OLAPDoris学习笔记
Posted 棉花糖灬
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OLAPDoris学习笔记相关的知识,希望对你有一定的参考价值。
一、简介
1. Doris介绍
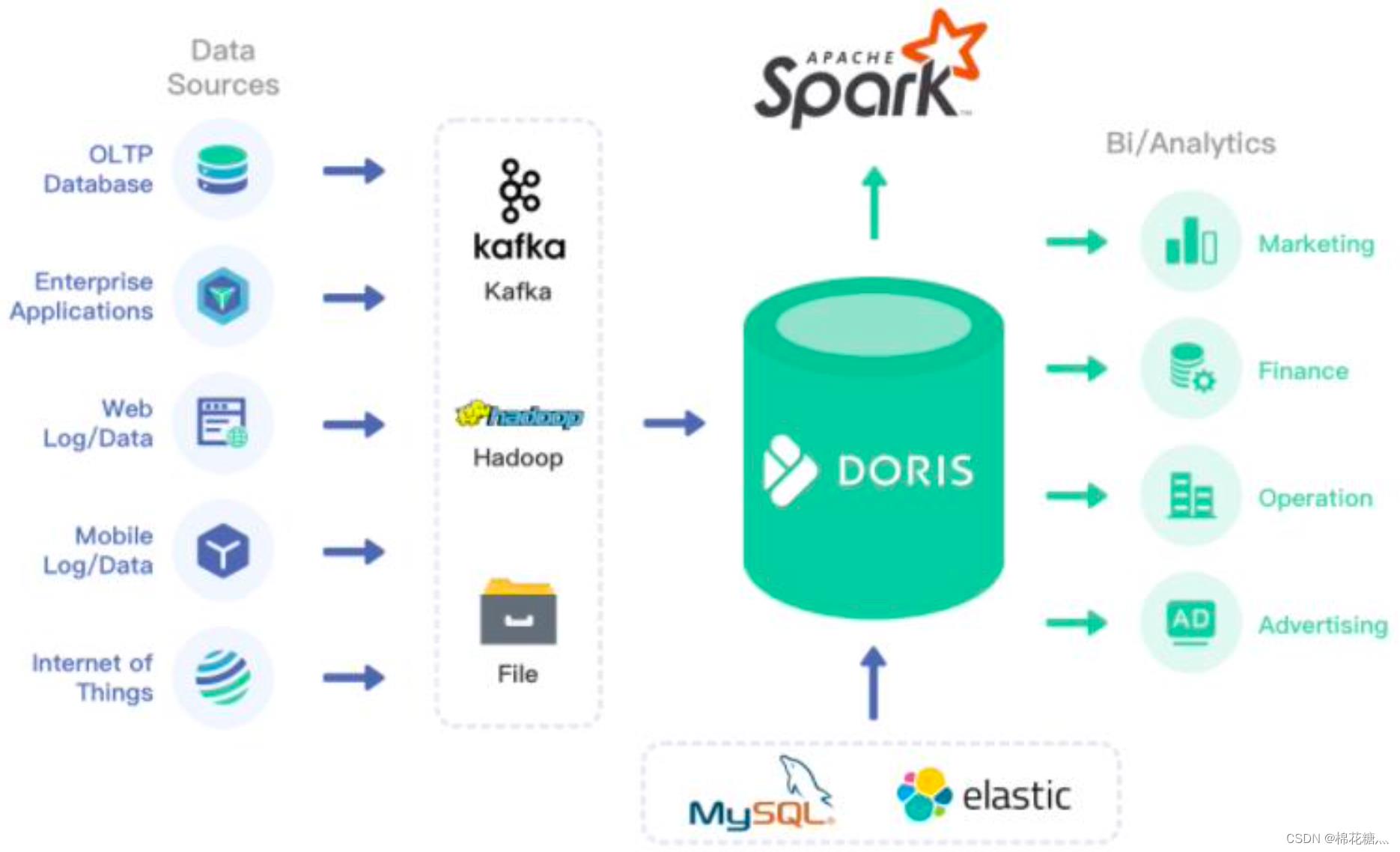
Apache Doris是由百度贡献的开源MPP分析型数据库产品,亚秒级查询响应时间,支持实时数据分析;分布式架构简洁,易于运维,可以支持10PB以上的超大数据集;可以满足多种数据分析需求,例如固定历史报表,实时数据分析,交互式数据分析和探索式数据分析等。
Doris是一个现代化的MPP(Massively Parallel Processing,即大规模并行处理)分析型数据库产品。仅需亚秒级响应时间即可获取查询结果,可以支持10PB以上的超大数据集。

2. Doris架构
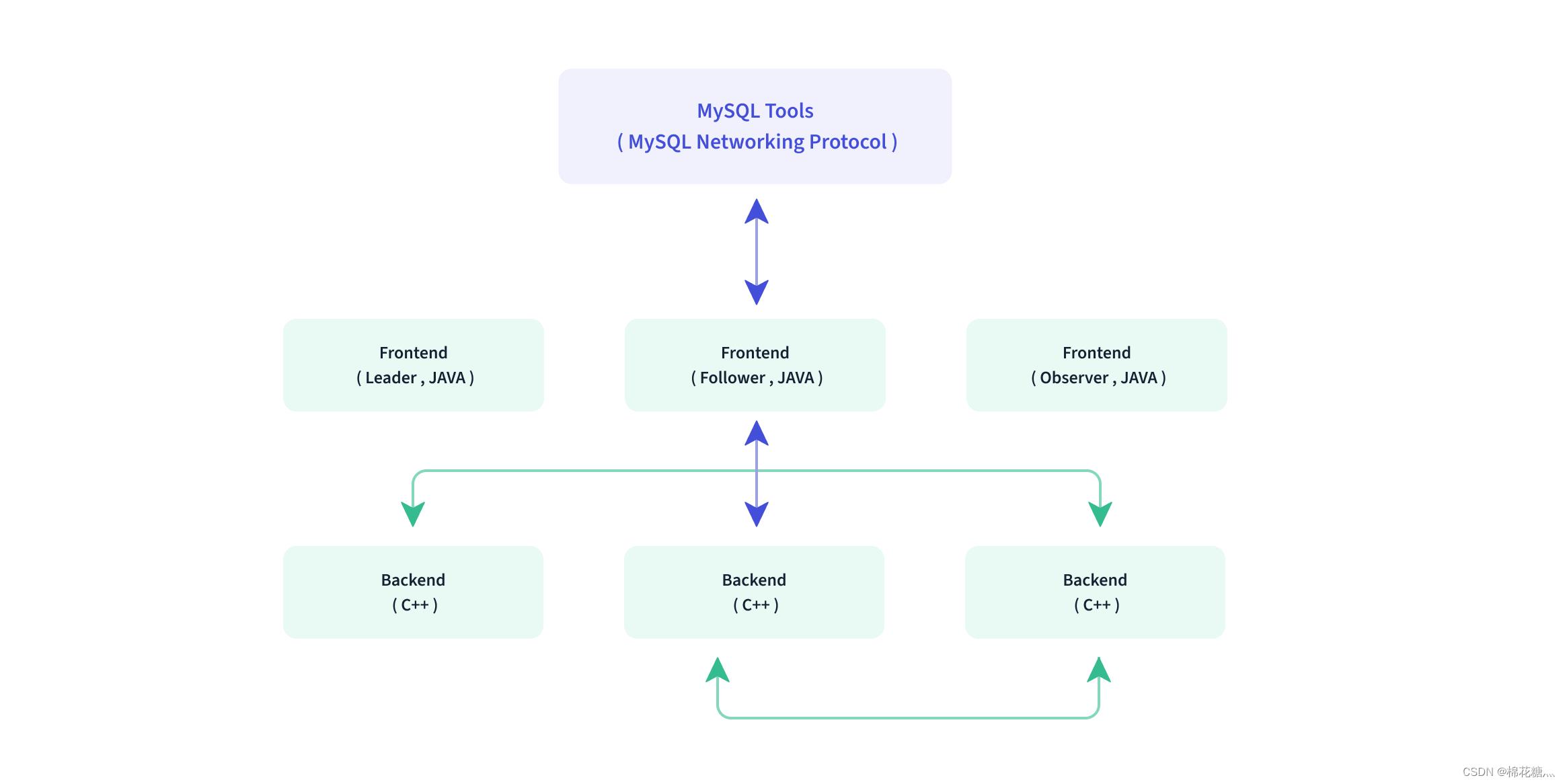
(1) FE
FE:前端,主要负责用户请求的接入、查询解析规划、元数据的管理、节点管理相关工作。
- FE的Leader和Follower用来达到元数据的高可用,保证单点宕机的情况下,元数据能够实时的在线回复,而不影响整个服务。
- Observer: 用来扩展查询节点,同时起到元数据备份的作用。如果发现集群压力非常大的情况下,需要去扩展整个查询能力,那么可以增加observer节点。observer不参与任何的写入,只参与读取。
(2) BE
BE:后端,主要负责数据存储、查询计划的执行。数据的可靠性由BE保证,BE会对整个数据进行多副本存储。
(3) mysql Client
MySQL Client:Doris借助MySQL协议,用户使用任意MySQL的ODBC/JDBC以及MySQL的客户端,就可以直接访问Doris。
(4) Broker
Broker:作为一个独立的无状态进程。封装了文件系统接口,提供Doris读取远端存储系统中文件的能力,包括HDFS、S3、BOS等。
二、数据表的创建
1. 基本概念
(1) Row和Column
一张表包括行(Row)和列(Column)。Row 即用户的一行数据。Column 用于描述一 行数据中不同的字段。
-
在默认的数据模型中,Column分为排序列和非排序列。存储引擎会按照排序列对数据进行排序存储,并建立稀疏索引,以便在排序数据上进行快速查找。
-
在聚合模型中,Column 可以分为 Key 和 Value。从业务角度看,Key 和 Value 分别对应维度列和指标列。从聚合模型的角度讲,Key 列相同的行会聚合为一行,其中 Value 列的聚合方式由用户在建表时指定。
(2) Partition和Tablet
在 Doris 的存储引擎中,用户数据首先被划分为若干个分区(Partition),划分的规则通常是按照用户指定的分区列进行范围划分,比如按时间划分。在每个分区内,数据被进一步按 Hash 的方式分桶,分桶的规则是要找用户指定的分桶列进行 Hash 后分桶。每个分桶就是一个数据分片(Tablet),也是数据划分的最小逻辑单元。
-
Tablet 之间的数据是没有交集的,独立存储的。Tablet 也是数据移动、复制等操作的最小物理存储单元。
-
Partion 可以视为是逻辑上的最小管理单元。数据的导入与删除,都可以或仅能支队一个 Partition 进行。
2. 数据模型
Doris 的数据模型主要分为 3 类:Aggregate、Uniq、Duplicate
(1) Aggregate模型
表中的列按照是否设置了 AggregationType,分为 Key(维度列)和 Value(指标列)。 没有设置 AggregationType 的称为 Key,设置了 AggregationType 的称为 Value。
1) 四种聚合方式
当我们导入数据时,对于 Key 列相同的行会聚合成一行,而 Value 列会按照设置的 AggregationType 进行聚合。AggregationType 目前有以下四种聚合方式:
-
SUM:求和,多行的Value进行累加。
-
REPLACE:替代,下一批数据中的 Value 会替换之前导入过的行中的 Value。
REPLACE_IF_NOT_NULL :当遇到 null 值则不更新。
-
MAX:保留最大值。
-
MIN:保留最小值。
2) 聚合时机
数据的聚合,在 Doris 中有如下三个阶段发生:
- 每一批次数据导入的 ETL 阶段。该阶段会在每一批次导入的数据内部进行聚合。
- 底层 BE 进行数据 Compaction 的阶段。该阶段,BE 会对已导入的不同批次的 数据进行进一步的聚合。
- 数据查询阶段。在数据查询时,对于查询涉及到的数据,会进行对应的聚合。
数据在不同时间,可能聚合的程度不一致。比如一批数据刚导入时,可能还未与之前已存在的数据进行聚合。但是对于用户而言,用户只能查询到聚合后的数据。即不同的聚合程度对于用户查询而言是透明的。用户需始终认为数据以最终的完成的聚合程度存在,而不应假设某些聚合还未发生。
(2) Unique模型
在某些多维分析场景下,用户更关注的是如何保证 Key 的唯一性,即如何获得 Primary Key 唯一性约束。因此,引入了 Uniq 的数据模型。该模型本质上是聚合模型的一个特例,也是一种简化的表结构表示方式。
Uniq 模型完全可以用聚合模型中的 REPLACE 方式替代。其内部的实现方式和数据存储方式也完全一样。
(3) Duplicate模型
在某些多维分析场景下,数据既没有主键,也没有聚合需求。Duplicate 数据模型可以满足这类需求。数据完全按照导入文件中的数据进行存储,不会有任何聚合。即使两行数据完全相同,也都会保留。 而在建表语句中指定的 DUPLICATE KEY,只是用来指明底层数据按照哪些列进行排序。
(4) 聚合模型的局限性
-
因为固定了 Value 列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性。
-
count(*)开销非常大,可以通过增加一个值恒为 1 的,聚合类型为 SUM 的列来模拟count(*),则select count(*) from table;的结果等价于select sum(count) from table;。另一种方式,就是 将如上的 count 列的聚合类型改为 REPLACE,且依然值恒为 1。那 么select sum(count) from table;和select count(*) from table;的结果将是一致的。并且这种方式,没有导入重复行的限制。
(5) 数据模型选择建议
因为数据模型在建表时就已经确定,且无法修改。所以,选择一个合适的数据模型非常重要。
- Aggregate 模型可以通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景。但是该模型对 count(*) 查询很不友好。 同时因为固定了 Value 列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性。
- Uniq 模型针对需要唯一主键约束的场景,可以保证主键唯一性约束。但是无法利用 ROLLUP 等预聚合带来的查询优势(因为本质是REPLACE,没有SUM这种聚合方式)。
- Duplicate 适合任意维度的 Ad-hoc 查询。虽然同样无法利用预聚合的特性,但是不受聚合模型的约束,可以发挥列存模型的优势(只读取相关列,而不需要读取所有 Key 列)
3. RollUp上卷
(1) 前缀索引
Doris 不支持在任意列上创建索引。Doris 这类 MPP 架构的 OLAP 数据库,通常都是通过提高并发,来处理大量数据的。
本质上,Doris 的数据存储在类似 SSTable(Sorted String Table)的数据结构中。该结构是一种有序的数据结构,可以按照指定的列进行排序存储。在这种数据结构上,以排序列作 为条件进行查找,会非常的高效。
在 Aggregate、Uniq 和 Duplicate 三种数据模型中。底层的数据存储,是按照各自建表语句中,AGGREGATE KEY、UNIQ KEY 和 DUPLICATE KEY 中指定的列进行排序存储的。而前缀索引,即在排序的基础上,实现的一种根据给定前缀列,快速查询数据的索引方式。
因为建表时已经指定了列顺序,所以一个表只有一种前缀索引。这对于使用其他不能命中前缀索引的列作为条件进行的查询来说,效率上可能无法满足需求。因此,我们可以通过创建 ROLLUP 来人为的调整列顺序。
(2) RollUp概念
ROLLUP 在多维分析中是“上卷”的意思,即将数据按某种指定的粒度进行进一步聚合。
在 Doris 中,我们将用户通过建表语句创建出来的表称为 Base 表(Base Table)。Base 表中保存着按用户建表语句指定的方式存储的基础数据。
在 Base 表之上,我们可以创建任意多个 ROLLUP 表。这些 ROLLUP 的数据是基于 Base 表产生的,并且在物理上是独立存储的。
ROLLUP 表的基本作用,在于在 Base 表的基础上,获得更粗粒度的聚合数据。
因为 Duplicate 模型没有聚合的语意。所以该模型中的 ROLLUP,已经失去了“上卷” 这一层含义。而仅仅是作为调整列顺序,以命中前缀索引,获得更好的查询效率。
(3) RollUp的几点说明
- ROLLUP 最根本的作用是提高某些查询的查询效率(无论是通过聚合来减少数据量,还是修改列顺序以匹配前缀索引)。因此 ROLLUP 的含义已经超出了“上卷” 的范围。这也是为什么在源代码中,将其命名为 Materialized Index(物化索引)的原因。
- ROLLUP是附属于Base表的,可以看做是Base表的一种辅助数据结构。用户可以 在 Base 表的基础上,创建或删除 ROLLUP,但是不能在查询中显式的指定查询某 ROLLUP。是否命中 ROLLUP 完全由 Doris 系统自动决定。
- ROLLUP的数据是独立物理存储的。因此,创建的ROLLUP越多,占用的磁盘空间也就越大。同时对导入速度也会有影响(导入的 ETL 阶段会自动产生所有 ROLLUP 的数据),但是不会降低查询效率(只会更好)。
- ROLLUP的数据更新与Base表是完全同步的。用户无需关心这个问题。
- ROLLUP中列的聚合方式,与Base表完全相同。在创建ROLLUP无需指定,也不能修改。
- 查询能否命中 ROLLUP 的一个必要条件(非充分条件)是,查询所涉及的所有列(包括 select list 和 where 中的查询条件列等) 都存在于该 ROLLUP 的列中。否则,查询只能命中 Base 表。
- 某些类型的查询(如count(*))在任何条件下,都无法命中ROLLUP。可以通过 EXPLAIN your_sql; 命令获得查询执行计划,在执行计划中,查看是否命中 ROLLUP。
- 可以通过 DESC tbl_name ALL; 语句显示 Base 表和所有已创建完成的 ROLLUP。
4. 物化视图
(1) 物化视图概念
物化视图就是包含了查询结果的数据库对象,可能是对远程数据的本地 copy,也可能是一个表或多表 join 后结果的行或列的子集,也可能是聚合后的结果。说白了,就是预先存储查询结果的一种数据库对象。
在 Doris 中的物化视图,就是查询结果预先存储起来的特殊的表。
物化视图的出现主要是为了满足用户,既能对原始明细数据的任意维度分析,也能快速的对固定维度进行分析查询。但 Doris 目前创建物化视图只能在单表操作,不支持 join。
(2) 适用场景
- 分析需求覆盖明细数据查询以及固定维度查询两方面。
- 查询仅涉及表中的很小一部分列或行。
- 查询包含一些耗时处理操作,比如:时间很久的聚合操作等。
- 查询需要匹配不同前缀索引。
(3) 优势
- 对于那些经常重复的使用相同的子查询结果的查询性能大幅提升。
- Doris自动维护物化视图的数据,无论是新的导入,还是删除操作都能保证base表和物化视图表的数据一致性。无需任何额外的人工维护成本。
- 查询时,会自动匹配到最优物化视图,并直接从物化视图中读取数据。 自动维护物化视图的数据会造成一些维护开销。
(4) 物化视图 VS RollUp
在没有物化视图功能之前,用户一般都是使用 Rollup 功能通过预聚合方式提升查询效率的。但是 Rollup 具有一定的局限性,他不能基于明细模型做预聚合。
物化视图则在覆盖了 Rollup 的功能的同时,还能支持更丰富的聚合函数。所以物化视图其实是 Rollup 的一个超集。
也就是说,之前 ALTER TABLE ADD ROLLUP 语法支持的功能现在均可以通过 CREATE MATERIALIZED VIEW 实现。
(5) 使用限制
- 目前支持的聚合函数包括,常用的 sum,min,max count,以及计算 pv ,uv, 留存率,等常用的去重算法 hll_union,和用于精确去重计算 count(distinct)的算法 bitmap_union。
- 物化视图的聚合函数的参数不支持表达式仅支持单列,比如: sum(a+b)不支持。
- 使用物化视图功能后,由于物化视图实际上是损失了部分维度数据的。所以对表的 DML 类型操作会有一些限制:
- 如果表的物化视图 key 中不包含删除语句中的条件列,则删除语句不能执行。
- 比如想要删除渠道为 app 端的数据,由于存在一个物化视图并不包含渠道这个字段,则 这个删除不能执行,因为删除在物化视图中无法被执行。这时候你只能把物化视图先删除, 然后删除完数据后,重新构建一个新的物化视图。
- 单表上过多的物化视图会影响导入的效率:导入数据时,物化视图和 base 表数据是同步更新的,如果一张表的物化视图表超过 10 张,则有可能导致导入速度很慢。这就像单次导入需要同时导入 10 张表数据是一样的。
- 相同列,不同聚合函数,不能同时出现在一张物化视图中,比如:select sum(a), min(a) from table 不支持。
- 物化视图针对 Unique Key 数据模型,只能改变列顺序,不能起到聚合的作用,所以在 Unique Key 模型上不能通过创建物化视图的方式对数据进行粗粒度聚合操作。
三、Doris与ClickHouse的对比
1. Doris更优的方面
-
使用更简单,如建表更简单,SQL标准支持更好, Join性能更好,导数功能更强大
-
运维更简单,如灵活的扩缩容能力,故障节点自动恢复,社区提供的支持更好
-
分布式更强,支持事务和幂等性导数,物化视图自动聚合,查询自动路由,全面元数据管理
2. ClickHouse更优的方面
-
性能更佳,导入性能和单表查询性能更好,同时可靠性更好
-
功能丰富,非常多的表引擎,更多类型和函数支持,更好的聚合函数以及庞大的优化参数选项
-
集群管理工具更多,更好多租户和配额管理,灵活的集群管理,方便的集群间迁移工具
3. 两者如何选择
-
业务场景复杂数据规模巨大,希望投入研发力量做定制开发,选ClickHouse
-
希望一站式的分析解决方案,少量投入研发资源,选择Doris
另外, Doris源自在线广告系统,偏交易系统数据分析;ClickHouse起源于网站流量分析服务,偏互联网数据分析,但是这两类场景这两个引擎都可以覆盖。如果说两者不那么强的地方,ClickHouse的问题是使用门槛高、运维成本高和分布式能力太弱,需要较多的定制化和较深的技术实力,Doris的问题是性能差一些可靠性差一些,下面就深入分析两者的差异。
四、Oncall结果
- agg表不支持条件判断,同一个字段可以进行不同的聚合函数操作。
以上是关于OLAPDoris学习笔记的主要内容,如果未能解决你的问题,请参考以下文章