使用Tesseract OCR引擎和层次聚集聚类(HAC)对多列数据进行OCR
Posted 程序媛一枚~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Tesseract OCR引擎和层次聚集聚类(HAC)对多列数据进行OCR相关的知识,希望对你有一定的参考价值。
这篇博客将介绍如何使用Tesseract OCR引擎和层次聚集聚类(HAC)对多列数据进行OCR。包括学习一些OCR多列数据的提示和技巧,最重要的是,将文本的行/列关联在一起。
层次聚集聚类(HAC hierarchical agglomerative clustering)
多列OCR算法的工作原理是:
- 利用梯度和形态学运算检测输入图像中的文本表
- 提取检测到的表
- 使用Tesseract(或等效工具)对表格中的文本进行本地化,并提取表格中文本的边界框(x,y)-坐标
- 在具有最大距离阈值截止的表的x坐标上应用HAC进行聚类
本质上是将文本本地化与相同或非常接近的x坐标进行分组。
为什么这种方法有效?
是因为电子表格、表格或任何其他具有多列的文档的结构。每列中的数据将具有几乎相同的起始x坐标,因为它们属于同一列。因此可以利用这些知识,然后用几乎相同的x坐标将文本组聚在一起。
虽然这种方法过于简单,但在实践中效果很好。
单元格中文本之间的距离越大,–dist thresh应该越大。单元格中文本之间的距离越小,–dist thresh可以越小
pytesseart 依赖本地的tessearct.exe, 如果需要识别中文,还需要本地路径有E:\\xx\\Tesseract-OCR\\tessdata\\chi_sim.traineddata;
英文+字母,无网格线边框线的识别效果好一些;否则还需要额外处理。
1. 效果图
官方例子 原图 VS table图如下:
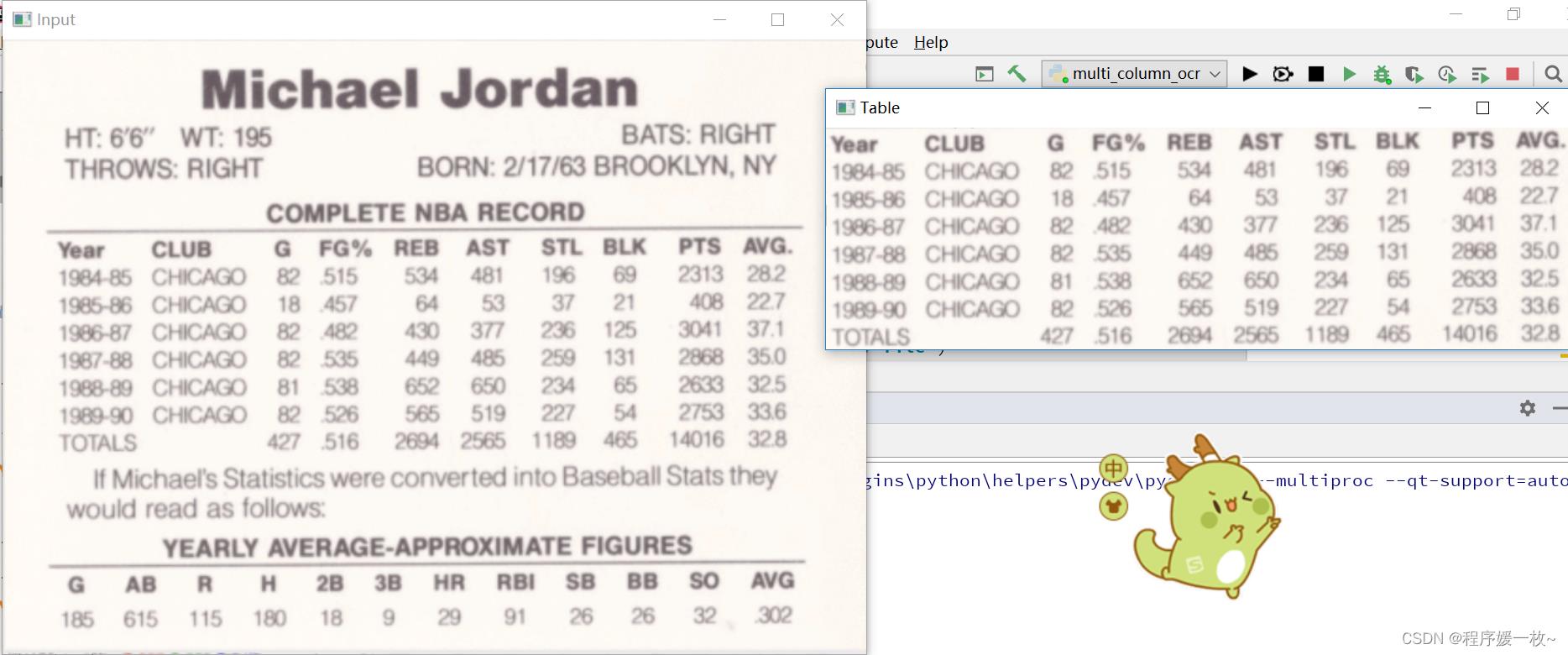
将层次聚集聚类(HAC)应用于OCR表,提取效果图:

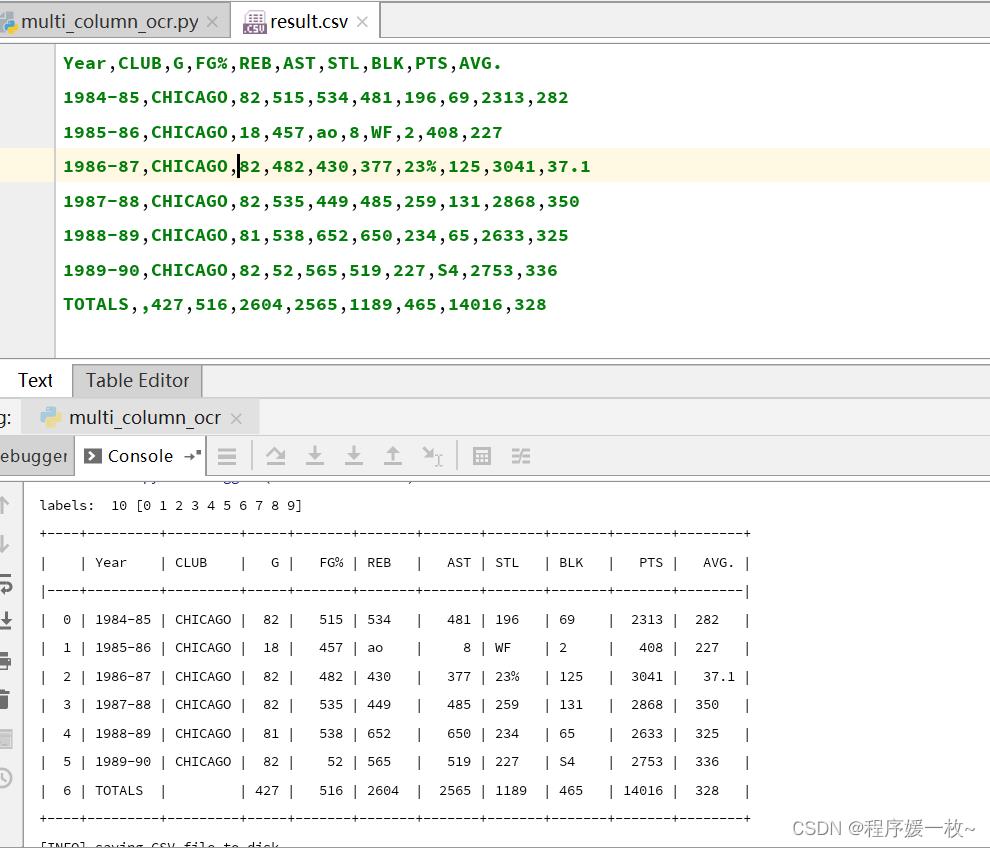
输出格式化的表格及csv,英文+数字,效果图很好
原始图 VS table图 效果图2如下:
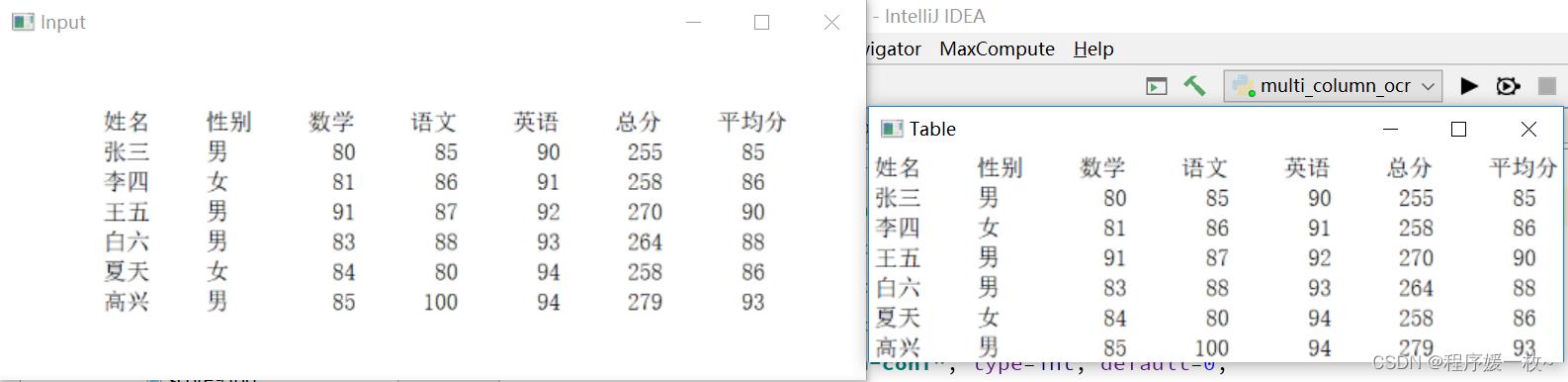
原始图 VS 将层次聚集聚类(HAC)应用于OCR表,提取效果图:

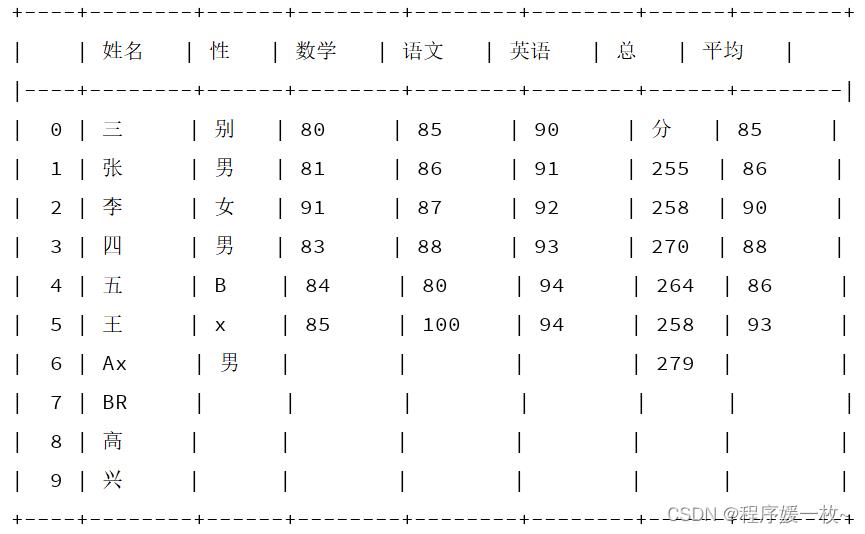
输出格式化的表格,中文的效果不是很好,有错位的
2. 原理
2.1 局限性
-
Tesseract在多列OCR方面不是很好,尤其是在图像有噪声的情况下。(可以关注Tesseract选项和配置的改进,以及后处理或者其他文本处理以提高其准确性)
-
可能需要先检测图像中的表格,然后才能进行OCR。
-
OCR引擎(Tesseract、云计算等)可能会正确地OCR- 文本,但无法将文本关联到列/行中。
具有相同边界框颜色的文本属于同一列,这表明HAC方法成功地将文本列关联在一起。
OCR结果在大多数情况下都非常准确,在多列上有时候表现不好。可以利用文本后处理启发式进一步改进OCR结果,以使Tesseract的性能高于最佳水平。
如小数点缺失,可以使用基本字符串解析/正则表达式插入小数点或将字符串转换为浮点数据类型。或者检查字符串长度等;
OCR结果中最重要的问题可以在STL和BLK列中找到,其OCR结果根本不正确。这是Tesseract结果的问题,而不是HAC列分组算法的问题。
2.2 步骤
- 从图像中提取表格
- 应用OCR和文本本地化来生成文本边界框的(x,y)坐标。获得这些边界框坐标是至关重要的。
- 要将文本列关联在一起,需要根据文本的起始x坐标对文本片段进行分组。
观察表格、电子表格等的结构。每一列的文本都将具有几乎相同的起始x坐标,因为它们属于同一列。 - 利用这些知识,然后用几乎相同的x坐标将文本组聚在一起。使用一种称为层次聚集聚类(HAC)的特殊聚类算法。
- 采取“自下而上”的方法,从初始数据点(即文本边界框的x坐标)开始,作为单独的簇,每个簇只包含一个观测值。
然后计算坐标之间的距离,并开始将距离<T的观测值分组,其中T是预定义的阈值。
在HAC的每次迭代中,选择距离最小的两个集群,并在满足距离阈值要求的情况下再次合并它们。
继续集群,直到没有其他集群可以形成,通常是因为没有两个集群在阈值要求范围内。
在多列OCR的上下文中,将HAC应用于x坐标值会导致具有相同或接近相同x坐标的簇,因此可以将列关联在一起。(scikit-learn实现了HAC)
2.3 依赖
为了向终端显示一个格式良好的OCR文本表,需要利用tabulate包对表进行格式化。表格包仅用于显示目的,不会影响实际的多列OCR算法。也可以不用,注释掉其导入就好~
workon your_env_name # 可选 进入某个环境
pip install tabulate
3. 源码
# usage
# python multi_column_ocr.py --image imgs/joeball.jpg --output imgs/results.csv
# 多列表的OCR
# 将接受一个输入图像,检测数据表,提取数据表,然后将数据表中的行/列进行OCR关联。然后将数据输出为csv
# 示例图像是迈克尔·乔丹棒球卡的扫描图
# 导入必要的包
import argparse
import cv2
import imutils
import numpy as np
import pandas as pd # 使用pandas,因为它能够轻松构建和管理表格数据。
import pytesseract
from pytesseract import Output
from sklearn.cluster import AgglomerativeClustering # scikit-learn的凝聚式集群实现。将使用HAC将文本聚类到列中。
from tabulate import tabulate # 表格软件包将允许在执行OCR后将格式良好的数据表打印到终端。这个包是可选的,可以不安装,只需在稍后的实现中注释掉导入行和第178行即可。
# 绘制轮廓ID号
def draw_contour(image, c, i):
# 计算轮廓区域的中心,并绘制⭕代表中心
M = cv2.moments(c)
cX = int(M["m10"] / M["m00"])
cY = int(M["m01"] / M["m00"])
# 在图像上绘制轮廓数
cv2.putText(image, "".format(i + 1), (cX - 10, cY - 10), cv2.FONT_HERSHEY_SIMPLEX,
0.5, (0, 255, 255), 1)
cv2.drawContours(image, [c], 0, (255, 0, 0), 1)
# 返回绘制了轮廓数的图像
return image
# 构建命令行参数及解析
# --image 要进行识别多列表的图像
# --output 输出csv路径
# --min-conf 过滤弱文件检测值的置信度值
# --dist-thresh 应用HAC时的距离阈值截止值(以像素为单位);可能需要调整图像和数据集的此值
# --min-size 集群中被视为聚类的最小数据点数
# 正确设置--dist-thresh对于OCR多列数据至关重要,一定要尝试不同的值。
# 最重要的命令行参数是--dist-thresh和--min-size。应用HAC时,需要使用距离阈值截止。
# 如果您允许集群无限期地继续,HAC将在每次迭代中继续集群,直到您最终得到一个包含所有数据点的集群。相反,当没有两个群集的距离小于阈值时,可以应用距离阈值来停止群集过程。
# 需要检查正在使用的图像数据。如果表格数据每行之间有大量空白,那么可能需要增加--dist-thresh。否则如果每行之间的空白较少,--dist-thresh可能会相应减少。
# --min-size命令行参数也很重要。
# 在聚类算法的每次迭代中,HAC都会检查两个集群,每个集群可能包含多个数据点或仅包含一个数据点。如果两个簇之间的距离小于--dist-thresh,HAC将合并它们。
# 然而总是会有异常值、远离表的文本片段或图像中的噪声。如果Tesseract检测到此文本,则HAC将尝试对其进行聚类。但是,有没有办法防止结果中报告这些集群?
# 一种简单的方法是在HAC完成后检查给定集群内的文本数据点的数量。
# 在本例中,将设置--min size=2,这意味着如果集群≤其中有2个数据点,将其视为异常值并忽略它。
# 结果不太正确,建议首先进行调整--dist-thresh,在调整 --min-size=2
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=False, default='imgs/joeball.jpg',
help="path to input image to be OCR'd")
ap.add_argument("-o", "--output", required=False, default='imgs/result_5.csv',
help="path to output CSV file")
ap.add_argument("-c", "--min-conf", type=int, default=0,
help="minimum confidence value to filter weak text detection")
ap.add_argument("-d", "--dist-thresh", type=float, default=25.0,
help="distance threshold cutoff for clustering")
ap.add_argument("-s", "--min-size", type=int, default=2,
help="minimum cluster size (i.e., # of entries in column)")
args = vars(ap.parse_args())
# 设置了伪随机数生成器的种子。这样做是为了为检测到的每一列文本生成颜色(对于可视化目的很有用)。
np.random.seed(42)
# 加载输入图像转换为灰度图
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# # cv2.imshow("origin", image)
# # cv2.imshow("gray", gray)
# 接下来将提取大片文本区域,类似于护照提取
# 初始化一个矩形内核,其宽度约为其高度的5倍,
# 然后使用3x3高斯模糊平滑图像,
# 然后应用blackhat形态学算子用于寻找亮背景中的暗区域(在浅色背景上显示深色区域(即浅色背景上的深色文本)。
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (51, 11))
gray = cv2.GaussianBlur(gray, (3, 3), 0)
blackhat = cv2.morphologyEx(gray, cv2.MORPH_BLACKHAT, kernel)
# # cv2.imshow("gaussianBlur VS blackhat", np.hstack([gray, blackhat]))
# 计算黑帽图像的Scharr梯度算子,并缩放像素为[0,255]
grad = cv2.Sobel(blackhat, ddepth=cv2.CV_32F, dx=1, dy=0, ksize=-1)
grad = np.absolute(grad)
(minVal, maxVal) = (np.min(grad), np.max(grad))
grad = (grad - minVal) / (maxVal - minVal)
grad = (grad * 255).astype("uint8")
# 使用矩形内核执行闭合操作以缩小表中文本行之间的缝隙
# 应用Octus阈值算法对图像进行阈值化
# 以及膨胀算法扩大前景区域
grad = cv2.morphologyEx(grad, cv2.MORPH_CLOSE, kernel)
thresh = cv2.threshold(grad, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
# cv2.imshow("gradientSoberScharr VS thresh", np.hstack([grad, thresh]))
thresh = cv2.dilate(thresh, None, iterations=3)
# cv2.imshow("dilate", thresh)
# 检测阈值图像中的轮廓,并获取最大的——统计表格
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
# # 遍历排序后的轮廓,并绘制在图像上
# for (i, c) in enumerate(cnts):
# draw_contour(image, c, i)
# cv2.waitKey(0)
tableCnt = max(cnts, key=cv2.contourArea)
# 计算统计表格的边界框坐标,并从输入图像中提取表格
(x, y, w, h) = cv2.boundingRect(tableCnt)
table = image[y:y + h, x:x + w]
# 展示输入图像和提取的表格到屏幕上
cv2.imshow("Input", image)
cv2.imshow("Table", table)
cv2.waitKey(0)
# 已经有了统计表格,开始Ocr
# 将PSM模式设置为检测稀疏文本,然后在其中本地化文本
# 使用Tesseract计算表中每段文本的边界框位置。这里使用了--psm 6的,原因是当文本是单个统一的文本块时,这种特殊的页面分割模式工作得很好。
# 大多数数据表将是统一的(有几乎相同的字体和字号)
# 如果--psm 6不适合,可以尝试其他psm模式,
# Tesseract页面分割模式(psm)解释了:如何提高OCR准确性。具体来说建议看一看——psm 11检测稀疏文本——这种模式也适用于表格数据。
options = "--psm 6"
# 表示识别简体中文和英文。lang='chi_sim+eng'
results = pytesseract.image_to_data(
cv2.cvtColor(table, cv2.COLOR_BGR2RGB),
lang='chi_sim+eng',
config=options,
output_type=Output.DICT)
# 在应用OCR文本检测后,初始化两个列表:coords和ocrText。
# coords列表将存储文本边界框的(x,y)坐标,而ocrText将存储实际的OCR文本本身。
coords = []
ocrText = []
# 遍历单独的文本及位置结果
for i in range(0, len(results["text"])):
# 从当前结果中提取文本区域的边界框
x = results["left"][i]
y = results["top"][i]
w = results["width"][i]
h = results["height"][i]
# 提取OCR文本本事,及文本位置的置信度
text = results["text"][i]
conf = int(float(results["conf"][i]))
# if(str(text) == '|'):
# continue
# 过滤弱检测
if conf > args["min_conf"]:
# 更新边界框及文本列表
coords.append((x, y, w, h))
ocrText.append(text)
# 提取文本边界框的所有x坐标,设置y坐标为0
# 要应用HAC,需要一组输入向量(也称为“特征向量”)。输入向量必须至少是2-D,所以添加了一个包含值0的普通维度。
# 其次对y坐标值不感兴趣。只想在x坐标位置上聚集。因为具有类似x坐标的文本片段可能是表中某列的一部分。
xCoords = [(c[0], 0) for c in coords]
# 对坐标应用层次聚集聚类(HAC hierarchical agglomerative clustering)
# 将n_clusters设置为None,因为不知道要生成多少个集群-相反希望HAC自然形成集群,
# 并使用distance_threshold继续创建集群。一旦没有两个集群的距离小于--dist-thresh,就会停止集群处理。
# 使用曼哈顿距离函数。为什么不使用其他距离函数(如欧几里德函数)?
# 虽然你可以尝试距离指标,但曼哈顿往往是一个合适的选择。因为对x坐标的要求非常严格。
clustering = AgglomerativeClustering(
n_clusters=None,
affinity="manhattan",
linkage="complete",
distance_threshold=args["dist_thresh"])
clustering.fit(xCoords)
# 初始化一个列表以存储排序后的聚类
sortedClusters = []
print('labels: ', len(np.unique(clustering.labels_)), np.unique(clustering.labels_))
# 遍历所有集群
for l in np.unique(clustering.labels_):
# 提取属于当前集群的坐标点的下标
idxs = np.where(clustering.labels_ == l)[0]
# 验证集群点是否足够大
if len(idxs) > args["min_size"]:
# 计算集群的平均x坐标值
# 更新当前集群标签的平均x值
avg = np.average([coords[i][0] for i in idxs])
sortedClusters.append((l, avg))
# 根据平均x值排序,并初始化dataFrame以存储ocr列表
# 执行此排序操作,以便在整个页面上从左到右对集群进行排序。
sortedClusters.sort(key=lambda x: x[1])
df = pd.DataFrame()
# 遍历排序过的所有集群
for (l, _) in sortedClusters:
# 提取属于当前集群的点的下标
idxs = np.where(clustering.labels_ == l)[0]
# 使用索引,从集群中的所有文本片段中提取y坐标,并从上到下排序
yCoords = [coords[i][1] for i in idxs]
sortedIdxs = idxs[np.argsort(yCoords)]
# 为当前列初始化一个随机颜色
color = np.random.randint(0, 255, size=(3,), dtype="int")
color = [int(c) for c in color]
# 遍历排序后的下标
for i in sortedIdxs:
# 提取文本的边界框坐标,给当前元素绘制边界框
(x, y, w, h) = coords[i]
cv2.rectangle(table, (x, y), (x + w, y + h), color, 2)
# 提取当前列OCR的文本,构建dataFrame存储数据,第一个条目存储标头
cols = [ocrText[i].strip() for i in sortedIdxs]
currentDF = pd.DataFrame(cols[0]: cols[1:])
# 连接原始数据和当前数据frame(做此操作防止表格有随机行)
df = pd.concat([df, currentDF], axis=1)
# 替换NaN值为空字符串,然后对多列表Ocr文本进行一个友好的格式化输出
# 如果某些列的条目比其他列多,则空条目将用“Not a Number”(NaN)值填充。
df.fillna("", inplace=True)
print(tabulate(df, headers="keys", tablefmt="psql"))
# 将表格写入csv文件到磁盘
print("[INFO] saving CSV file to disk...")
df.to_csv(args["output"], index=False)
# 展示执行多列表Ocr的输出图片
cv2.imshow("Output", image)
cv2.waitKey(0)
参考
- https://pyimagesearch.com/2022/02/28/multi-column-table-ocr/
- https://scikit-learn.org/stable/modules/generated/sklearn.cluster.AgglomerativeClustering.html
以上是关于使用Tesseract OCR引擎和层次聚集聚类(HAC)对多列数据进行OCR的主要内容,如果未能解决你的问题,请参考以下文章