Kafka安装与简介
Posted Trigl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka安装与简介相关的知识,希望对你有一定的参考价值。
今天来讲一下Kafka,它是一个消息队列,应用场景比较广泛。刚开始学习一门东西,咱们先不管它是干什么的,先跑起来才是正经,所以本文主要讲两点:
- 安装搭建Kafka
- 简单介绍下Kafka的原理和应用
1. 安装Kafka
1.1 下载解压
下载地址:http://kafka.apache.org/downloads,如0.10.1.0版本的Kafka下载
wget http://apache.fayea.com/kafka/0.10.1.0/kafka_2.11-0.10.1.0.tgz
tar -xvf kafka_2.11-0.10.1.0.tgz
cd kafka_2.11-0.10.1.01.2 安装Zookeeper
Kafka需要Zookeeper的监控,所以先要安装Zookeeper,如何安装请传送至: hadoop、zookeeper、hbase、spark集群环境搭建 ,安装完成以后依次启动各个节点
1.3 配置kafka broker集群
我们的宗旨是面向实战,所以拒绝安装本地版本Kafka,来看一下Kafka集群的配置,也很简单
首先把Kafka解压后的目录复制到集群的各台服务器
然后修改各个服务器的配置文件:进入Kafka的config目录,修改server.properties
# brokerid就是指各台服务器对应的id,所以各台服务器值不同
broker.id=0
# 端口号,无需改变
port=9092
# 当前服务器的IP,各台服务器值不同
host.name=192.168.0.10
# Zookeeper集群的ip和端口号
zookeeper.connect=192.168.0.10:2181,192.168.0.11:2181,192.168.0.12:2181
# 日志目录
log.dirs=/home/www/kafka-logs1.4 启动Kafka
在每台服务器上进入Kafka目录,分别执行以下命令:
bin/kafka-server-start.sh config/server.properties &1.5 Kafka常用命令
1、新建一个主题
bin/kafka-topics.sh --create --zookeeper hxf:2181,cfg:2181,jqs:2181,jxf:2181,sxtb:2181 --replication-factor 2 --partitions 2 --topic testtest有两个复制因子和两个分区
2、查看新建的主题
bin/kafka-topics.sh --describe --zookeeper hxf:2181,cfg:2181,jqs:2181,jxf:2181,sxtb:2181 --topic test
其中第一行是所有分区的信息,下面的每一行对应一个分区
Leader:负责某个分区所有读写操作的节点
Replicas:复制因子节点
Isr:存活节点
3、查看Kafka所有的主题
bin/kafka-topics.sh --list --zookeeper hxf:2181,cfg:2181,jqs:2181,jxf:2181,sxtb:2181
4、在终端发送消息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
5、在终端接收(消费)消息
bin/kafka-console-consumer.sh --zookeeper hxf:2181,cfg:2181,jqs:2181,jxf:2181,sxtb:2181 --bootstrap-server localhost:9092 --topic test --from-beginning
2. Kafka简介
讲完实战让我们稍微了解一下Kafka的一些基本入门知识
2.1 基本术语
消息
先不管其他的,我们使用Kafka这个消息系统肯定是先关注消息这个概念,在Kafka中,每一个消息由键、值和一个时间戳组成
主题和日志
然后研究一下Kafka提供的核心概念——主题
Kafka集群存储同一类别的消息流称为主题
主题会有多个订阅者(0个1个或多个),当主题发布消息时,会向订阅者推送记录
针对每一个主题,Kafka集群维护了一个像下面这样的分区日志:
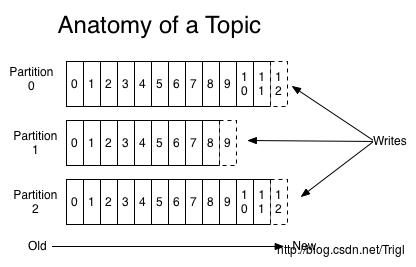
这些分区位于不同的服务器上,每一个分区可以看做是一个结构化的提交日志,每写入一条记录都会记录到其中一个分区并且分配一个唯一地标识其位置的数字称为偏移量offset
Kafka集群会将发布的消息保存一段时间,不管是否被消费。例如,如果设置保存天数为2天,那么从消息发布起的两天之内,该消息一直可以被消费,但是超过两天后就会被丢弃以节省空间。其次,Kafka的数据持久化性能很好,所以长时间存储数据不是问题
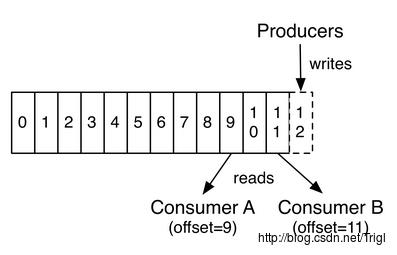
如下图所示,生产者每发布一条消息就会向分区log写入一条记录的offset,而消费者就是通过offset来读取对应的消息的,一般来说每读取一条消息,消费者对应要读取的offset就加1,例如最后一条读到offset=12,那么下条offset就为13.由于消费者通过offset来读取消息,所以可以重复读取已经读过的记录,或者跳过某些记录不读
Kafka中采用分区的设计有几个目的。一是可以处理更多的消息,不受单台服务器的限制。Topic拥有多个分区意味着它可以不受限的处理更多的数据。第二,分区可以作为并行处理的单元,稍后会谈到这一点
分布式
Log的分区被分布到集群中的多个服务器上。每个服务器处理它分到的分区。 根据配置每个分区还可以复制到其它服务器作为备份容错
每个分区有一个leader,零或多个follower。Leader处理此分区的所有的读写请求,而follower被动的复制数据。如果leader宕机,其它的一个follower会被推举为新的leader。 一台服务器可能同时是一个分区的leader,另一个分区的follower。 这样可以平衡负载,避免所有的请求都只让一台或者某几台服务器处理
生产者
生产者往某个Topic上发布消息。生产者还可以选择将消息分配到Topic的哪个节点上。最简单的方式是轮询分配到各个分区以平衡负载,也可以根据某种算法依照权重选择分区
消费者
Kafka有一个消费者组的概念,生产者把消息发到的是消费者组,在消费者组里面可以有很多个消费者实例,如下图所示:

Kafka集群有两台服务器,四个分区,此外有两个消费者组A和B,消费者组A具有2个消费者实例C1-2,消费者B具有4个消费者实例C3-6
那么Kafka发送消息的过程是怎样的呢?
例如此时我们创建了一个主题test,有两个分区,分别是Server1的P0和Server2的P1,假设此时我们通过test发布了一条消息,那么这条消息是发到P0还是P1呢,或者是都发呢?答案是只会发到P0或P1其中之一,也就是消息只会发给其中的一个分区
分区接收到消息后会记录在分区日志中,记录的方式我们讲过了,就是通过offset,正因为有这个偏移量的存在,所以一个分区内的消息是有先后顺序的,即offset大的消息比offset小的消息后到。但是注意,由于消息随机发往主题的任意一个分区,因此虽然同一个分区的消息有先后顺序,但是不同分区之间的消息就没有先后顺序了,那么如果我们要求消费者顺序消费主题发的消息那该怎么办呢,此时只要在创建主题的时候只提供一个分区即可
讲完了主题发消息,接下来就该消费者消费消息了,假设上面test的消息发给了分区P0,此时从图中可以看到,有两个消费者组,那么P0将会把消息发到哪个消费者组呢?从图中可以看到,P0把消息既发给了消费者组A也发给了B,但是A中消息仅被C1消费,B中消息仅被C3消费。这就是我们要讲的,主题发出的消息会发往所有的消费者组,而每一个消费者组下面可以有很多消费者实例,这条消息只会被他们中的一个消费掉
2.2 核心API
Kafka具有4个核心API:
- Producer API:用于向Kafka主题发送消息。
- Consumer API:用于从订阅主题接收消息并且处理这些消息。
- Streams API:作为一个流处理器,用于从一个或者多个主题中消费消息流然后为其他主题生产消息流,高效地将输入流转换为输出流。
- Connector API:用于构建和运行将Kafka主题和已有应用或者数据系统连接起来的可复用的生产者或消费者。例如一个主题到一个关系型数据库的连接能够捕获表的任意变化。
2.3 Kafka的应用场景
Kafka用作消息系统
Kafka流的概念与传统企业消息系统有什么异同?
传统消息系统有两个模型:队列和发布-订阅系统。在队列模式中,每条服务器的消息会被消费者池中的一个所读取;而发布-订阅系统中消息会广播给所有的消费者。这两种模式各有优劣。队列模式的优势是可以将消息数据让多个消费者处理以实现程序的可扩展,然而这就导致其没有多个订阅者,只能用于一个进程。发布-订阅模式的好处在于数据可以被多个进程消费使用,但是却无法使单一程序扩展性能
Kafka中消费者组的概念同时涵盖了这两方面。对应于队列的概念,Kafka中每个消费者组中有多个消费者实例可以接收消息;对应于发布-订阅模式,Kafka中可以指定多个消费者组来订阅消息
相对传统消息系统,Kafka可以提供更强的顺序保证
Kafka用作存储系统
任何发布消息与消费消息解耦的消息队列其实都可以看做是用来存放发布的消息的存储系统,而Kafka是一个非常高效的存储系统
写入Kafka的数据会被存入磁盘并且复制到集群中以容错。Kafka允许生产者等待数据完全复制并且确保持久化到磁盘的确认应答
Kafka使用的磁盘结构扩容性能很好——不管服务器上有50KB还是50TB,Kafka的表现都是一样的
由于能够精致的存储并且供客户端程序进行读操作,你可以把Kafka看做是一个用于高性能、低延迟的存储提交日志、复制及传播的分布式文件系统
Kafka的流处理
仅仅读、写、存储流数据是不够的,Kafka的目的是实现实时流处理。
在Kafka中一个流处理器的处理流程是首先持续性的从输入主题中获取数据流,然后对其进行一些处理,再持续性地向输出主题中生产数据流。例如一个销售商应用,接收销售和发货量的输入流,输出新订单和调整后价格的输出流
可以直接使用producer和consumer API进行简单的处理。对于复杂的转换,Kafka提供了更强大的Streams API。可构建聚合计算或连接流到一起的复杂应用程序
流处理有助于解决这类应用面临的硬性问题:处理无序数据、代码更改的再处理、执行状态计算等
Streams API所依托的都是Kafka的核心内容:使用producer和consumer API作为输入,使用Kafka作为状态存储,在流处理实例上使用相同的组机制来实现容错
Refer
http://www.cnblogs.com/davidwang456/p/4238536.html
以上是关于Kafka安装与简介的主要内容,如果未能解决你的问题,请参考以下文章