Linux命令之排序sort
Posted 二木成林
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux命令之排序sort相关的知识,希望对你有一定的参考价值。
概述
sort 命令可以用于对文本文件进行排序,通常是以行为单位来排序。
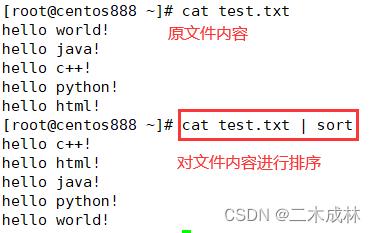
sort 将文件的每一行作为一个单位,相互比较。比较原则是从首字符向后,依次按 ASCII 码值进行比较,最后将它们按升序输出。
语法
该命令的语法如下:
sort [选项] 文件名
该命令支持的选项有:
| 选项 | 说明 |
|---|---|
| -b | 忽略每行前面开始出的空格字符。 |
| -c | 检查文件是否已经按照顺序排序。 |
| -d | 排序时,处理英文字母、数字及空格字符外,忽略其他的字符。 |
| -f | 排序时,将小写字母视为大写字母。 |
| -i | 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。 |
| -m | 将几个排序好的文件进行合并。 |
| -M | 将前面3个字母依照月份的缩写进行排序。 |
| -n | 依照数值的大小排序。 |
| -u | 意味着是唯一的(unique),输出的结果是去完重了的。 |
-o<输出文件> | 将排序后的结果存入指定的文件。 |
| -r | 以相反的顺序来排序。 |
-t <分隔字符> | 指定排序时所用的栏位分隔字符。 |
+<起始栏位>-<结束栏位> | 以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。 |
| –help | 显示帮助。 |
| –version | 显示版本信息。 |
[-k field1[,field2]] | 按指定的列进行排序。 |
使用
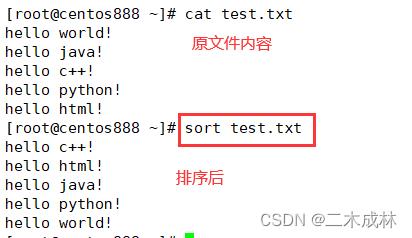
默认对文件排序
sort 命令默认将文件的每一列以 ASCII 码的次序排列,并将结果输出。语法格式如下:
# 语法
sort 文件名
去除重复行
如果我们想要去除文件中的重复行,那么可以使用 -u 选项。命令格式如下:
# 语法
sort -u 文件名
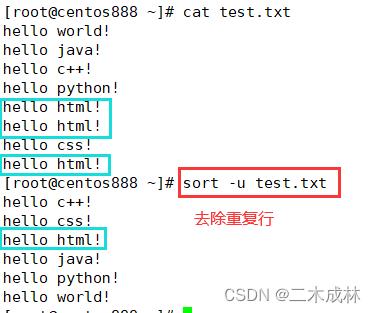
注:是去除所有重复行,无论它们是否连续。
降序排序
默认 sort 命令是升序排序,如果想要降序排序,那么加上 -r 选项:
# 语法
sort -r 文件名

输出到文件
默认 sort 是将结果输出到标准输出,如果要使用重定向 > 写入到文件,是需要写入到一个新文件的,是不会写入到的原文件的,如果想要将排序后结果的写入原文件,需要使用 -o 选项:
# 语法,将排序结果写回原文件,如果要写回原文件那么下面的文件名必须一致,如果不要写回原文件而是写到一个新文件中第二个文件名可以不一样
sort 文件名 -o 文件名
# 示例
sort test.txt -o test.txt

按数值排序
sort 命令默认是按照 ASCII 码次序来排序的,如果每一行都是数字,那么排序的结果看可能并不理想,那么如果要按照数字来进行排序,可以使用 -n 选项:
# 语法
sort -n 文件名

指定分隔符和指定列排序
如果文件内容如下:
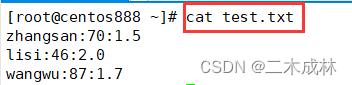
每一列之间通过冒号(:)进行分隔,如果我们想要按照第二列来进行排序,那么就需要用到 -t 选项和 -k 选项。这两个选项通常是一起使用,其中 -t 选项指定分隔符,-k 选项指定列号(从 1开始)。语法格式如下:
# 语法
sort -t 分隔符 -k 列号 文件名

指定排序优先级
即在排序时如果第一个域相同,则对第二个域进行排序,如果相同再以第三个域进行排序。例如,按照第二列进行排序,如果第二列相同,则再以第三列进行排序:

以上是关于Linux命令之排序sort的主要内容,如果未能解决你的问题,请参考以下文章