Java 应用压测性能问题定位经验分享
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java 应用压测性能问题定位经验分享相关的知识,希望对你有一定的参考价值。
什么是压测
压测,即压力测试,是确立系统稳定性的一种测试方法,通常在系统正常运作范围之外进行,以考察其功能极限和和可能存在的隐患。
压测主要用于检测服务器的承受能力,包括用户承受能力,即多少用户同时使用系统时基本不影响质量、流量承受等。另外,通过诸如疲劳测试还能发现系统一些稳定性的问题,比如是否存在连接池中的连接被耗尽,内存被耗尽,线程池被耗尽,这些只能通过疲劳测试来进行发现定位。
为什么要压测
压测的目的就是通过模拟真实用户的行为,测算出机器的性能(单台机器的 QPS、TPS),从而推算出系统在承受指定用户数(100 W)时,需要多少机器能支撑得住。因此在进行压测时一定要事先设定压测目标值,这个值不能太小,也不能太大,按照目前业务预估的增长量来做一个合理的评估。压测是在上线前为了应对未来可能达到的用户数量的一次预估(提前演练),压测以后通过优化程序的性能或准备充足的机器,来保证用户的体验。压测还能探测应用系统在出现交易洪峰时稳定性情况,以及可能出现的一些问题,发现应用系统薄弱一环,从而更有针对性地进行加强。
压测

这几种测试可以穿插进行,一般会在压力测试性能指标达标后,再安排耐久性测试。
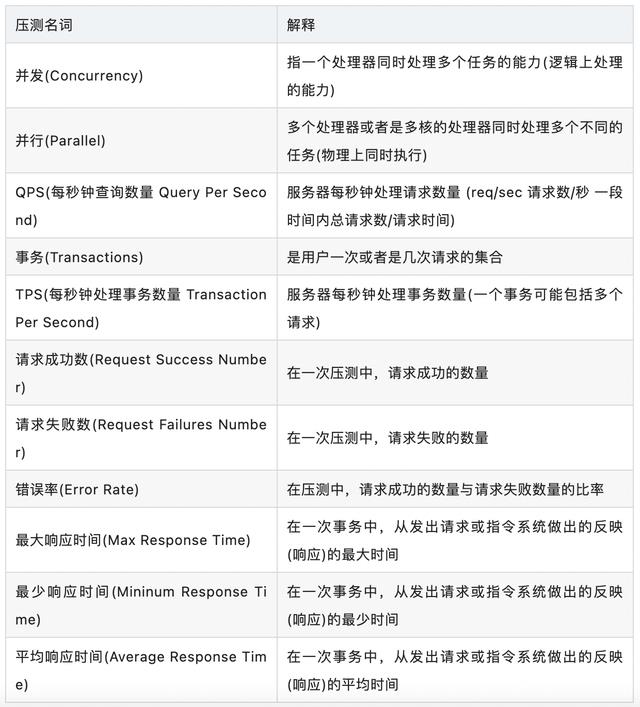
压测名词解释
常见的压测工具
ab
ApacheBench 是 Apache 服务器自带的一个 web 压力测试工具,简称 ab。ab 又是一个命令行工具,对发起负载的本机要求很低,根据 ab 命令可以创建很多的并发访问线程,模拟多个访问者同时对某一 URL 地址进行访问,因此可以用来测试目标服务器的负载压力。总的来说 ab 工具小巧简单,上手学习较快,可以提供需要的基本性能指标,但是没有图形化结果,不能监控。
Jmeter
Apache JMeter 是 Apache 组织开发的基于 Java 的压力测试工具。用于对软件做压力测试,它最初被设计用于 Web 应用测试,但后来扩展到其他测试领域。
JMeter 能够对应用程序做功能/回归测试,通过创建带有断言的脚本来验证你的程序返回了你期望的结果。
JMeter 的功能过于强大,这里暂时不介绍用法,可以查询相关文档使用(参考文献中有推荐的教程文档)
LoadRunner
LoadRunner 是 HP(Mercury)公司出品的一个性能测试工具,功能非常强大,很多企业级客户都在使用,具体请参考官网链接。
阿里云PTS
性能测试 PTS(Performance Testing Service)是一款性能测试工具。支持按需发起压测任务,可提供百万并发、千万 TPS 流量发起能力,100% 兼容 JMeter。提供的场景编排、API 调试、流量定制、流量录制等功能,可快速创建业务压测脚本,精准模拟不同量级用户访问业务系统,帮助业务快速提升系统性能和稳定性。
作为阿里内部使用多年的性能测试工具,PTS 具备如下特性:
- 免运维、开箱即用。SaaS化施压、最大支持百万级并发、千万级TPS流量自助发起能力。
- 支持多协议HTTP1.1/HTTP2/JDBC/MQTT/Kafka/RokectMq/Redis/Websocket/RMTP/HLS/TCP/UDP/SpringCloud/Dubbo/Grpc 等主流协议。
- 支持流量定制。全球施压地域定制/运营商流量定制/IPv6 流量定制。
- 稳定、安全。阿里自研引擎、多年双十一场景打磨、支持 VPC 网络压测。
- 性能压测一站式解决方案。** 0 编码构建复杂压测场景,覆盖压测场景构建、压测模型设定、发起压力、分析定位问题、出压测报告完整的压测生命周期。
- 100% 兼容开源 JMeter。
- 提供安全、无侵入的生产环境写压测解决方案。
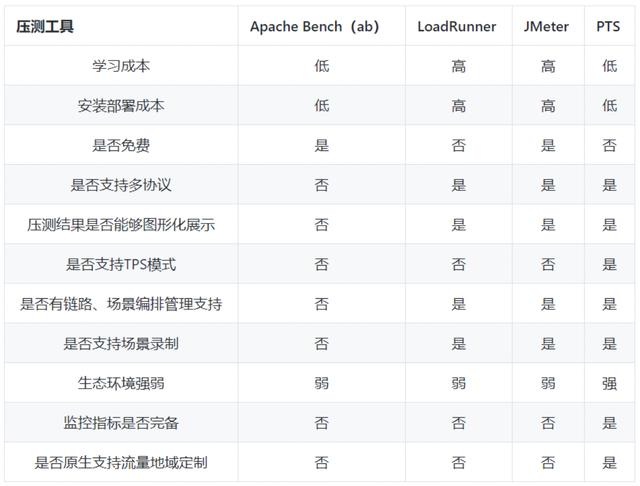
压测工具的比较
如何选择压测工具
这个世界上没有最好的工具,只有最适合的工具,工具千千万,选择一款适合你的才是最重要的,在实际使用中有各种场景,读者可以结合压测步骤来确定适合自己的工具:
- 确定性能压测目标:性能压测目标可能源于项目计划、业务方需求等
- 确定性能压测环境:为了尽可能发挥性能压测作用,性能压测环境应当尽可能同线上环境一致
- 确定性能压测通过标准:针对性能压测目标以及选取的性能压测环境,制定性能压测通过标准,对于不同于线上环境的性能压测环境,通过标准也应当适度放宽
- 设计性能压测:编排压测链路,构造性能压测数据,尽可能模拟真实的请求链路以及请求负载
- 执行性能压测:借助性能压测工具,按照设计执行性能压测
- 分析性能压测结果报告:分析解读性能压测结果报告,判定性能压测是否达到预期目标,若不满足,要基于性能压测结果报告分析原因
由上述步骤可知,一次成功的性能压测涉及到多个环节,从场景设计到施压再到分析,缺一不可。工欲善其事,必先利其器,而一款合适的性能工具意味着我们能够在尽可能短的时间内完成一次合理的性能压测,达到事半功倍的效果。
JAVA 应用性能问题排查指南
问题分类
问题形形色色,各种各样的问题都会有。对其进行抽象和分类是非常必要的。这里将从两个维度来对性能问题进行分类。第一个维度是资源维度,第二个维度是频率维度。
资源维度类的问题:CPU 冲高,内存使用不当,网络过载。
频率维度类的问题:交易持续性缓慢,交易偶发性缓慢。
对于每一类问题都有相应的解决办法,方法或者工具使用不当,会导致不能快速而且精准地排查定位问题。
压测性能问题定位调优是一门需要多方面综合能力结合的一种技术工作,需要凭借个人的技术能力、经验、有时候还需要一些直觉和灵感,还需要一定的沟通能力,因为有时候问题并不是由定位问题的人发现的,所以需要通过不断地沟通来发现一些蛛丝马迹。涉及的技术知识面远不仅限于程序语言本身,还可能需要扎实的技术基本功,比如操作系统原理、网络、编译原理、JVM 等知识,决不只是简单的了解,而是真正的掌握,比如 TCP/IP,必须得深入掌握。JVM 得深入掌握内存组成,内存模型,深入掌握 GC 的一些算法等。这也是一些初中级技术人员在一遇到性能问题就傻眼,完全不知道如何从哪里下手。如果拥有扎实的技术基本功,再加上一些实战经验然后形成一套属于自己的打法,在遇到问题后才能心中不乱,快速拨开迷雾,最终找到问题的症结。
本文笔者还带来了实际工作中定位和排查出来的一些典型的性能问题的案例,每个案例都会介绍问题发生的相关背景,一线人员提供的问题现象和初步排查定位结论,且在笔者介入后看到的问题现象,再配合一些常用的问题定位工具,介绍发现和定位问题的整个过程,问题发生的根本原因等。
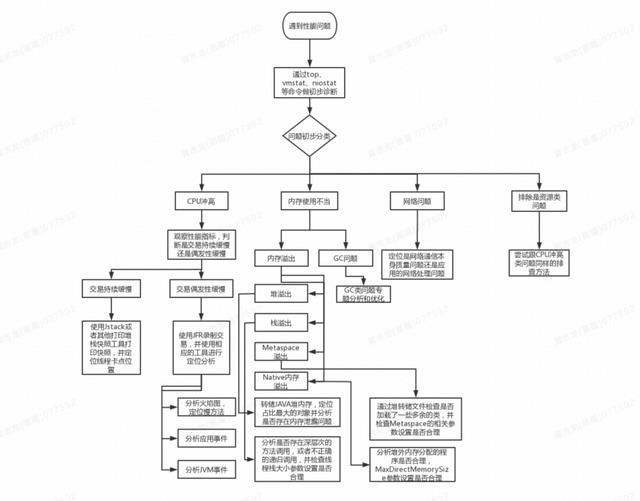
分析思路框架
遇到一个性能问题,首先要从各种表象和一些简单工具将问题进行定义和分类,然后再做进一步的定位分析,可以参考一下图 1 作者总结出来的一个决策图,这张图是笔者从近几个金融行业 ToB 项目中做性能定位调优过程的一个总结提练,不一定适合所有的问题,但至少覆盖到了近几个项目中遇到的性能问题的排查过程。在接下来的大篇幅中将对每一类问题进行展开,并附上一些真实的经典案例,这些案例都是真真实实发生的,有一定的代表性,且很多都是客户定位了很长时间都没发现问题根本原因的问题。其中 GC 类问题在此文不做过多分析,对于 GC 这一类问题后续有空写一篇专门的文章来进行展开。
内存溢出
内存溢出问题按照问题发生频率又可进一步分为堆内存溢出、栈内存溢出、Metaspace 内存溢出以及 Native 内存溢出,下面对每种溢出情况进行详细分析。
- 堆内存溢出
相信这类问题大家多多少少都接触过,问题发生的根本原因就是应用申请的堆内存超过了 Xmx 参数设置的值,进而导致 JVM 基本处于一个不可用的状态。如图 2 所示,示例代码模拟了堆内存溢出,运行时设置堆大小为 1MB,运行后结果如图3所示,抛出了一个 OutOfMemoryError 的错误异常,相应的 Message 是 Java heap space,代表溢出的部分是堆内存。
- 栈内存溢出
这类问题主要是由于方法调用深度太深,或者不正确的递归方法调用,又或者是 Xss 参数设置不当都会引发这个问题,如图 4 所示,一个简单的无限递归调用就会引发栈内存溢出,出错结果如图5所示,将会抛一个 StackOverflowError 的错误异常。Xss 参数可以设置每个线程栈内存最大大小,JDK8 的默认大小为 1MB,正常情况下一般不需要去修改该参数,如果遇到 StackOverflowError 的报错,那么就需要留意了,需要查证是程序的问题还是参数设置的问题,如果确实是方法调用深度很深,默认的 1MB 不够用,那么就需要调高 Xss 参数。
- Native内存溢出
这种溢出发生在 JVM 使用堆外内存时,且超过一个进程所支持的最大的内存上限,或者堆外内存超过 MaxDirectMemorySize 参数指定的值时即会引发 Native 内存溢出。如图 6 所示,需要配置 MaxDirectMemorySize 参数,如果不配置这个参数估计很难模拟出这个问题,作者的机器的 64 位的机器,堆外内存的大小可想而知了。运行该程序得到的运行结果如图 7 所示,抛出来的异常也是 OutOfMemoryError,这个跟堆内存异常类似,但是 Message 是 Direct buffer memory,这个跟堆内存溢出的 Message 是不一样的,请特别留意这条 Message,这对精准定位问题是非常重要的。
- Metaspace内存溢出
Metaspace 是在 JDK8 中才出现的,之前的版本中都叫 Perm 空间,大概用途都相差不大。模拟 Metaspace 溢出的方式很简单,如图 8 所示通过 cglib 不断动态创建类并加载到 JVM,这些类信息就是保存在 Metaspace 内存里面的,在这里为了快速模拟出问题,将 MaxMetaspaceSize 设置为 10MB。执行结果如图 9 所示,依然是抛出 OutOfMemoryError 的错误异常,但是 Message 变成了 Metaspace。
JVM 的内存溢出最常见的就这四种,如果能知道每一种内存溢出出现的原因,那么就能快速而精准地进行定位。下面对一些遇到的真实的经典案例进行分析。
- 案例:堆外内存溢出
这种问题也比较好查,前提是在堆内存发生溢出时必须自动转储堆内存到文件中,如果压测过程中通过 kill -3 或者 jmap 命令触发堆内存转储。然后通过一些堆内存分析工具比如 IBM 的 Heap Analyzer 等工具找出是哪种对象占用内存最多,最终可以把问题原因揪出来。
如果需要在发生 OOM 时自动转储堆内存,那么需要在启动参数中加入如下参数:
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/usr/local/oom
如果需要手工获取线程转储或者内存转储,那么请使用 kill -3 命令,或者使用 jstack 和 jmap 命令。
jstack -l pid > stackinfo,这条命令可以把线程信息转储到文本文件,把文件下载到本地然后用诸如 IBM Core file analyze 工具进行分析。
jmap -dump:format=b,file=./jmap.hprof pid,这条命令可以把堆内存信息到当前目录的 jmap.hprof 文件中,下载到本地,然后用诸如 IBM Heap Analyze 等堆内存分析工具进行分析,根据二八定律,找准最耗内存的对象就可以解决 80% 的问题。
图 10 就是一个真实发生的案例,该问题的发生现象是这样的,压测开始后,前十分钟一切正常,但是在经历大约十分钟后,TPS 逐渐下降,直到后面客户端的 TCP 连接都建不上去,客户一度认为是服务端Linux的网络栈的参数设置有问题,导致 TCP 无法建连,给出的证据是,服务端存在大量的 TIME_WAIT 状态的连接,然后要求调整Linux内核网络参数,减少 TIME_WAIT 状态的连接数。什么是 TIME_WAIT?在这个时候就不得不祭出祖传 TCP 状态机的那张图了,如图 11 所示。对照这个图就能知道 TIME_WAIT 的来胧去脉了,TIME_WAIT 主要出现在主动关闭连接方,当然了,如果双方刚好同时关闭连接的时候,那么双方都会出现 TIME_WAIT 状态。在进行关闭连接四路握手协议时,最后的 ACK 是由主动关闭端发出的,如果这个最终的 ACK 丢失,服务器将重发最终的 FIN,因此客户端必须维护状态信息以允许它重发最终的 ACK。如果不维持这个状态信息,那么客户端将响应 RST 分节,服务器将此分节解释成一个错误(在 java 中会抛出 connection reset的SocketException)。因而,要实现 TCP 全双工连接的正常终止,必须处理终止序列四个分节中任何一个分节的丢失情况,主动关闭的客户端必须维持状态信息进入 TIME_WAIT 状态。
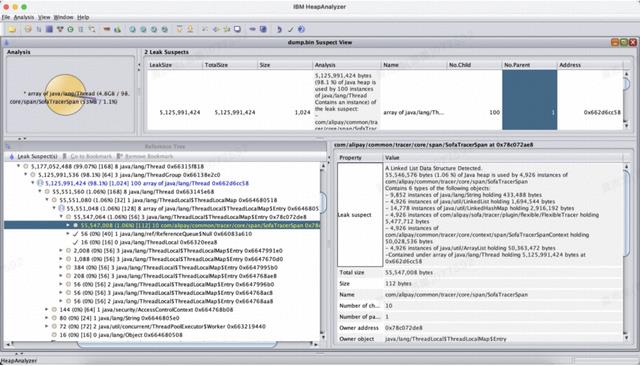
图 10 真实堆内存溢出案例一
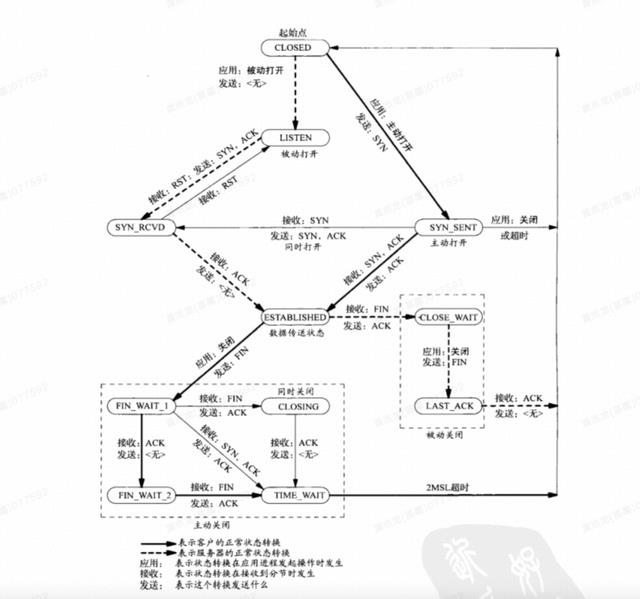
图 11 TCP 状态机
顺着客户提供的这些信息,查了一下压测客户端,采用的是 HTTP 协议,keep-alive 为开,而且采用的是连接池的方式与服务端进行交互,理论上在服务器端不应该出现如此之多的 TIME_WAIT 连接,猜测一种可能性是由于客户侧刚开始压测的时候 TPS 比较高,占用连接数多,后续性能下来后,连接数空闲且来不及跟服务端进行保活处理,导致连接被服务端给主动关闭掉了,但这也仅限于是猜测了。
为了更精准地定位问题,决定去一线现场看下情况,在 TPS 严重往下掉的时候,通过 top、vmstat 等命令进行初步探测,发现 cpu 占比并不十分高,大约 70% 左右。但是 JVM 占用的内存已经快接近 Xmx 参数配置的值了,然后用 jstat -gcutil -h10 pid 5s 100 命令看一下 GC 情况,不查不知道一查吓一跳,如图 12 所示,初看这就是一份不太正常的 GC 数据,首先老年代占比直逼 100%,然后 5 秒内居然进行了 7 次 FullGC,eden 区占比 100%,因为老年代已经满了,年轻代的 GC 都已经停滞了,这明显不正常,趁 JVM 还活着,赶紧执行 jmap -dump:format=b,file=./jmap.hprof pid,把整个堆文件快照拿下来,整整 5 个 G。取下来后通过 IBM 的 HeapAnalyzer 工具分析堆文件,结果如图 10 所示,经过一番查找,发现某个对象占比特别大,占比达 98%,继续追踪持有对象,最终定位出问题,申请了某个资源,但是一直没有释放,修改后问题得到完美解决,后续再经过长达 8 个小时的耐久性测,没能再发现问题,TPS 一直非常稳定。
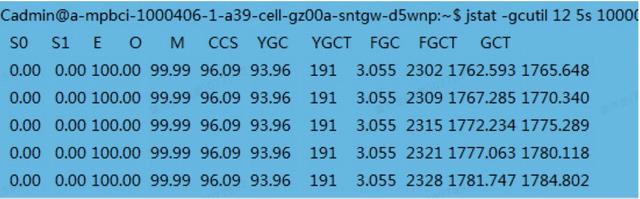
图 12 GC 情况统计分析
再来看看为何会出现那么多的 TIME_WAIT 连接,跟开始的猜测是一致的,由于大量的闲置连接被服务端主动关闭掉,所以才会出现那么多的 TIME_WAIT 状态的连接。
CPU高
- 案例
某金融银行客户在压测过程中发现一个问题,导致 TPS 极低,交易响应时长甚至接近惊人的 30S,严重不达票,服务响应时间如图 23 所示,这是应用打的 tracer log,显示的耗时很不乐观。应用采用 SOFA 构建,部署在专有云容器上面,容器规格为 4C8G,使用 OceanBase 数据库。交易缓慢过程中客户在相应容器里面用 top、vmstat 命令获取 OS 信息,发现内存使用正常,但是 CPU 接近 100%,通过 jstack 命令取线程转储文件,如图 22 所示,客户发现大量的线程都卡在了获取数据库连接上面,再上应用日志中也报了大量的获取 DB 连接失败的错误日志,这让客户以为是连接池中的连接数不够,所以不断继续加大 MaxActive 这个参数,DB 连接池使用的是 Druid,在加大参数后,性能没有任何改善,且获取不到连接的问题依旧。客户在排查该问题大概两周且没有任何实质性进展后,开始向阿里 GTS 的同学求助。
笔者刚好在客户现场,介入该性能问题的定位工作。跟客户一番沟通,并查阅了了历史定位信息记录后,根据以往的经验,这个问题肯定不是由于连接池中的最大连接数不够的原因导致的,因为这个时候客户已经把 MaxActive 的参数已经调到了恐怖的 500,但问题依旧,在图 22 中还能看到一些有用的信息,比如正在 Waiting 的线程高达 908 个,Runnable 的线程高达 295 个,都是很恐怖的数字,大量的线程处于 Runnable 状态,CPU 忙着进行线程上下文的切换,CPU 呼呼地转,但实际并没有干多少有实际有意义的事。后经询问,客户将 SOFA 的业务处理线程数调到了 1000,默认是 200。
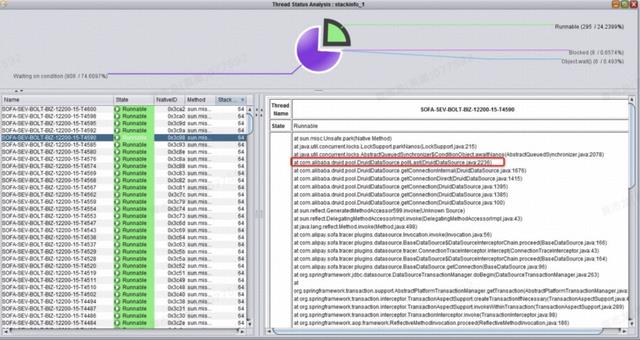
图 22 线程卡在获取 DB 连接池中的连接
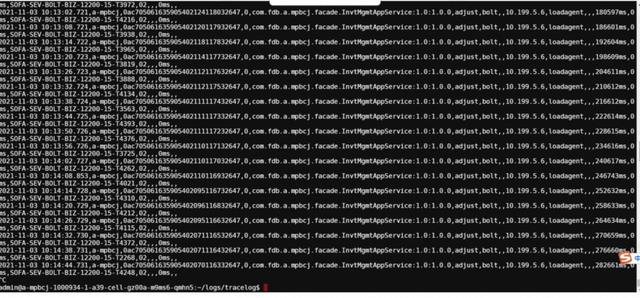
图 23 交易缓慢截图
查到这里基本可以断定客户陷入了“头痛医头,脚痛医脚”,“治标不治本”的窘境,进一步跟客户沟通后,果然如此。刚开始的时候,是由于 SOFA 报了线程池满的错误,然后客户不断加码 SOFA 业务线程池中最大线程数,最后加到了 1000,性能提升不明显,然后报了一个获取不到数据库连接的错误,客户又认为这是数据库连接不够了,调高 Druid 的 MaxActive 参数,最后无论怎么调性能也都上不来,甚至到后面把内存都快要压爆了,如图 24 所示,内存中被一些业务 DO 对象给填满了,后面客户一度以为存在内存泄露。对于这类问题,只要像是出现了数据库连接池不够用、或者从连接池中获取连接超时,又或者是线程池耗尽这类问题,只要参数设置是在合理的范围,那么十有八九就是交易本身处理太慢了。后面经过进一步的排查最终定位是某个 SQL 语句和内部的一些处理不当导致的交易缓慢。修正后,TPS 正常,最后把线程池最大大小参数、DB 连接池的参数都往回调成最佳实践中推荐的值,再次压测后,TPS 依然保持正常水平,问题得到最终解决。
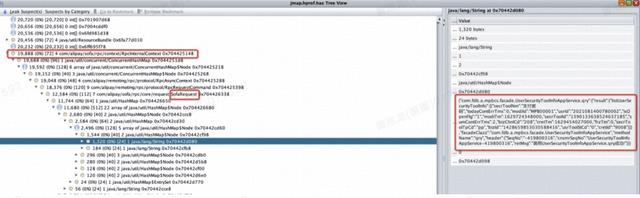
图 24 内存填满了业务领域对象
这个案例一虽说是因为 CPU 冲高且交易持续缓慢的这一类典型问题,但其实就这个案例所述的那样,在定位和调优的时候很容易陷进一种治标不治本的困境,很容易被一些表象所迷惑。如何拨开云雾见月明,笔者的看法是 5 分看经验,1 分看灵感和运气,还有 4 分得靠不断分析。如果没经验怎么办?那就只能沉下心来分析相关性能文件,无论是线程转储文件还是 JFR,又或者其他采集工具采集到性能信息,反正不要放过任何蛛丝马迹,最后实在没辙了再请求经验丰富的专家的协助排查解决。
- 使用 JMC+JFR 定位问题
如果超长问题偶然发生,这里介绍一个比较简单且非常实用的方法,使用 JMC+JFR,可以参考链接进行使用。但是使用前必须开启 JMX 和 JFR 特性,需要在启动修改启动参数,具体参数如下,该参数不要带入生产,另外如果将容器所属宿主机的端口也暴露成跟 jmxremote.port 一样的端口,如下示例为 32433,那么还可以使用 JConsole 或者 JVisualvm 工具实时观察虚拟机的状况,这里不再做详细介绍。
-Dcom.sun.management.jmxremote.port=32433
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.
authenticate=false
-XX:+UnlockCommercialFeatures -XX:+FlightRecorder
下面以一个实际的 JFR 实例为例。
首先要开启 JMX 和 JFR 功能,需要在启动参数中加 JMX 开启参数和 JFR 开启参数,如上面所述,然后在容器里面执行下述命令,执行后显示“Started recording pid. The result will be written to xxxx”,即表示已经开始录制,这个时候开始进行压测,下述命令中的 duration 是 90 秒,也就表示会录制 90S 后才会停止录制,录制完后将文件下载到本地,用 jmc 工具进行分析,如果没有这个工具,也可以使用 IDEA 进行分析。
jcmd pid JFR.start name=test duration=90s filename=output.jfr
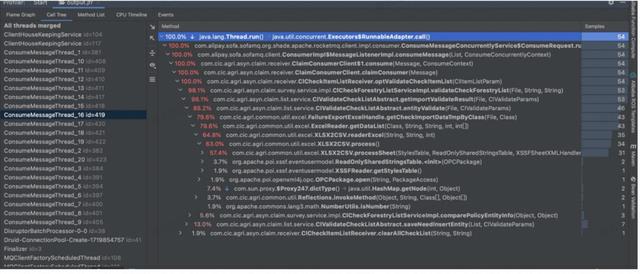
通过分析火焰图,具体怎么看火焰图请参考链接。通过这个图可以看到主要的耗时是在哪个方法上面,给我们分析问题提供了很大的便利。
还可以查看 call tree,也能看出耗时主要发生在哪里。
JMC 工具下载地址:JDK Mission Control (JMC) 8 Downloads (oracle.com)
最后再介绍一款工具,阿里巴巴开源的 arthas,也是性能分析和定位的一把利器,具体使用就不在这里介绍了,可以参考 arthas 官网。
- 如何定位 CPU 耗时过高的线程及方法
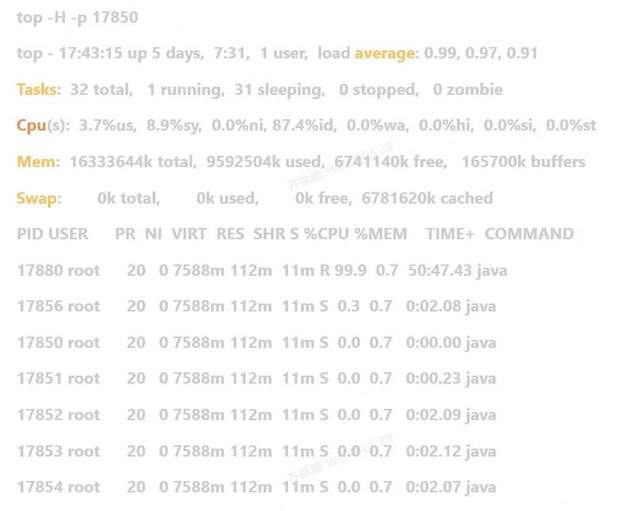
首先找到 JAVA 进程的 PID,然后执行 top -H -p pid,这样可以找到最耗时的线程,如下图所示。然后使用 printf "%x\\n" 17880,将线程号转成 16 进制,最终通过这个 16 进制值去 jstack 线程转储文件中去查找是哪个线程占用 CPU 最高。
其他问题案例
这类问题在发生的时候,JVM 表现得静如止水,CPU 和内存的使用都在正常水位,但是交易就是缓慢,对于这一类问题可以参考 CPU 冲高类问题来进行解决,通过使用线程转储文件或者使用JFR来录制一段 JVM 运行记录。这类问题大概率的原因是由于大部分线程卡在某个 IO 或者被某个锁个 Block 住了,下面也带来一个真实的案例。
- 案例一
某金融保险头部客户,反应某个交易非常缓慢,经常响应时间在 10S 以上,应用部署在公有云的容器上,容器规格为 2C4G,数据库是 OceanBase。问题每次都能重现,通过分布式链路工具只能定位到在某个服务上面慢,并不能精确定是卡在哪个方法上面。在交易缓慢期间,通过 top、vmstat 命令查看 OS 的状态,CPU 和内存资源都在正常水位。因此,需要看在交易期间的线程的状态。在交易执行缓慢期间,将交易的线程给转储出来,如图 29 所示,可以定位相应的线程卡在哪个方法上面,案例中的线程卡在了执行 socket 读数据阶段,从堆栈可以断定是卡在了读数据库上面了。如果这个方法依然不好用,那么还可以借助抓包方式来进行定位。
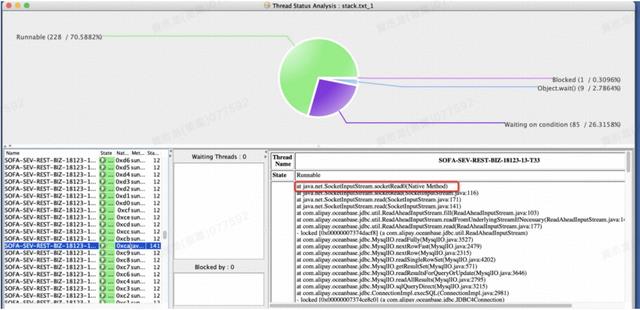
图 29 交易被 hang 住示例图
- 案例二
某金融银行客户压测过程中发现 TPS 上不去,10TPS 不到,响应时间更是高到令人发指,在经过一段时间的培训赋能和磨合,该客户已经具备些性能定位的能力。给反馈的信息是 SQL 执行时间、CPU 和内存使用一切正常,客户打了一份线程转储文件,发现大多数线程都卡在了使用 RedissionLock 的分布式锁上面,如图 30 所示,后经查是客户没有合理使用分布式锁导致的问题,解决后,TPS 翻了 20 倍。
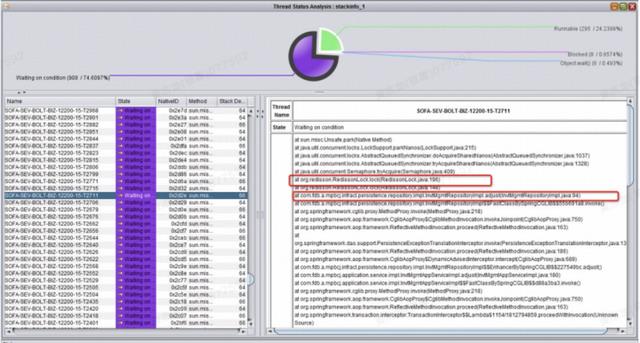
图 30 分布式锁使用不当导致的问题示例
这两个案例其实都不算复杂,也很容易进行排查,放到这里只是想重述一下排查这类问题的一个整体的思路和方法。如果交易缓慢且资源使用都正常,可以通过分析线程转储文件或者 JFR 文件来定位问题,这类问题一般是由于 IO 存在瓶颈,又或者被锁 Block 住的原因导致的。
总结
问题千千万,但只要修练了足够深厚的内功,形成一套属于自己的排查问题思路和打法,再加上一套支撑问题排查的工具,凭借已有的经验还有偶发到来的那一丝丝灵感,相信所有的问题都会迎刃而解。
作者:凡勇
本文为阿里云原创内容,未经允许不得转载。
以上是关于Java 应用压测性能问题定位经验分享的主要内容,如果未能解决你的问题,请参考以下文章