Spark 延迟30秒
Posted fansy1990
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark 延迟30秒相关的知识,希望对你有一定的参考价值。
Spark延迟30秒
Spark延迟30秒
问题引出:问题来源于一次小的测试,在进行一个常规的读取Hive数据,并使用Spakr MLlib中的Describe进行基本的表统计时,发现Executor的任务发起到任务实际执行相差30秒左右,故此引出本篇博客。
1. 环境/版本/测试代码
1.1 使用软件版本:
| 软件 | 版本 |
|---|---|
| Spark | 2.2.2 |
| Hadoop | 2.6.5 |
| Hive | 1.2.2 |
| JDK | 1.8 |
1.2 集群部署
| 机器 | 服务 |
|---|---|
| node200 | NameNode/Spark Master/Hive Metastore / Hive Server2/ResourceManager |
| node201~node203 | DataNode /Spark Worker/NodeManager |
1.3 测试代码
代码下载:https://github.com/fansy1990/spark222_test
测试使用下面的命令在node200终端执行:
spark-submit --class statics.DescribeStatics --deploy-mode cluster test_demo-1.0-SNAPSHOT.jar default.demo_30m default.demo_30_statics statics_30m_01
采用cluster模式提交,这样Driver程序也会在集群的一个节点上,而Executor会分别在另外两个子节点上。
2. 时间线
下面给出时间线
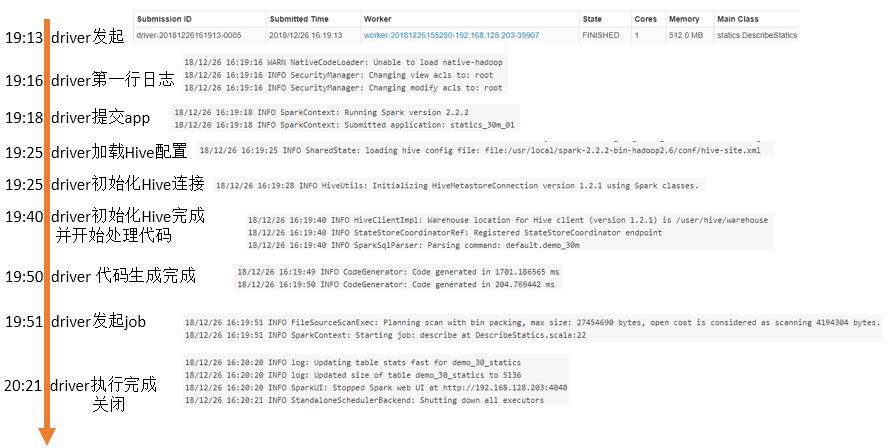
Driver时间线:
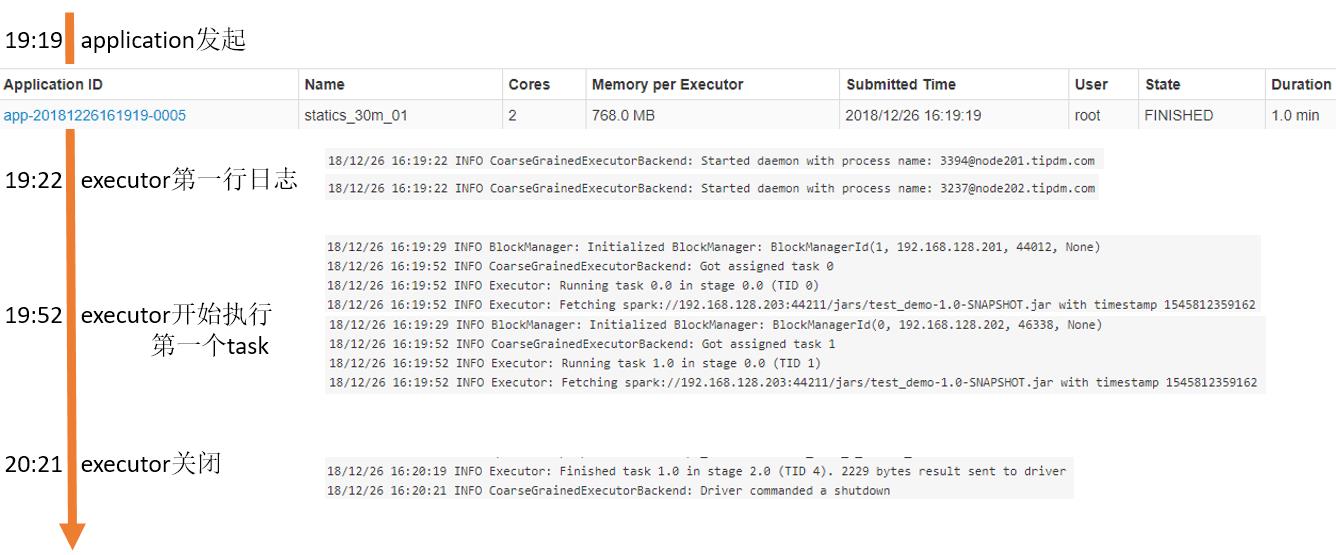
executor时间线:
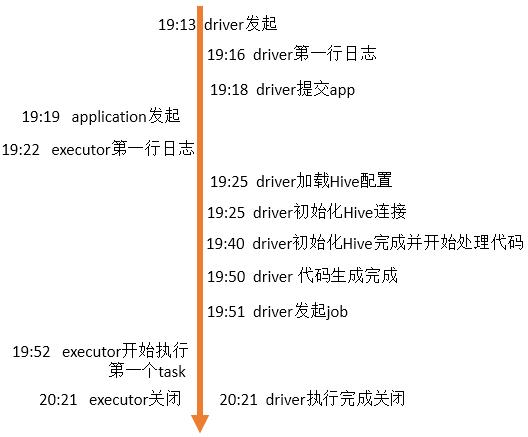
汇总时间线:
3. 问题重述及分析
问题重述:延迟30秒是指Executor从发起到实际执行间隔是30秒,从“executor时间线”图片中也可以看到时间间隔大概在33秒,而从Executor的日志是完全分析不出这33秒到底干了啥的(日志从29秒直接跳到52秒),这就是最初的疑问!
问题分析:而从“汇总时间线”图片中可以很清楚的看到在这段时间,主要是连接Hive以及生成代码。
问题引申:
- 从日志中可以看到其实,这30秒基本是在连接Hive的操作,那么很直观的问题:连接Hive需要这么多时间么?
- 实际应该是由Executor来执行读取连接Hive,为什么日志是在Driver程序中?难道是Driver程序读取Hive?
- 发起Driver到Driver提交Application耗时5秒,是否可以再快点?
关于问题的引申,后续会继续探讨!
具体日志如下:
18/12/26 16:19:25 INFO SharedState: loading hive config file: file:/usr/local/spark-2.2.2-bin-hadoop2.6/conf/hive-site.xml
18/12/26 16:19:25 INFO SharedState: spark.sql.warehouse.dir is not set, but hive.metastore.warehouse.dir is set. Setting spark.sql.warehouse.dir to the value of hive.metastore.warehouse.dir ('/user/hive/warehouse').
18/12/26 16:19:25 INFO SharedState: Warehouse path is '/user/hive/warehouse'.
18/12/26 16:19:28 INFO HiveUtils: Initializing HiveMetastoreConnection version 1.2.1 using Spark classes.
18/12/26 16:19:29 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (192.168.128.201:51932) with ID 1
18/12/26 16:19:29 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (192.168.128.202:41014) with ID 0
18/12/26 16:19:29 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.128.201:44012 with 265.5 MB RAM, BlockManagerId(1, 192.168.128.201, 44012, None)
18/12/26 16:19:29 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.128.202:46338 with 265.5 MB RAM, BlockManagerId(0, 192.168.128.202, 46338, None)
18/12/26 16:19:31 INFO HiveMetaStore: 0: Opening raw store with implemenation class:org.apache.hadoop.hive.metastore.ObjectStore
18/12/26 16:19:31 INFO ObjectStore: ObjectStore, initialize called
18/12/26 16:19:32 INFO Persistence: Property hive.metastore.integral.jdo.pushdown unknown - will be ignored
18/12/26 16:19:32 INFO Persistence: Property datanucleus.cache.level2 unknown - will be ignored
18/12/26 16:19:35 INFO ObjectStore: Setting MetaStore object pin classes with hive.metastore.cache.pinobjtypes="Table,StorageDescriptor,SerDeInfo,Partition,Database,Type,FieldSchema,Order"
18/12/26 16:19:37 INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MFieldSchema" is tagged as "embedded-only" so does not have its own datastore table.
18/12/26 16:19:37 INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MOrder" is tagged as "embedded-only" so does not have its own datastore table.
18/12/26 16:19:38 INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MFieldSchema" is tagged as "embedded-only" so does not have its own datastore table.
18/12/26 16:19:38 INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MOrder" is tagged as "embedded-only" so does not have its own datastore table.
18/12/26 16:19:38 INFO Query: Reading in results for query "org.datanucleus.store.rdbms.query.SQLQuery@0" since the connection used is closing
18/12/26 16:19:38 INFO MetaStoreDirectSql: Using direct SQL, underlying DB is mysql
18/12/26 16:19:38 INFO ObjectStore: Initialized ObjectStore
18/12/26 16:19:38 INFO HiveMetaStore: Added admin role in metastore
18/12/26 16:19:39 INFO HiveMetaStore: Added public role in metastore
18/12/26 16:19:39 INFO HiveMetaStore: No user is added in admin role, since config is empty
18/12/26 16:19:39 INFO HiveMetaStore: 0: get_all_databases
18/12/26 16:19:39 INFO audit: ugi=root ip=unknown-ip-addr cmd=get_all_databases
18/12/26 16:19:39 INFO HiveMetaStore: 0: get_functions: db=default pat=*
18/12/26 16:19:39 INFO audit: ugi=root ip=unknown-ip-addr cmd=get_functions: db=default pat=*
18/12/26 16:19:39 INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MResourceUri" is tagged as "embedded-only" so does not have its own datastore table.
18/12/26 16:19:39 INFO SessionState: Created local directory: /tmp/24153031-33ac-4728-b78f-5a50a06d36bc_resources
18/12/26 16:19:39 INFO SessionState: Created HDFS directory: /tmp/hive/root/24153031-33ac-4728-b78f-5a50a06d36bc
18/12/26 16:19:39 INFO SessionState: Created local directory: /tmp/root/24153031-33ac-4728-b78f-5a50a06d36bc
18/12/26 16:19:39 INFO SessionState: Created HDFS directory: /tmp/hive/root/24153031-33ac-4728-b78f-5a50a06d36bc/_tmp_space.db
18/12/26 16:19:39 INFO HiveClientImpl: Warehouse location for Hive client (version 1.2.1) is /user/hive/warehouse
18/12/26 16:19:39 INFO HiveMetaStore: 0: get_database: default
18/12/26 16:19:39 INFO audit: ugi=root ip=unknown-ip-addr cmd=get_database: default
18/12/26 16:19:39 INFO HiveMetaStore: 0: get_database: global_temp
18/12/26 16:19:39 INFO audit: ugi=root ip=unknown-ip-addr cmd=get_database: global_temp
18/12/26 16:19:39 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
18/12/26 16:19:40 INFO SessionState: Created local directory: /tmp/c81ba25a-de2a-4c34-a843-f8d632f4c682_resources
18/12/26 16:19:40 INFO SessionState: Created HDFS directory: /tmp/hive/root/c81ba25a-de2a-4c34-a843-f8d632f4c682
18/12/26 16:19:40 INFO SessionState: Created local directory: /tmp/root/c81ba25a-de2a-4c34-a843-f8d632f4c682
18/12/26 16:19:40 INFO SessionState: Created HDFS directory: /tmp/hive/root/c81ba25a-de2a-4c34-a843-f8d632f4c682/_tmp_space.db
18/12/26 16:19:40 INFO HiveClientImpl: Warehouse location for Hive client (version 1.2.1) is /user/hive/warehouse
18/12/26 16:19:40 INFO StateStoreCoordinatorRef: Registered StateStoreCoordinator endpoint
18/12/26 16:19:40 INFO SparkSqlParser: Parsing command: default.demo_30m
18/12/26 16:19:41 INFO HiveMetaStore: 0: get_database: default
18/12/26 16:19:41 INFO audit: ugi=root ip=unknown-ip-addr cmd=get_database: default
18/12/26 16:19:41 INFO HiveMetaStore: 0: get_table : db=default tbl=demo_30m
18/12/26 16:19:41 INFO audit: ugi=root ip=unknown-ip-addr cmd=get_table : db=default tbl=demo_30m
18/12/26 16:19:41 INFO HiveMetaStore: 0: get_table : db=default tbl=demo_30m
18/12/26 16:19:41 INFO audit: ugi=root ip=unknown-ip-addr cmd=get_table : db=default tbl=demo_30m
18/12/26 16:19:41 INFO CatalystSqlParser: Parsing command: string
18/12/26 16:19:41 INFO CatalystSqlParser: Parsing command: int
18/12/26 16:19:41 INFO CatalystSqlParser: Parsing command: string
18/12/26 16:19:41 INFO CatalystSqlParser: Parsing command: int
18/12/26 16:19:41 INFO CatalystSqlParser: Parsing command: double
18/12/26 16:19:41 INFO CatalystSqlParser: Parsing command: int
18/12/26 16:19:41 INFO CatalystSqlParser: Parsing command: int
18/12/26 16:19:41 INFO CatalystSqlParser: Parsing command: int
18/12/26 16:19:41 INFO CatalystSqlParser: Parsing command: double
18/12/26 16:19:41 INFO CatalystSqlParser: Parsing command: array<string>
18/12/26 16:19:47 INFO FileSourceStrategy: Pruning directories with:
18/12/26 16:19:47 INFO FileSourceStrategy: Post-Scan Filters:
18/12/26 16:19:47 INFO FileSourceStrategy: Output Data Schema: struct<FFP_DATE: string, AGE: int, LOAD_TIME: string, FLIGHT_COUNT: int, SUM_YR_1: double ... 7 more fields>
18/12/26 16:19:47 INFO FileSourceScanExec: Pushed Filters:
18/12/26 16:19:47 WARN Utils: Truncated the string representation of a plan since it was too large. This behavior can be adjusted by setting 'spark.debug.maxToStringFields' in SparkEnv.conf.
18/12/26 16:19:48 INFO ContextCleaner: Cleaned accumulator 0
18/12/26 16:19:49 INFO CodeGenerator: Code generated in 1701.186565 ms
18/12/26 16:19:50 INFO CodeGenerator: Code generated in 204.769442 ms
18/12/26 16:19:50 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 234.2 KB, free 116.7 MB)
18/12/26 16:19:50 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 23.3 KB, free 116.7 MB)
18/12/26 16:19:50 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.128.203:44515 (size: 23.3 KB, free: 116.9 MB)
18/12/26 16:19:50 INFO SparkContext: Created broadcast 0 from describe at DescribeStatics.scala:22
18/12/26 16:19:51 INFO FileSourceScanExec: Planning scan with bin packing, max size: 27454690 bytes, open cost is considered as scanning 4194304 bytes.
18/12/26 16:19:51 INFO SparkContext: Starting job: describe at DescribeStatics.scala:22
以上是关于Spark 延迟30秒的主要内容,如果未能解决你的问题,请参考以下文章