一起架构-某实时分析项目云原生 serverless 架构的设计思路和poc代码实现
Posted 明哥的IT随笔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一起架构-某实时分析项目云原生 serverless 架构的设计思路和poc代码实现相关的知识,希望对你有一定的参考价值。
1. 前言 - 云原生与多云混合云的部署架构
大家好,我是明哥!
在数字化转型的大背景下,越来越多的企业不断将越来越多的应用部署到云上,应用的架构也更加倾向云原生,以支持多云和混合云的部署架构。
前段时间,笔者参与了某个实时分析项目在 AWS 上的架构设计和 POC 开发,该项目使用了 serverless 的云原生架构,在此跟大家分享下架构设计和 poc 代码的细节,希望大家喜欢。
2. 项目背景和目标 Background and goals
整个项目的背景和目标如下:

经提炼和概括,项目的背景,基本目标和额外目标如下:
- 背景:Ingest, transform and prepare the netCDF data provided by UK Met Office, make them available for secure querying by our customer, as soon as it arrives in the S3 bucket.
- 基本目标:Core capabilities include:
- high availability (no downtime)
- quick response
- timely availability of new data.
- 额外目标:Extra Goals:
- Security
- cost effectiveness
3. 整体架构图 Architecture overview
最终设计的完整的架构图如下:
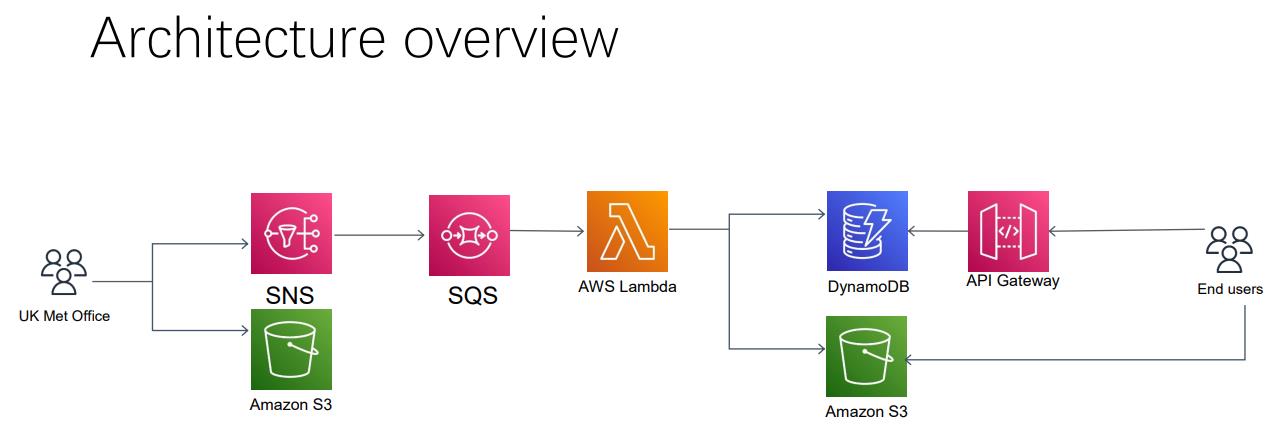
4. 架构设计和技术选型 Architecture details and thought process
4.1 How to discover new available data ASAP? - SQS
- UK Met Office prepares the original data in netCDF format and uploaded them to a S3 bucket, but as listing a bucket is both expensive and slow (file system vs object store), we can’t take this approach for quickly discover of new available data in s3;
- We noticed that UK Met Office will also send a message to a SNS topic once new data is available in the S3 bucket, so we can use a SQS to scribe to the SNS topic, and got notified when new objects are created, this solution is latency-efficient, cost-effective and scalable;
4.2 Can we use the original S3 bucket used by the UK Met Office?
- We noticed that the original data will be held in the bucket for 7 days after the notification is sent, then they will be deleted;
- We can use our own S3 bucket to store the data, so we have full control of the data, including the data lifecycle, the data security policies, etc;
4.3 How to server our end users, with quick response and high availability? – API gateway + DynamoDB
- Our end users typically ask questions like “how will the weather/humidity/temperature be like in city C1, at time T1? how about city C2 and C3? How about time T2?”, to answer that question, we have to first figure out which files in the S3 bucket contains forecast results for that specific time (all the files contains forecast results for all the cities in UK, so place should not be a problem);
- So we can use a RDS or DynamoDB to store the metadata “which s3 file contains forecast results for which time”, then when we receive a specific question from our customer, we can first query the RDS/DynamoDB to find out the corresponding S3 file, then they can query the s3 file to get all the forecast details, including weather/humidity/temperature etc, for all the UK cities;
- RDS is a relational database and is typically for well-formed structured data, while DynamoDB is a fully-managed Key-value NoSql data store, both can fulfill our functional requirements, but considering that we don’t have highly-structured data, and DynamoDB shines in Availability. Scalability and Performance, so we will go with DynamoDB;
- We can use an API gateway as a proxy to the DynamoDB and answer the end user’s request directly, with out an extra lambda layer between API gateway and DynamoDB, hence the whole data pipeline is shorter, which will be more time-effective, cost-effective, and less issues will occur; Also API gateway provides many security mechanisms, including authentication, authorization,audit and encryption;
- With api gateway, DynamoDB and S3, the whole serving layer will response quickly with high availability, and is also cost-effective and secured;
4.4 How to ingest, transform and prepare the original data - Lambda!
- To consume messages in SQS queues, we normally follow the event-driven architecture and use streaming processing frameworks like spark streaming/flink/kafka stream, but to use them, you need to first provision ec2 servers and possibly use ecs/eks, but you need to deploy, monitor and scale(both up and down) your app all by yourself, this is cumbersome and not cost-effective;
- You can consider using serverless Fargate, but you have to deal with the event-driven by yourself;
- Lambda is both serverless and event-driven, it automatically scales according to your data volume, it integrates with other aws services like sqs, s3, DynamoDB, api gateway well, and it allow you to pay for what you use, so it is a perfect match for our case!
- we can use lambda and create a sqs trigger, so right after events arrived in sqs, it will trigger the execution of lamba where we can do the transform and load into downstream DynamoDB table;
5 技术组件细节和示例代码 Component details and code samples
5.1 Component details and code samples – sqs and lambda
- Sqs type:as there is no need for First-in-first-out message delivery and Exactly-once processing, we can stay with the standard type sqs,which offers better scalability;
- Sqs encryption: Amazon SQS provides in-transit encryption by default, we also added at-rest encryption to our queue by enable server-side encryption (uses Amazon SQS key (SSE-SQS));
- Lambda: lambda has an sqs trigger, and for performance consideration, we are using batch to writer into dynamodb;
- Labmda permission: to follow the least-access polity, we created a new IAM role with basic Lambda permissions (with just polices like AWSLambdaSQSQueueExecutionRole/AWSLambdaExecute/AWSLambdaDynamoDBExecutionRole)
5.2 Component details and code samples - dynamoDB
- dynamoDB is serverless and will auto scale based on data volume and query, so to avoid hot spot bottleneck, we used forecast_period as partition key/hash key and forecast_time as sort key;(forecast_period is the difference between forecast_reference_time and forecast_time);
- As end users typically query based on time, so we created a secondary global indexes sgi, with partition key on the time field forecast_time;
- Encryption: we turned on Encryption at rest, and used encryption keys stored in AWS Key Management Service, whch is managed by DynamoDB at no extra cost;
- permission: for apis to query the dynamoDB, we followed the least-access polity and created an access control policy with only read policy on the table and index;
5.3 Component details and code samples – api gateway
- Api: I created two methods and resources, and configured the integration request and integration response’s mapping template, to full fill the scan and query on the dynamoDB, with paths like /times and /times/time, the latter one will use the sgi we created for the table;
- Api key: I configured the method request to use API Key;
- permission: to follow the least-access polity, we created a new IAM role with only necessary permissions (with just polices like AmazonAPIGatewayPushToCloudWatchLogs, and the dynamodb read-only policy we created earlier)
5.4 Component details and code samples – lambda codes
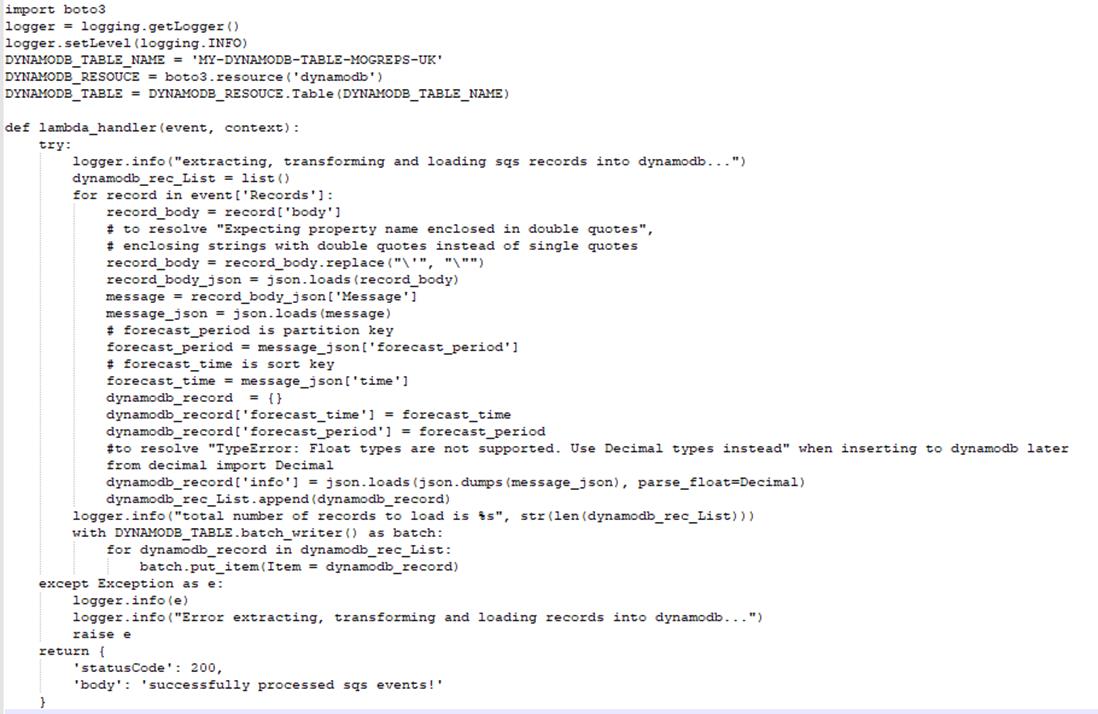
5.5 Component details and code samples – api codes

6. 脚本与自动化 automation using script - cloudFormation
- I believe in IaC (infrustructure As Code) and GitOps, humans will make mistakes and automation helps us on this (plus automation is more efficient and script is more repeatable);
- So I tried to use cloudFormation template to simplify the infrastructure management (due to time constraint, I only finished the dynamodb template);
- Below are part of the cloudFormation script for the dynamodb table creation;

7. 终端用户模拟访问效果 End user query simulation results
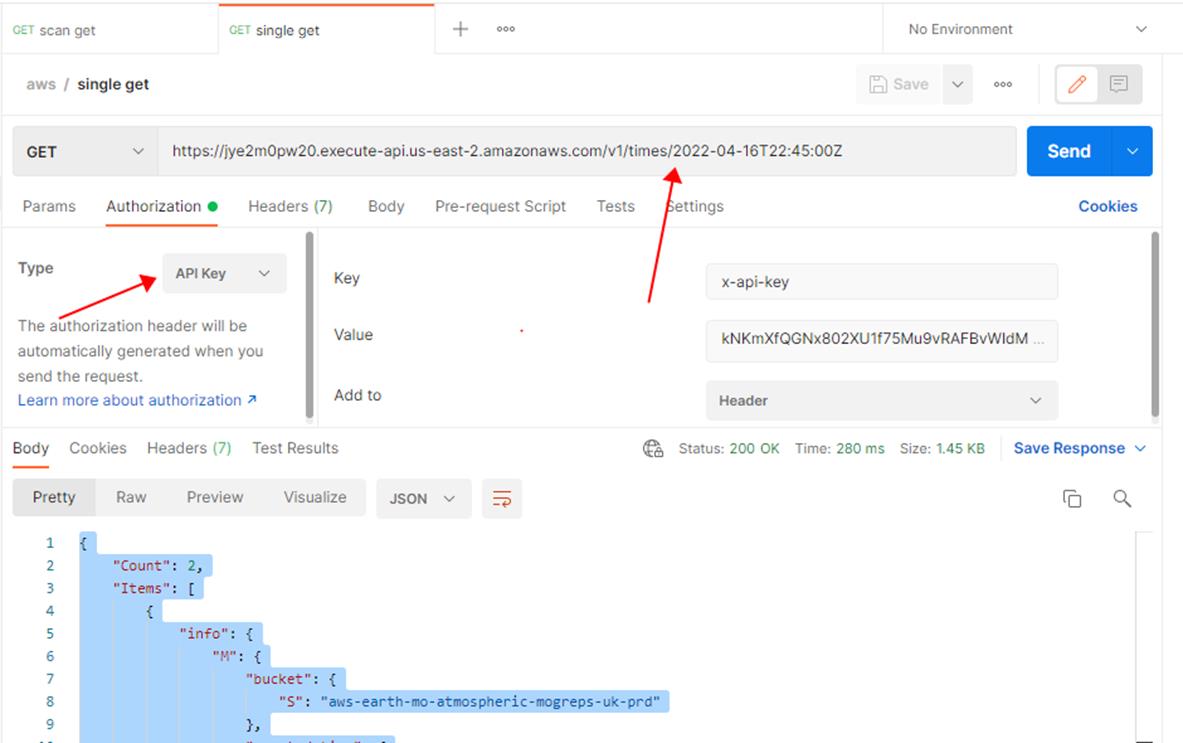
- IAM user with read only permission – IAM user name: arn:aws:iam::000435319421:user/demo
- IAM user with read only permission – IAM user password: demo123@aws
- End user request url: https://jye2m0pw20.execute-api.us-east2.amazonaws.com/v1/times/2022-04-16T22:45:00Z
- End user request sample path parameter: 2022-04-17T22:30:00Z/2022-04-16T22:45:00Z, etc;
- End user request type: get
- End user request Authorization Type: api key
- Key: x-api-key
- Value: kNKmXfQGNx802XU1f75Mu9vRAFBvWIdM5uT7NmHa
- Add to: header
8. 总结 Wrap up
- high availability (no downtime): The solution used components like sns,sqs,lambda,dynamodb,api gateway and s3, all of which are managed services which scaled well and scaled automatically, to ensure high availability (no downtime);
- quick response: The solution used dynamoDB in the serving layer, which scales well and scales automatically, and with the careful design of hashkey,sortkey and sgi, it offers quick response time to end users;
- timely availability of new data: The solution followed the event driven architecture, with sqs and lambda, and ensured the timely availability of new data;
- cost effectiveness:The solution followed the server-less architecture and used aws serveless services, so we can pay only what we use, and hence is cost effective;
- security:
- Encryption:aws service used TLS to provide encryption between user application and the AWS service which offered data-in-motion/transit encryption, and we enabled data-at-rest encryption;
- Authentication and Authorization:we also followed the least-access policy to create IAM roles and policyes. we also used an api key to protect our api gateway from malicious attacks
- Audit: CloudWatch is used for the audit;
!关注不迷路~ 各种福利、资源定期分享!欢迎小伙伴们扫码添加明哥微信,后台加群交流学习。

 开发者涨薪指南
开发者涨薪指南
 48位大咖的思考法则、工作方式、逻辑体系
48位大咖的思考法则、工作方式、逻辑体系
以上是关于一起架构-某实时分析项目云原生 serverless 架构的设计思路和poc代码实现的主要内容,如果未能解决你的问题,请参考以下文章