-聚类算法
Posted 說詤榢
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了-聚类算法相关的知识,希望对你有一定的参考价值。
文章目录
8-聚类算法
8.1 聚类任务
什么是聚类,聚类是做什么的
8.1.1 概念
机器学习里面的聚类是无监督的学习问题,它的目标是为了感知样本间的相似度进行类别归纳。它可以用于潜在类别的预测以及数据压缩上去。
潜在类别预测,比如说可以基于通过某些常听的音乐而将用户进行不同的分类。数据压缩则是指将样本进行归类后,就可以用比较少的的One-hot向量来代替原来的特别长的向量。
聚类,既可以作为一个单独的过程,也可以作为其他机器学习任务的预处理模块。
8.1.2 问题描述
给定一个包含 N N N个样本的样本集 X = x 1 , x 2 , . . . , x N X=\\x_1,x_2,...,x_N\\ X=x1,x2,...,xN,要给对这N个样本给定一个划分方式,将这些样本划分为m类 C 1 , C 2 , C 3 , . . . , C m C_1,C_2,C_3,...,C_m C1,C2,C3,...,Cm,使得满足
C i ≠ ϕ , i = 1 , 2 , . . . , m C_i\\ne \\phi,i=1,2,...,m Ci=ϕ,i=1,2,...,m
U i = 1 , 2 , . . , m C i = X U_i=1,2,..,mC_i=X Ui=1,2,..,mCi=X
C i ⋂ C j = ϕ , i ≠ j C_i\\bigcap C_j=\\phi,i\\ne j Ci⋂Cj=ϕ,i=j
8.1.3 算法分类
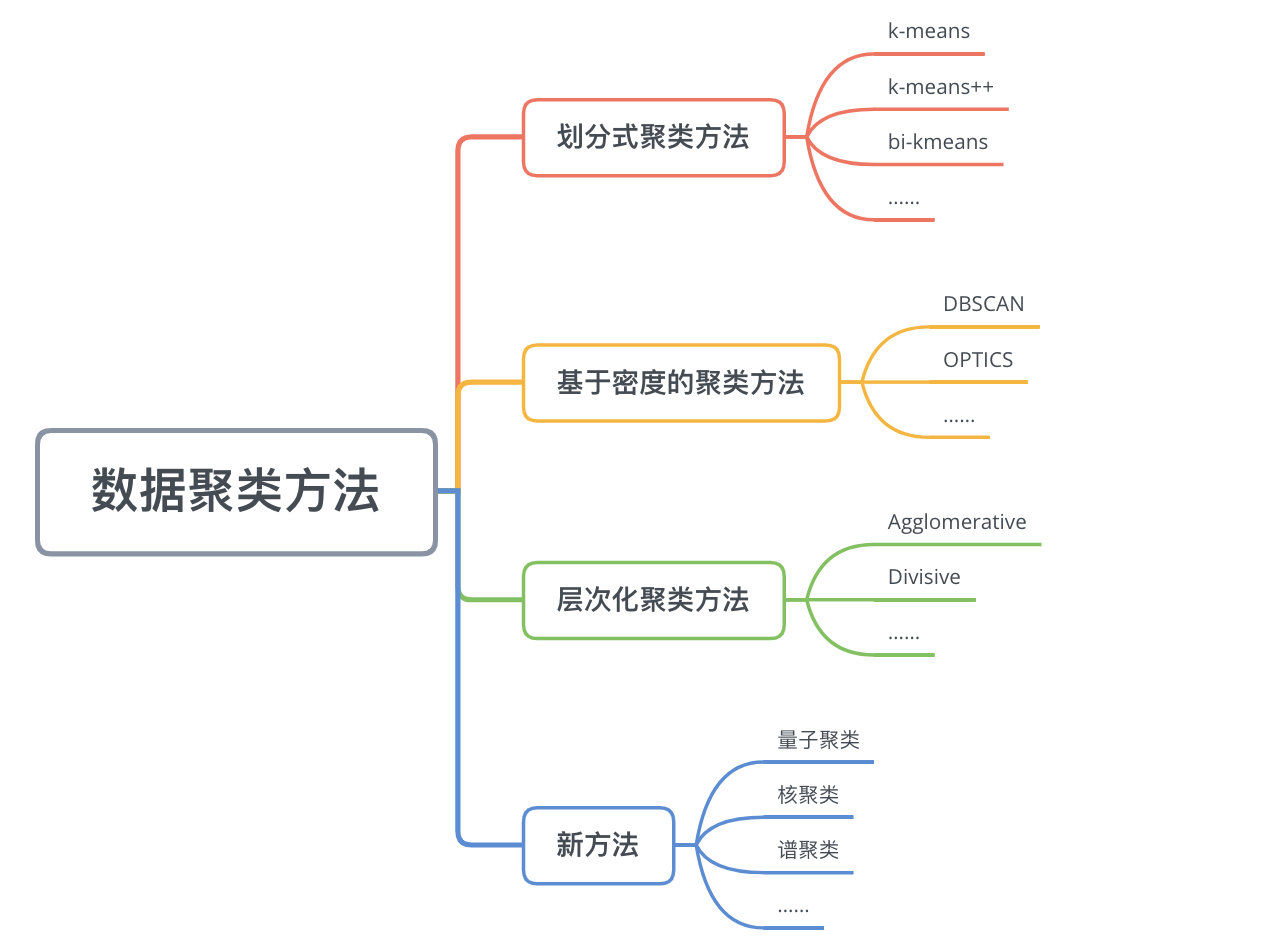
聚类算法主要有:
- 序贯法
- 层次分析法
- 基于损失函数最优化的:K-means,概率聚类
- 基于密度的聚类
- 其他特殊聚类方法:基因聚类算法,分治限界聚类算法;子空间聚类算法;基于核的聚类方法。
问题的提出
虽然 聚类看起来是很棒的,可以进行“物以类分,人以类聚”,但是聚类确守很多方面的影响。
例如:
1.属性选择不同,导致不同的结果
2.相似度度量不同,导致不同的结果
3.聚类的方法不同,导致不同的结果如何衡量无监督学习的指标
- 性能指标
- 距离计算
8.1.4 数学准备
样本集合中由n个样本,每个样本由m个属性的特征向量组成,样本集合可以用矩阵X表示:
X
=
[
x
i
j
]
m
×
n
=
[
x
11
x
12
⋯
x
1
n
x
21
x
22
⋯
x
2
n
⋮
⋮
⋯
⋮
x
m
1
x
m
2
⋯
x
m
n
]
X=[x_ij]_m\\times n=\\beginbmatrix x_11&x_12&\\cdots&x_1n \\\\ x_21&x_22&\\cdots&x_2n \\\\ \\vdots &\\vdots&\\cdots&\\vdots \\\\ x_m1&x_m2&\\cdots&x_mn \\endbmatrix
X=[xij]m×n=⎣⎢⎢⎢⎡x11x21⋮xm1x12x22⋮xm2⋯⋯⋯⋯x1nx2n⋮xmn⎦⎥⎥⎥⎤
给定样本集合X,
x
i
,
x
j
∈
X
,
x
i
=
(
x
1
i
,
x
2
i
,
.
.
.
,
x
m
i
)
T
,
x
j
=
(
x
1
j
,
x
2
j
,
.
.
.
,
x
m
j
)
T
x_i,x_j\\in X,x_i=(x_1i,x_2i,...,x_mi)^T,x_j=(x_1j,x_2j,...,x_mj)^T
xi,xj∈X,xi=(x1i,x2i,...,xmi)T,xj=(x1j,x2j,...,xmj)T
1) 类或簇
用 G G G表示类或簇,用 x i , x j x_i,x_j xi,xj表示类中的样本, N G N_G NG表示 G G G中的样本个数, d i j d_ij dij表示样本 x i x_i xi与样本 x j x_j xj之间的距离
类或簇的定义
设给定的整数 ,若集合 G G G中的任意两个样本 x i , x j x_i,x_j xi,xj,有 d i j ≤ T d_ij\\le T dij≤T, 则称 G G G表示为一个类或簇
2) 类或簇的特征
-
类的均值 x ‾ G = 1 N G ∑ i = 1 N G x i \\overlinex_G=\\frac1N_G\\sum_i=1^N_Gx_i xG=