大数据:Spark CoreExecutor上是如何launch task
Posted raintungli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据:Spark CoreExecutor上是如何launch task相关的知识,希望对你有一定的参考价值。
1. 启动任务
在前面一篇博客中( Driver 启动、分配、调度Task)介绍了Driver是如何调动、启动任务的,Driver向Executor发送了LaunchTask的消息,Executor接收到了LaunchTask的消息后,进行了任务的启动,在CoarseGrainedExecutorBackend.scala case LaunchTask(data) =>
if (executor == null)
exitExecutor(1, "Received LaunchTask command but executor was null")
else
val taskDesc = ser.deserialize[TaskDescription](data.value)
logInfo("Got assigned task " + taskDesc.taskId)
executor.launchTask(this, taskId = taskDesc.taskId, attemptNumber = taskDesc.attemptNumber,
taskDesc.name, taskDesc.serializedTask)
接收消息,反序列化了TaskDescription的对象
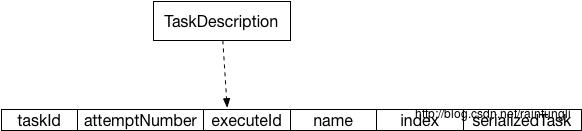
在TaskDescription反序列化了taskId, executeId, name,index, attemptNumber, serializedTask属性,其中serializedTask是ByteBuffer。 Executor的launchTask方法
def launchTask(
context: ExecutorBackend,
taskId: Long,
attemptNumber: Int,
taskName: String,
serializedTask: ByteBuffer): Unit =
val tr = new TaskRunner(context, taskId = taskId, attemptNumber = attemptNumber, taskName,
serializedTask)
runningTasks.put(taskId, tr)
threadPool.execute(tr)
private val threadPool = ThreadUtils.newDaemonCachedThreadPool("Executor task launch worker")2. 任务的运行
前面提到了TaskDescription中的serializedTask是个bytebuffer, 里面的结构如下图所示: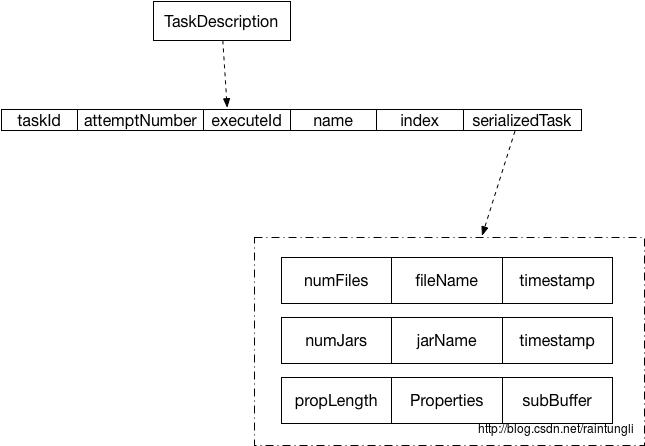
分别是task所依赖的文件的数量,文件的名字,时间戳,Jar的数量,Jar的名字,Jar的时间戳,属性,subBuffer是个bytebuffer
2.1 加载Jars文件
Driver所运行的class等包括依赖的Jar文件在Executor上并不存在,Executor首先要fetch所依赖的jars,也就是TaskDescription中serializedTask中的jar部分 在上面的结构描述中,jar相关的只是numJars,jarName,timestamp并没有jar的内容,也就是在LaunchTask里的消息中并不携带Jar的内容,原因也很容易理解,rpc的消息体必须简单高效- timestamp:这是用于判断文件的时间戳,在相同文件名的情况下只有新的才需要重新fetch
- jarName: 这里的JarName是网络文件名:spark://192.168.121.101:37684/jars/spark-examples_2.11-2.1.0.jar
通常在相同的Driver在起多个任务的时候,任务的所依赖的jar是基本相同的,所以没必要每个Task都重新fetch相同的jars
for ((name, timestamp) <- newJars)
val localName = name.split("/").last
val currentTimeStamp = currentJars.get(name)
.orElse(currentJars.get(localName))
.getOrElse(-1L)
if (currentTimeStamp < timestamp)
logInfo("Fetching " + name + " with timestamp " + timestamp)
// Fetch file with useCache mode, close cache for local mode.
Utils.fetchFile(name, new File(SparkFiles.getRootDirectory()), conf,
env.securityManager, hadoopConf, timestamp, useCache = !isLocal)
currentJars(name) = timestamp
// Add it to our class loader
val url = new File(SparkFiles.getRootDirectory(), localName).toURI.toURL
if (!urlClassLoader.getURLs().contains(url))
logInfo("Adding " + url + " to class loader")
urlClassLoader.addURL(url)
spark.files.useFetchCache/tmp/spark-e9555893-6556-4a56-a692-54a984c3addb/executor-4b9581ca-fe9f-4e96-9db0-192146158a44/spark-bf41fdbd-a84e-473a-aa60-76480745b50b缓存文件的命名规则:
s"$url.hashCode$timestamp_cache"- 检查本地是否有相同的缓存文件
- 如果没有,先Fetch文件从Driver中获取,通过URL:(
spark://192.168.121.101:37684/jars/spark-examples_2.11-2.1.0.jar
)复制到本地的缓存文件 - 复制本地缓存文件到工作目录 /work/app-ID/executorid/
- 设置工作目录文件具有可执行权限
2.2 运行task
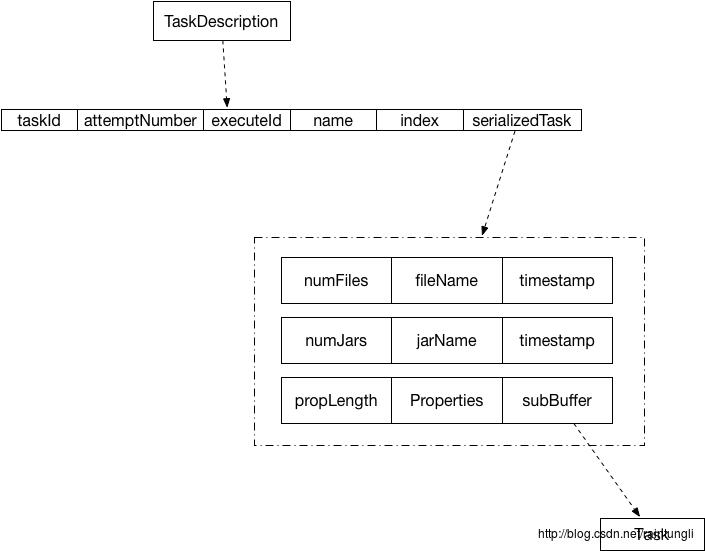
前面所提到的subBuffer实际上就是Task的序列化对象,通过反序列化可以获取到Driver生成的Task 在Executor.scala里的run方法中
val res = task.run(
taskAttemptId = taskId,
attemptNumber = attemptNumber,
metricsSystem = env.metricsSystem)最后调用了task.run的方法,在task的run方法,所有继承了Task的类都只需要实现runTask的方法
2.3 反序列化RDD,Dependency
RDD是算子,Dependency是依赖,这是在Executor需要的运算,但是在前面的序列化对象中,并没有看到有RDD,Dep的属性,那么RDD,Dep是怎么传递到Task里进行运算的呢? 在DAG里生成的task就是ShuffleMapTask, ResultTask,下面以ShuffleMapTask为例,在runTask里 val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
_executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported)
threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime
else 0LtaskBinary: Broadcast[Array[Byte]], /** Get the broadcasted value. */
def value: T =
assertValid()
getValue()
@transient private lazy val _value: T = readBroadcastBlock()broadcast_executorIDbroadcast_executorID_pieceidval blocks = readBlocks().flatMap(_.getChunks())
logInfo("Reading broadcast variable " + id + " took" + Utils.getUsedTimeMs(startTimeMs))
val obj = TorrentBroadcast.unBlockifyObject[T](
blocks, SparkEnv.get.serializer, compressionCodec)
// Store the merged copy in BlockManager so other tasks on this executor don't
// need to re-fetch it.
val storageLevel = StorageLevel.MEMORY_AND_DISK
if (!blockManager.putSingle(broadcastId, obj, storageLevel, tellMaster = false))
throw new SparkException(s"Failed to store $broadcastId in BlockManager")
在远端获取多个piece块后,在blockManager里会合成一个以broadcast_executorID为key的大block块保存在blockManager里,作为缓存同一个executor下的其他运行的task直接使用blockManager里的块,而不在需要远端在去获取block。 在这里blockManager同时也保存着每个piece的block快,主要考虑到TorrentBroadcast的时候,Executor也可以作为一个传播block块的节点,而不只是Driver的单个节点。 Block里面的内容反序列化后生成RDD和Dependency对象。
2.4 序列化RDD,Dependency
前面讲了executor的反序列化的过程,当然序列化过程是在Driver中做的,回到DAGScheduler.scala的submitMissingTasks函数中 var taskBinary: Broadcast[Array[Byte]] = null
try
// For ShuffleMapTask, serialize and broadcast (rdd, shuffleDep).
// For ResultTask, serialize and broadcast (rdd, func).
val taskBinaryBytes: Array[Byte] = stage match
case stage: ShuffleMapStage =>
JavaUtils.bufferToArray(
closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef))
case stage: ResultStage =>
JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.func): AnyRef))
taskBinary = sc.broadcast(taskBinaryBytes)
catch
// In the case of a failure during serialization, abort the stage.
case e: NotSerializableException =>
abortStage(stage, "Task not serializable: " + e.toString, Some(e))
runningStages -= stage
// Abort execution
return
case NonFatal(e) =>
abortStage(stage, s"Task serialization failed: $e\\n$Utils.exceptionString(e)", Some(e))
runningStages -= stage
return
3 总结:
- TaskDescription 只是包含了任务需要的文件列表,jar文件,配置相关属性,并没有这些具体的文件
- 具体的文件下载路径是Driver直接在TaskDescription中的serializedTask提供的
- 具体要运行的Task是通过serializedTask中的subbuffer中反序列化的
- Task中依赖的RDD,Dependency是从BlockManager从Driver的Block快中获取进行反序列化
- ShuffleMapTask里依赖的的RDD是ShuffledRDD的前一个RDD,而Dependency就是ShuffleDependency
以上是关于大数据:Spark CoreExecutor上是如何launch task的主要内容,如果未能解决你的问题,请参考以下文章