分布式协调服务框架——Zookeeper的基本使⽤
Posted 小企鹅推雪球!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式协调服务框架——Zookeeper的基本使⽤相关的知识,希望对你有一定的参考价值。
文章目录
ZooKeeper命令⾏操作
-
进⼊到zookeeper的bin⽬录之后,通过zkClient进⼊zookeeper客户端命令⾏
./zkcli.sh 连接本地的zookeeper服务器 ./zkCli.sh -server ip:port(2181) 连接指定的服务器 -
连接成功之后,系统会输出Zookeeper的相关环境及配置信息等信息。输⼊help之后,屏幕会输出可⽤的Zookeeper命令。
ZooKeeper创建节点
-
使⽤create命令,可以创建⼀个Zookeeper节点
create [-s][-e] path data 其中,-s或-e分别指定节点特性,顺序或临时节点,若不指定,则创建持久节点 -
创建顺序节点:使⽤
create -s /zk-test 123命令创建zk-test顺序节点[zk: localhost:2181(CONNECTED) 4] create -s /zk-test 123 Created /zk-test0000000000- 执⾏完后,就在根节点下创建了⼀个叫做/zk-test的节点,该节点内容就是123,同时创建的zk-test节点后⾯添加了⼀串数字以示区别
-
创建临时节点:使⽤ create -e /zk-temp 123 命令创建zk-temp临时节点
[zk: localhost:2181(CONNECTED) 1] create -e /zk-temp 123 Created /zk-temp [zk: localhost:2181(CONNECTED) 2] ls / [zk-test0000000000, zookeeper, zk-temp]- 临时节点在客户端会话结束后,就会⾃动删除,下⾯使⽤quit命令退出客户端,再次查看,临时节点被删除
-
创建永久节点:使⽤ create /zk-permanent 123 命令创建zk-permanent永久节点 ,可以看到永久节点不同于顺序节点,不会⾃动在后⾯添加⼀串数字
[zk: localhost:2181(CONNECTED) 1] create /zk-permanent 123 Created /zk-permanent [zk: localhost:2181(CONNECTED) 2] ls / [zk-permanent, zk-test0000000000, zookeeper]
ZooKeeper读取节点
-
与读取相关的命令有ls 命令和get 命令
-
ls命令可以列出Zookeeper指定节点下的所有⼦节点,但只能查看指定节点下的第⼀级的所有⼦节点;
ls path 其中,path表示的是指定数据节点的节点路径 -
get命令可以获取Zookeeper指定节点的数据内容和属性信息
get path -
若获取根节点下⾯的所有⼦节点,使⽤ls / 命令即可
[zk: localhost:2181(CONNECTED) 2] ls / [zk-permanent, zk-test0000000000, zookeeper] -
若想获取/zk-permanent的数据内容和属性,可使⽤命令:
get /zk-permanent[zk: localhost:2181(CONNECTED) 3] get /zk-permanent 123 cZxid = 0x300000008 ctime = Thu Jul 16 04:33:41 EDT 2020 mZxid = 0x300000008 mtime = Thu Jul 16 04:33:41 EDT 2020 pZxid = 0x300000008 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 3 numChildren = 0- 第⼀⾏是节点/zk-permanent 的数据内容,其他⼏⾏则是创建该节点的事务ID(cZxid)、最后⼀次更新该节点的事务ID(mZxid)和最后⼀次更新该节点的时间(mtime)等属性信息
ZooKeeper更新节点
-
使⽤set命令,可以更新指定节点的数据内容,如将/zk-permanent节点的数据更新为456,
[zk: localhost:2181(CONNECTED) 4] set /zk-permanent 456 cZxid = 0x300000008 ctime = Thu Jul 16 04:33:41 EDT 2020 mZxid = 0x300000009 mtime = Thu Jul 16 05:07:00 EDT 2020 pZxid = 0x300000008 cversion = 0 dataVersion = 1 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 3 numChildren = 0- data就是要更新的新内容,version表示数据版本,
- 在zookeeper中,节点的数据是有版本概念的,这个参数⽤于指定本次更新操作是基于Znode的哪⼀个数据版本进⾏的
- 现在dataVersion已经变为1了,表示进⾏了更新
ZooKeeper删除节点
-
使⽤delete命令可以删除Zookeeper上的指定节点,使⽤delete /zk-permanent 命令即可删除/zk-permanent节点
[zk: localhost:2181(CONNECTED) 8] delete /zk-permanent [zk: localhost:2181(CONNECTED) 9] ls / [zk-test0000000000, zookeeper -
已经成功删除/zk-permanent节点。
-
注意,若删除节点存在⼦节点,那么⽆法删除该节点,必须先删除⼦节点,再删除⽗节点
Zookeeper ——Leader选举
- Leader选举机制
- 半数机制:集群中半数以上机器存活,集群可⽤。所以Zookeeper适合安装奇数台服务器
- Zookeeper虽然在配置⽂件中并没有指定Master和Slave。但是,Zookeeper⼯作时,是有⼀个节点为Leader,其它为Follower,Leader是通过内部的选举机制产⽣的。
- 假设有五台服务器组成的Zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这⼀点上,都是⼀样的。假设这些服务器依序启动

- Zookeeper的选举机制流程:
- 服务器1启动,此时只有它⼀台服务器启动了,它发出去的报⽂没有任何响应,所以它的选举状态⼀直是LOOKING状态
- 服务器2启动,它与最开始启动的服务器1进⾏通信,互相交换⾃⼰的选举结果,由于两者都没有历史数据,所以id值较⼤的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例⼦中的半数以上是3),所以服务器1、2还是继续保持LOOKING状态。
- 服务器3启动,根据前⾯的理论分析,服务器3成为服务器1、2、3中的⽼⼤,⽽与上⾯不同的是,此时有三台服务器选举了它,所以它成为了这次选举的Leader。
- 服务器4启动,根据前⾯的分析,理论上服务器4应该是服务器1、2、3、4中最⼤的,但是由于前⾯已经有半数以上的服务器选举了服务器3
- 服务器5启动,同服务器4⼀样称为follower。
Zookeeper 分布式数据⼀致性问题
- 为什么会出现分布式数据⼀致性问题?
- 分布式可以解决的问题:将数据复制到分布式部署的多台机器中,可以消除单点故障,防⽌系统由于某台(些)机器宕机导致的不可⽤。
- 分布式可以解决的问题:通过负载均衡技术,能够让分布在不同地⽅的数据副本全都对外提供服务。有效提⾼系统性能。
- 分布式导致的问题:在分布式系统中引⼊数据复制机制后,多台数据节点之间由于⽹络等原因很容易产⽣数据不⼀致的情况
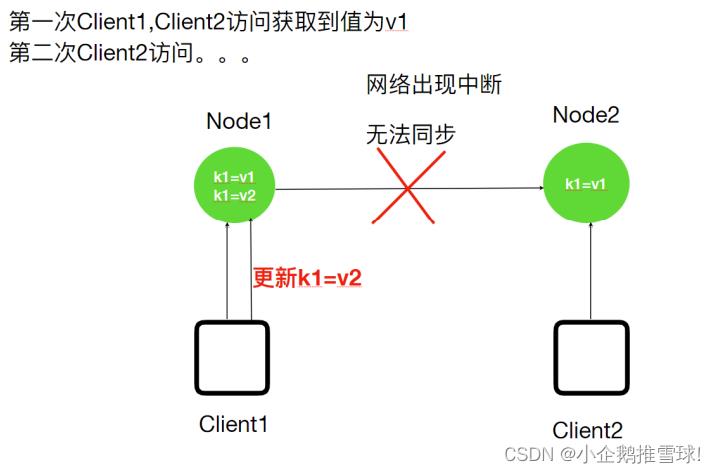
- 当客户端Client1将系统中的⼀个值K1由V1更新为V2,但是客户端Client2读取的是⼀个还没有同步更新的副本,K1的值依然是V1,这就导致了数据的不⼀致性。其中,常⻅的就是主从数据库之间的复制延时问题。
Zookeeper ZAB协议
- ZAB 协议是为分布式协调服务 Zookeeper 专⻔设计的⼀种⽀持崩溃恢复和原⼦⼴播协议。
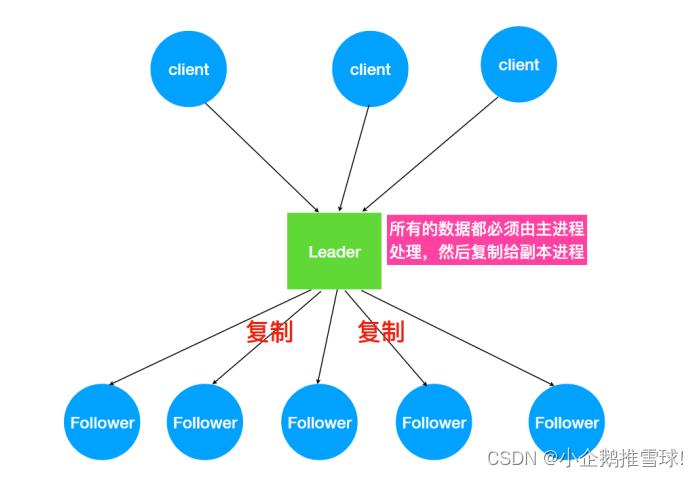
- Zookeeper 怎么处理集群中的数据?
- 所有客户端写⼊数据都是写⼊Leader中,然后,由 Leader 复制到Follower中。
- ZAB会将服务器数据的状态变更以事务Proposal的形式⼴播到所有的副本进程上。
- ZAB协议能够保证了事务操作的⼀个全局的变更序号(ZXID)。
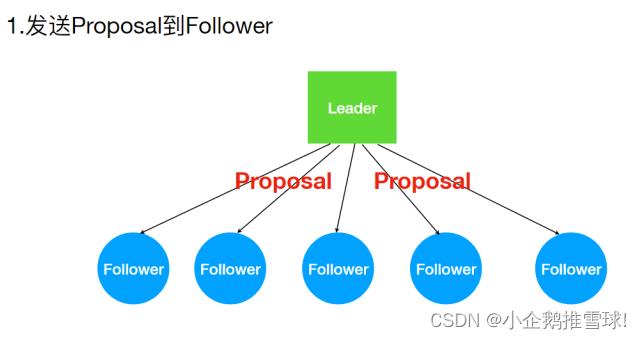
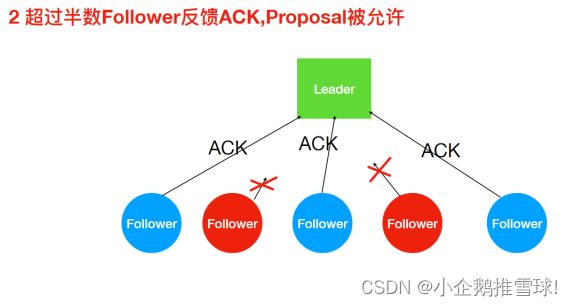
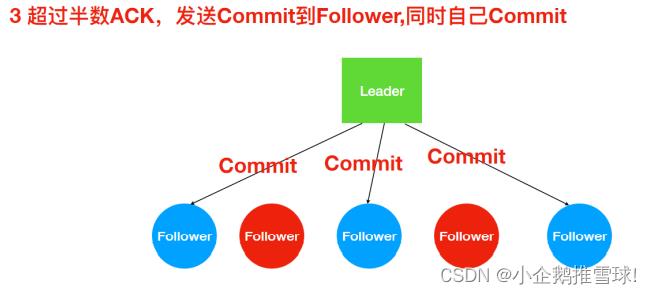
- ZAB 协议的消息⼴播过程类似于 ⼆阶段提交过程。对于客户端发送的写请求,全部由 Leader 接收,eader 将请求封装成⼀个事务 Proposal(提议),将其发送给所有 Follwer ,如果收到超过半数反馈ACK,则执⾏ Commit 操作(先提交⾃⼰,再发送 Commit 给所有 Follwer)
-
发送Proposal到Follower
-
Leader接收Follower的ACK
-
超过半数ACK则Commit,不能正常反馈Follower恢复正常后会进⼊数据同步阶段最终与Leader保持⼀致!
-
Leader 崩溃问题
- Leader宕机后,ZK集群⽆法正常⼯作,ZAB协议提供了⼀个⾼效且可靠的leader选举算法
- Leader宕机后,被选举的新Leader需要解决的问题
- ZAB 协议确保那些已经在 Leader 提交的事务最终会被所有服务器提交。
- ZAB 协议确保丢弃那些只在 Leader 提出/复制,但没有提交的事务。
- ZAB协议设计了⼀个选举算法:能够确保已经被Leader提交的事务被集群接受,丢弃还没有提交的事务。这个选举算法的关键点:保证选举出的新Leader拥有集群中所有节点最⼤编号(ZXID)的事务!!
ZooKeeper 特性
- ZooKeeper是⼀个典型的发布/订阅模式的分布式数据管理与协调框架,可以使⽤它来进⾏分布式数据的发布与订阅。
- 通过对ZooKeeper中丰富的数据节点类型进⾏交叉使⽤,配合Watcher事件通知机制,可以⾮常⽅便地构建⼀系列分布式应⽤中都会涉及的核⼼功能如数据发布/订阅、命名服务、集群管理、Master选举、分布式锁和分布式队列等。
- Zookeeper的两⼤特性:
- 客户端如果对Zookeeper的数据节点注册Watcher监听,那么当该数据节点的内容或是其⼦节点列表发⽣变更时,Zookeeper服务器就会向订阅的客户端发送变更通知。
- 对在Zookeeper上创建的临时节点,⼀旦客户端与服务器之间的会话失效,那么临时节点也会被⾃动删除
- 利⽤其两⼤特性,可以实现集群机器存活监控系统,若监控系统在/clusterServers节点上注册⼀个Watcher监听,那么但凡进⾏动态添加机器的操作,就会在/clusterServers节点下创建⼀个临时节点:/clusterServers/[Hostname],这样,监控系统就能够实时监测机器的变动情况。
分布式锁
什么是锁?
- 在单机程序中,当存在多个线程可以同时改变某个变量(可变共享变量)时,为了保证线程安全(数据不能出现脏数据)就需要对变量或代码块做同步,使其在修改这种变量时能够串⾏执⾏消除并发修改变量。
- 对变量或者堆代码码块做同步本质上就是加锁。⽬的就是实现多个线程在⼀个时刻同⼀个代码块只能有⼀个线程可执⾏
分布式锁
-
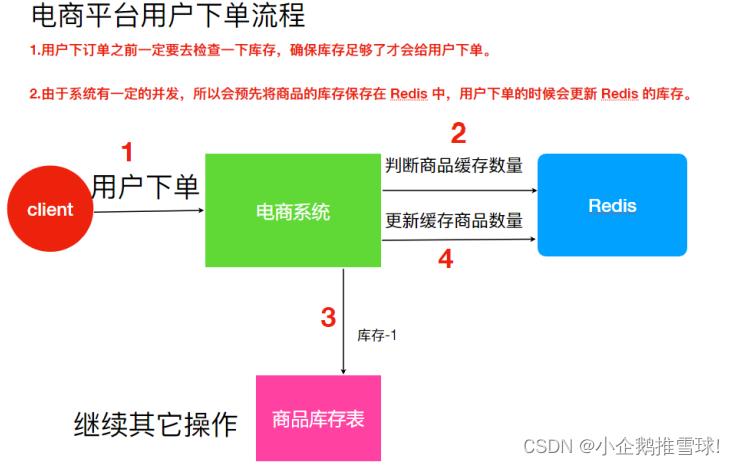
分布式的环境中会不会出现脏数据的情况呢?类似单机程序中线程安全的问题.
-
假设Redis ⾥⾯的某个商品库存为 1;此时两个⽤户同时下单,其中⼀个下单请求执⾏到第 3 步,更新数据库的库存为 0,但是第 4 步还没有执⾏。⽽另外⼀个⽤户下单执⾏到了第 2 步,发现库存还是 1,就继续执⾏第 3 步。但是商品库存已经为0,所以如果数据库没有限制就会出现超卖的问题。
-
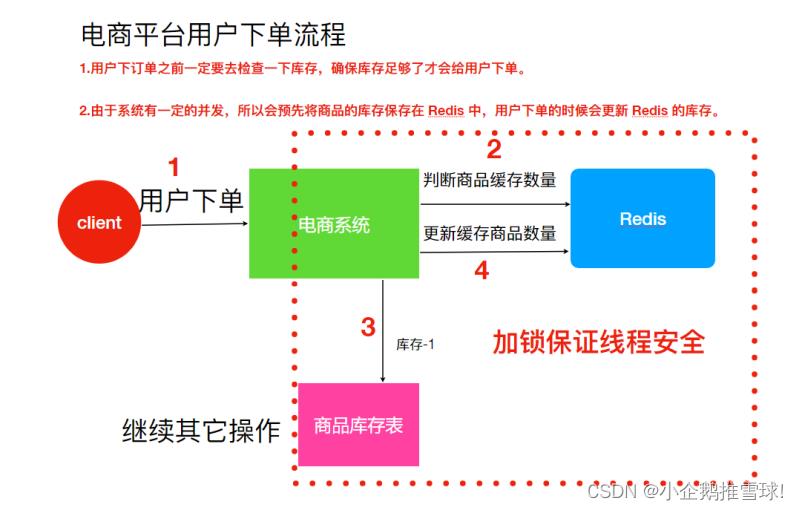
解决⽅法:⽤锁把 2、3、4 步锁住,让他们执⾏完之后,另⼀个线程才能进来执⾏
-
但是,电商系统如果分布在多台机器上时,会出现更大的问题
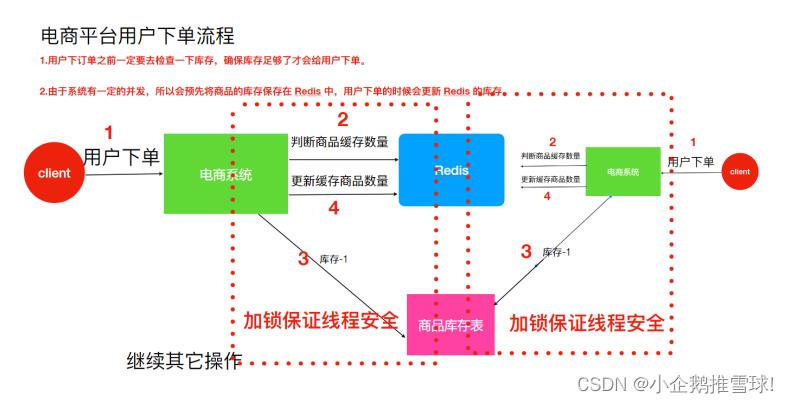
- 假设有两个下单请求同时到来,分别由两个机器执⾏,那么这两个请求是可以同时执⾏了,依然存在超卖的问题。因为如图所示系统是运⾏在两个不同的 JVM ⾥⾯,不同的机器上,增加的锁只对⾃⼰当前 JVM ⾥⾯的线程有效,对于其他 JVM 的线程是⽆效的。所以现在已经不是线程安全问题。需要保证两台机器加的锁是同⼀个锁,此时分布式锁就能解决该问题
- 分布式锁的作⽤:在整个系统提供⼀个全局、唯⼀的锁,在分布式系统中每个系统在进⾏相关操作的时候需要获取到该锁,才能执⾏相应操作
以上是关于分布式协调服务框架——Zookeeper的基本使⽤的主要内容,如果未能解决你的问题,请参考以下文章