大数据:Spark CoreDriver上的Task的生成分配调度
Posted raintungli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据:Spark CoreDriver上的Task的生成分配调度相关的知识,希望对你有一定的参考价值。
1. 什么是Task?
在前面的章节里描述过几个角色,Driver(Client),Master,Worker(Executor),Driver会提交Application到Master进行Worker上的Executor上的调度,显然这些都不是Task.
Spark上的几个关系可以这样理解:
- Application: Application是Driver在构建SparkContent的上下文的时候创建的,就像申报员,现在要构建一个能完成任务的集群,需要申报的是这次需要多少个Executor(可以简单理解为虚拟的机器),每个Executor需要多少CPU,多少内存。
- Job: 这是Driver在调用Action的时候生成的Job,让DAGScheduler线程进行最后的调度,代表着这时候RDD的状态分析完了,需要进行最后的Stage分析了,Job并不是提交给Executor运行的,一个Application存在多个Job
- Task: 一个Job可以分成多个Task, 相当于这些Task分到了一个Group里,这个Group的ID就是Job ID
2. Task的类型
Task的类型和Stage相关,关于Stage,以及Stage之间的相关依赖构成任务的不同提交,就不在这篇描述了
ShuffleMapStage 转化成 ShuffleMapTask
ResultStage 转化成为 ResultTask
当Spark上的action算子,通过DAG进行提交任务的时候,会通过Stage来决定提交什么类型的任务,具体的实现都在DAGScheduler.scala 的submitMissingTasks方法中。
3. 同一个Stage的Task数量
Spark是一个分布式的执行任务的框架,那么同一个Stage的并行任务的拆分就非常的重要,在任务的分解中并不只是stage的步骤的分解,同时也是对同一个Stage中的要分析的数据分解,而对数据的分解直接决定对同一个Stage所提交的任务的数量。对Stage的任务拆解决定着任务的之间的关系,而对同一个Stage的分析数据进行拆解控制着任务的数量。
比如基于拆解的分析数据的而执行的算子象map,这些任务都是独立的,并没有对数据进行最后的归并和整理,这些task是完全可以进行并行计算的,对同一个Stage的task的数量在Spark上是可以控制的。
在这里以ParallelCollectionRDD为简单的例子,先看DAGScheduler.submitMissingTasks的方法
private def submitMissingTasks(stage: Stage, jobId: Int)
logDebug("submitMissingTasks(" + stage + ")")
// Get our pending tasks and remember them in our pendingTasks entry
stage.pendingPartitions.clear()
// First figure out the indexes of partition ids to compute.
val partitionsToCompute: Seq[Int] = stage.findMissingPartitions()
。。。。。。。。。。。
val tasks: Seq[Task[_]] = try
stage match
case stage: ShuffleMapStage =>
partitionsToCompute.map id =>
val locs = taskIdToLocations(id)
val part = stage.rdd.partitions(id)
new ShuffleMapTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, stage.latestInfo.taskMetrics, properties, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId)
case stage: ResultStage =>
partitionsToCompute.map id =>
val p: Int = stage.partitions(id)
val part = stage.rdd.partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, id, properties, stage.latestInfo.taskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId)
catch
case NonFatal(e) =>
abortStage(stage, s"Task creation failed: $e\\n$Utils.exceptionString(e)", Some(e))
runningStages -= stage
return
生产task的数量是由val partitionsToCompute: Seq[Int] = stage.findMissingPartitions()来决定的,在ShuffleMapStage里
override def findMissingPartitions(): Seq[Int] =
val missing = (0 until numPartitions).filter(id => outputLocs(id).isEmpty)
assert(missing.size == numPartitions - _numAvailableOutputs,
s"$missing.size missing, expected $numPartitions - _numAvailableOutputs")
missing
可以看到具体是由numPartitions来决定的,在来看numPartitions
val numPartitions = rdd.partitions.length在MapPartitionsRDD来说的partitions
override def getPartitions: Array[Partition] = firstParent[T].partitionssparkcontext.parallelize(exampleApacheLogs)override def getPartitions: Array[Partition] =
val slices = ParallelCollectionRDD.slice(data, numSlices).toArray
slices.indices.map(i => new ParallelCollectionPartition(id, i, slices(i))).toArray
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope
assertNotStopped()
new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]())
def defaultParallelism: Int =
assertNotStopped()
taskScheduler.defaultParallelism
override def defaultParallelism(): Int = backend.defaultParallelism()
在CoarseGrainedSchedulerBackend.scala 的类中:
override def defaultParallelism(): Int =
conf.getInt("spark.default.parallelism", math.max(totalCoreCount.get(), 2))
默认的值是受以下控制:
- 配置文件spark.default.parallelism
- totalCoreCount 的值: CoarseGrainedSchedulerBackend是一个executor管理的backend,里面维护着executor的信息,totalCoreCount就是executor汇报上来的核数,注意因为executor汇报自己是在application分配好后发生的,汇报的信息和获取totalCoreCount的线程是异步的,也就是如果executor没有汇报上来,totalCoreCount.get()的值并不准确(根绝Master对executor的分配策略,是无法保证分配多少个executor, 在这里spark更依赖executor主动的向driver汇报),这里的策略是无法保证准确的获取executor的核数。
- 如果没有设置spark.default.parallelism,最小值是2
依赖于rdd.partitions的策略,最后决定task的分配数量。
4. Task的提交和调度分配
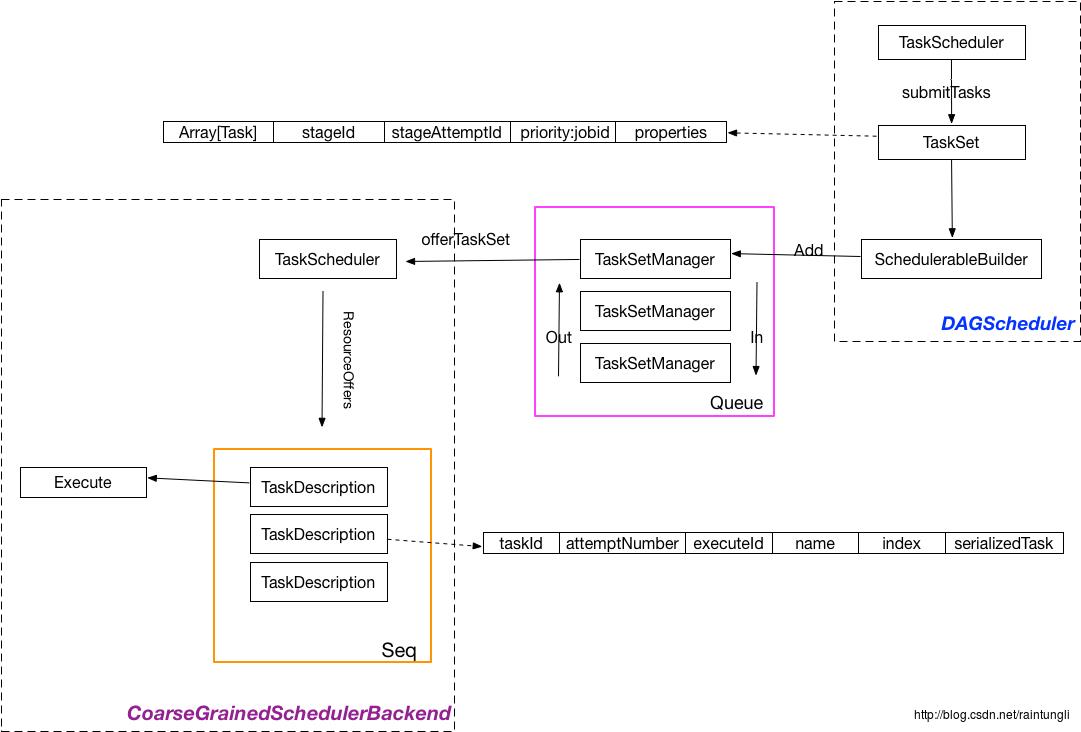
在本篇中主要描述集群下的任务调度
4.1 Task的提交
在DAGScheduler将一个Stage中所分配的Task形成一个TaskSet进行提交,在TaskSet里所保存的是Task的集合,还有Stage的Id,以及JobId,注意在这里JobId是作为一个优先级的参数,作为后序队列调度的参数。
在TaskSchedulerImpl.scala中
override def submitTasks(taskSet: TaskSet)
val tasks = taskSet.tasks
logInfo("Adding task set " + taskSet.id + " with " + tasks.length + " tasks")
this.synchronized
val manager = createTaskSetManager(taskSet, maxTaskFailures)
val stage = taskSet.stageId
val stageTaskSets =
taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager])
stageTaskSets(taskSet.stageAttemptId) = manager
val conflictingTaskSet = stageTaskSets.exists case (_, ts) =>
ts.taskSet != taskSet && !ts.isZombie
if (conflictingTaskSet)
throw new IllegalStateException(s"more than one active taskSet for stage $stage:" +
s" $stageTaskSets.toSeq.map_._2.taskSet.id.mkString(",")")
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
if (!isLocal && !hasReceivedTask)
starvationTimer.scheduleAtFixedRate(new TimerTask()
override def run()
if (!hasLaunchedTask)
logWarning("Initial job has not accepted any resources; " +
"check your cluster UI to ensure that workers are registered " +
"and have sufficient resources")
else
this.cancel()
, STARVATION_TIMEOUT_MS, STARVATION_TIMEOUT_MS)
hasReceivedTask = true
backend.reviveOffers()

- FIFOSchedulableBuilder: 单一pool
- FairSchedulableBuilder: 多个pool
4.1.1 FairSchedulableBuilder pool池
通过fairsscheduler.xml的模版来设置参数来控制pool的调度
<allocations>
<pool name="production1">
<schedulingMode>FAIR</schedulingMode>
<weight>3</weight>
<minShare>4</minShare>
</pool>
<pool name="production2">
<schedulingMode>FAIR</schedulingMode>
<weight>5</weight>
<minShare>2</minShare>
</pool>
</allocations>参数的定义:
- name: 调度池的名称,可根据该参数使用指定pool,EX: sc.setLocalProperty("spark.scheduler.pool", "production1")
- weight: 调度池的权重,调度池根据该参数分配资源。
- minShare: 调度池需要的最小资源数(CPU核数),公平调度器首先会尝试为每个调度池分配最少minShare资源,然后剩余资源才会按照weight大小继续分配
- schedulingMode: 调度池内的调度模式
在TaskSchedulerImpl在submitTasks添加TaskSetManager到pool后,调用了backend.reviveOffers();
override def reviveOffers()
driverEndpoint.send(ReviveOffers)
是向driver的endpoint发送了reviveoffers的消息,Spark中的许多操作都是通过消息来传递的,哪怕DAGScheduler的线程和endpoint的线程都是同一个Driver进程4.2 Task的分配
Netty 的dispatcher线程接受到revievoffers的消息后,CoarseGrainedSchedulerBackend
case ReviveOffers =>
makeOffers()调用了makeoffers函数
private def makeOffers()
// Filter out executors under killing
val activeExecutors = executorDataMap.filterKeys(executorIsAlive)
val workOffers = activeExecutors.map case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores)
.toIndexedSeq
launchTasks(scheduler.resourceOffers(workOffers))
makeOffers里进行了资源的调度,netty中接收所有的信息,同时也在CoarseGrainedSchedulerBackend中维护着executor的状态map:executorDataMap,executor的状态是executor主动汇报的。
通过scheduler.resourceOffers来进行task的资源分配到executor中
def resourceOffers(offers: IndexedSeq[WorkerOffer]): Seq[Seq[TaskDescription]] = synchronized
// Mark each slave as alive and remember its hostname
// Also track if new executor is added
var newExecAvail = false
for (o <- offers)
if (!hostToExecutors.contains(o.host))
hostToExecutors(o.host) = new HashSet[String]()
if (!executorIdToRunningTaskIds.contains(o.executorId))
hostToExecutors(o.host) += o.executorId
executorAdded(o.executorId, o.host)
executorIdToHost(o.executorId) = o.host
executorIdToRunningTaskIds(o.executorId) = HashSet[Long]()
newExecAvail = true
for (rack <- getRackForHost(o.host))
hostsByRack.getOrElseUpdate(rack, new HashSet[String]()) += o.host
// Randomly shuffle offers to avoid always placing tasks on the same set of workers.
val shuffledOffers = Random.shuffle(offers)
// Build a list of tasks to assign to each worker.
val tasks = shuffledOffers.map(o => new ArrayBuffer[TaskDescription](o.cores))
val availableCpus = shuffledOffers.map(o => o.cores).toArray
val sortedTaskSets = rootPool.getSortedTaskSetQueue
for (taskSet <- sortedTaskSets)
logDebug("parentName: %s, name: %s, runningTasks: %s".format(
taskSet.parent.name, taskSet.name, taskSet.runningTasks))
if (newExecAvail)
taskSet.executorAdded()
// Take each TaskSet in our scheduling order, and then offer it each node in increasing order
// of locality levels so that it gets a chance to launch local tasks on all of them.
// NOTE: the preferredLocality order: PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY
for (taskSet <- sortedTaskSets)
var launchedAnyTask = false
var launchedTaskAtCurrentMaxLocality = false
for (currentMaxLocality <- taskSet.myLocalityLevels)
do
launchedTaskAtCurrentMaxLocality = resourceOfferSingleTaskSet(
taskSet, currentMaxLocality, shuffledOffers, availableCpus, tasks)
launchedAnyTask |= launchedTaskAtCurrentMaxLocality
while (launchedTaskAtCurrentMaxLocality)
if (!launchedAnyTask)
taskSet.abortIfCompletelyBlacklisted(hostToExecutors)
if (tasks.size > 0)
hasLaunchedTask = true
return tasks
- 随机化了有效的executor的列表,为了均匀的分配
- 获取池里(前面已经提过油两种池)的排号序的taskSetManager的队列
- 对taskSetManager里面的task集合进行调度分配
4.2.1 taskSetManager队列的排序
这里的排序是对单个Pool里的taskSetManager进行排序,Spark有两种排序算法 var taskSetSchedulingAlgorithm: SchedulingAlgorithm =
schedulingMode match
case SchedulingMode.FAIR =>
new FairSchedulingAlgorithm()
case SchedulingMode.FIFO =>
new FIFOSchedulingAlgorithm()
case _ =>
val msg = "Unsupported scheduling mode: $schedulingMode. Use FAIR or FIFO instead."
throw new IllegalArgumentException(msg)
在这里就简单介绍FIFOSchedulingAlgorithm的算法
private[spark] class FIFOSchedulingAlgorithm extends SchedulingAlgorithm
override def comparator(s1: Schedulable, s2: Schedulable): Boolean =
val priority1 = s1.priority
val priority2 = s2.priority
var res = math.signum(priority1 - priority2)
if (res == 0)
val stageId1 = s1.stageId
val stageId2 = s2.stageId
res = math.signum(stageId1 - stageId2)
res < 0
4.2.2 单个TaskSetManager的task调度
TaskSetManager 里保存了TaskSet,也就是DAGScheduler里生成的tasks的集合,在TaskSchedulerImpl.scala中进行了单个的TaskSetManager进行调度private def resourceOfferSingleTaskSet(
taskSet: TaskSetManager,
maxLocality: TaskLocality,
shuffledOffers: Seq[WorkerOffer],
availableCpus: Array[Int],
tasks: IndexedSeq[ArrayBuffer[TaskDescription]]) : Boolean =
var launchedTask = false
for (i <- 0 until shuffledOffers.size)
val execId = shuffledOffers(i).executorId
val host = shuffledOffers(i).host
if (availableCpus(i) >= CPUS_PER_TASK)
try
for (task <- taskSet.resourceOffer(execId, host, maxLocality))
tasks(i) += task
val tid = task.taskId
taskIdToTaskSetManager(tid) = taskSet
taskIdToExecutorId(tid) = execId
executorIdToRunningTaskIds(execId).add(tid)
availableCpus(i) -= CPUS_PER_TASK
assert(availableCpus(i) >= 0)
launchedTask = true
catch
case e: TaskNotSerializableException =>
logError(s"Resource offer failed, task set $taskSet.name was not serializable")
// Do not offer resources for this task, but don't throw an error to allow other
// task sets to be submitted.
return launchedTask
return launchedTask
在这里,我们看到了一个参数CPUS_PER_TASK
val CPUS_PER_TASK = conf.getInt("spark.task.cpus", 1)通过计算每个executor的剩余资源,决定是否需要从tasksetmanager里分配出task.
def resourceOffer(
execId: String,
host: String,
maxLocality: TaskLocality.TaskLocality)
: Option[TaskDescription] =
.....
dequeueTask(execId, host, allowedLocality).map case ((index, taskLocality, speculative)) =>
......
new TaskDescription(taskId = taskId, attemptNumber = attemptNum, execId,
taskName, index, serializedTask)
else
None
核心函数dequeueTask
private def dequeueTask(execId: String, host: String, maxLocality: TaskLocality.Value)
: Option[(Int, TaskLocality.Value, Boolean)] =
for (index <- dequeueTaskFromList(execId, host, getPendingTasksForExecutor(execId)))
return Some((index, TaskLocality.PROCESS_LOCAL, false))
if (TaskLocality.isAllowed(maxLocality, TaskLocality.NODE_LOCAL))
for (index <- dequeueTaskFromList(execId, host, getPendingTasksForHost(host)))
return Some((index, TaskLocality.NODE_LOCAL, false))
if (TaskLocality.isAllowed(maxLocality, TaskLocality.NO_PREF))
// Look for noPref tasks after NODE_LOCAL for minimize cross-rack traffic
for (index <- dequeueTaskFromList(execId, host, pendingTasksWithNoPrefs))
return Some((index, TaskLocality.PROCESS_LOCAL, false))
if (TaskLocality.isAllowed(maxLocality, TaskLocality.RACK_LOCAL))
for
rack <- sched.getRackForHost(host)
index <- dequeueTaskFromList(execId, host, getPendingTasksForRack(rack))
return Some((index, TaskLocality.RACK_LOCAL, false))
if (TaskLocality.isAllowed(maxLocality, TaskLocality.ANY))
for (index <- dequeueTaskFromList(execId, host, allPendingTasks))
return Some((index, TaskLocality.ANY, false))
// find a speculative task if all others tasks have been scheduled
dequeueSpeculativeTask(execId, host, maxLocality).map
case (taskIndex, allowedLocality) => (taskIndex, allowedLocality, true)
在Spark中为了尽量分配任务到task所需的资源的本地,依据task里的preferredLocations所保存的需要资源的位置进行分配
- 尽量分配到task到task所需资源相同的executor里执行,比如ExecutorCacheTaskLocation,HDFSCacheTaskLocation
- 尽量分配到task里task所需资源相通的host里执行
- task的数组从最后向前开始分配
分配完生成TaskDescription,里面记录着taskId, execId, task在数组的位置,和task的整个序列化的内容
4.2.3 Launch Tasks
private def launchTasks(tasks: Seq[Seq[TaskDescription]])
for (task <- tasks.flatten)
val serializedTask = ser.serialize(task)
if (serializedTask.limit >= maxRpcMessageSize)
scheduler.taskIdToTaskSetManager.get(task.taskId).foreach taskSetMgr =>
try
var msg = "Serialized task %s:%d was %d bytes, which exceeds max allowed: " +
"spark.rpc.message.maxSize (%d bytes). Consider increasing " +
"spark.rpc.message.maxSize or using broadcast variables for large values."
msg = msg.format(task.taskId, task.index, serializedTask.limit, maxRpcMessageSize)
taskSetMgr.abort(msg)
catch
case e: Exception => logError("Exception in error callback", e)
else
val executorData = executorDataMap(task.executorId)
executorData.freeCores -= scheduler.CPUS_PER_TASK
logDebug(s"Launching task $task.taskId on executor id: $task.executorId hostname: " +
s"$executorData.executorHost.")
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
这里的逻辑就相对比较简单,TaskDescription里面包含着executorId,而CoarseGrainedSchedulerBackend里有executor的信息,根据executorId获取到executor的通讯端口,发送LunchTask的信息。
这里有个RPC的消息的大小控制,如果序列化的task的内容超过了最大RPC的消息,这个任务会被丢弃
/** Returns the configured max message size for messages in bytes. */
def maxMessageSizeBytes(conf: SparkConf): Int =
val maxSizeInMB = conf.getInt("spark.rpc.message.maxSize", 128)
if (maxSizeInMB > MAX_MESSAGE_SIZE_IN_MB)
throw new IllegalArgumentException(
s"spark.rpc.message.maxSize should not be greater than $MAX_MESSAGE_SIZE_IN_MB MB")
maxSizeInMB * 1024 * 1024
以上是关于大数据:Spark CoreDriver上的Task的生成分配调度的主要内容,如果未能解决你的问题,请参考以下文章