一文速学-Pandas中DataFrame转换为时间格式数据与处理
Posted fanstuck
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文速学-Pandas中DataFrame转换为时间格式数据与处理相关的知识,希望对你有一定的参考价值。
前言
由于在Pandas中经常要处理到时间序列数据,需要把一些object或者是字符、整型等某列进行转换为pandas可识别的datetime时间类型数据,方便时间的运算等操作。正好原来有篇文章特别是讲述
一文速学-Pandas处理时间序列数据操作详解。这篇文章忽略掉了如何转换为时间序列数据,正好补上,这样就实现的Pandas处理时间数据的全部内容和方法了。大家如果经常要使用到pandas dataframe处理时间数据不妨将两篇文章细读收藏,可以解决绝大多数处理时间序列的问题。有任何疑惑或者是问题可随时在评论区提出,博主会长期维护博文正确性,望大家指正,不吝赐教。
目录
一、Time Series / Date functionality
一、Time Series / Date functionality
首先要了解转换机制我们才能更好的明白转换原理。在Pandas中时间数据类型依赖于两种类型:一种是Numpy的datetime64类型,另一种是timedelta64。前者代表为时间数据,可以有各类时间表达方法,后者为时间量表示数据,可以为时间差值。
在处理时间序列数据时,我们会经常寻求:
- 生成固定平率日期和时间跨度的序列
- 各类数据转换为时间类型数据,且格式指定为需求的格式
- 将时间序列频率需求
对于创建和转换时间序列,官方给出了相对应的函数列表
| 类型 | 说明 | 创建函数 |
| Timestamp | 表示为单个时间戳 | to_datetime,Timestamp |
| DatetimeIndex | 表示时间维度数据 | to_datetime、date_range、bdate_range、DatetimeIndex |
| Period | 表示单个时间跨度 | Period |
| PeriodIndex | 指数Period | period_range,PeriodInex |
1.创建日期范围
rng = pd.date_range('6/14/2022', periods=3, freq='H')periods为指定的时间次数,freq为时间变化频时。
DatetimeIndex(['2011-01-01 00:00:00', '2011-01-01 01:00:00',
'2011-01-01 02:00:00'],
dtype='datetime64[ns]', freq='H')
rng = pd.date_range('1/1/2011', periods=5, freq='d')DatetimeIndex(['2011-01-01', '2011-01-02', '2011-01-03', '2011-01-04',
'2011-01-05'],
dtype='datetime64[ns]', freq='D')
2.频率截至
通过使用asfreq改变频率函数设定每次频率改变可以设定每个时间片都对应一个值:
rng = pd.date_range('1/1/2011', periods=2, freq='d')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
converted = ts.asfreq('360Min', method='pad')2011-01-01 00:00:00 2.397753 2011-01-01 06:00:00 2.397753 2011-01-01 12:00:00 2.397753 2011-01-01 18:00:00 2.397753 2011-01-02 00:00:00 1.489299 Freq: 360T, dtype: float64
将系列重新采样为每日频率resample:
rng = pd.date_range('1/1/2011', periods=5, freq='H')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
ts.resample('D').mean()2011-01-01 -0.245825 Freq: D, dtype: float64
3.Series数据类型转换
我们知道单个的DataFrame的一列数据其实提出来就是一个Series:
df=pd.DataFrame('name':['Tom','Stark'],
'sex':['男','女']
)
print(type(df['name']))<class 'pandas.core.series.Series'>
而to_datetime函数使用对象就是Series函数,因此在Pandas 中需要大量用到to_datetime函数,该函数我将会专门写一文来具体说明此函数和参数的全部用法。现作简单使用即可:
我们拿一个dataframe来展示:
df_csv.dtypescollect_date object cid int64 sid_sum int64 lg_track_traffic int64 lg_track_len float64 avg_day_sid_num int64 avg_day_track_len int64 dtype: object

我们想要把这一列object64类型数据转换为datetime数据类型,就可以使用to_dataframe函数了:
df_csv['collect_date']=pd.to_datetime(df_csv['collect_date'],format="%Y-%m-%d")
df_csv.dtypescollect_date datetime64[ns] cid int64 sid_sum int64 lg_track_traffic int64 lg_track_len float64 avg_day_sid_num int64 avg_day_track_len int64 dtype: object
若以日期开头可以通过传递dayfirst标识 :
pd.to_datetime(['14-01-2012', '01-14-2012'], dayfirst=True)DatetimeIndex(['2012-01-14', '2012-01-14'], dtype='datetime64[ns]', freq=None)
其他int64等类型都可以通过该方法进行转换,但是如果想要把这列数据转换为想要的format格式的类型,就得使用datetime库了,该库不能直接对Series使用。需要把列元素单独拿出来再转换:
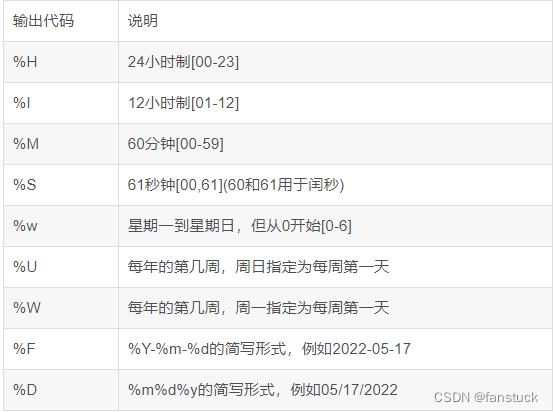
df_csv['collect_date']=df_csv['collect_date'].apply(lambda x: datetime.datetime.strftime(x,"%Y%m%d")) 
strftime可以将x传入的参数转换为想要的格式,此函数上篇文章已讲过,这里不在重复。
二、时间戳与时间跨度
1.时间格式引用
import pandas as pd
import datetime
pd.Timestamp(datetime.datetime(2022,6,14))时间戳数据是将值与时间点相关联的最基本类型的时间序列数据。对于 pandas 对象,这意味着使用时间点。
Timestamp('2022-06-14 00:00:00')
pd.Timestamp('2022-06-14')Timestamp('2022-06-14 00:00:00')
pd.Timestamp(2022,6,14)Timestamp('2022-06-14 00:00:00')
但是,在许多情况下,将诸如更改变量之类的事物与时间跨度相关联更为自然。表示的跨度Period可以显式指定,也可以从日期时间字符串格式推断。
pd.Period('2022-06-14 10:46')Period('2022-06-14 10:46', 'T')
pd.Period('2022-06-14')Period('2022-06-14', 'D')
pd.Period('2022-06-14',freq='M')Period('2022-06', 'M')
Period和Timestamp都可以作为index索引。Timestamp和的列表 Period被自动强制转换为DatetimeIndex 和PeriodIndex。
在底层,pandas 使用 的实例表示时间戳,Timestamp使用 DatetimeIndex. 对于常规时间跨度,pandas 将Period对象用于标量值和PeriodIndex跨度序列。
2.生成时间戳范围
在生成带有时间戳的索引,可以使用DatetimeIndex和Index构造函数并传入日期时间对象列表:
dates = [datetime(2022, 6, 10), datetime(2022, 6, 11), datetime(2022, 6, 12)]
index = pd.DatetimeIndex(dates)DatetimeIndex(['2022-06-10', '2022-06-11', '2022-06-12'], dtype='datetime64[ns]', freq=None)
index = pd.Index(dates)DatetimeIndex(['2022-06-10', '2022-06-11', '2022-06-12'], dtype='datetime64[ns]', freq=None)
但是这确实挺麻烦的需要一个一个输入时间戳数据。如果有固定的频率需求的时间戳,可以使用date_range()和bdate_range()函数来创建一个DatetimeIndex。默认频率为date_range的日,而默认频率bdate_range为工作日:
start=datetime(2022,6,10)
end=datetime(2022,6,14)
index=pd.date_range(start,end)DatetimeIndex(['2022-06-10', '2022-06-11', '2022-06-12', '2022-06-13',
'2022-06-14'],
dtype='datetime64[ns]', freq='D')
index = pd.bdate_range(start, end)DatetimeIndex(['2022-06-10', '2022-06-13', '2022-06-14'], dtype='datetime64[ns]', freq='B')
而6月11和6月12日正好为休息日故不显示。
当然也可以通过指定相应的频率实现到最终的日期:
pd.date_range(start, periods=5, freq='M')DatetimeIndex(['2022-06-30', '2022-07-31', '2022-08-31', '2022-09-30',
'2022-10-31'],
dtype='datetime64[ns]', freq='M')
参数 freq
数据格式 string 或 DateOffset,默认值是 'D',表示以自然日为单位。这个参数用来指定计时频率,比如 '5H' 表示每隔 5 个小时计算一次。
一些串别名被赋予有用的常见时间序列频率。我们将把这些别名称为偏移别名。
B 工作日频率
D 日历日频率
W 每周频率
W-SUN 星期天为起始(Sundays). 等同 ‘W’
W-MON 星期一为起始(Mondays)
W-TUE 星期二为起始(Tuesdays)
W-WED 星期三为起始(Wednesdays)
W-THU 星期四为起始(Thursdays)
W-FRI 星期五为起始(Fridays)
W-SAT 星期六为起始(Saturdays)
WOM 每月的第几周的第几天BH 工作小时级频率
H 小时级频率
T,min 分钟级频率
S 秒级频率
L,ms 毫秒
U,us 微秒
N 纳秒M 月结束频率,如'2018-11-30', '2018-12-31'
SM 半月结束频率(15日和月末)
BM 工作月结束频率
MS 月起始频率,如'2018-12-01'
SMS 短信半月开始频率(第1和第15)
BMS 工作月份开始频率Q 季末频率
BQ 工作季度结束频率
QS 季度开始频率
BQS 工作季度开始频率A,Y 年结束频率,如'2000-12-31'
A-DEC 年级别的频率,以 十二月(December) 为年底,等同 'A'。
A-JAN 年级别的频率,以 一月(January )为年底。(其他二到十一月:FEB、MAR、APR、MAY、JUN、JUL、AUG、SEP、OCT、NOV)
BA,BY 工作年度结束频率
AS,YS 年开始频率
BAS,BYS 工作年度开始频率更多:
https://pandas.pydata.org/pandas-docs/stable/user_guide/timeseries.html#timeseries-offset-aliases
这篇先讲到这里,接下来会有两篇重点解释to_datetime()函数和date_range、bdate_range函数。
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见
以上是关于一文速学-Pandas中DataFrame转换为时间格式数据与处理的主要内容,如果未能解决你的问题,请参考以下文章