异步并行强化学习 + Double DQN
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了异步并行强化学习 + Double DQN相关的知识,希望对你有一定的参考价值。
Double DQN 见:DQN笔记:高估问题 & target network & Double DQN_UQI-LIUWJ的博客-CSDN博客
1 整体架构
- 系统中有一个服务器和 m 个 Worker 节点
- 服务器可以随时给某个 Worker 发送一条信息,一个 Worker 也可以随时给服务器发送信息,但是Worker 之间不能通信。
- 服务器和 Worker 都存储 DQN 的参数。
- 服务器上的参数是最新的,服务器用 Worker 发来的梯度对参数做更新。
- Worker 节点的参数可能是过时的,所以 Worker 需要频繁向服务器索要最新的参数。
- Worker 节点有自己的目标网络,而服务器上不存储目标网络。
- 每个 Worker 节点有自己的环境,用 DQN 控制智能体与环境交互,收集经验,把 (s, a, r, s′) 这样的四元组存储到本地的经验回放数组。
- 在收集经验的同时,Worker 节点做经验回放,计算梯度,把梯度发送给服务器。
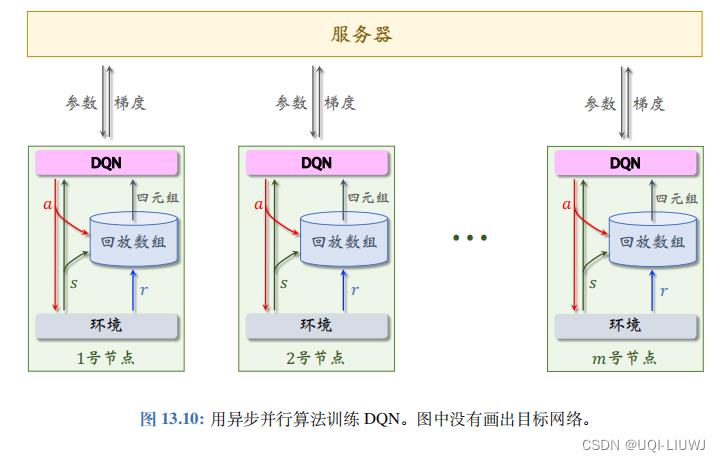
2 Worker端计算
每个 Worker 节点本地有独立的环境,独立的经验回放数组,还有一个 DQN 和一个目标网络。
设某个 Worker 节点当前参数为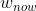 。
。
第 k 号 Worker 节点重复下面的步骤:

3 服务器端计算
服务器上储存有一份模型参数,记为(和2的不是一个东西)
每当一个 Worker 节点发来请求,服务器就把
发送给该
Worker
节点。
每当一个
Worker
节点发来梯度
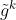 ,服务器就立刻做梯度下降更新参数:
,服务器就立刻做梯度下降更新参数:

 开发者涨薪指南
开发者涨薪指南
 48位大咖的思考法则、工作方式、逻辑体系
48位大咖的思考法则、工作方式、逻辑体系
以上是关于异步并行强化学习 + Double DQN的主要内容,如果未能解决你的问题,请参考以下文章