Python 数据存储读取,6千字搞定各种方法
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 数据存储读取,6千字搞定各种方法相关的知识,希望对你有一定的参考价值。

作者 | 老表
来源 | 简说Python
一、前言
二、专栏概要
三、做准备:将爬取到的数据存入csv和mysql、其他数据库
3.1 前情回顾
3.1 数据存入+读取csv
3.2 数据存入+读取 MySQL
3.3 数据存入+读取 SQLAlchemy
3.4 pandas 自带to_sql和read_sql实现数据存储、读取
3.5 其他拓展
四、总结
一、前言
今天给大家分享的是 Python 数据存储读取相关的内容,最近有读者提起,所以再分享一遍~
二、专栏概要
直接来:一行代码爬取微博热搜数据
做准备:将爬取到的数据存入csv和mysql、其他数据库
搞事情:读取mysql数据并进行数据分析与可视化
进阶活:将可视化数据结果呈现到web页面(大屏可视化)
悄悄话:项目总结与思考,期待你的来稿
三、做准备:将爬取到的数据存入csv和mysql、其他数据库
首先需要你的电脑安装好了Python环境,并且安装好了Python开发工具。
如果仅用Python来处理数据、爬虫、数据分析或者自动化脚本、机器学习等,建议使用Python基础环境+jupyter即可,安装使用参考Windows/Mac 安装、使用Python环境+jupyter notebook
如果想利用Python进行web项目开发等,建议使用Python基础环境+Pycharm。
3.1 前情回顾
在上一节中,我们爬取好了数据,在之前的基础上,我拓展了下数据,爬取了2021年1月1日到2021年9月1日的微博热搜数据,需要数据的可以在文末获取,当然你直接利用上次获取数据的方法获取到相应数据,也可以学习本系列,不影响。
数据基本情况:
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 wb_title 82869 non-null object
1 wb_hot_time 82869 non-null int64
2 wb_hot_number 82869 non-null int64
3 wb_first_time 82869 non-null object
dtypes: int64(2), object(2)
memory usage: 2.5+ MB字段说明:
| 字段名 | 数据类型 | 含义 |
|---|---|---|
| wb_title | str | 热搜标题 |
| wb_hot_time | int | 热搜在榜时间(分钟) |
| wb_hot_number | int | 热搜热度 |
| wb_first_time | str | 热搜上榜时间(第一次) |
数据示例:
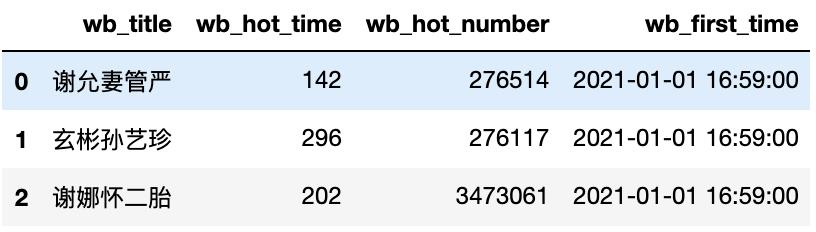
3.1 数据存入+读取csv
这里我们利用pandas的to_csv方法,如果你还没有安装过,直接:
pip install pandaspandas为Python编程语言提供高性能,是基于NumPy 的一种易于使用的数据结构和数据分析工具,pandas为我们提供了高性能的高级数据结构(比如:DataFrame)和高效地操作大型数据集所需的工具,同时提供了大量能使我们快速便捷地处理数据的函数和方法。
首先需要导入pandas模块,并起一个别名pd:
import pandas as pd写数据
# 数据已经是pandas的DataFrame,所以直接调用to_csv函数即可
save_path = '../wb_hot_data.csv' # 文件存储路径,这里使用相对路径,存储到代码的上级目录下
wb_hot_data.to_csv(save_path)超级简单,直接调用to_scv函数,传入一个文件路径即可实现写入csv功能,但是你会发现直接打开会中文会乱码,索引列也被存储进去了。
to_csv(path_or_buf,sep,na_rep,columns,header,index)
1. path_or_buf:字符串,文件名、文件具体、相对路径、文件流等;
2. sep:字符串,文件分割符号;
3. na_rep:字符串,将NaN转换为特定值;
4. columns:列表,选择部分列写入;
5. header:None,写入时忽略列名;
6. index:False则选择不写入索引,默认为True。我们存储的时候设置下编码(编码设置为utf_8_sig)和不要存储索引即可:
# 数据已经是pandas的DataFrame,所以直接调用to_csv函数即可
save_path = '../wb_hot_data.csv' # 文件存储路径,这里使用相对路径,存储到代码的上级目录下
# 改为utf_8_sig编码 https://blog.csdn.net/pipisorry/article/details/44136297
wb_hot_data.to_csv(save_path, encoding='utf_8_sig',index=False)
读数据
# 直接调用pandas的read_csv函数即可,传入文件存储路径
wb_hot_data = pd.read_csv('../wb_hot_data.csv')
# 查看数据前3行
wb_hot_data.head(3)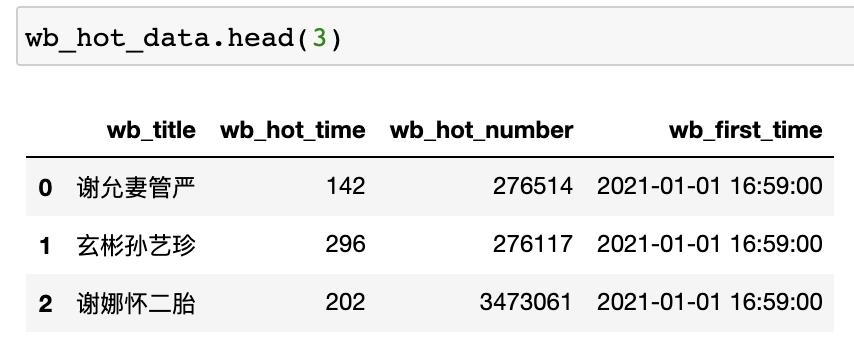
read_csv(filepath_or_buffer,sep,header,names,skiprows,na_values,encoding,nrows)
按指定格式读取csv文件。
常见参数解析:
1. filepath_or_buffer:字符串,表示文件路径。
2. sep: 字符串,指定分割符,默认是’,’。
3. header:数值, 指定第几行作为列名(忽略注解行),如果没有指定列名,默认header=0,数据第一行为表头; 如果指定了列名,则需要设置header=None。
4. names: 列表,指定列名,如果文件中不包含header的行,应该设置header=None。
5. skiprows:列表,需要忽略的行数(从0开始),设置的行数将不会进行读取。
6. na_values:列表,设置需要将值替换成NAN的值,pandas默认NAN为缺省,可以用来处理一些缺省、错误的数值。
7. encoding:字符串,用于unicode的文本编码格式。例如,"utf-8"或"gbk"等文本的编码格式。
8. nrows:需要读取的行数。直接利用pandas的to_csv和read_csv我们就可以很快的完成python写、读csv文件。
3.2 数据存入+读取 MySQL
跟着之前的文章安装好MySQL后(最简单的安装方法就是官网下载安装包然后一步步安装),就可以进行后面操作了。
首先确保mysql安装和环境变量配置没问题,打开终端(或者cmd),输入下面指令,输出对应的mysql版本则表示相关配置ok。
# 1)查看mysql版本 确保环境变量配置OK
mysql --version
# 2)启动mysql服务
mysql.server start接下来,我们需要打开终端(或者cmd),进入mysql数据库,并创建一个数据库sql_study,并在该数据库下创建一张表wb_hot用于存放微博热搜数据,主键设置为热搜标题。
当然,这些操作也可以利用python完成,这里提前这样操作是为了让大家了解mysql基本语法,这对后面我们使用mysql进行数据分析处理是有很大好处的,希望你能重视或理解。
# 3)进入mysql
mysql -u数据库用户名 -p设置的数据库登录密码
# 4)创建一个数据库 sql_study
create database sql_study charset=utf8;
# 5)进入数据库
use sql_study;
# 6)创建一个数据表 wb_hot
create table if not exists `wb_hot`(
`wb_title` varchar(100) not null,
`wb_hot_time` int not null,
`wb_hot_number` int not null,
`wb_first_time` datetime not null,
primary key(`wb_title`, `wb_first_time`)
)engine=InnoDB default charset=utf8;
# 7)查看新建的表
show tables;接下来我们使用pymysql这个库来实现Python对mysql的操作,首先安装pymysql,推荐直接使用镜像源安装,速度快,
pip install -i https://pypi.douban.com/simple/ pymysql打开jupyter notebook,开始写代码啦~(当然你习惯用其他开发工具也可以,如pycharm、vscode等)
# 打开jupyter
jupyter notebook这里我们假设数据已经读取出来,存放在 wb_hot_data 一个dataframe对象,你可以是直接接上一篇文章爬取数据整理后,或者是本篇文章中从 csv文件读取都可以,总之我们假设数据已经读取到了 wb_hot_data 变量中,后面也是。
数据已经准备好了,我们就开始利用python连接mysql并进行相关插入操作吧~
连接mysql
import pymysql
# 连接数据库 并添加cursor游标,后面所有操作都利用游标进行
conn = pymysql.connect(host = "localhost",port = 3306,user = "你的数据库登录用户名", password = "你的数据库登录密码",charset="utf8")
cursor = conn.cursor()创建数据库
'''
新建一个数据库
database:数据库名称
cursor:数据库连接游标
'''
def create_database(database, cursor):
# 创建database, 如果存在则不创建
cursor.execute("create database if not exists %s;"%database)
# 将相关操作内容传入数据库
conn.commit()
print("成功创建数据库:%s"%database)指定数据库中创建数据表
'''
在指定数据库中新建一个数据表
'''
def create_table(table_name, table_sql, database, cursor):
# 选择 database 数据库
cursor.execute("use %s;"%database)
# 创建数据表,因为数据表创建相对复杂,所以直接传入sql语句
cursor.execute(table_sql)
# 将相关操作内容传入数据库
conn.commit()
print("成功在数据库0中创建数据表:1".format(database,table_name))对指定数据表进行增删查改
'''
在指定数据库的数据表中增、删、查、改
'''
def sql_basic_operation(table_sql, database, cursor):
# 选择 database 数据库
cursor.execute("use %s"%database)
# 执行sql语句
cursor.execute(table_sql)
# 增删查改 一般为批量操作,不建议直接commit,可以操作完自己写个commit
# 这样执行效率会高很多,实测8w+数据,先插入所有再commit的耗费17.48s
# 每插入一次就commit一次的耗时为56.63s
# conn.commit()
print("sql语句执行成功")从上面我们可以看出,主要是利用了execute函数来执行sql操作语句,从而实现对数据库的控制。
利用python将爬取到的数据存入mysql
由于数据库和数据表我们之前已经创建过了,所以现在只需要插入数据到mysql即可,接下来我们写一个循环插入数据的语句吧~
'''
将dataframe数据存储到mysql
'''
import time
def df_to_sql(df, table_name, database, cursor):
t1 = time.time() # 时间戳 单位秒
print('数据插入开始时间:0'.format(t1))
i = 0
for row in df.itertuples():
# print(type(row)) # <class 'pandas.core.frame.Pandas'>
# 拼接插入sql语句
# insert into wb_hot values('谢允妻管严', 142, 276514, '2021-01-01 16:59:00');
sql_insert = '''insert into 0 values('1', 2, 3, '4');
'''.format(table_name,getattr(row,'wb_title'),
getattr(row,'wb_hot_time'),
getattr(row,'wb_hot_number'),
getattr(row,'wb_first_time')
)
# 将插入语句传入函数,执行相关操作
sql_basic_operation(sql_insert, database, cursor)
i+=1
conn.commit()
t2 = time.time() # 时间戳 单位秒
print('数据插入结束时间:0'.format(t2))
print('成功插入数据%d条,'%i, '耗费时间:%.5f秒。'%(t2-t1))接着我们就可以将数据插入mysql数据库啦,
# 对数据进行小处理,将wb_first_time列改为日期类型
wb_hot_data['wb_first_time'] = pd.to_datetime(wb_hot_data['wb_first_time'])
df_to_sql(wb_hot_data, 'wb_hot', 'sql_study', cursor)
一共82869条数据,从mysql后台也可以看到相关数据,都正常。

利用python从mysql读取爬取到的数据
根据上面学习,我们直接写好读取(查询)的sql语句就可以啦,然后调用我们之前写的sql操作函数即可读取相关数据:
'''
从sql读取数据,并转成dataframe格式数据
'''
def read_from_sql(sql_query, database, cursor, columns):
# 直接调用
sql_basic_operation(sql_query, database, cursor)
conn.commit()
# 获取匹配到的数据
result = cursor.fetchall() # 放回数据为元组 格式((字段名1, 字段名2...),()...)
# 将元组数据转为dataframe
df = pd.DataFrame(result, columns=columns)
return df调用数据查询函数,并获取相关数据:
'''
获取wb_hot中前三行数据
'''
# sql查询语句
sql_query = '''select * from wb_hot limit 3'''
# 列名
columns = ['wb_title', 'wb_hot_time', 'wb_hot_number', 'wb_first_time']
# 调用函数,并获取返回值
sql_data = read_from_sql(sql_query, 'sql_study', cursor, columns)
sql_data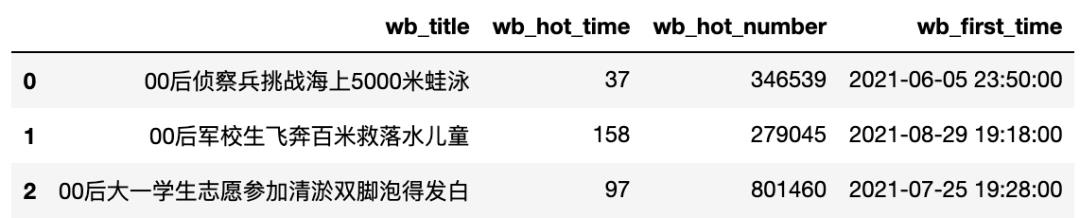
我们会发现这与我们存入数据的前三行不同,这是因为在mysql中插入数据默认会按主键顺序进行排列,解决这个问题最好的方法是我们家一个自增序号列,并设置为主键,这样数据顺序就和我们插入顺序一致了。
或者我们在写查询语句加上指定的查询条件(where),以及排序列(order by)即可。
# 完成操作后记得close cursor和conn
cursor.close()
conn.close()3.3 数据存入+读取 SQLAlchemy
SQLAlchemy 是 Python SQL 工具包和对象关系映射器(ORM),可为应用程序开发人员提供 SQL 的全部功能和灵活性。所谓ORM,就是指把关系数据库的表结构映射到对象上,在Python里面我们直接操作对象,就能对数据库进行操作了,简便、逻辑性更强。
首先还是安装SQLAlchemy模块:
pip install -i https://pypi.douban.com/simple/ sqlalchemy3.3.1 首先导入相关包
# 导入相关包
from sqlalchemy import Column, String, Integer, DateTime, create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_basesqlalchemy下的:
Column 数据列对象
String, Integer, DateTime 数据类型
create_engine 创建数据库连接引擎,有个重要参数url,一般格式为:数据库类型+数据库驱动://数据库用户名:数据库密码@IP地址:端口/数据库
sqlalchemy.orm下的:
sessionmaker 创建python与数据库的会话对象,后面直接利用实例化session对象调用增删查改相关操作
sqlalchemy.ext.declarative下的:
declarative_base 创建sqlalchemy基本对象,很重要
3.3.2 初始化数据库,并创建会话session
# 初始化数据库连接引擎
# create_engine("数据库类型+数据库驱动://数据库用户名:数据库密码@IP地址:端口/数据库",其他参数)
engine = create_engine('mysql+pymysql://数据库用户名:数据库密码@localhost:3306/sql_study?charset=utf8')
# 创建数据库会话对象,并实例化
db_session = sessionmaker(bind=engine)()3.3.3 创建一个WbHot类,并利用WbHot类创建表wb_hot
# 创建sqlalchemy基本对象
# 后面每个对象都继承自它
Base = declarative_base()
# 定义WbHot类,一个类可以理解成一张表
# 后面对对象进行操作就是对表进行操作
class WbHot(Base):
# 表名,为了不和之前的表重名,新表起名为wb_hot2
__tablename__ = 'wb_hot2'
# 表结构,初学者对照sql创建语句写更简单
'''
create table if not exists `wb_hot`(
`wb_title` varchar(100) not null,
`wb_hot_time` int not null,
`wb_hot_number` int not null,
`wb_first_time` datetime not null,
primary key(`wb_title`, `wb_first_time`)
)engine=InnoDB default charset=utf8;
'''
# Column nullable是否可为空 primary_key 是否为主键
wb_title = Column(String(100), nullable=False, primary_key=True)
wb_hot_time = Column(Integer, nullable=False)
wb_hot_number = Column(Integer, nullable=False)
wb_first_time = Column(DateTime, nullable=False, primary_key=True)
# 调用基础对象中的元数据模块中的create_all创建数据表
Base.metadata.create_all(engine)创建好表,我们可以在mysql下查看下我们刚刚创建的表相关信息,可以看出,和之前直接利用sql创建的数据表表结构一致。

3.3.4 存储数据
表创建好后,我们就可以开始存储数据啦,前面说过了,sqlalchemy是对对象进行操作了,所以我们将数据变成一个一个的WbHot对象,然后在调用session中的add函数即可实现新增数据,代码如下:
# 存储数据
import time
def sqlalchemy_to_sql(df, session):
t1 = time.time() # 时间戳 单位秒
print('数据插入开始时间:0'.format(t1))
i = 0
for row in df.itertuples():
# print(type(row)) # <class 'pandas.core.frame.Pandas'>
# 初始化WbHot对象
# WbHot('谢允妻管严', 142, 276514, '2021-01-01 16:59:00');
wb_hot = WbHot(wb_title=getattr(row,'wb_title'),
wb_hot_time=getattr(row,'wb_hot_time'),
wb_hot_number=getattr(row,'wb_hot_number'),
wb_first_time=getattr(row,'wb_first_time')
)
# 调用session中的add函数将对象添加到数据表
session.add(wb_hot)
i+=1
session.commit()
t2 = time.time() # 时间戳 单位秒
print('数据插入结束时间:0'.format(t2))
print('成功插入数据%d条,'%i, '耗费时间:%.5f秒。'%(t2-t1))
# 调用函数
sqlalchemy_to_sql(wb_hot_data, db_session)sql里还提供了一种一直新增多行数据的方法add_all,将所有要提交的数据存入列表,然后利用session调用add_all函数即可,测试了下,以8w条数据为例,两者效率如下:
add 成功插入数据82869条, 耗费时间:8.07842秒。
add_all 成功插入数据82869条, 耗费时间:7.29939秒。相差0.8s左右,当然会有误差,不过不管怎么说,这比前面直接用pymysql使用sql语句插入数据的效率高了2倍多,优秀~
3.3.4 读取(查询)数据
这里我们直接调用query函数进行查询,这个函数功能非常强大,包含了很多查询方法,比如:limit、filter、order_by、group_by等,操作起来非常方便。
def wbhot_to_df(data, columns):
df_data = []
for i in data:
list_data = [i.wb_title, i.wb_hot_time, i.wb_hot_number, i.wb_first_time]
df_data.append(list_data)
df = pd.DataFrame(df_data, columns=columns)
return df
# 读取非常简单,直接调用query函数即可
# all()表示 所有查询到的数据对象
# first()表示 查询到的数据对象中的第一个
data = db_session.query(WbHot).limit(3).all()
columns = ['wb_title', 'wb_hot_time', 'wb_hot_number', 'wb_first_time']
# 调用函数,将批量WbHot对象转换成dataframe
data_df = wbhot_to_df(data, columns)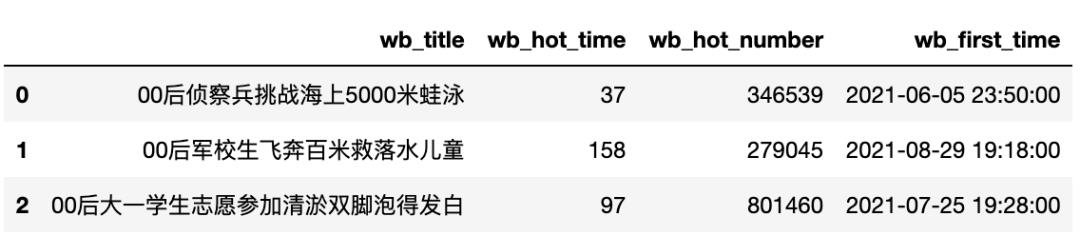
接下来我们简单介绍下sqlalchemy中查询的一些几本操作(以WbHot类为例):
# 直接查询,并返回所有数据,返回为一个包含WbHot的列表
db_session.query(WbHot).all()
# 限制输出列 limit
# 查询所有数据,输出前五行
db_session.query(WbHot).limit(5).all()
# 单条件过滤查询 返回所有热搜在榜时间2h及以上的热搜数据
# filter参数 类名.字段名
db_session.query(WbHot).filter(WbHot.wb_hot_time>=120).all()
# 多条件过滤查询
# filter_by 不能使用判断过滤,比如== >=等,另外参数是字段名,不需要类名.字段名
db_session.query(WbHot).filter_by(wb_hot_time=528 , wb_hot_number=2995191).all()
# 也可以使用filter来进行多条件过滤,略麻烦
# 需要从sqlalchemy导入 and_, or_(与、或判断方法)
# 返回所有热搜在榜时间2h及以上且热度大于1千万的数据
from sqlalchemy import and_, or_
db_session.query(WbHot).filter(and_(WbHot.wb_hot_time>=120, WbHot.wb_hot_number>=10000000)).all()
# 查询结果排序 order_by
# 参数 类名.字段名[.desc() 降序|asc() 升序]
# 返回所有热搜在榜时间2h及以上且热度大于3千万的数据,按热度降序排序
from sqlalchemy import and_, or_
db_session.query(WbHot).filter(and_(WbHot.wb_hot_time>=120, WbHot.wb_hot_number>=30000000)).order_by(WbHot.wb_hot_number.desc()).all()
# 分组查询 order_by
# 参数 类名.字段名
# 按标题分组,计算每个标题出现的天数、总在线时长、总热度、最后在线时间
db_session.query(WbHot.wb_title,
func.count(WbHot.wb_title).label('counts'),
func.sum(WbHot.wb_hot_time).label('wb_hot_times'),
func.sum(WbHot.wb_hot_number).label('wb_hot_numbers'),
func.max(WbHot.wb_first_time).label('wb_finally_time')).group_by(WbHot.wb_title).having(func.count(WbHot.wb_title)>=10).all()更多其他关于sqlalchemy查询数据库用法,大家用到的时候浏览器一查就可以啦~也欢迎大家留言区补充。
除了mysql数据库外,sqlalchemy也可以连接很多其他数据库,如:
# '数据库类型+数据库驱动名称://用户名:密码@机器地址:端口号/数据库名'
engine = create_engine('sqlite:/// wb_hot.db') # 连接sqlite文件
engine = create_engine('postgresql://用户名:密码@hostname:5432/dbname') # 连接postgresql
engine = create_engine('oracle://用户名:密码@hostname:1521/sidname') # oracle # 连接oracle
...3.4 pandas 自带to_sql和read_sql实现数据存储、读取
3.4.1 to_sql 存储数据到mysql
经过实验,这种方法写数据效率是最高的,直接上代码,
# 调用pandas 的 to_sql 存储数据
import time
from sqlalchemy import create_engine
# 利用sqlalchemy的create_engine创建一个数据库连接引擎
engine = create_engine('mysql+pymysql://用户名:密码@localhost:3306/sql_study?charset=utf8')
t1 = time.time() # 时间戳 单位秒
print('数据插入开始时间:0'.format(t1))
# 直接调用to_sql
# 第一个参数:表名,如果表不存在就会直接根据数据结构新建
# 第二个参数:engine,数据库连接引擎
# 第三个参数:设置存储不要将数据索引存入
# 第四个参数:如果表存在,以什么方式存储,append表示追加,replace表示删除表重建,默认fail抛出ValueError异常
wb_hot_data.to_sql('wb_hot2', engine, index=False, if_exists='append')
t2 = time.time() # 时间戳 单位秒
print('数据插入结束时间:0'.format(t2))
print('成功插入数据%d条,'%len(wb_hot_data), '耗费时间:%.5f秒。'%(t2-t1))
仅仅花了2.4s,比pymysql快9倍,比sqlalchemy快4倍,当然也可能是我操作问题(pymysql、sqlalchemy里我都写了循环,一个个读取然后再存入,遍历本生会耗费很长时间),如果大家有更好方法,欢迎留言区分享。
3.4.2 read_sql 读取数据从mysql
# 读取的sql语句
sql = 'select * from wb_hot2'
# 第一个参数:查询sql语句
# 第二个参数:engine,数据库连接引擎
# 第三个参数:将指定列转换成指定的日期格式
pd_read_sql = pd.read_sql(sql, engine, parse_dates='wb_first_time': "%Y:%m:%H:%M:%S")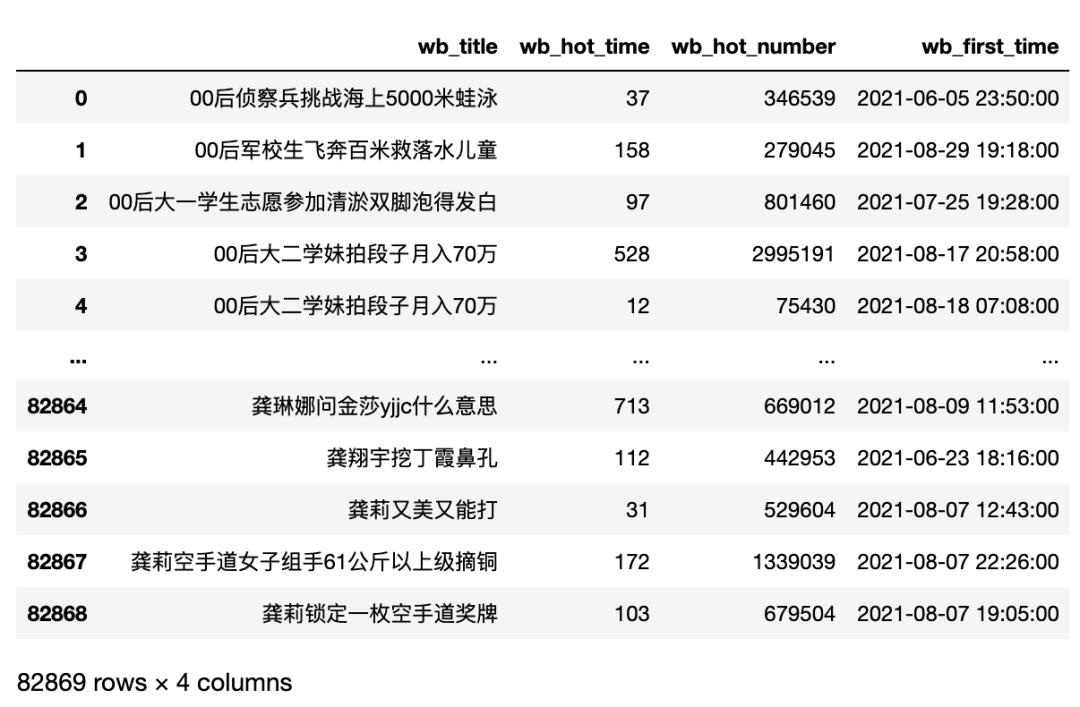
简单便捷,读取出来的数据格式也都对,而且就是dataframe数据格式,更方便我们进行数据分析和处理。
我还发现这个read_sql还可以执行复杂的查询,效率也还比较高,如查询热搜热度在3千万以上且在榜时间超过2h的热搜数据:
sql = 'select * from wb_hot2 where wb_hot_number>=30000000 and wb_hot_time>120'
pd_read_sql = pd.read_sql(sql, engine, parse_dates='wb_first_time': "%Y:%m:%H:%M:%S")简直太香了,我觉定后面就用pandas+sqlalchemy了。
3.5 其他拓展
mongodb
Python连接mongodb使用pymongodb即可,连接操作也很简单,直接在开启mongodb服务后,pymongo.MongoClient(host="127.0.0.1",port=27017)连接即可,默认端口是27017。
# 使用前先安装 pymongodb 模块 :pip install pymongodb
# 导入 pymogodb 模块
import pymongo
# 连接数据库,参数说明:服务器IP,端口号默认为27017
my_client = pymongo.MongoClient(host="127.0.0.1",port=27017)
# 直接通过数据库名称索引,有点像字典
my_db = my_client["db_name"]
# 连接 collection_name 集合,Mongodb里集合就相当于Mysql里的表
my_collection = my_client["collection_name"]
datas = my_collection .find() # 查询
for x in datas :
print(x)sqlite
除了上面提到的用sqlachemy操作sqlite,还可以直接利用sqlite3这个模块操作,连接也非常方便,sqlite3.connect('test.db')直接传入sqlite数据文件目录即可。
# 使用前先安装 sqlite3 模块 :pip install sqlite3
'''
sqlite数据库和前面两种数据库不一样,它是一个本地数据库
也就是说数据直接存在本地,不依赖服务器
'''
# 导入 sqlite3 模块
import sqlite3
# 连接数据库,参数说明:这里的参数就是数据文件的地址
conn = sqlite3.connect('test.db')
#使用cursor()方法创建一个游标对象
c = conn.cursor()
#使用execute()方法执行SQL语句
cursor = c.execute("SELECT * from test_table")
for row in cursor:
print(row)
#关闭游标和数据库的连接
c.close()
conn.close()
CSDN音视频技术开发者在线调研正式上线!
现邀开发者们扫码在线调研


往期回顾
分享
点收藏
点点赞
点在看以上是关于Python 数据存储读取,6千字搞定各种方法的主要内容,如果未能解决你的问题,请参考以下文章
(小甲鱼python)文件永久存储(上)总结 python文件永久存储(创建打开文件文件对象的各种方法及含义)
利用Python进行数据分析 第6章 数据加载存储与文件格式
python - 如何在python中附加一个列表时处理异常,其中包含从存储从.json文件读取的数据的dict读取的数据?