SPARK的计算向量化-已有的向量化项目
Posted 鸿乃江边鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SPARK的计算向量化-已有的向量化项目相关的知识,希望对你有一定的参考价值。
背景
在SPARK的计算向量化-spark本身的向量化中,我们提到spark是利用代码生成(生成for循环),从而JIT进行向量化。这是有局限的,所以大部分公司都会采用通过其他方式来进行向量化计算。
我们列举几种已知的应用到spark计算引擎的向量化技术。
Velox
Meta(也就是Facebook)开源的一个C++实现的SQL执行引擎,输入逻辑执行计划,利用SIMD指令实现向量化操作,输出结果;
结合Apache Arrow作数据交换,可以实现Spark的计算向量化。
项目见facebookincubator/velox
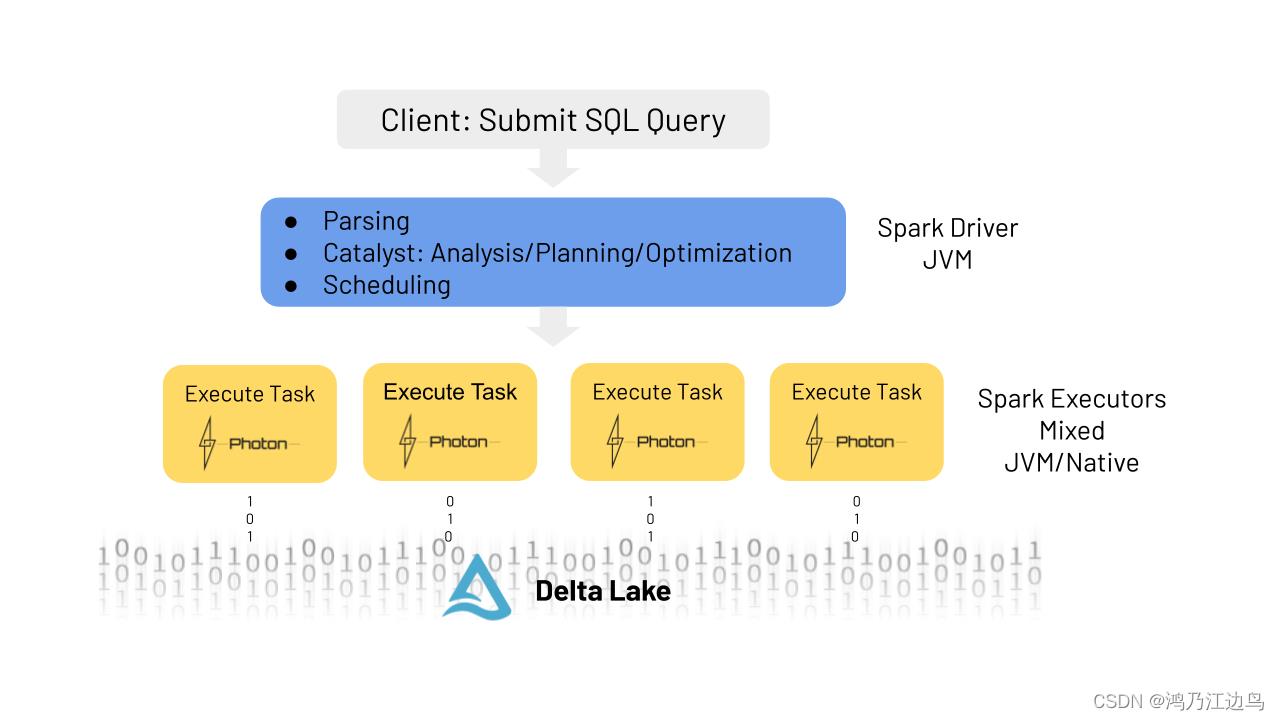
Photon
这是Databricks执行引擎的内部实现,也是用C++实现的,但是它复用了spark的逻辑计划,在物理计划task级别进行判断哪些是可以运行在Photon,具体执行位置如下:
gazelle
Intel开源的,底层依赖于Apache Arrow高效数据存储和Gandiva(基于LLVM)的高效向量计算,但是Gandiva目前只是支持表达式向量化,不支持sort,join这种物理算子。
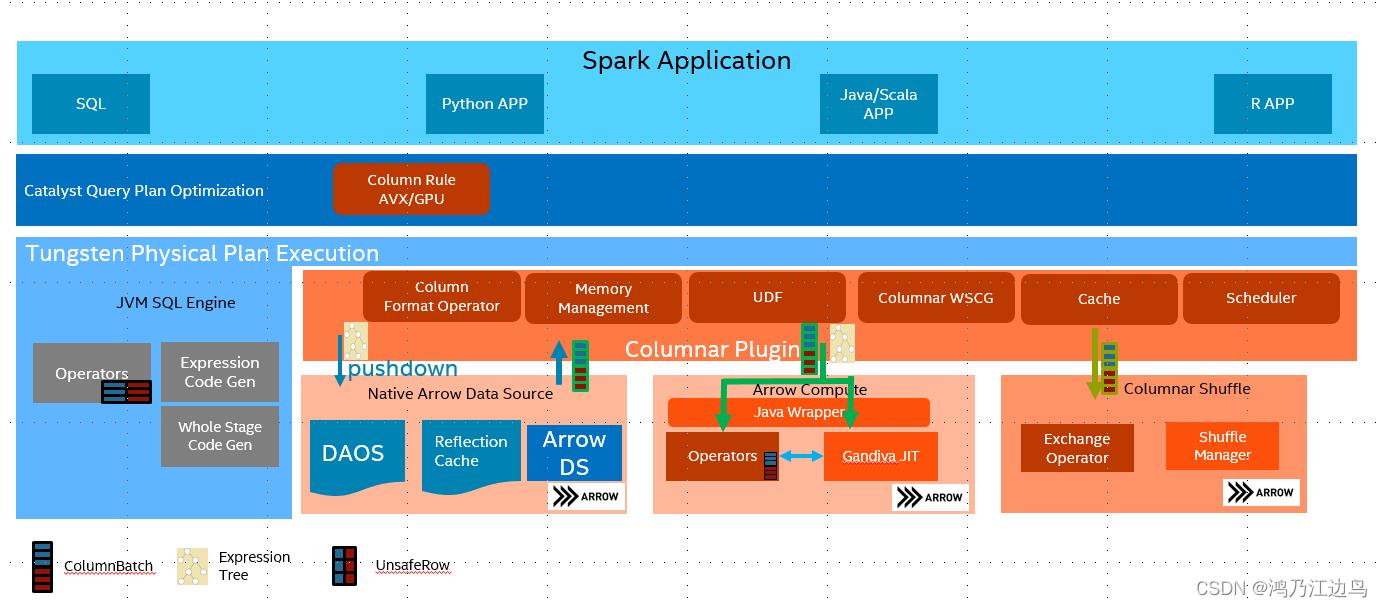
项目见:gazelle_plugin
blaze 和Arrow DataFusion
DataFusion(是Apache Arrow的一部分) 是用Rust语言实现的,使用Apache Arrow作为内存格式的向量化计算引擎框架,它支持用SQL和DataFrame API构建逻辑计划,以及能够使用线程对分区数据源(CSV 和 Parquet)并行执行的查询优化器和执行引擎。
项目见:arrow-datafusion(2k的星)
Blaze是基于 arrow datafusion 向量化执行引擎构建的 Spark 加速器。它从 Spark获取一个完全优化的物理计划,将其映射到 DataFusion 的执行计划中,并在Spark executor中计算,同时结合了DataFusion 库的强大功能和 Spark 分布式计算框架的可扩展性。
项目见:blaze-init/blaze
gluten
Intel开源的解藕spark jvm和native SQL执行引擎的项目,它利用substrait进行解藕,通过把spark的物理计划转换为对应的substrait plan,之后再传递到后台的native SQL backend执行引擎执行。当然也是利用了Apache Arrow作为数据存储。
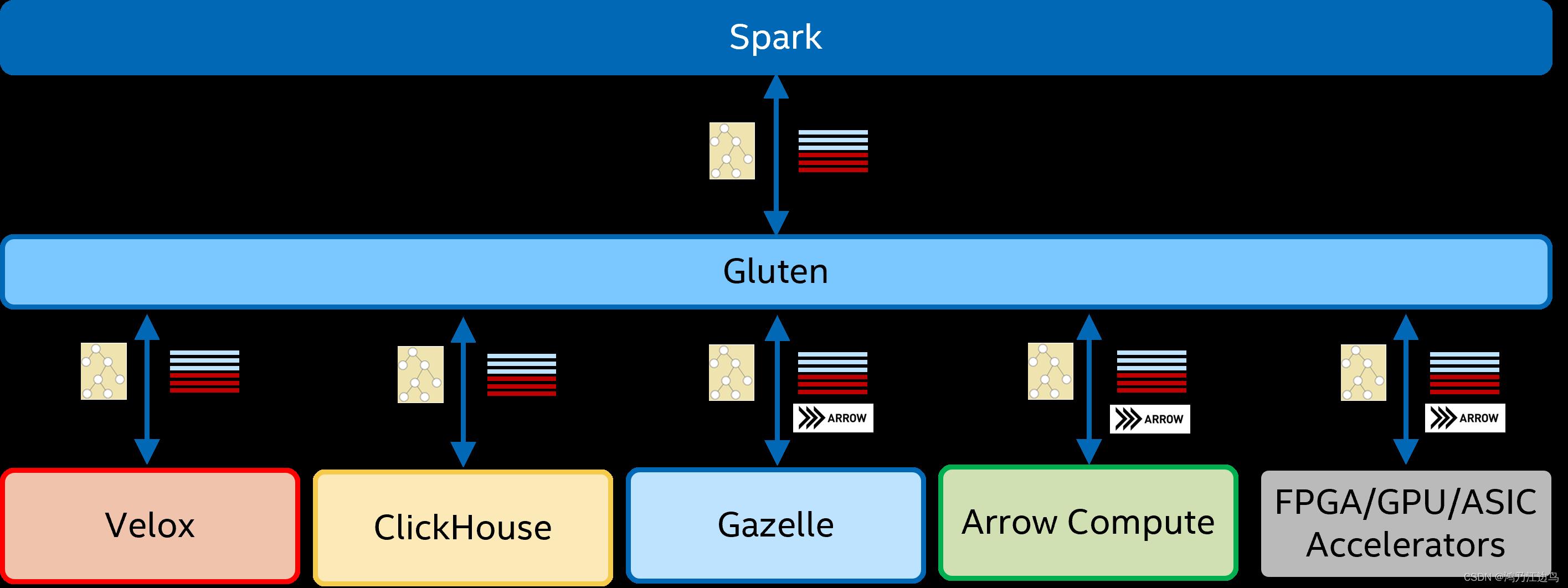
额外话题:columnar shuffle
我们知道在spark内部,spark的数据都是按行处理的,但是如果我们进行了native向量化以后,我们并不能保证spark的每个operator都能映射到native向量化算子(或者说spark内部的算子不是基于列来操作的),所以对于存在shuffle的operator算子来说就不适用基于行的shuffle操作,而是用基于列格式的shuffle,这样在operator计算的时候,就不需要进行Row2Columnar的操作,比如聚合操作:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-f3Vffjvn-1653881075595)(https://github.com/oap-project/gluten/blob/main/docs/image/flow.png)]
参考
本文参考了:
Velox: 现代化的向量化执行引擎
Announcing Photon Public Preview: The Next Generation Query Engine on the Databricks Lakehouse Platform
Apache Arrow Gandiva:远大理想与尴尬现实
以上是关于SPARK的计算向量化-已有的向量化项目的主要内容,如果未能解决你的问题,请参考以下文章