我的NVIDIA开发者之旅 - 极智AI | TensorRT API 构建模型推理流程
Posted 极智视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我的NVIDIA开发者之旅 - 极智AI | TensorRT API 构建模型推理流程相关的知识,希望对你有一定的参考价值。
"我的NVIDIA开发者之旅” | 征文活动进行中…
欢迎关注我的公众号 [极智视界],获取我的更多笔记分享
大家好,我是极智视界,本文介绍一下 TensorRT API 构建模型推理流程。
TensorRT 构建模型推理一般有三种方式:(1) 使用框架自带的 TensorRT 接口,如 TF-TRT、Torch-TRT;(2) 使用 Parser 前端解释器,如 TF / Torch / … -> ONNX -> TensorRT;(3) 使用 TensorRT 原生 API 搭建网络。当然难度和易用性肯定是由低到高的,伴随而来的性能和兼容性也是由低到高的。这里我们直接介绍第三种方式。
文章目录
1 TensorRT API 构建流程
TensorRT API 的整个构建过程可以分为 构建阶段 和 运行阶段 ,其中构建阶段指的是添加算子&数据、网络参数配置、进行算子间逻辑连接以组建模型网,来生成 TensorRT Engine;运行阶段则可以抛开算子实现,直接调用构建阶段生成的 TensorRT Engine 进行前向推理计算。两个阶段中都有一些比较关键的模块,在下面的图中予以列出:
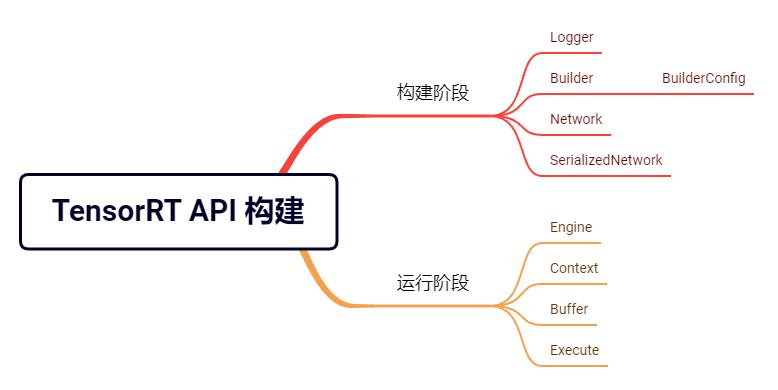
下面分别进行细致介绍。
2 构建阶段
2.1 构建 Logger
首先是构建 Logger 日志记录器:
logger = trt.Logger(trt.Logger.VERBOSE)
可选参数:VERBOSE、INFO、WARNING、ERROR、INTERNAL_ERROR,产生不同等级的日志,由详细到简略:
- VERiosE:[TensorRT] VERBOSE:Graph construction and optimization completed in 0.000261295 seconds.
- INFO:[TensorRT] INFO:Detected 1 inputs and 1 output network tensors.
- WARNING:[TensorRT] WARNING:Tensor DataType is determined at build time for tensors not marked as input or output.
- ERROR:[TensorRT] ERROR:INVALID_CONFIG:Deserialize the cuda engine failed.
- INTERNAL_ERROR:[TensorRT] ERROR:…/builder/tacticOptimizer.cpp (1820) - TRTInternal Error in computeCosts:0 (Could not find any implementation for node (Unnamed Layer* 0) [TopK].)
2.2 构建 Builder
然后是构建 Builder 网络元数据,这是模型搭建的入口,网络的 TensorRT 内部表示以及可执行程序引擎,都是由该对象的成员方法生成的,来看 Builder 是怎么构建的:
builder = trt.Builder(logger)
来看 Builder 的常用成员:
- builder.max_batch_size = 256:用于指定最大 batch size,在 static shape 模式下使用;
- builder.max_workspace_size = 1 << 30:用于指定最大可用显存,单位为 byte ( 注意:该项即将被废弃);
- builder.fp16_mode = True / False:用于开启 / 关闭 fp16 模式 ( 注意:该项即将被废弃);
- builder.int8_mode = True / False:用于开启 / 关闭 int8 模式 ( 注意:该项即将被废弃);
- builder.int8_calibrator = … :int8 模式的校准表 ( 注意:该项即将被废弃);
- builder.strict_type_constraints = True / False:开启 / 关闭强制精度模式 ( 注意:该项即将被废弃);
- builder.refittable = True / False:开启 / 关闭 refit 模式 ( 注意:该项即将被废弃);
你可能会比较好奇,可以看到上面很多的配置项即将被废弃,这不是说这些配置项不能用了,而是把它们移到了 BuilderConfig 中进行配置。需要注意的一点是,现在 NLP 里用的比较多的 Dynamic Shape 模式必须用 BuilderConfig 及其相关 API,那么紧接着我们来看 BuilderConfig。
2.3 构建 BuilderConfig
构建 BuilferConfig 网络元数据的选项,该项负责设置模型的一些参数,如是否开启 fp16 模式、int8 模式等。BuilderConfig 是建立在 Builder 基础之上的:
config = builder.create_builder_config()
来看 BuilderConfig 的常用成员:
- config.max_workspace_size = 1 << 30:用于指定最大可用显存;
- config.max_batch_size = … :用于指定最大 batch,若没有配置该成员,则默认 Explicit batch 模式;
- config.flag = … :用于设置标志位,如 1 << int(trt.BuilderFlag.FP16) 或 1 << int(trt.BuilderFlag.INT8) ;
- config.int8_calibrator = … :int8 模式的校准表;
- 等等更多高级用法
在以上的 等等更多高级用法 中还有如 set_tactic_sources (限制算法实现)、set_timing_cache (节约构建时间)、algorithm_selector (精确控制节点算法) 等。
2.4 构建 Network
构建 Network 计算图,是 最为核心的一个模块。Network 是网络的主体,使用 TensorRT API 搭建模型,并且标记网络的输入输出节点,以把各个计算节点织连成网状:
network = builder.create_network()
- 常用参数:1 << int(tensorrt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH),使用 Explicit Batch 模式;
- 常用方法:
- network.add_input(‘oneTensor’, trt.float32, (3, 4, 5)) 标记网络输入张量;
- convLayer = network.add_convolution_nd(XXX) 添加各种网络层;
- network.mark_output(convLayer.get_output(0)) 标记网络输出张量;
2.5 构建 SerializedNetwork
构建 SerializedNetwork,这是网络的 TensorRT 内部表示,这个地方的后续处理就有两种选择:(1) 可以用它生成可执行的推理引擎直接进行后续推理,这样就不用反序列化的过程;(2) 把它序列化保存为文件,方便以后重新读取和使用,这里就需要涉及到反序列化,这是工程部署常用的方式。来看看怎么构建 SerializedNetwork:
engineString = builder.build_serialized_network(network, config)
这样就完成了构建阶段,下面来看运行阶段。
3 运行阶段
运行阶段相比构建阶段,过程较为简洁明了。下面来看。
3.1 构建 Engine
构建 Engine,Engine 是推理引擎,是模型计算的核心,可以理解为可执行程序的代码段。来看 Engine 是怎么构建的:
engine = trt.Runtime(logger).deserialize_cuda_engine(engineString)
3.2 构建 Context
构建 Context,主要用于计算的 GPU 上下文,类比 cpu 上的进程概念,是执行推理引擎的主体。来看 Context 是怎么构建的:
context = engine.create_execution_context()
3.3 构建 Buffer 相关
构建 Buffer 相关,主要涉及数据的准备,包括 Host 端和 Device 端,以及数据的拷贝,如执行推理前需要将 CPU 数据拷贝到 GPU 上,即 Host -> Device;当推理完成后,需要将结果数据从 GPU 拷出到 CPU,也即 Device -> Host。一些相关的示例代码如下:
cudart.cudaMemcpy(bufferD, bufferH, bufferSize, cudart.cudaMemcpyKind.cudaMemcpyHostToDevice) # Host -> Device
cudart.cudaMemcpy(bufferH, bufferD, bufferSize, cudart.cudaMemcpyKind.cudaMemcpyDeviceToHost) # Device -> Host
3.4 构建 Execute
构建 Execute,Execute 调用计算核心执行计算的过程,看代码,很简单:
context.execute_v2(bufferD)
以上就完成了整个的 构建 与 运行过程,下面看个示例代码。
4 整流程构建示例代码
这里以构建单算子 ( Identity Layer ) 网络为例,进行代码展示:
## 构建期
logger = trt.logger(trt.Logger.ERROR)
if os.path.isfile(trtFile):
with open(trtFile, 'rb') as f:
engineString = f.read()
else:
builder = trt.Builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
profile = builder.create_optimization_profile()
config = builder.create_builder_config()
config.max_workspace_size = 1 << 30
inputTensor = network.add_input('inputT0', trt.DataType.FLOAT, [-1, -1, -1])
profile.set_shape(inputTensor.name, [1, 1, 1], [3, 4, 5], [6, 7, 8])
config.add_optimization_profile(profile)
identityLayer = network.add_identity(inputTensor)
network.mark_output(identityLayer.get_output(0))
engineString = builder.build_serialized_network(network, config)
with open(trtFile, 'wb') as f:
f.write(engineString)
## 运行期
engine = trt.Runtime(logger).deserialize_cuda_engine(engineString)
context = engine.create_execution_context()
dataShape = [3, 4, 5]
context.set_binding_shape(0, dataShape)
data = np.arange(np.prod(dataShape), dtype=np.float32).reshape(*dataShape)
bufferH = [np.ascontiguousarray(data.reshape(-1))]
bufferD = [cudart.cudaMalloc(bufferH[0].nbytes)[1]]
cudart.cudaMemcpy(bufferD[0], bufferH[0].ctypes.data, bufferH[0].nbytes, cudart.cudaMemcpyKind.cudaMemcpyHostToDevice) # Host -> Device
context.execute_v2(bufferD)
cudart.cudaMemcpy(bufferH[i].ctypes.data, bufferD[i], bufferH[i].nbytes, cudart.cudaMemcpyKind.cudaMemcpyDeviceToHost) # Device -> Host
cudart.cudaFree(bufferD[0])
好了,以上分享了 TensorRT API 构建模型推理流程的方法。希望我的分享能对你的学习有一点帮助。
【公众号传送】

扫描下方二维码即可关注我的微信公众号【极智视界】,获取我的更多经验分享,让我们用极致+极客的心态来迎接AI !
以上是关于我的NVIDIA开发者之旅 - 极智AI | TensorRT API 构建模型推理流程的主要内容,如果未能解决你的问题,请参考以下文章