A Comprehensive Overhaul of Feature Distillation
Posted 爆米花好美啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了A Comprehensive Overhaul of Feature Distillation相关的知识,希望对你有一定的参考价值。
Motivation
ClovaAI今年ICCV做了还几篇总结性的工作,该篇也类似,先总结当下做feature distillation的各个方向,总体的pipeline是选取student和teacher网络结构的某个位置然后对特征进行变换,最后拉进他们的距离
- Teacher transform: 为了让teacher和student的feature map一样大(空间或者通道),会对teacher的feature上做reduce dim,但是这样会损失一部分信息,比如Attention Transfer是去除通道维度,在各个位置求和
- Student transform: 为了让teacher和student的feature map一样大(空间或者通道),会对student的feature进行变换,比如FitNets就加了1x1卷积,这样不会使student的feature信息产生丢失
- Distillation feature position: 在网络的哪些地方做feature distillation,Attention Transfer那篇文章在每组的最后一个输出都做,而FitNets仅在最后一组的最后输出做。
- Distance function: 最常用的就是L1、L2聚集
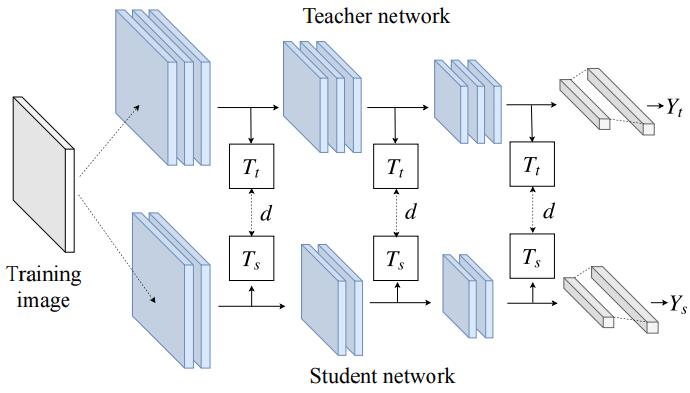
Method
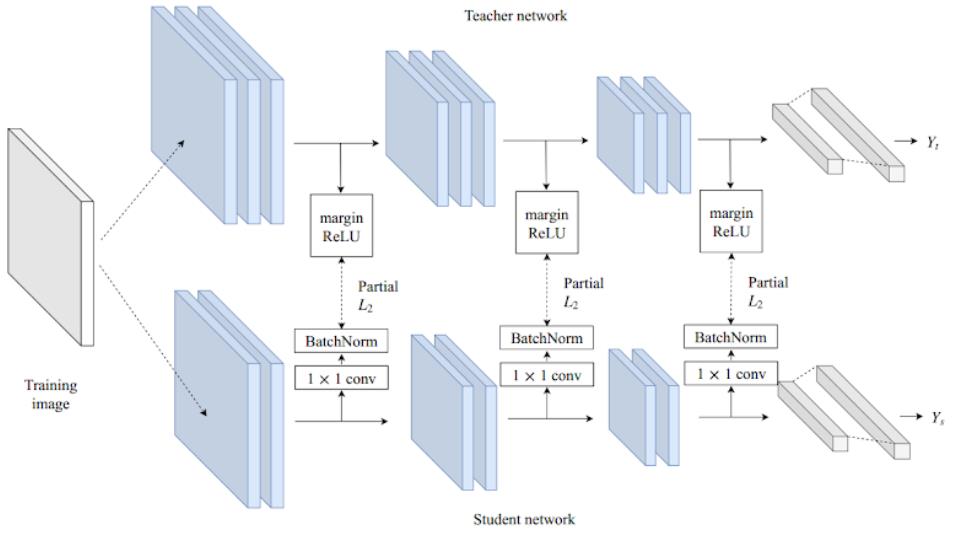
-
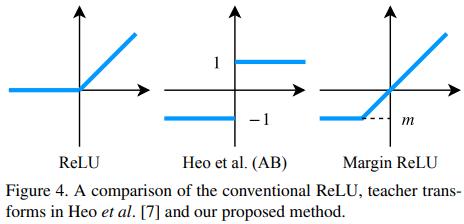
Teacher transform: 为了不丢失信息,采用margin ReLU,正值都保留,负值被抑制。这样的话就不用学习精确的“没有用”的负值,而集中精力学习“有用”的正值。而Heo提出的AB正值也不用学习精确,就舍弃太多了
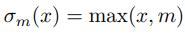
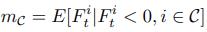 ,m是各个通道负值的期望,在训练中动态计算
,m是各个通道负值的期望,在训练中动态计算
-
Student transform: 采用和HitNets一样,在student后加1x1卷积
-
Distillation feature position: 在ReLu前,为了保留正值和负值
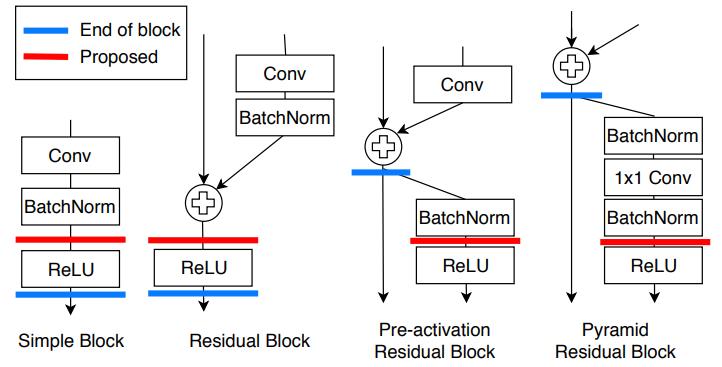
-
Distance function
我们的蒸馏是在ReLu前做的,如果teacher小于0时,student比它小就不必惩罚,因为经过ReLU后是一样的
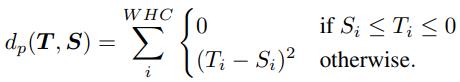
5. 总结
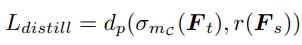
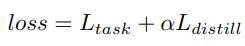
6. 其他细节
关于bn的问题,在进行KD时,teacher的bn应该是training mode,而且为了和teacher一致,我们在做student transform时1x1卷积后加了bn
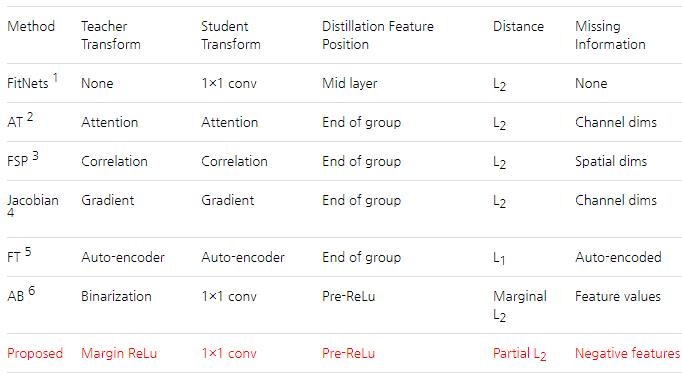
Experiments
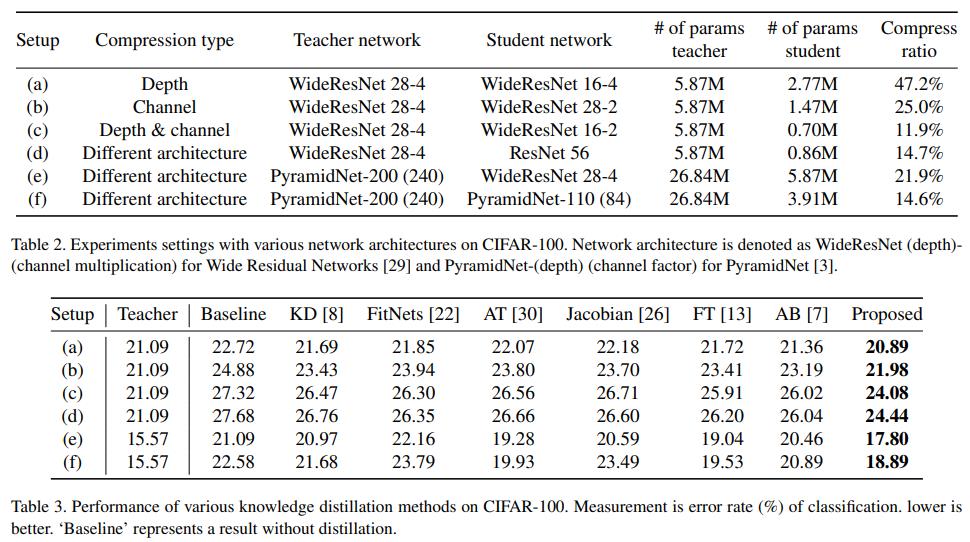
CIFAR100,22、13、7三种方法是feature distillation + output distillation,其他都是默认的无output distillation
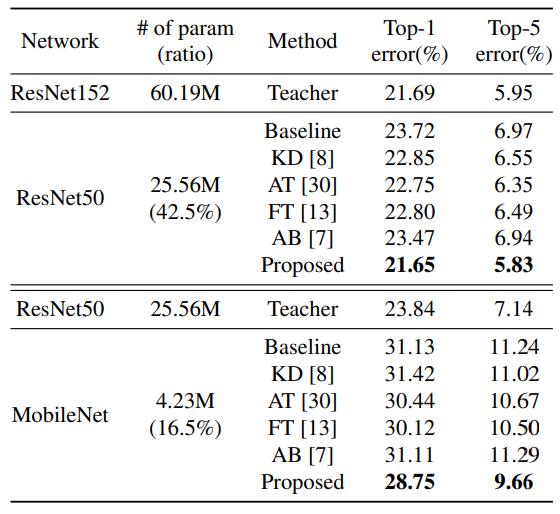
ImageNet,student ResNet50超过了ResNet152的性能
Object Detection、Semantic segmentation都有提升
Analysis
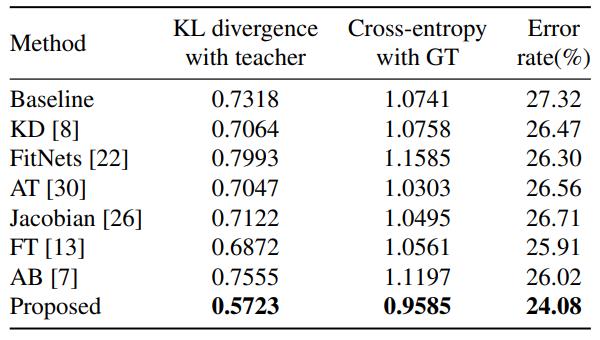
分析蒸馏到底有木有拉进teacher和student的距离
从下表看到,仅在训练早期进行蒸馏的方法如FitNets、AB,student和teacher的KL距离反而变大了。
训练过程中持续蒸馏的方法如KD、AT等确实拉进了KL距离,而我们的方法则把KL距离拉得更近,效果也最好
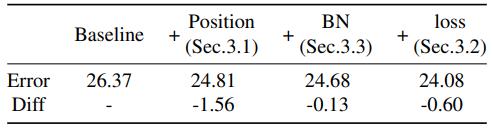
baseline是L2 loss用在每个阶段的最后一层输出,改变位置到ReLU前提升最多
 开发者涨薪指南
开发者涨薪指南
 48位大咖的思考法则、工作方式、逻辑体系
48位大咖的思考法则、工作方式、逻辑体系
以上是关于A Comprehensive Overhaul of Feature Distillation的主要内容,如果未能解决你的问题,请参考以下文章