kafkaKafka 快速入门
Posted 技术能量站
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafkaKafka 快速入门相关的知识,希望对你有一定的参考价值。
1. kafka 简介和环境搭建
Kafka 是由 Linkedin 公司开发的,它是一个分布式的,支持多分区、多副本,基于 Zookeeper 的分布式消息流平台,它同时也是一款开源的基于发布订阅模式的消息引擎系统。
- kafka官网:http://kafka.apache.org/
- kafka配置快速入门:http://kafka.apache.org/quickstart
1.1 基于win10搭建单机版kafka环境(采用自带的Zookeeper)
(1)kafka下载页面:http://kafka.apache.org/downloads

(2)下载完成后,目录如下:

(3)修改config目录下的zookeeper.properties和server.properties配置文件
- server.properties文件注意下面几项
advertised.listeners=PLAINTEXT://127.0.0.1:9092
log.dirs=F:/studyTools/MQ/kafka_2.13-2.7.0/kafka-logs
zookeeper.connect=127.0.0.1:2181- zookeeper.properties 文件配置:
dataDir=F:/studyTools/MQ/kafka_2.13-2.7.0/data/zk (4)如上修改后,win本地基本就可以启动环境了
- kafka官网也给我们提供了指南:http://kafka.apache.org/quickstart
- 启动的时候,可以自己按照 .bat + .properties 形式启动,启动顺序是:先启动zookeeper,后启动
# Start the ZooKeeper service
# Note: Soon, ZooKeeper will no longer be required by Apache Kafka.
$ bin/zookeeper-server-start.sh config/zookeeper.properties
# Start the Kafka broker service
$ bin/kafka-server-start.sh config/server.properties- 为了方便可以自己写一个bat,使用win 处理脚本启动运行:
start-zookeeper-1.bat 启动
echo "zookeeper start ..."
@echo off
start F:/studyTools/MQ/kafka_2.13-2.7.0/bin/windows/zookeeper-server-start.bat
F:/studyTools/MQ/kafka_2.13-2.7.0/config/zookeeper.propertiesstart-kafka-2.bat
echo "zookeeper start ..."
@echo off
start F:/studyTools/MQ/kafka_2.13-2.7.0/bin/windows/kafka-server-start.bat
F:/studyTools/MQ/kafka_2.13-2.7.0/config/server.properties(5)双击启动后如下显示,表示启动成功
start-zookeeper-1.bat 启动

start-kafka-2.bat

2. springboot 整合kafka
2.1 引入pom依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
2.2 application.propertise配置(本文用到的配置项这里全列了出来)
###########【Kafka集群】###########
spring.kafka.bootstrap-servers=112.126.74.249:9092,112.126.74.249:9093
###########【初始化生产者配置】###########
# 重试次数
spring.kafka.producer.retries=0
# 应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
spring.kafka.producer.acks=1
# 批量大小
spring.kafka.producer.batch-size=16384
# 提交延时
spring.kafka.producer.properties.linger.ms=0
# 当生产端积累的消息达到batch-size或接收到消息linger.ms后,生产者就会将消息提交给kafka
# linger.ms为0表示每接收到一条消息就提交给kafka,这时候batch-size其实就没用了
# 生产端缓冲区大小
spring.kafka.producer.buffer-memory = 33554432
# Kafka提供的序列化和反序列化类
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
# 自定义分区器
# spring.kafka.producer.properties.partitioner.class=com.felix.kafka.producer.CustomizePartitioner
###########【初始化消费者配置】###########
# 默认的消费组ID
spring.kafka.consumer.properties.group.id=defaultConsumerGroup
# 是否自动提交offset
spring.kafka.consumer.enable-auto-commit=true
# 提交offset延时(接收到消息后多久提交offset)
spring.kafka.consumer.auto.commit.interval.ms=1000
# 当kafka中没有初始offset或offset超出范围时将自动重置offset
# earliest:重置为分区中最小的offset;
# latest:重置为分区中最新的offset(消费分区中新产生的数据);
# none:只要有一个分区不存在已提交的offset,就抛出异常;
spring.kafka.consumer.auto-offset-reset=latest
# 消费会话超时时间(超过这个时间consumer没有发送心跳,就会触发rebalance操作)
spring.kafka.consumer.properties.session.timeout.ms=120000
# 消费请求超时时间
spring.kafka.consumer.properties.request.timeout.ms=180000
# Kafka提供的序列化和反序列化类
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
# 消费端监听的topic不存在时,项目启动会报错(关掉)
spring.kafka.listener.missing-topics-fatal=false
# 设置批量消费
# spring.kafka.listener.type=batch
# 批量消费每次最多消费多少条消息
# spring.kafka.consumer.max-poll-records=50
2.3 简单的消息生产消费
(1)简单生产者
/**
* 简单的生产者
* http://localhost:8080/kafka/normal/%E4%BD%A0%E5%A5%BD
*/
@GetMapping("/kafka/normal/message")
public void sendMessage1(@PathVariable("message") String normalMessage)
log.info("生产消息:",normalMessage);
// topic命名规范:公司部门开头,环境结尾
kafkaTemplate.send(ConstantKafka.TOPIC_SIMPLE, normalMessage);
(2)简单消费
// 消费监听 普通消息
@KafkaListener(topics = ConstantKafka.TOPIC_SIMPLE)
public void onMessage1(ConsumerRecord<?, ?> record)
// 消费的哪个topic、partition的消息,打印出消息内容
System.out.println(
"简单消费:" + record.topic() +
"-" + record.partition() +
"-" + record.value());
上面示例创建了一个生产者,发送消息到topic1,消费者监听topic1消费消息。监听器用@KafkaListener注解,topics表示监听的topic,支持同时监听多个,用英文逗号分隔。启动项目,postman调接口触发生产者发送消息,

可以看到监听器消费成功,
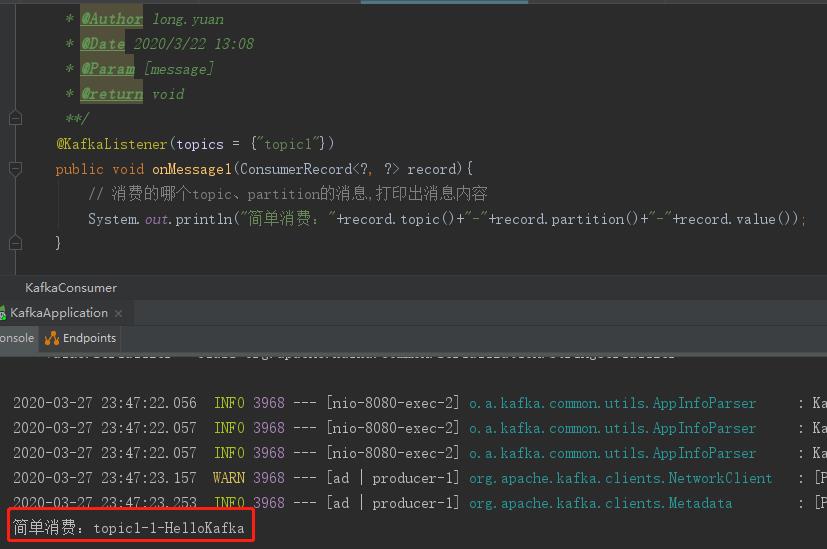
2.4 kafka 生产者
(1)带回调的生产者
kafkaTemplate提供了一个回调方法addCallback,我们可以在回调方法中监控消息是否发送成功 或 失败时做补偿处理,有两种写法,
@GetMapping("/kafka/callbackOne/message")
public void sendMessage2(@PathVariable("message") String callbackMessage)
kafkaTemplate.send(ConstantKafka.TOPIC_CALLBACK, callbackMessage).addCallback(success ->
// 消息发送到的topic
String topic = success.getRecordMetadata().topic();
// 消息发送到的分区
int partition = success.getRecordMetadata().partition();
// 消息在分区内的offset
long offset = success.getRecordMetadata().offset();
System.out.println("发送消息成功:" + topic + "-" + partition + "-" + offset);
, failure ->
System.out.println("发送消息失败:" + failure.getMessage());
);
@GetMapping("/kafka/callbackTwo/message")
public void sendMessage3(@PathVariable("message") String callbackMessage)
kafkaTemplate.send(ConstantKafka.TOPIC_CALLBACK, callbackMessage)
.addCallback(new ListenableFutureCallback<SendResult<String, Object>>()
@Override
public void onFailure(Throwable ex)
System.out.println("发送消息失败:" + ex.getMessage());
@Override
public void onSuccess(SendResult<String, Object> result)
System.out.println("发送消息成功:" + result.getRecordMetadata().topic() +
"-" + result.getRecordMetadata().partition() +
"-" + result.getRecordMetadata().offset());
);
(2)自定义分区器
我们知道,kafka中每个topic被划分为多个分区,那么生产者将消息发送到topic时,具体追加到哪个分区呢?这就是所谓的分区策略,Kafka 为我们提供了默认的分区策略,同时它也支持自定义分区策略。其路由机制为:
- 若发送消息时指定了分区(即自定义分区策略),则直接将消息append到指定分区;
- 若发送消息时未指定 patition,但指定了 key(kafka允许为每条消息设置一个key),则对key值进行hash计算,根据计算结果路由到指定分区,这种情况下可以保证同一个 Key 的所有消息都进入到相同的分区;
- patition 和 key 都未指定,则使用kafka默认的分区策略,轮询选出一个 patition;
我们来自定义一个分区策略,将消息发送到我们指定的partition,首先新建一个分区器类实现Partitioner接口,重写方法,其中partition方法的返回值就表示将消息发送到几号分区,
public class CustomizePartitioner implements Partitioner
@Override
public int partition(String topic,
Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster)
// 自定义分区规则(这里假设全部发到0号分区)
// ......
return 0;
@Override
public void close()
@Override
public void configure(Map<String, ?> configs)
在application.propertise中配置自定义分区器,配置的值就是分区器类的全路径名,
# 自定义分区器
spring.kafka.producer.properties.partitioner.class=com.felix.kafka.producer.CustomizePartitioner
(3)kafka事务提交
如果在发送消息时需要创建事务,可以使用 KafkaTemplate 的 executeInTransaction 方法来声明事务,
/**
* kafka 事务提交
*/
@GetMapping("/kafka/transaction")
public void sendMessageTransaction()
// 声明事务:后面报错消息不会发出去
kafkaTemplate.executeInTransaction(operations ->
operations.send(ConstantKafka.TOPIC_TRANSACTION,"test executeInTransaction");
throw new RuntimeException("fail");
);
// 不声明事务:后面报错但前面消息已经发送成功了
kafkaTemplate.send(ConstantKafka.TOPIC_TRANSACTION,"test executeInTransaction");
throw new RuntimeException("fail");
2.5 kafka 消费者
(1)指定topic、partition、offset消费
前面我们在监听消费topic1的时候,监听的是topic1上所有的消息,如果我们想指定topic、指定partition、指定offset来消费呢?也很简单,@KafkaListener注解已全部为我们提供,
/**
* @Title 指定topic、partition、offset消费
* @Description 同时监听topic1和topic2,监听topic1的0号分区、topic2的 "0号和1号" 分区,
* 指向1号分区的offset初始值为8
* @Date 2020/3/22 13:38
* @Param [record]
* @return void
**/
@KafkaListener(
id = "consumer1",
groupId = "felix-group",
topicPartitions =
@TopicPartition(topic = "topic1", partitions = "0"),
@TopicPartition(topic = "topic2", partitions = "0", partitionOffsets =
@PartitionOffset(partition = "1", initialOffset = "8"))
)
public void onMessage2(ConsumerRecord<?, ?> record)
System.out.println(
"topic:" + record.topic() +
"|partition:" + record.partition() +
"|offset:" + record.offset() +
"|value:" + record.value());
属性解释:
- id:消费者ID;
- groupId:消费组ID;
- topics:监听的topic,可监听多个;
- topicPartitions:可配置更加详细的监听信息,可指定topic、parition、offset监听。
上面onMessage2监听的含义:监听topic1的0号分区,同时监听topic2的0号分区和topic2的1号分区里面offset从8开始的消息。
注意:topics和topicPartitions不能同时使用;
(2)批量消费
设置application.prpertise开启批量消费即可,
# 设置批量消费
spring.kafka.listener.type=batch
# 批量消费每次最多消费多少条消息
spring.kafka.consumer.max-poll-records=50
接收消息时用List来接收,监听代码如下,
@KafkaListener(id = "consumer2",groupId = "felix-group", topics = "topic1")
public void onMessage3(List<ConsumerRecord<?, ?>> records)
System.out.println(">>>批量消费一次,records.size()="+records.size());
for (ConsumerRecord<?, ?> record : records)
System.out.println(record.value());
(3)消费异常处理
通过异常处理器(ConsumerAwareListenerErrorHandler),我们可以处理consumer在消费时发生的异常。新建一个 ConsumerAwareListenerErrorHandler 类型的异常处理方法,用@Bean注入,BeanName默认就是方法名,然后我们将这个异常处理器的BeanName放到@KafkaListener注解的errorHandler属性里面,当监听抛出异常的时候,则会自动调用异常处理器,
// 新建一个异常处理器,用@Bean注入
@Bean
public ConsumerAwareListenerErrorHandler consumerAwareErrorHandler()
return (message, exception, consumer) ->
System.out.println("消费异常:"+message.getPayload());
return null;
;
// 将这个异常处理器的BeanName放到@KafkaListener注解的errorHandler属性里面
@KafkaListener(topics = "topic1",errorHandler = "consumerAwareErrorHandler")
public void onMessage4(ConsumerRecord<?, ?> record) throws Exception
throw new Exception("简单消费-模拟异常");
// 批量消费也一样,异常处理器的message.getPayload()也可以拿到各条消息的信息
@KafkaListener(topics = "topic1",errorHandler="consumerAwareErrorHandler")
public void onMessage5(List<ConsumerRecord<?, ?>> records) throws Exception
System.out.println("批量消费一次...");
throw new Exception("批量消费-模拟异常");
执行看一下效果,

(4)消费时消息过滤器
消息过滤器可以在消息抵达consumer之前被拦截,在实际应用中,我们可以根据自己的业务逻辑,筛选出需要的信息再交由KafkaListener处理,不需要的消息则过滤掉。
配置消息过滤只需要为 监听器工厂 配置一个RecordFilterStrategy(消息过滤策略),返回true的时候消息将会被抛弃,返回false时,消息能正常抵达监听容器。
@Component
public class ConsumerFilterMessage
@Resource
private ConsumerFactory consumerFactory;
// 消息过滤器
@Bean
public ConcurrentKafkaListenerContainerFactory filterContainerFactory()
ConcurrentKafkaListenerContainerFactory factory =
new ConcurrentKafkaListenerContainerFactory();
factory.setConsumerFactory(consumerFactory);
// 被过滤的消息将被丢弃
factory.setAckDiscarded(true);
// 消息过滤策略
factory.setRecordFilterStrategy(consumerRecord ->
if (Integer.parseInt(consumerRecord.value().toString()) % 2 == 0)
return false;
//返回true消息则被过滤
return true;
);
return factory;
// 消息过滤监听
@KafkaListener(
topics = "topic1",
containerFactory = "filterContainerFactory")
public void onMessage6(ConsumerRecord<?, ?> record)
System.out.println(record.value());
上面实现了一个"过滤奇数、接收偶数"的过滤策略,我们向topic1发送0-99总共100条消息,看一下监听器的消费情况,可以看到监听器只消费了偶数,
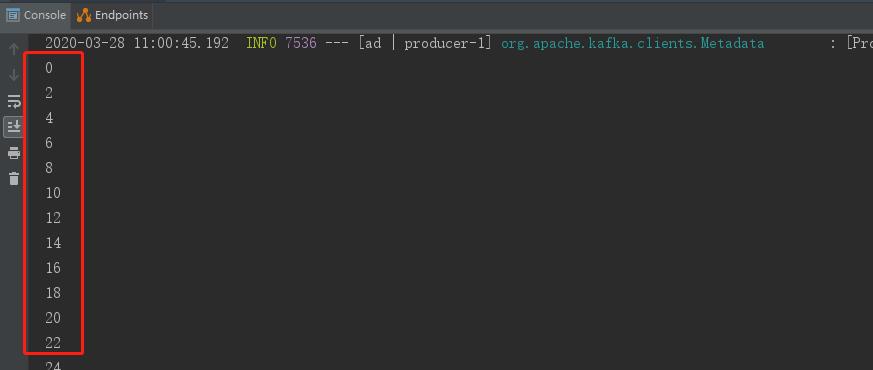
(5)消息转发
在实际开发中,我们可能有这样的需求,应用A从TopicA获取到消息,经过处理后转发到TopicB,再由应用B监听处理消息,即一个应用处理完成后将该消息转发至其他应用,完成消息的转发。
在SpringBoot集成Kafka实现消息的转发也很简单,只需要通过一个@SendTo注解,被注解方法的return值即转发的消息内容,如下,
/**
* @Title 消息转发
* @Description 从topic1接收到的消息经过处理后转发到topic2
**/
@KafkaListener(topics = "topic1")
@SendTo("topic2")
public String onMessage7(ConsumerRecord<?, ?> record)
return record.value()+"-forward message";
(6)定时启动、停止监听器
默认情况下,当消费者项目启动的时候,监听器就开始工作,监听消费发送到指定topic的消息,那如果我们不想让监听器立即工作,想让它在我们指定的时间点开始工作,或者在我们指定的时间点停止工作,该怎么处理呢——使用KafkaListenerEndpointRegistry,下面我们就来实现:
- 禁止监听器自启动;
- 创建两个定时任务,一个用来在指定时间点启动定时器,另一个在指定时间点停止定时器;
新建一个定时任务类,用注解@EnableScheduling声明,KafkaListenerEndpointRegistry 在SpringIO中已经被注册为Bean,直接注入,设置禁止KafkaListener自启动,
@EnableScheduling
@Component
public class CronTimer
/**
* @KafkaListener注解所标注的方法并不会在IOC容器中被注册为Bean,
* 而是会被注册在KafkaListenerEndpointRegistry中,
* 而KafkaListenerEndpointRegistry在SpringIOC中已经被注册为Bean
**/
@Resource
private KafkaListenerEndpointRegistry registry;
@Resource
private ConsumerFactory consumerFactory;
// 监听器容器工厂(设置禁止KafkaListener自启动)
@Bean
public ConcurrentKafkaListenerContainerFactory delayContainerFactory()
ConcurrentKafkaListenerContainerFactory container =
new ConcurrentKafkaListenerContainerFactory();
container.setConsumerFactory(consumerFactory);
//禁止KafkaListener自启动
container.setAutoStartup(false);
return container;
// 监听器
@KafkaListener(id="timingConsumer",topics = "topic1",
containerFactory = "delayContainerFactory")
public void onMessage1(ConsumerRecord<?, ?> record)
System.out.println("消费成功:"+record.topic()+
"-"+record.partition()+"-"+record.value());
// 定时启动监听器
@Scheduled(cron = "0 42 11 * * ? ")
public void startListener()
System.out.println("启动监听器...");
// "timingConsumer"是@KafkaListener注解后面设置的监听器ID,标识这个监听器
if (!registry.getListenerContainer("timingConsumer").isRunning())
registry.getListenerContainer("timingConsumer").start();
//registry.getListenerContainer("timingConsumer").resume();
// 定时停止监听器
@Scheduled(cron = "0 45 11 * * ? ")
public void shutDownListener()
System.out.println("关闭监听器...");
registry.getListenerContainer("timingConsumer").pause();
启动项目,触发生产者向topic1发送消息,可以看到consumer没有消费,因为这时监听器还没有开始工作,

11:42分监听器启动开始工作,消费消息,
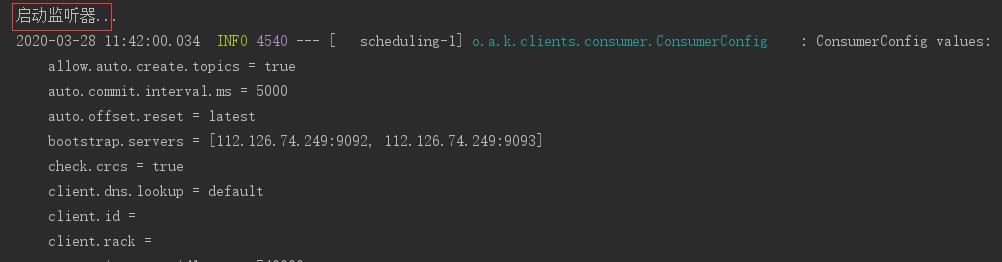

11:45分监听器停止工作,

3. Kafka 探险总结
3.1 Kafka 名称解释
Kafka是一个分布式消息(存储)系统。分布式系统通过分片增加并行度;通过副本增加可靠性,kafka也不例外。它的结构逃不出基本分布式理论。如果你把副本、分区、主题通道,生产者、消费者这些名词放在一块的话,图就可以变得非常大。

你在一台机器上安装了Kafka,那么这台机器就叫Broker,KAFKA集群包含了一个或者多个这样的实例。这只是一个命名而已,并没有什么特定含义。
- 负责往KAFKA写入数据的组件就叫做
Producer,消息的生产者一般写在业务系统里。 - 发送到KAFKA的消息可能有多种,如何区别其分类?就是
Topic的概念。一个主题分布式化后,可能会存在多个Broker上。 - 将Topic拆成多个段,增加并行度后,拆成的每个部分叫做
Partition,分区一般平均分布在所有机器上。 - 那些消费Kafka中数据的应用程序,就叫做
Consumer,我们给某个主题的某个消费业务起一个名字,这么名字就叫做Consumer Group
再看一下Kafka Server的配置文件,最重要的两个参数:partitions和replication.factor,其实就非常好理解了。

-
副本
单机上的任何数据都是不可信的,因为硬盘会坏,会断电,会被挖光缆。所以一般通过冗余多个副本来保证数据的安全。副本的另外一个作用,就是提供额外的计算能力,比如某些请求,会落到副本上。副本越多,可用性越高。

而加入副本以后,就涉及到数据的同步问题。即使是最快的局域网,也会存在延迟,更不用说机器性能差异引起的同步延迟。这就存在一个问题,读副本的请求读到的数据,可能不是最新的,这就是数据的一致性发生了改变。当然有些手段能保证数据的一致性,但副本越多,延迟越大。
副本的加入还会引入主从的问题。主节点死掉以后,要有副本节点顶上去,这个过程的协调需要时间,其间部分不可用。
所以的消息系统,需要有大量的代码去处理这些异常情况。
- 分区
而当一类数据足够大(比如说某张表),在其上的操作已经非常耗时的情况下,就需要对此类数据进行切割,将其分布到多台机器上。这个切割过程就是Sharding,通过一定规则的分片来减少单次查询数据的规模,增加集群容量。

针对一个分片的数据,只能有一个写入的地方,这就是master,其他副本都是从master复制数据。
副本能够增加读操作的并行读,但会读到脏数据。如果你想要读到的数据是一致的,可以采用同步写副本的方式,比如KAFKA的ack=-1,只有全部同步成功了,才认为本次提交成功。
但如果你的副本太多,这个过程会非常的慢。你可能想要通过分配写入和读取的副本个数来协调写入和读取的效率,Quorum的R+W>N就是一个权衡策略。
Kafka解决副本之间的同步,采用的是
ISR,这是一个面试Kafka必考的点之一。
ISR全称"In-Sync Replicas",是保证HA和一致性的重要机制。副本数对Kafka的吞吐率是有一定的影响,但极大的增强了可用性。一般2-3个为宜。
副本有两个要素,一个是数量要够多,一个是不要落在同一个实例上。ISR是针对与Partition的,每个分区都有一个同步列表。N个replicas中,其中一个replica为leader,其他都为follower, leader处理partition的所有读写请求,其他的都是备份。与此同时,follower会被动定期地去复制leader上的数据。
如果一个flower比一个leader落后太多,或者超过一定时间未发起数据复制请求,则leader将其重ISR中移除。
当ISR中所有Replica都向Leader发送ACK时,leader才commit。
3.2 消息系统的作用
说了这么多,是时候把消息队列的作用,使用计算机的术语解释一下了:
- 削峰 用于承接超出业务系统处理能力的请求,使业务平稳运行。这能够大量节约成本,比如某些秒杀活动,并不是针对峰值设计容量。
- 缓冲 在服务层和缓慢的落地层作为缓冲层存在,作用与削峰类似,但主要用于服务内数据流转。比如批量短信发送。
- 解耦 项目尹始,并不能确定具体需求。消息队列可以作为一个接口层,解耦重要的业务流程。只需要遵守约定,针对数据编程即可获取扩展能力。
- 冗余 消息数据能够采用一对多的方式,供多个毫无关联的业务使用。
- 健壮性 消息队列可以堆积请求,所以消费端业务即使短时间死掉,也不会影响主要业务的正常进行
但是,由于Kafka是个优秀的小伙,它内卷的非常可以,就能做更多的事情。它的本分范围更加大,包括但不限于:
- 传递业务消息
- 用户活动日志 • 监控项等
- 日志
- 流处理,比如某些聚合
- Commit Log,作为某些重要业务的冗余
- Event Source,实践溯源,DDD中的概念
下面是一个日志方面的典型使用场景。

3.3 kafka 为什么这么快
一般用到Kafka,都是奔着它的速度去的,这一度让人认为它只能处理一些日志类的消息。事实上,Kafka就连最复杂的事务消息都支持,也算是被它的速度所掩盖的一个光彩。
那么,它为什么那么快呢?总结下来有以下几点原因:
- Cache Filesystem Cache PageCache缓存
- 顺序写 由于现代的操作系统提供了预读和写技术,磁盘的顺序写大多数情况下比随机写内存还要快
- Zero-copy 零拷⻉,少了一次内存交换
- Batching of Messages 批量处理。合并小的请求,然后以流的方式进行交互,直顶网络上限
- Pull 拉模式 使用拉模式进行消息的获取消费,与消费端处理能力相符
主要就这5点,至于什么压缩,JVM性能优化之类的,都是小儿科,上不了台面。
END
可以看到,Kafka是一个全能的选手,既能做消息处理,又能做数据存储。它无怨无悔的工作,虽然效率奇高,也要一刻不停歇的工作,体现了打工人最悲催的命运。
它的分布式系统设计也是非常棒的,这是它的设计者为它量身定做的一套体系:一台Kafka节点倒下了,会有更多的Kafka节点顶上来,经过十几秒的阵痛,然后就可以彻底的忘掉它的牺牲。
Kafka是一个本分的分布式消息系统,但也不要无限的压迫它。只给它分配了1核cpu、512M的内存,这是要磨练它在艰苦环境下不屈不挠的本分意志,啊!
丢了数据还骂ta不稳定,你的良心不会痛么?
相关文章
以上是关于kafkaKafka 快速入门的主要内容,如果未能解决你的问题,请参考以下文章