由于该网络节点上有很多网络namespace,所以记得使用 ip netns exec命令来进入到对应的ns查询这个虚拟空间里面的详情。
floating IP(EIP)
VM除了有自己的虚拟网络内的IP,还可以拥有一个floating IP(注:对应云厂商,一般把这个叫做 EIP)。咱们来看下这个“浮动IP”是个什么实现逻辑。
逻辑概念
首先,浮动IP,是物理网络世界的,即OpenStack的外部网络的。它是一个真实存在的IP地址(不跟VM一样,那是你虚拟出来的IP)。
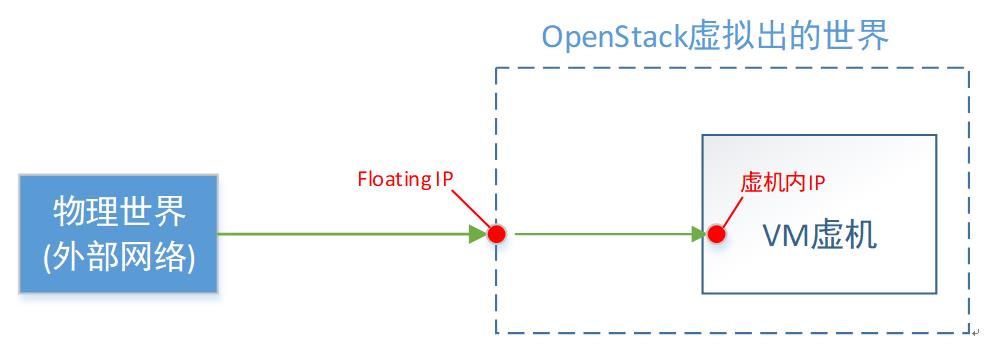
如上图,对floating IP,我总结的一句话概况就是:VM对外的名号。
当你从外部网络,访问这个“浮动IP”,就等于访问这一台VM。至于为什么要叫“浮动”这个词,是因为这个名号,会漂移。
举个例子:“护国大法师”这个名号很响亮,当你一报你要找“护国大法师”这个人时,大家都知道你要找具体的谁。但是这个“护国大法师”名号,是可以从一个人身上转移到另一个人身上的。
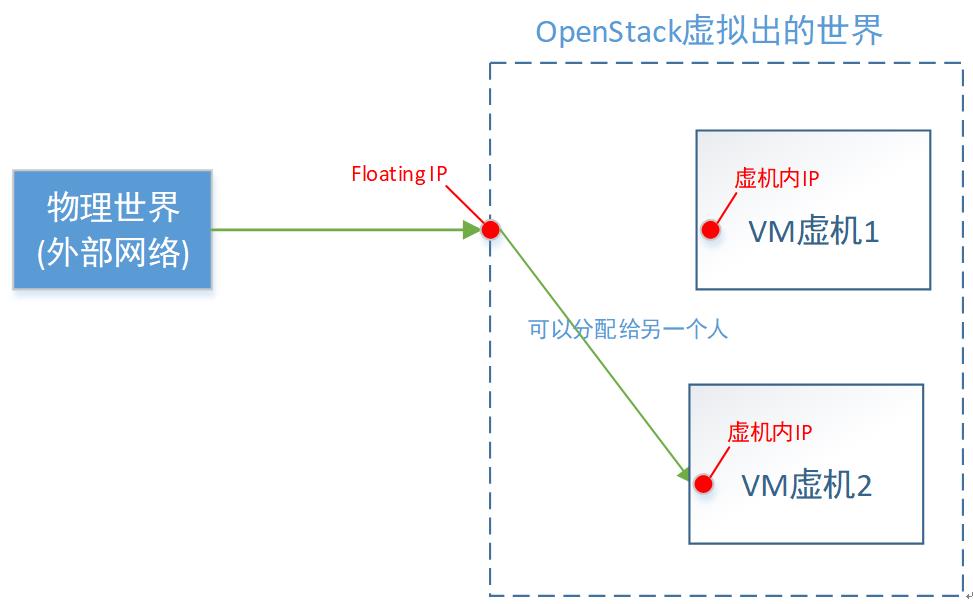
直接对应云厂商的EIP,是不是就好理解了。
具体实现
我们关注点,直接聚焦到网络节点的一个namespace里面。(本例的浮动IP是 192.168.101.3)。如下图:
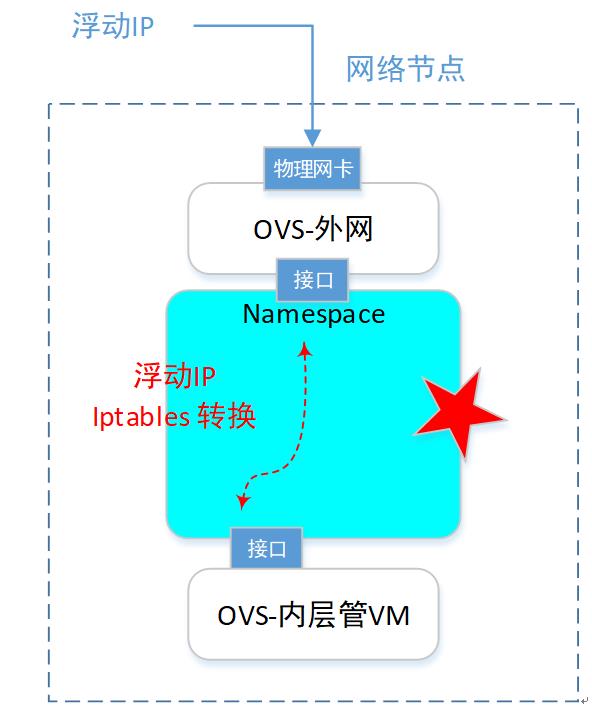
在网络节点,查询ns。
root@netnode:/# ip netns
qdhcp-a7e512cf-1ca0-4ec7-be75-46a8998cf9ca
qrouter-4cdb0354-7732-4d8f-a3d0-9fbc4b93a62d找到对应的 router 那个ns(上图五角星处),然后查询这个里面的网卡信息:
root@netnode:/# ip netns exec qrouter-4cdb0354-7732-4d8f-a3d0-9fbc4b93a62d ip address
11: qg-1423ba35-7c: <BROADCAST,MULTICAST,PROMISC,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN
inet 192.168.101.2/24 brd 192.168.101.255 scope global qg-1423ba35-7c
inet 192.168.101.3/32 brd 192.168.101.3 scope global qg-1423ba35-7c
12: qr-9f1fa61e-1e: <BROADCAST,MULTICAST,PROMISC,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN
inet 172.17.17.1/24 brd 172.17.17.255 scope global qr-9f1fa61e-1e可以看到,有个叫qg-xx的网卡,拥有了这个 floating IP地址。
然后我们查询一下这个ns里面的iptables规则:
root@netnode:/# ip netns exec qrouter-4cdb0354-7732-4d8f-a3d0-9fbc4b93a62d iptables -t nat -S你会发现有这么2条规则:
-A quantum-l3-agent-float-snat -s 172.17.17.2/32 -j SNAT --to-source 192.168.101.3
-A quantum-l3-agent-PREROUTING -d 192.168.101.3/32 -j DNAT --to-destination 172.17.17.2第1条是SNAT规则,就是把源IP地址换掉的意思。 具体内容是:如果源IP是 172.17.17.2 的(VM的),那么把源IP换成192.168.101.3(floatingIP的)。
第2条是DNAT规则,就是把目的IP地址换掉。具体内容是:如果目的IP的192.168.101.3(floatingIP的),就把目的IP换成172.17.17.2 的(VM的)。
这样一来,报文不就统统转给了这个VM嘛。
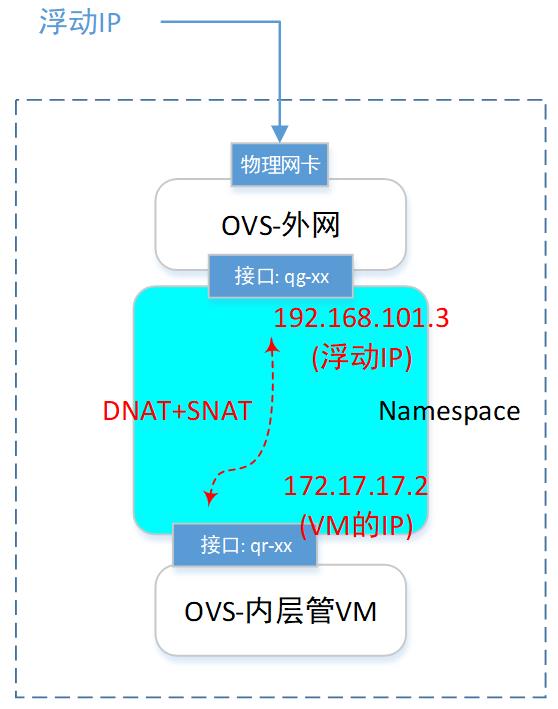
于是,一个VM一旦拥有了floatingIP(也叫EIP),它就可以被外网访问,也可以直接访问外网。
不过,真正的外部IP,可能是有限的,得省着点用,这就有了下面的SNAT和DNAT功能。
SNAT功能
如果一台VM,想访问外部网络,但是又不给它分配floatingIP。这时候就可以使用SNAT。
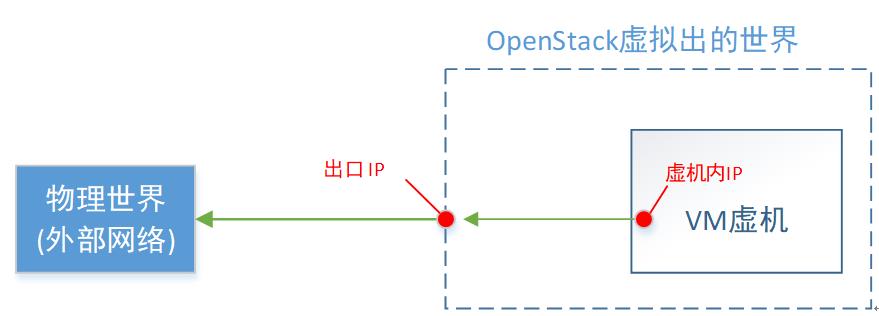
还是上一节的这个ns,查询这个ns里面的网卡信息,可以看到,还有一个 101.2 的IP。
root@netnode:/# ip netns exec qrouter-4cdb0354-7732-4d8f-a3d0-9fbc4b93a62d ip address
11: qg-1423ba35-7c: <BROADCAST,MULTICAST,PROMISC,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN
inet 192.168.101.2/24 brd 192.168.101.255 scope global qg-1423ba35-7c
inet 192.168.101.3/32 brd 192.168.101.3 scope global qg-1423ba35-7c
12: qr-9f1fa61e-1e: <BROADCAST,MULTICAST,PROMISC,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN
inet 172.17.17.1/24 brd 172.17.17.255 scope global qr-9f1fa61e-1e还是查询一下这个ns里面的iptables规则:
root@netnode:/# ip netns exec qrouter-4cdb0354-7732-4d8f-a3d0-9fbc4b93a62d iptables -t nat -S你会发现有这么1条规则:
-A quantum-l3-agent-snat -s 172.17.17.0/24 -j SNAT --to-source 192.168.101.2该规则是,所有源IP是 172.17.17.0/24 这个网段的报文(就是该网络内的所有VM),都把源IP地址换掉的意思。
所以,一旦给一个虚拟网络设置了SNAT功能,那么这个网络里面的所有VM,都可以访问外网了。只是大家共用一个外部出口IP地址(本质还是EIP),这个就是省着点用的意思。
缺点是:只能从内部(虚拟网络)访问外部(外部网络),外部不能访问内部(毕竟,这个IP是大家共用的,不是某一台VM的)。
DNAT功能
在本着省着点用的原则下(即好多VM共享一个外部IP)。如果希望外部访问内部VM,还可以使用DNAT功能。
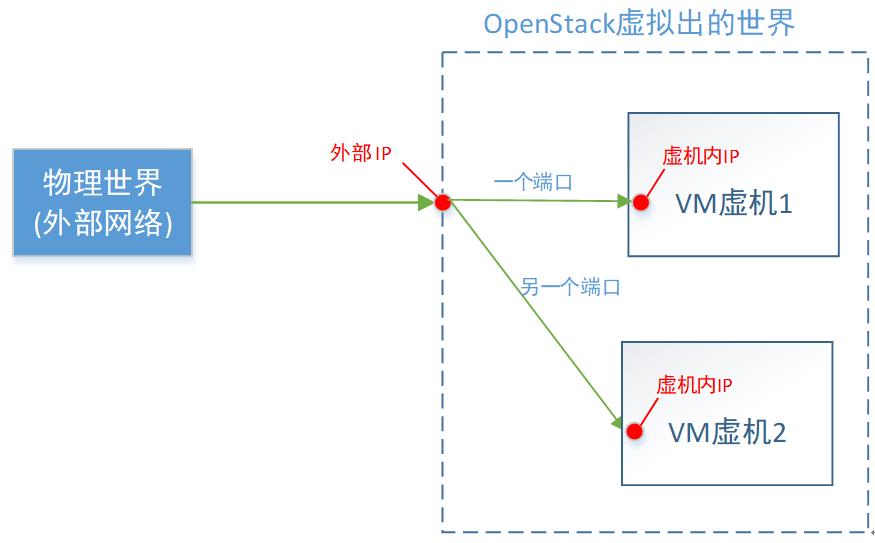
原理上,你应该想到了,就是在ns里面增加一条,根据不同的端口,转发不同目的IP地址的DNAT规则。
这一种省钱的办法,缺点是:只能指定对应的目的端口。比如,外部端口80,分配给VM1占用了。那么VM2就不能用80了,它只能委屈下,使用外部端口号81(或其他)了。
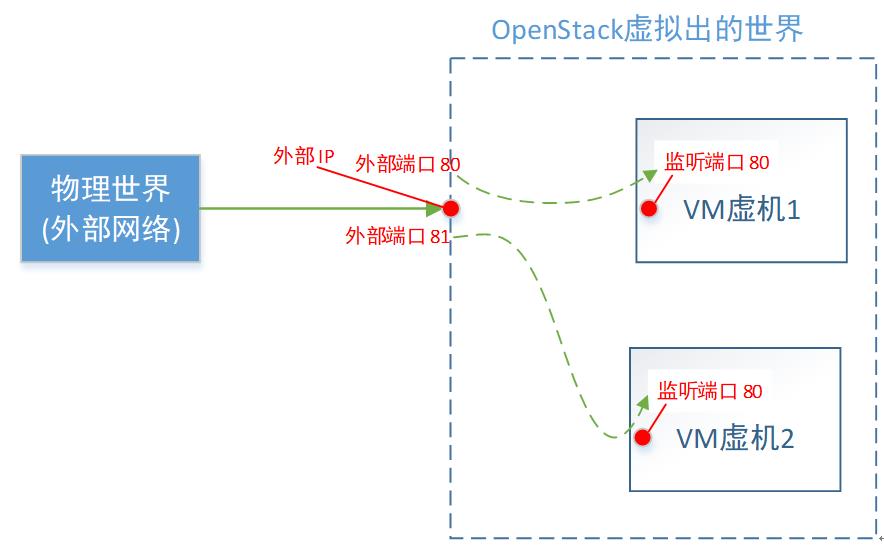
省钱总得要失去点什么,要不然,给每台VM都买个EIP不就完了。
Router
OpenStack里面的Router,是用来将“一个网络”,连接到“另一个网络”的。可以是2个虚拟网络,也可以是1个虚拟网络+1个实际外部网络。
一个Router本质是一个 网络namespace,同上一个章节描述浮动ip一样,这个ns是一个虚拟的“中转站”。 所有的网络连接,需要先到这个中转站“休息打扮一下”,然后再前往目的网络。
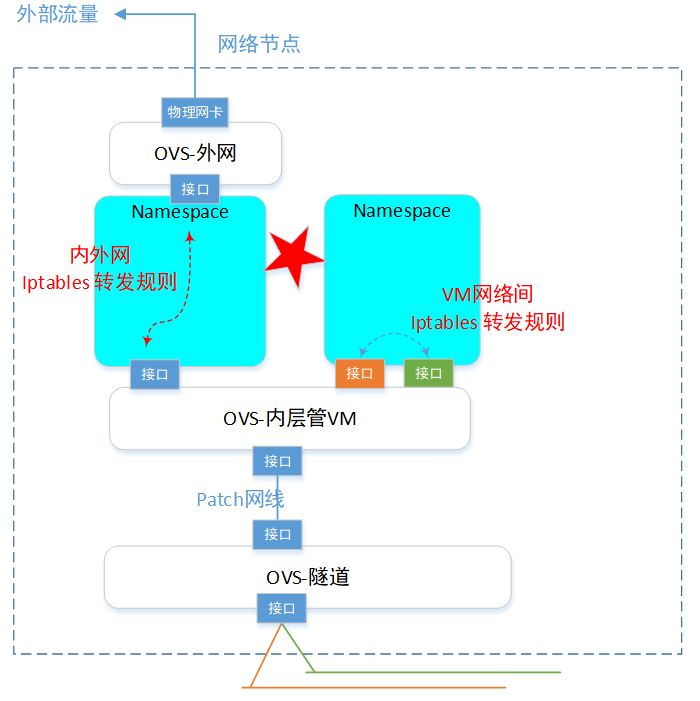
注意,在同一个用户的2个网络互联,和2个不同用户的网络互联,在底层实现的技术上是一样的。不同点是不同用户的话,需要控制好权限,不然张三不就可以随便去连李四的网络了。
Router概念,对应到云厂商,一般叫 “VPC互联”。产品各式各样,比如以前的“vpc peering”,现在的“云企业网络”“企业路由”“云连接”等。
Metadata服务
metadata服务,就是允许每个VM去问上帝(OpenStack平台):“你创建我的档案上面,都写了些什么?”。 这是一个非常有意思的特性。
功能介绍
你(VM)去问上帝,你总得知道上帝在哪里把?所以在OpenStack上,将上帝的地址,写死了一个特殊的IP:169.254.169.254, 挺好记的。
询问上帝的方法:
$ curl http://169.254.169.254
1.0
2007-01-19
2007-03-01
2007-08-29
2007-10-10
2007-12-15
2008-02-01
2008-09-01
2009-04-04
latest你可以去试一下,如果发现这个IP可以访问,说明你可以证明自己的机子是一台被虚拟出来的VM,而不是一台物理机了。
举个例子,VM问:我被生出来后的启动脚本是什么?
即问自己的 “userdata信息”
$ curl http://169.254.169.254/openstack/latest/user_data
#!/bin/bash
echo 'Extra user data here'这个功能,还是比较有用的,特别是在做VM自动化的时候(ps,可以去查一下一个称作 cloud-init 的东西)。
metadata特性应该是来自AWS。OpenStack为了兼容AWS的这个“询问上帝”的功能(当然,肯定也是认可这个功能还是有用的)。也支持了这个 metadata服务。
具体实现
我们知道创造&管理VM的组件,是叫Nova。也就是metadata特性,要从虚拟世界(VM里面)去访问物理世界(Nova的API),经过上面的介绍,这种情况下,肯定要经过一个“中转站”的。
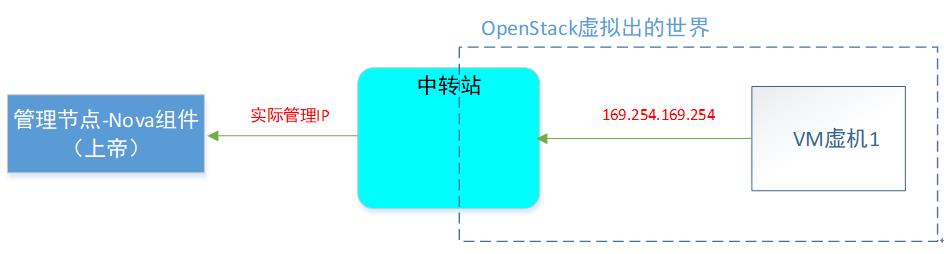
我们先看下VM内部,访问169.254.169.254的时候,报文去哪里了:
在VM里面敲:
ip route
default via 172.17.17.1 dev eth0
172.17.17.0/24 dev eth0 src 172.17.17.5
169.254.169.254 via 172.17.17.1 dev eth0可以看到 访问“上帝”时,报文去了 VM网络的网关IP(172.17.17.1)那了。
那么网关IP在哪里?在网络节点的namespace里面:
root@netnode:/# ip netns exec qrouter-4cdb0354-7732-4d8f-a3d0-9fbc4b93a62d ip address里面有个网卡叫做:
12: qr-9f1fa61e-1e: <BROADCAST,MULTICAST,PROMISC,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN
inet 172.17.17.1/24 brd 172.17.17.255 scope global qr-9f1fa61e-1e我们再来看下,访问169.254的报文,到这个“中转站”后,被如何“拿捏”的。
root@netnode:/# ip netns exec qrouter-7a44de32-3ac0-4f3e-92cc-1a37d8211db8 iptables -S可以看到,目的地址是169.254的报文,会转给本地的 9697端口。
-A quantum-l3-agent-PREROUTING -d 169.254.169.254/32 -p tcp -m tcp --dport 80 -j REDIRECT --to-ports 9697
-A quantum-l3-agent-INPUT -d 127.0.0.1/32 -p tcp -m tcp --dport 9697 -j ACCEPT那么,谁在本地(这个namespace内)监听 9697端口呢?答案是上帝的代理,一个agent在这里偷听呢。
root@netnode:/# ip netns exec qrouter-7a44de32-3ac0-4f3e-92cc-1a37d8211db8 netstat -anpt
tcp 0 0 0.0.0.0:9697 0.0.0.0:* LISTEN 11937/python 看下这个进程号,具体的命令:。
root@netnode:/# ps -ef | grep 11937
root 11937 1 0 08:43 ? 00:00:00 python
/usr/bin/neutron-ns-metadata-proxy -metadata_proxy_socket=/var/lib/neutron/metadata_proxy可以看到,有一个proxy进程监听者9697端口,并将“访问上帝的请求”,转给了本地 unix domain socket 的监听者(即agent)。
使用
root@netnode:/# netstat -lxp | grep metadata或者
root@netnode:/# lsof /var/lib/neutron/metadata_proxy 查询到在监听本地unix domain socket的进程ID
然后看下这个进程ID,是不是上帝的agent:
root@netnode:/# ps -ef | grep “具体进程ID”逻辑上,整体过程如下:
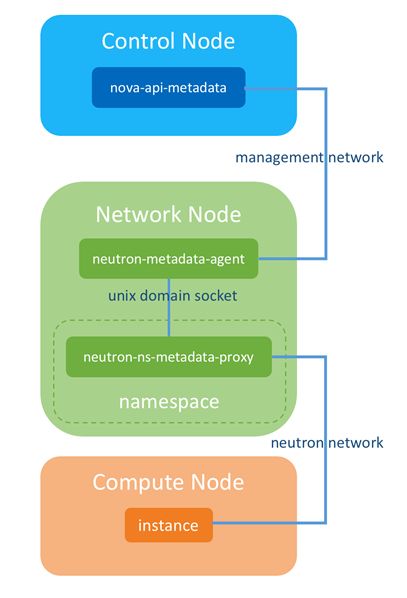
具体可参考该图:
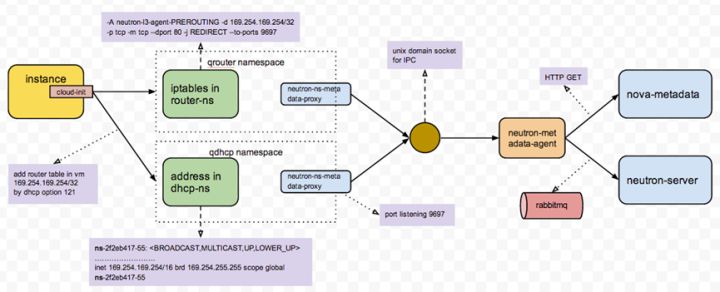
所以,关键其实还是那个 namespace中转站。
附,本段参考链接:
http://niusmallnan.com/_build/html/_templates/openstack/metadata_server.html
http://techbackground.blogspot.com/2013/06/metadata-via-quantum-router.html
DVR(Distributed Virtual Routing)
在上面的介绍中可以看到,所有的VM虚机,要访问外网,都要经过网络节点。这样也有不好地方,1是网络节点的网络流量压力非常大;2是一旦网络节点异常,大量的VM都要受影响。所以,这里能不能把网络节点的“中转站”功能,复制一份到各个计算节点上去。然后在计算节点上面,增加判断逻辑:
if (本地有“中转站”) && (符合使用条件) 使用本地“中转站”;
else 继续使用原来的网络节点的“中转站”。答案就是DVR了。为了降低网络节点的负载,同时提高可扩展性,OpenStack在Juno版本引入了DVR特性,DVR部署在计算节点上。计算节点上的VM使用floatingIP访问Internet,不必经过网络节点,直接从计算节点的DVR就可以访问。
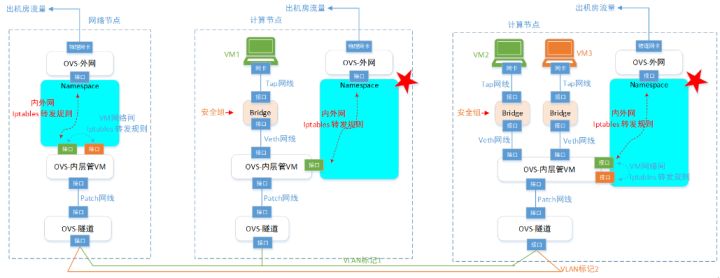
这样网络节点只需要处理占到整体流量一部分的 SNAT (无 floating IP 的 vm 跟外面的通信)流量,大大降低了负载和整个系统对网络节点的依赖。
具体计算节点的if条件判断,就是通过openflow规则,来控制的。这个有点太细节了,没有细研究。可以去看看相应的文章:
https://www.cnblogs.com/sammyliu/p/4713562.html
https://docs.openstack.org/ocata/networking-guide/deploy-ovs-ha-dvr.html
所以你可以看到,原来网络节点的路由器,现在分散到各个计算节点上面了。原来一个人(网络节点的Router)要干的活,现在分散给很多人(各计算节点的Router)干。确实分布式路由器了。
总结
基本上,OpenStack的网络实现,是集成了目前所有的“网络虚拟化零件”,包括:ovs交换机,bridge网桥,veth网线,tap网线,patch网线,namespace空间,iptables规则等。也是唐老师我接触过最复杂的网络实现(所以本文一直拖到最后)。如果你能理解OpenStack的网络,那么对于其他云平台的网络,应该也可以通过分析后理解掌握了。
最后,基础的云网络相关的课程,唐老师就只能教到此了。毕竟咱可以是一个入门导师,也不是专门负责网络开发的。所以在入门后,如果还要继续深入研究云网络,甚至开始设计网络虚拟化方案的,还得靠你自己继续修行。骚年,加油~
注:由于作者现阶段主要专注于云原生相关的业务(Kubernetes集群),所以OpenStack网络信息不就是最新的了。不过这个关系应该不大,因为其网络设计原理是继承的。并且,咱们的课程,主要目的就是能看懂。要设计的话,还得自己再深入学习。So,本着能看懂OpenStack网络的原则,本文还是够用的。
以上是关于一文理解OpenStack网络的主要内容,如果未能解决你的问题,请参考以下文章