Redis详细教程入门
Posted Mr.zhou_Zxy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis详细教程入门相关的知识,希望对你有一定的参考价值。
Redis
1 互联网架构演变
1.1 单一数据库
在90年代,由于互联网没有普及。一个网站访问量并不大,单一数据库完全能够满足访问的需求。因为在哪个年下几乎都是静态的页面,动态交互型的功能不多。
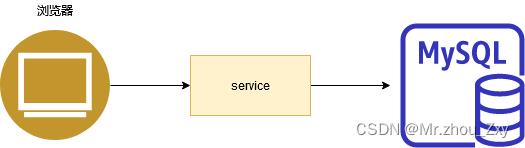
1.2 Memcached + 数据库 + 垂直拆分
当数据量达到一定级别,一个机器总有存放不下的时候、数据索引的时候单台机器的内存可能也不够。架构就发生了改变。
最快速的提升查询性能的方式就是使用缓存技术、第二也需要去优化数据库:表结构建立索引、优化表的机构(垂直拆分:将一个表拆分为多个表)。
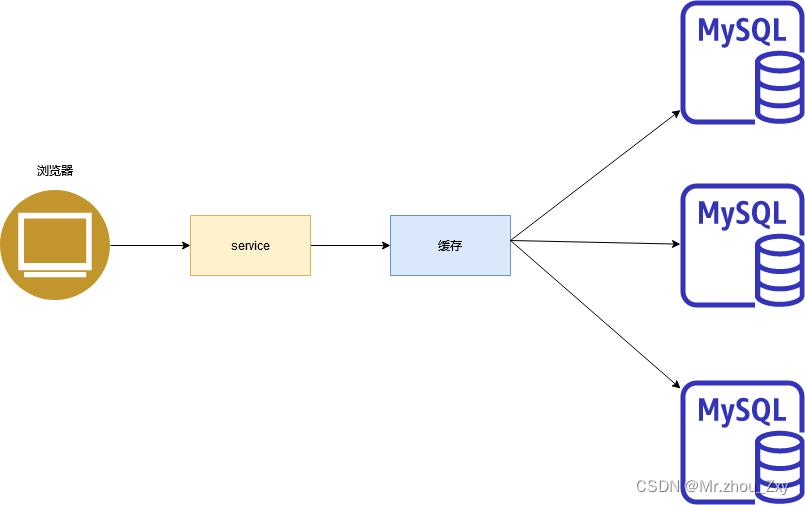
1.3 主从复制 + 读写分离
再向后面发展,进入到互联网时代的初期,互联网的产品对于读的压力特别大,我们传统的架构都是读写放在一起的,我们就将写集中在主上,释放素有的从机的来处理读压力。所以大部分的网站还是使用主从复制,读写分离。

1.4 分表分库 + 水平拆分 + mysql的集群模式
随着互联网时代从初期过渡完毕,我们数据量开始产生激增。上面的架构已经无法胜任海量数据的存储和查询。架构进一步采取了演变。水平拆分:(将表的行拆分),因为一张表的数据达到超过200w行的时候,性能势必直线下降。
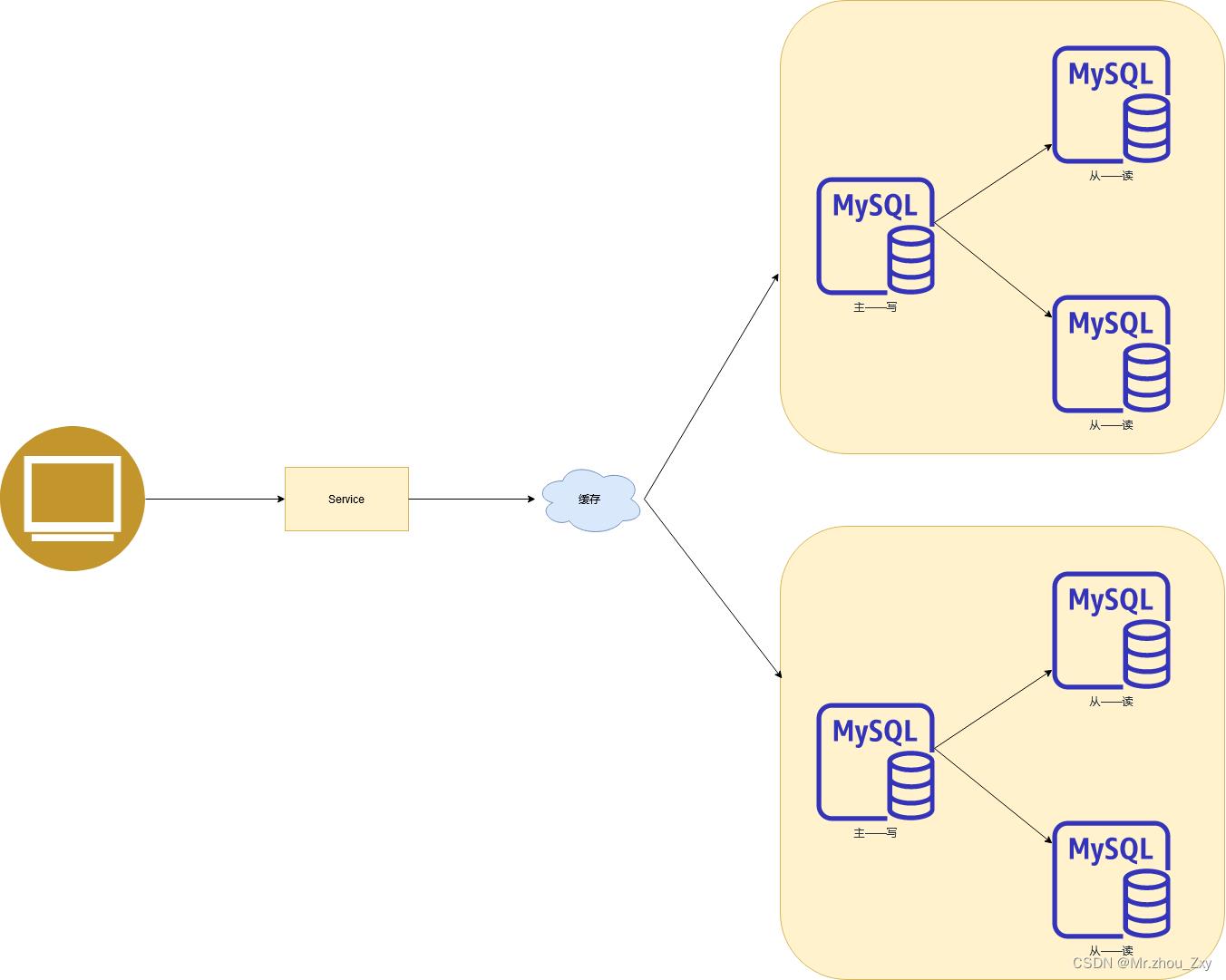
1.5 慢慢发展到了移动互联——大数据年代了

2 Nosql
2.1 为什么Nosql
因为随着互联网行业的发展,数据量激增,传统的RDBMS由于自身性能的瓶颈,不适合作为大数据领域的存储工具。比如,一般的用户行为操作等等的这些日志,又多又没有规则,如mysql这样的数据库更适合存放结构化数据,所以传统数据不适合大数据领域。
Nosql:Not only sql。他非常符合海量数据下的快速查询的要求。
2.2 Nosql种类
种类非常多,但是有一个共同的特点就是一定是去除了RDBMS中的关系表达。不适用SQL。
- Memcached
- Redis
- HBase
- MongoDB
- ClickHouse
…
- 大数据时代3V+3高
- Volume : 海量
- Variety : 多样
- velocity :实时
----------------------
- 高并发
- 高可扩
- 高性能
3 阿里架构演变
1999 第一代架构: Perl,CGI,Oracle
2000 第二代架构:Java, Servlet
2001-2004第三代架构:EJB时代,Dao、Service
2005-2007第四代架构:去EJB重构:Spring+iBatis+Webx。底层架构:iSearch,MQ+ESB,数据挖掘
2008-2009第五代架构:Memcached集群 + mysql + 数据切分, 分布式存储,Hadoop,KV, CDN
2010安全,镜像:安全、镜像、应用服务器升级、秒杀、Nosql、SSD
…
敏捷开发、开放式开发、用户体验
4 Redis
4.1 介绍
Remote Dictionary Server。开源,基于C语言开发,基于BSD协议(只要基于这个协议的都可以修改源码)的KV的Nosql的分布式数据库。
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。
它支持多种类型的数据结构,如
字符串(strings),
散列(hashes),
列表(lists),
集合(sets),
有序集合(sorted sets) 与范围查询,
bitmaps,
hyperloglogs 和
地理空间(geospatial) 索引半径查询。
Redis 内置了
复制(replication),LUA脚本(Lua scripting),
LRU驱动事件(LRU eviction),事务(transactions)
和不同级别的
磁盘持久化(persistence),
并通过
Redis哨兵(Sentinel)和自动
分区(Cluster)提供高可用性(high availability)。
4.2 redis的特点
- redis支持数据的持久化:AOF和RDB
- redis本身不仅仅只是KV的数据,还支持多种数据结构:List、Set、Hash…
- redis支持数据的备份。主从
4.3 做什么
- 内存存储和持久化
- 取最新的数据
- 单点登陆——模拟HttpSession
- 计数器/定时器
- 保持offset
4.4 网址
http://www.redis.cn/
https://www.redis.net.cn/
4.5 安装
##1. 安装
[root@hadoop ~]# yum -y install gcc-c++
[root@hadoop software]# tar -zxvf redis-3.2.8.tar.gz -C /opt/apps/
[root@hadoop redis-3.2.8]# make
[root@hadoop redis-3.2.8]# make PREFIX=/opt/apps/redis-3.2.8/bin install
##2. 配置环境变量
4.6 启动
4.6.1 默认的连接
##1. 启动前台服务
[root@hadoop bin]# ./redis-server
##2. 启动客户端
[root@hadoop ~]# redis-cli
4.6.2 后台启动,使用配置连接
##1. 配置后端启动
[root@hadoop redis-3.2.8]# cp redis.conf redis.conf.bak
[root@hadoop redis-3.2.8]# vi redis.conf
bind 0.0.0.0
port 6379
daemonize yes
##2. 启动redis的服务
[root@hadoop redis-3.2.8]# redis-server redis.conf
[root@hadoop redis-3.2.8]# ps -ef | grep redis
root 4196 1 0 16:52 ? 00:00:00 redis-server 0.0.0.0:6379
root 4325 30685 0 16:53 pts/0 00:00:00 grep --color=auto redis
##3. 客户端连接redis服务
[root@hadoop redis-3.2.8]# ./redis-cli -h 127.0.0.1 -p 6379
# 如果有密码,则需要通过auth 指定密码
[root@hadoop redis-3.2.8]# auth password
4.7 redis.conf
详细的参考:Redis的配置文件解读(redis.conf)
4.7.1 INCLUDES
# Redis configuration file example.
#
# 启动redis服务的时候必须按照一下的方式启动
# ./redis-server /path/to/redis.conf
################################## INCLUDES ###################################
# 通过一个注册配置文件去include你自定义的其他的配置文件,参考我们openresty的用法
#
# include /path/to/local.conf
# include /path/to/other.conf
4.7.2 NETWORK
################################## NETWORK #####################################
# 绑定你的redis-server的可访问的ip地址
# bind 127.0.0.1
bind 0.0.0.0
# 开启保护模式,目的是为了其他的客户端不能够非法的访问我的redis服务
# yes/no
protected-mode yes
# 配置redis-server的端口号
port 6379
# TCP listen() backlog.
#
# 当redis-server面临高并发的时候,它将一部分的连接请求存入backlog的日志中,从而避免高积压。
tcp-backlog 511
# Unix socket.
#
# 配置显示的显示出redis服务的socket的配置文件,如果没有配置,就没有这个文件
#
# unixsocket /tmp/redis.sock
# unixsocketperm 700
# 服务端和客户端断开连接的最大的超时时间
timeout 0
# 配置每隔5分钟汇报一次当前服务端的情况
tcp-keepalive 300
4.7.3 通用
################################# GENERAL #####################################
# 开启后台启动
daemonize yes
# 如果你使用了外部组件(supervisord)来控制你的redis的启动,你就要选择这个下面的选项来控制
# supervision tree. Options:
# supervised no - no supervision interaction
# supervised upstart - signal upstart by putting Redis into SIGSTOP mode
# supervised systemd - signal systemd by writing READY=1 to $NOTIFY_SOCKET
# supervised auto - detect upstart or systemd method based on
# UPSTART_JOB or NOTIFY_SOCKET environment variables
# Note: these supervision methods only signal "process is ready."
# They do not enable continuous liveness pings back to your supervisor.
supervised no
# redis-server的进程文件的生成路径
pidfile /var/run/redis_6379.pid
# 指定你的日志级别:从以下4种模式种选择
# debug 最多日志的提示,一般在开发环境下使用
# verbose 在测试环境下可以使用这个模式
# notice 日志提示相对较少,一般只提示一些启动关闭等等关键的信息,一般在生产环境中使用
# warning 只有非常重要的日志才会被记录
loglevel notice
# 指定redis-server的日志的路径
logfile ""
# 设置你的数据库的数量
databases 16
4.7.4 SECURITY
################################## SECURITY ###################################
# Require clients to issue AUTH <PASSWORD> before processing any other
# commands. This might be useful in environments in which you do not trust
# others with access to the host running redis-server.
#
# This should stay commented out for backward compatibility and because most
# people do not need auth (e.g. they run their own servers).
#
# Warning: since Redis is pretty fast an outside user can try up to
# 150k passwords per second against a good box. This means that you should
# use a very strong password otherwise it will be very easy to break.
# 通过requirepass 指定密码
requirepass redis6379
# Command renaming.
#
# It is possible to change the name of dangerous commands in a shared
# environment. For instance the CONFIG command may be renamed into something
# hard to guess so that it will still be available for internal-use tools
# but not available for general clients.
#
4.7.5 Redis的第一种持久化方式-快照 -RDB
################################ SNAPSHOTTING ################################
#
# 将数据库保存在磁盘的策略:RDB
# 以下配置含义:
# 900秒(15分钟)完成了至少一次写操作,就将数据保存在磁盘
# 300秒(5分钟)完成了至少10此写操作
# 1分钟之内至少完成10000此写操作
save 900 1
save 300 10
save 60 10000
# 配置的作用是,当你的后台RDB进行日志持久化的时候,如果持久化快照失败了,你的redis的服务将不再允许继续进# 行数据保存。因为普通状态下我们的开发者很难观察到日志快照失败,它通过停止写操作来强制使开发者注意到日志# # 保存失效的。
# 如果你的日志又可以保存成功的情况下,自动允许写入。如果你有第三方监控工具监控redis的日志情况,你也可以关# 闭此选项。
stop-writes-on-bgsave-error yes
# 设置使用LZF算法对持久化数据进行压缩,但是压缩会非常消耗CPU性能,但是文件的体积可以得到缩减
rdbcompression yes
# 在压缩完成之后,redis还恶意使用CRC64算法校验你保存的文件完整性。但是这个做法会让你多牺牲10%性能。
rdbchecksum yes
# 持久化的文件的名称
dbfilename dump.rdb
# 持久化文件的路径
dir /opt/apps/redis-3.2.8
4.7.5 主从复制读写分离
- 配置文件
################################# REPLICATION #################################
250
251 # 这个命令使用于连接redis服务中的主节点的命令
265 # slaveof <masterip> <masterport>
266
267 # 使用主机授权
272 # masterauth <master-password>
273
274 # 当你的从机连接主机做主从复制的时候,如果失败。yes的策略将会使slave重新向master请求;no的策略发送 # 要给错误信息给主
slave-serve-stale-data yes
286
287 # 配置主从复制,读写分离。从机只读
301 slave-read-only yes
302
303 # 同步策略:本地磁盘同步,无盘同步:Socket
309 # yes:表示使用无盘同步,no表示有磁盘同步
332 repl-diskless-sync no
333
334 # 当开启无盘同步配置的最大的延迟时间(秒)
344 repl-diskless-sync-delay 5
345
363
364 # Disable TCP_NODELAY on the slave socket after SYNC?
365 #
366 # 配置从机延迟带宽。yes的时候,会减少带宽这将增加从机的数据延迟度。no的话就会降低从机的数据延迟。但是选择yes的好处是我们将主从复制的带宽减少,这些带宽更多的是用于写操作。所以当你的集群面对海量的数据写入的时候,选择yes是一个good idea
377 repl-disable-tcp-nodelay no
378
379 #
389 # 配置的是当你的从机断开了与主机连接,从机一旦断开连接,这个从机重启之后就没有主机的数据了。这个时候从机需要重新同步,但是由于我们之前同步过,如果每次都要从头再来,成本太大了。backlog,我们可以通过这个backlog进行同步恢复,通过它,我只需要同步我宕机之后的那一部分新的数据。
390 # repl-backlog-size 1mb
391
392 # After a master has no longer connected slaves for some time, the backlog
393 # will be freed. The following option configures the amount of seconds that
# will be freed. The following option configures the amount of seconds that
394 # need to elapse, starting from the time the last slave disconnected, for
395 # the backlog buffer to be freed.
396 #
397 # A value of 0 means to never release the backlog.
398 #
399 # repl-backlog-ttl 3600
400
416 # It is possible for a master to stop accepting writes if there are less than
417 # N slaves connected, having a lag less or equal than M seconds.
418 #
419 # The N slaves need to be in "online" state.
420 #
421 # The lag in seconds, that must be <= the specified value, is calculated from
422 # the last ping received from the slave, that is usually sent every second.
423 #
424 # This option does not GUARANTEE that N replicas will accept the write, but
425 # will limit the window of exposure for lost writes in case not enough slaves
426 # are available, to the specified number of seconds.
427 #
428 # For example to require at least 3 slaves with a lag <= 10 seconds use:
429 #
430 # min-slaves-to-write 3
431 # min-slaves-max-lag 10
432 #
433 # Setting one or the other to 0 disables the feature.
434 #
435 # By default min-slaves-to-write is set to 0 (feature disabled) and
436 # min-slaves-max-lag is set to 10.
437
438 # A Redis master is able to list the address and port of the attached
439 # slaves in different ways. For example the "INFO replication" section
440 # offers this information, which is used, among other tools, by
441 # Redis Sentinel in order to discover slave instances.
442 # Another place where this info is available is in the output of the
443 # "ROLE" command of a masteer.
444 #
445 # The listed IP and address normally reported by a slave is obtained
446 # in the following way:
447 #
448 # IP: The address is auto detected by checking the peer address
449 # of the socket used by the slave to connect with the master.
450 #
451 # Port: The port is communicated by the slave during the replication
452 # handshake, and is normally the port that the slave is using to
453 # list for connections.
454 #
455 # However when port forwarding or Network Address Translation (NAT) is
456 # used, the slave may be actually reachable via different IP and port
457 # pairs. The following two options can be used by a slave in order to
458 # report to its master a specific set of IP and port, so that both INFO
459 # and ROLE will report those values.
460 #
461 # There is no need to use both the options if you need to override just
462 # the port or the IP address.
463 #
464 # slave-announce-ip 5.5.5.5
465 # slave-announce-port 1234
- 操作演示
##1. 在一台机器上创建3个redis.conf的配置文件,分别修改他们的端口、日志、pid文件
##2. 分别启动他们
[root@hadoop redis-3.2.8]# redis-server redis6379.conf
[root@hadoop redis-3.2.8]# redis-server redis6380.conf
[root@hadoop redis-3.2.8]# redis-server redis6381.conf
##3. 使用3个客户端分别连接到3个不同的服务端
[root@hadoop redis-3.2.8]# redis-cli -p 6379
[root@hadoop redis-3.2.8]# redis-cli -p 6380
[root@hadoop redis-3.2.8]# redis-cli -p 6381
##4. 查看各个客户端连接到服务端,服务端的状态
127.0.0.1:6379> INFO REPLICATION
# Replication
role:master
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6380> INFO REPLICATION
# Replication
role:master
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6381> INFO REPLICATION
# Replication
role:master
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
##5. 设置主从:一主二仆
127.0.0.1:6380> SLAVEOF hadoop 6379
OK
127.0.0.1:6381> SLAVEOF hadoop 6379
OK
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6381,state=online,offset=43,lag=0
slave1:ip=127.0.0.1,port=6380,state=online,offset=43,lag=0
master_repl_offset:43
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:42
127.0.0.1:6380> INFO REPLICATION
# Replication
role:slave
master_host:hadoop
master_port:6379
master_link_status:up
master_last_io_seconds_ago:4
master_sync_in_progress:0
slave_repl_offset:85
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6381> INFO REPLICATION
# Replication
role:slave
master_host:hadoop
master_port:6379
master_link_status:up
master_last_io_seconds_ago:2
master_sync_in_progress:0
slave_repl_offset:141
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
##6. 演示主从复制,读写分离
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> get k1
"v1"
127.0.0.1:6381> get k1
"v1"
127.0.0.1:6381> set k2 v2
(error) READONLY You can't write against a read only slave.
- slave --》 master
当我们master挂掉的时候,从机会一直尝试连接master。但是如果master一直没有回来,群龙无首,关键写操作只有master才能够操作,所以如果一直保持这个样子,你的集群将不能写入数据。所以我们需要将从机转换位为主机。
- 演示
##1. 切换6381成为新的master
127.0.0.1:6381> SLAVEOF no one ## 将当前从机重新定义为新的master
OK
127.0.0.1:6381> info replication
# Replication
role:master
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6381>
##2. 6380重新以6381为master
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:hadoop
master_port:6381
master_link_status:up
master_last_io_seconds_ago:6
master_sync_in_progress:0
slave_repl_offset:1
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
-
自动故障转移——哨兵模式
作用就是监控master,一旦主机宕机,就会从已有的从机中投票选举一个作为新的master。整个过程自动完成。
-
操作
##1. 配置
[root@hadoop redis-3.2.8]# mkdir conf
[root@hadoop redis-3.2.8]# vi conf/sentinel.conf
sentinel monitor mymaster hadoop 6381 1
##2. 启动哨兵
[root@hadoop redis-3.2.8]# redis-sentinel conf/sentinel.conf
4.7.6 Redis的第二种持久化方式-AOF
############################## APPEND ONLY MODE ###############################
# AOF的持久化方式是它通过将所有的向redis的写操作记录到日志中的形式来帮助我们进行数据的恢复。我可以每1秒种记录一次,也可以每一次写操作都记录。但是这个模式默认是关闭的,所以我们需要手动的开启。在生产环境中我们一般都是RDB和AOF一起配合使用。
appendonly yes
# 指定AOF的日志文件名称
appendfilename "appendonly.aof"
# 配置AOF同步日志的策略
# appendfsync always ## 每一次写操作都记录日志
appendfsync everysec ## 每一秒中记录日志
# appendfsync no ## 不记录
4.8 Redis的五大类型
4.8.1 类型
- string:redis的string的单个值最大只能存储512M
- hash:类似于java中的map
- list:列表,按照插入顺序进行排序。列表有两头,两头都可以查。
- set:集合,他其实hashtable实现。无序不重复
- zset:有序集合。有序(不是插入顺序)不重复
4.8.2 string
- API
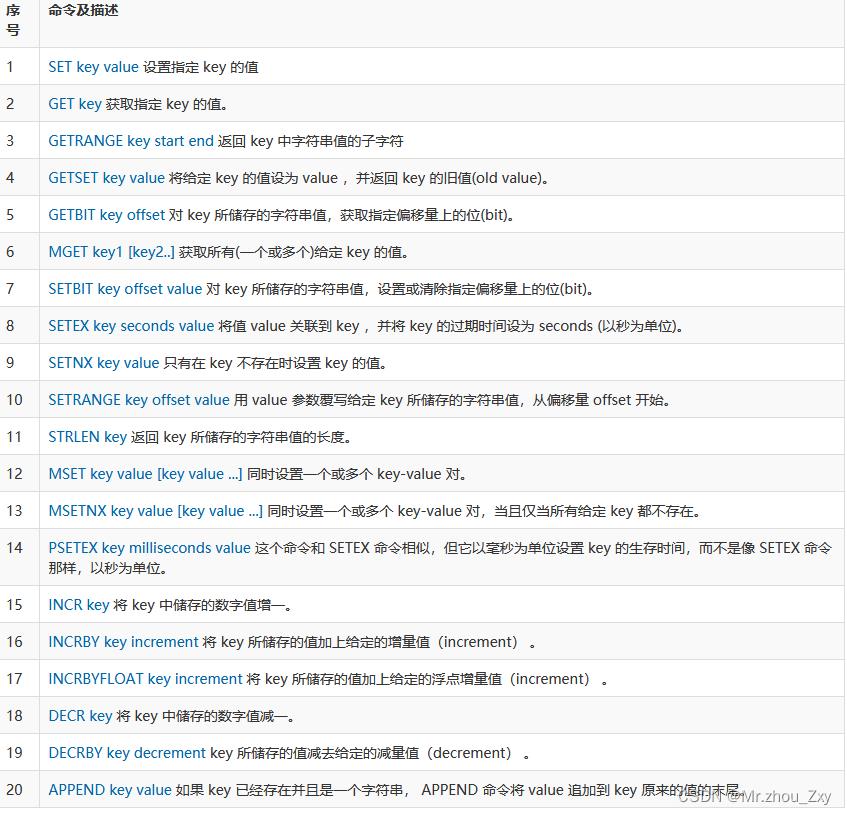
- 测试
##1. set
127.0.0.1:6379> set k1 v1
OK
##2. get
127.0.0.1:6379> get k1
"v1"
##3. GETRANGE 获取指定的key的value的子串
127.0.0.1:6379> GETRANGE k2 0 1
"wu"
##4. KEYS : 将库中的所有的key查询罗列
127.0.0.1:6379> KEYS *
1) "k1"
2) "k2"
##5. GETSET : 先获取旧值,然后将新值覆盖旧值
127.0.0.1:6379> GETSET k2 v2
"wuliji"
127.0.0.1:6379> GET k2
"v2"
##6. GETBIT : 根据key获取指定的value的bit位的偏移量上的值(0,1)
127.0.0.1:6379> GETBIT k2 7
(integer) 0
##7. MGET key1 [key2..] : 获取多个key的值
127.0.0.1:6379> MGET k1 k2
1) "v1"
2) "v2"
##8. SETBIT key offset value : 修改指定key上的value的bit位的值
##9. SETEX key seconds value : 设置key的值并指定过期时间
127.0.0.1:6379> SETEX k3 5 v3
OK
127.0.0.1:6379> get k3
"v3"
127.0.0.1:6379> get k3
(nil)
##10. SETNX key value : 如果值不存在就设置
127.0.0.1:6379> SETNX k4 v4
(integer) 1
127.0.0.1:6379> get k4
"v4"
127.0.0.1:6379> SETNX k4 v5
(integer) 0
127.0.0.1:6379> get k4
"v4"
##11. SETRANGE key offset value
127.0.0.1:6379> set k5 vvv555
OK
127.0.0.1:6379> get k5
"vvv555"
127.0.0.1:6379> SETRANGE k5 3 666
(integer) 6
127.0.0.1:6379> get k5
"vvv666"
##12. STRLEN key : 查看key对应的value的长度
127.0.0.1:6379> STRLEN k5
(integer) 6
##13. MSET key value [key value ...]
127.0.0.1:6379> MSET k6 v6 k7 v7
OK
127.0.0.1:6379> MGET k6 k7
1) "v6"
2) "v7"
##14. MSETNX key value [key value ...]
127.0.0.1:6379> MSETNX k6 v888 k9 v9
(integer) 0
127.0.0.1:6379> MGET k6 k9
1) "v666"
2) (nil)
##15. PSETEX key milliseconds value
127.0.0.1:6379> PSETEX k10 5000 v10
OK
127.0.0.1:6379> get k10
"v10"
127.0.0.1:6379> get k10
(nil)
##16. INCR key 自增值
127.0.0.1:6379> INCR k1
(integer) 1
127.0.0.1:6379> INCR k1
(integer) 2
127.0.0.1:6379> INCR k1
(integer) 3
127.0.0.1:6379> SET k2 v2
OK
127.0.0.1:6379> INCR k2
(error) ERR value is not an integer or out of range
##17. INCRBY key increment
127.0.0.1:6379> INCRBY k3 10
(integer) 10
127.0.0.1:6379> INCRBY k3 10
(integer) 20
127.0.0.1:6379> INCRBY k3 10
(integer) 30
##18. INCRBYFLOAT key increment
127.0.0.1:6379> INCRBYFLOAT k4 1.1
"1.1"
127.0.0.1:6379> INCRBYFLOAT k4 1.1
"2.2"
127.0.0.1:6379> INCRBYFLOAT k4 1.1
"3.3"
##19. DECR key
127.0.0.1:6379> DECR k1
(integer) 2
127.0.0.1:6379> DECR k1
(integer) 1
##20. APPEND key value
127.0.0.1:6379> APPEND k1 lixi
(integer) 5
127.0.0.1:6379> get k1
"1lixi"
4.8.3 key
- API
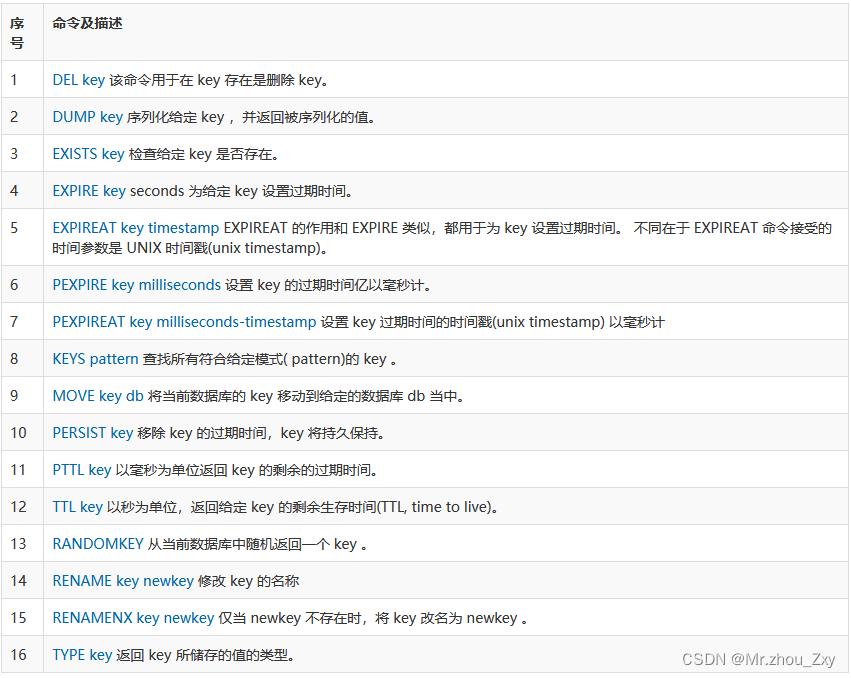
- 测试
##1. DEL :删除key
127.0.0.1:6379> DEL k4
(integer) 1
127.0.0.1:6379> KEYS *
1) "k1"
2) "k3"
3) "k2"
##2. DUMP : 将key值序列化展示
127.0.0.1:6379> DUMP k1
"\\x00\\x051lixi\\a\\x00\\x80j\\xfa\\xaa\\xb3\\xda\\x89"
##3. MOVE key db 将当前库的key移动到指定的库中
127.0.0.1:6379> KEYS *
1) "k1"
2) "k3"
3) "k2"
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]> KEYS *
(empty list or set)
127.0.0.1:6379[1]> select 0
OK
127.0.0.1:6379> MOVE k1 1
(integer) 1
127.0.0.1:6379> SELECT 1
OK
127.0.0.1:6379[1]> KEYS *
1) "k1"
##4. PTTL/TTL : 设置key的过期时间
127.0.0.1:6379[1]> EXPIRE k1 120
(integer) 1
127.0.0.1:6379[1]> TTL k1
(integer) 95
127.0.0.1:6379[1]> TTL k1
(integer) 94
127.0.0.1:6379[1]> TTL k1
(integer) 93
127.0.0.1:6379[1]> PTTL k1
(integer) 90554
127.0.0.1:6379[1]>
4.8.4 list
- API
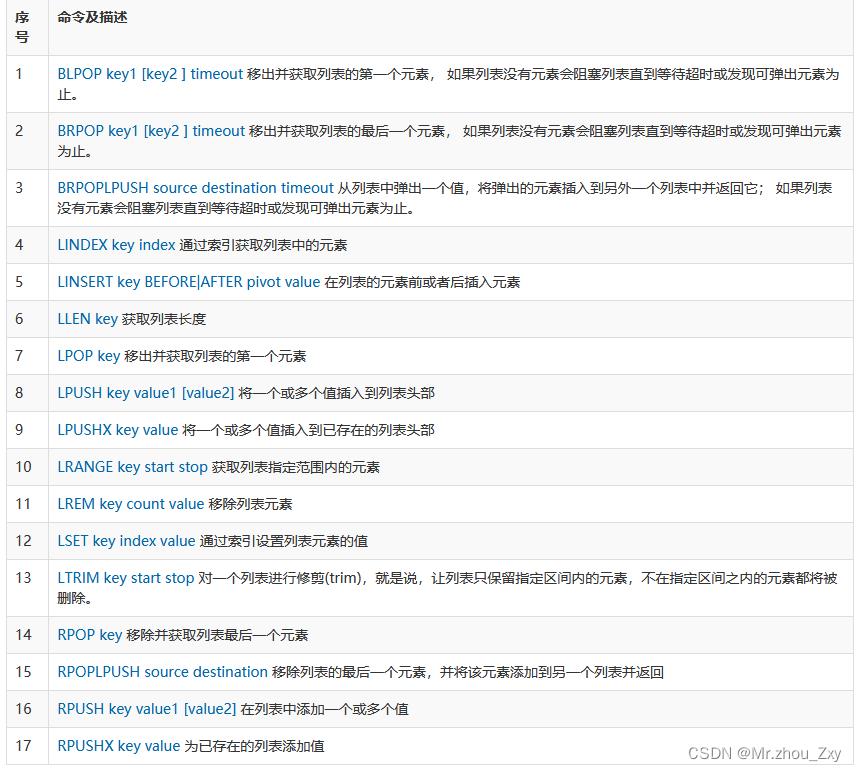
- 测试
##1. LPOP/RPOP : 从列表的左/右弹数据出来
127.0.0.1:6379> LPOP list1
"5"
127.0.0.1:6379> RPOP list1
"1"
##2. LPUSH/RPUSH :左/右推数据到列表,没有右推
127.0.0.1:6379> LPUSH list1 1 2 3 4 5
(integer) 5
127.0.0.1:6379> KEYS *
1) "list1"
##3. LRANGE : 从左边获取到数据
127.0.0.1:6379> LRANGE list1 0 2
1) "4"
2) "3"
3) "2"
##4. LINDEX : 获取到指定索引的单个元素
127.0.0.1:6379> LINDEX list1 0
"4"
127.0.0.1:6379> LINDEX list1 2
"2"
127.0.0.1:6379> LINDEX list1 -1
"2"
127.0.0.1:6379> LINDEX list1 -2
"3"
##5. BLPOP/BRPOP : 从左/右弹出第一个列表的元素,如果第一个列表没有,就弹出第二个列表的元素
127.0.0.1:6379> BLPOP list2 list1 1
1) "list2"
2) "5"
127.0.0.1:6379> BLPOP list1 list2 1
1) "list1"
2) "2"
127.0.0.1:6379> BLPOP list1 list2 1
1) "list2"
2) "4"
127.0.0.1:6379> BLPOP list1 list2 1
1) "list2"
2) "3"
127.0.0.1:6379> BLPOP list1 list2 1
1) "list2"
2) "2"
##6. BRPOPLPUSH
127.0.0.1:6379> BRPOPLPUSH list2 list3 1000
"1"
127.0.0.1:6379> LRANGE list2 0 -1
(empty list or set)
127.0.0.1:6379> LRANGE list3 0 -1
1) "1"
##7. LREM : 删除列表中的指定的元素
127.0.0.1:6379> LPUSH list3 1 1 1 1 1 2 2 2 2 1 1 1 3 1 3 1 3
(integer) 30
127.0.0.1:6379>
127.0.0.1:6379> LRANGE list3 0 -1
1) "3"
2) "1"
3) "3"
4) "1"
5) "3"
6) "1"
7) "1"
8) "1"
9) "2"
10) "2"
11) "2"
12) "2"
13) "1"
14) "1"
15) "1"
16) "1"
17) "1"
18) "3"
19) "3"
20) "3"
21) "2"
22) "2"
23) "2"
24) "2"
25) "1"
26) "1"
27) "1"
28) "1"
29) "1"
30) "1"
127.0.0.1:6379> LREM list3 5 1
(integer) 5
127.0.0.1:6379> LRANGE list3 0 -1
1) "3"
2) "3"
3) "3"
4) "2"
5) "2"
6) "2"
7) "2"
8) "1"
9) "1"
10) "1"
11) "1"
12) "1"
13) "3"
14) "3"
15) "3"
16) "2"
17) "2"
18) "2"
19) "2"
20) "1"
21) "1"
22) "1"
23) "1"
24) "1"
25) "1"
##8. LSET 向指定索引处替换值
127.0.0.1:6379> LSET list3 1 666
OK
127.0.0.1:6379> LRANGE list3 0 -1
1) "3"
2) "666"
3) "3"
4) "2"
5) "2"
6) "2"
7) "2"
8) "1"
9) "1"
10) "1"
11) "1"
12) "1"
13) "3"
14) "3"
15) "3"
16) "2"
17) "2"
18) "2"
19) "2"
20) "1"
21) "1"
22) "1"
23) "1"
24) "1"
25) "1"
##9. LTRIM 保留指定区间的元素
127.0.0.1:6379> LTRIM list3 3 6
OK
127.0.0.1:6379> LRANGE list3 0 -1
1) "2"
2) "2"
3) "2"
4) "2"
4.8.5 set
- API
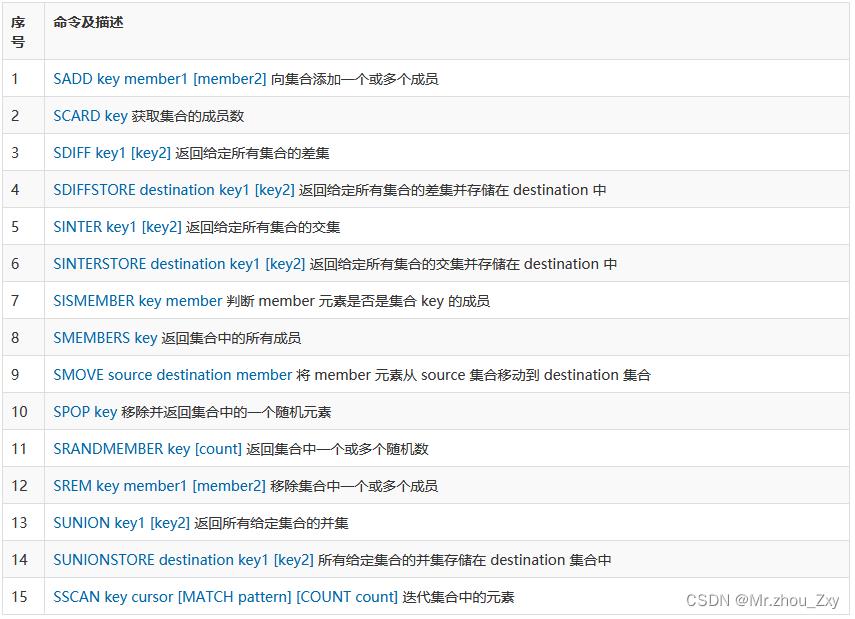
- 测试
##1. SADD key member1 [member2] 向集合添加一个或多个成员
127.0.0.1:6379> SADD set1 1 2 3 4 5 1 2 6
(integer) 6
##2. SCARD key 获取集合的成员数
127.0.0.1:6379> SCARD set1
(integer) 6
##3. SMEMBERS key 返回集合中的所有成员
127.0.0.1:6379> SMEMBERS set1
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
##4. SISMEMBER key member 判断 member 元素是否是集合 key 的成员
127.0.0.1:6379> SISMEMBER set2 6
(integer) 1
127.0.0.1:6379> SISMEMBER set2 0
(integer) 0
##5. SMOVE source destination member 将 member 元素从 source 集合移动到 destination 集合
127.0.0.1:6379> SMOVE set2 set3 2
(integer) 1
127.0.0.1:6379> SMEMBERS set3
1) "2"
##6. 交集
127.0.0.1:6379> SINTER set1 set3
1) "2"
##7. 并集
127.0.0.1:6379> SUNION set1 set4
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "7"
8) "9"
##8. 差集
127.0.0.1:6379> SDIFF set2 set3
1) "1"
2) "3"
3) "4"
4) "5"
5) "6"
127.0.0.1:6379> SDIFF set3 set2
(empty list or set)
4.8.6 Hash
- API
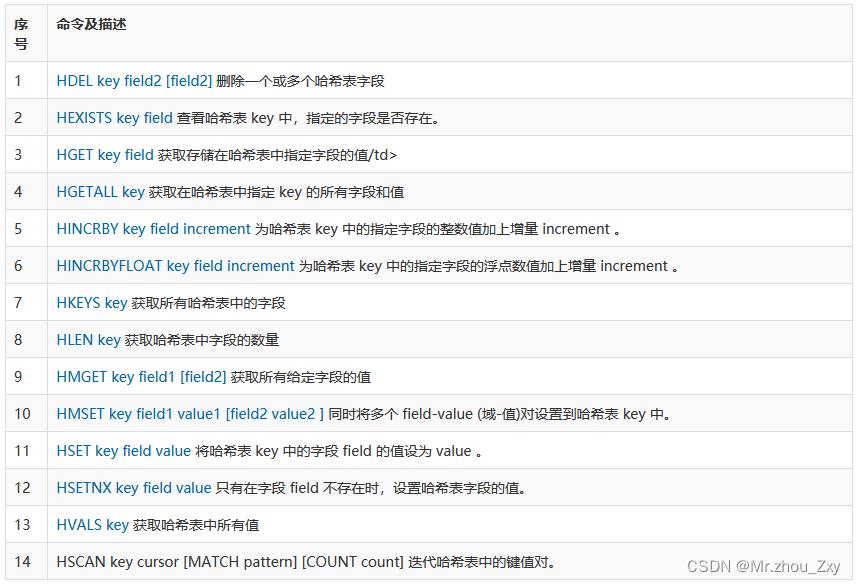
- 测试
##1. HSET key field value 将哈希表 key 中的字段 field 的值设为 value 。
127.0.0.1:6379> HSET p1 name wuliji
(integer) 1
127.0.0.1:6379> HSET p1 sex man
(integer) 1
127.0.0.1:6379> HSET p1 age 18
(integer) 1
##2. HGET key field 获取存储在哈希表中指定字段的值
127.0.0.1:6379> HGET p1 name
"wuliji"
127.0.0.1:6379> HGET p1 sex
"man"
##3. HGETALL key 获取在哈希表中指定 key 的所有字段和值
127.0.0.1:6379> HGETALL p1
1) "name"
2) "wuliji"
3) "sex"
4) "man"
5) "age"
6) "18"
##4. HDEL key field2 [field2] 删除一个或多个哈希表字段
127.0.0.1:6379> HDEL p1 sex age
(integer) 2
127.0.0.1:6379> HGET p1 sex
(nil)
##5. HINCRBY key field increment 为哈希表 key 中的指定字段的整数值加上增量 increment 。
127.0.0.1:6379> HINCRBY p1 age 2
(integer) 2
127.0.0.1:6379> HINCRBY p1 age 2
(integer) 4
127.0.0.1:6379> HINCRBY p1 age 2
(integer) 6
127.0.0.1:6379> HINCRBY p1 age 2
(integer) 8
##6. HVALS key 获取哈希表中所有值
127.0.0.1:6379> HVALS p1
1) "wuliji"
2) "8"
4.8.6 Sorted Set(ZSet)
- API

- 测试
##1. ZADD key score1 member1 [score2 member2] 向有序集合添加一个或多个成员,或者更新已存在成员的分数
127.0.0.1:6379> ZADD zset1 100 v1 99 v2 101 v3
(integer) 3
##2. ZRANGE key start stop [WITHSCORES] 通过索引区间返回有序集合成指定区间内的成员
127.0.0.1:6379> ZRANGE zset1 0 -1
1) "v2"
2) "v1"
3) "v3"
127.0.0.1:6379> ZRANGE zset1 0 -1 WITHSCORES
1) "v2"
2) "99"
3) "v1"
4) "100"
5) "v3"
6) "101"
##3. ZRANK key member 返回有序集合中指定成员的索引
127.0.0.1:6379> ZRANK zset1 v1
(integer) 1
##4. ZREMRANGEBYSCORE key min max 移除有序集合中给定的分数区间的所有成员
127.0.0.1:6379> ZRANGE zset1 0 -1
1) "v5"
2) "v4"
3) "v2"
4) "v1"
5) "v3"
6) "v6"
127.0.0.1:6379> ZREMRANGEBYSCORE zset1 77 99
(integer) 3
127.0.0.1:6379> ZRANGE zset1 0 -1
1) "v1"
2) "v3"
3) "v6"
##5. ZREVRANK key member 返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序
127.0.0.1:6379> ZRANGE zset1 0 -1
1) "v1"
2) "v3"
3) "v6"
127.0.0.1:6379> ZREVRANK zset1 v6
(integer) 0
127.0.0.1:6379> ZREVRANK zset1 v3
(integer) 1
127.0.0.1:6379> ZREVRANK zset1 v1
(integer) 2
4.9 Redis事务
4.9.1 API

4.9.2 事务
MULTI 、 EXEC 、 DISCARD 和 WATCH 是 Redis 事务相关的命令。事务可以一次执行多个命令, 并且带有以下两个重要的保证:
- 事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
- 事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
EXEC 命令负责触发并执行事务中的所有命令:
4.9.3 测试
##1. 测试1 —— 事务提交
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> EXEC
1) OK
2) OK
3) OK
127.0.0.1:6379> KEYS * ## 在事务未提交之前,我们是在另外的客户端中不能查看到这些数据
(empty list or set)
127.0.0.1:6379> KEYS *
1) "k1"
2) "k3"
3) "k2"
127.0.0.1:6379>
##2. 事务回滚
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> set k4 v4
QUEUED
127.0.0.1:6379> DISCARD
OK
##3. 原子性测试1——株连九族
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> GETSET k4
(error) ERR wrong number of arguments for 'getset' command
127.0.0.1:6379> EXEC
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379> get k1
(nil)
##4. 原子性测试2——冤有头债有主
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> INCR k1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> INCR k3
QUEUED
127.0.0.1:6379> EXEC
1) (integer) 1
2) OK
3) OK
4) (error) ERR value is not an integer or out of range
127.0.0.1:6379> get k1
"1"
127.0.0.1:6379> get k2
"v2"
127.0.0.1:6379> get k3
"v3"
4.9.4 Watch
乐观锁的方式进行数据安全保证。
- 演示
##1. 模拟信心卡记录
##1.1 客户端A
127.0.0.1:6379> watch balance
OK
127.0.0.1:6379> set balance 100
OK
127.0.0.1:6379> set debt 0
OK
127.0.0.1:6379> watch balance
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> DECRBY balance 20
QUEUED
127.0.0.1:6379> INCRBY debt 20
QUEUED
127.0.0.1:6379> EXEC
(nil)
127.0.0.1:6379> get balance
"200"
127.0.0.1:6379>
##1.2 客户端B : 保证客户端A提交事务之前执行命令
127.0.0.1:6379> get balance
"100"
127.0.0.1:6379> set balance 200
OK
4.10 发布/订阅
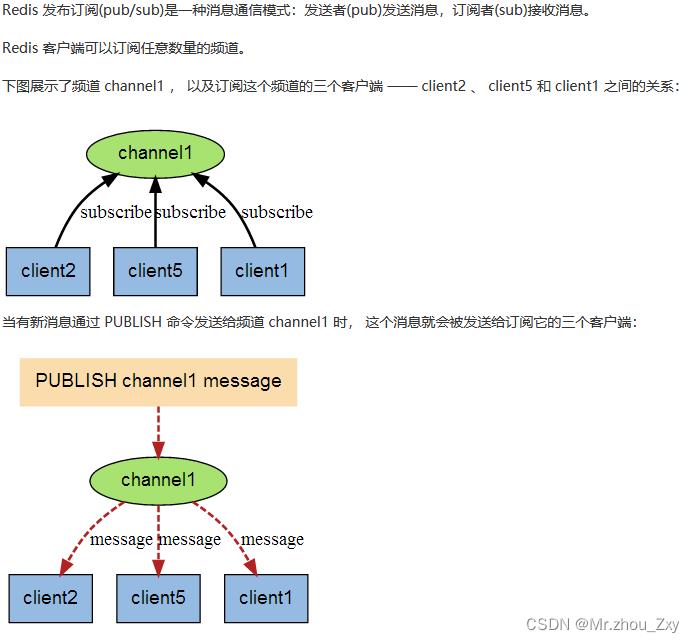
- API
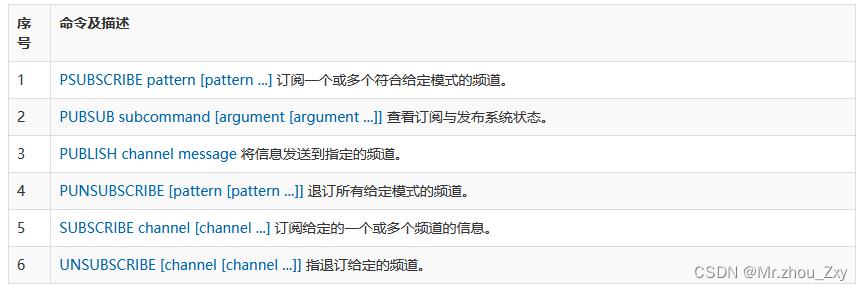
- 演示
##1. 客户端订阅了频道
127.0.0.1:6379> SUBSCRIBE nba cba aba mba
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "nba"
3) (integer) 1
1) "subscribe"
2) "cba"
3) (integer) 2
1) "subscribe"
2) "aba"
3) (integer) 3
1) "subscribe"
2) "mba"
3) (integer) 4
##2. 发布者发布消息
127.0.0.1:6379> PUBLISH nba wulijiIsMvp
(integer) 1
以上是关于Redis详细教程入门的主要内容,如果未能解决你的问题,请参考以下文章