案例分享:如何通过JVM crash 的日志和core dump定位和分析Instrument引起的JVM crash
Posted raintungli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了案例分享:如何通过JVM crash 的日志和core dump定位和分析Instrument引起的JVM crash相关的知识,希望对你有一定的参考价值。
1. JVM crash了
产品发来一份crash report, 什么是crash report请参考我的前期博客( http://blog.csdn.net/raintungli/article/details/7642575),下面是截取了crash report的部分,用于分析:# Problematic frame:
# V [libjvm.so+0x5bbf05] instanceKlass::oop_follow_contents(ParCompactionManager*, oopDesc*)+0x2c5
Stack 信息:
Stack: [0x00007fa9482b3000,0x00007fa9483b4000], sp=0x00007fa9483b2a10, free space=1022k
Native frames: (J=compiled Java code, j=interpreted, Vv=VM code, C=native code)
V [libjvm.so+0x5bbf05] instanceKlass::oop_follow_contents(ParCompactionManager*, oopDesc*)+0x2c5
V [libjvm.so+0x87504c] ParCompactionManager::follow_marking_stacks()+0x1ec
V [libjvm.so+0x85c138] MarkFromRootsTask::do_it(GCTaskManager*, unsigned int)+0x78
V [libjvm.so+0x55813f] GCTaskThread::run()+0x12f
V [libjvm.so+0x821ca8] java_start(Thread*)+0x108- 看到里面的栈信息是GCTaskThread线程,初步判断在执行GC的时候发生了crash,代码段在0x5bbf05,函数是instanceKlass::oop_follow_content。
- InstanceKlass 就是我们常说的class对象,因为是在GC的时候出现问题,具体的代码段通常是在GC部分并不能容易的判断发生了什么,而我们更需要知道的是GC的时候在处理哪个对象出了问题
2. GC 的参数
JVM在GC的控制参数中,有一个GC前进行校验的参数,在校验过程中当发生地址异常的化会打印出异常的地址,并且让JVM crash,因为这个参数每一次GC都要检查,包括新生代的GC,影响一定的性能,并不适合在产品环境中使用,但对发现GC中的对象问题,却非常有帮助。-XX:+VerifyBeforeGC -XX:+VerifyAfterGCFailed: 0x000000079ac5fe30 -> 0x0000000410bc55c03. SA 工具之CLHSDB
知道错误的对象地址,需要分析core dump知道哪个对象出了问题,在Linux上通常会用GDB,但是这并不适合分析我们初学者,尤其是我们并不是非常清楚对象的结构和布局,我们需要利用JMV提供的SA工具 JVM提供的HSDB工具是一款非常好的工具,通过工具能查看和分析运行中的JVM的heap对象,当然也可以常看core dump, 但问题是HSDB是有UI界面的,我们在linux系统中通常没有UI界面,用过HSDB工具,可以发现当我们启动命令控制台的时候,实际上HSDB是把CLHSDB嵌入在了HSDB的图形界面里,那我们可以使用CLHSDB来通过命令行的方式进行dump分析,关于如何使用HSDB工具,可参考 博客3.1 如何启动CLHSDB
java -cp .:$JAVA_HOME/lib/sa-jdi.jar sun.jvm.hotspot.CLHSDBjava -cp .:$JAVA_HOME/lib/sa-jdi.jar sun.jvm.hotspot.CLHSDB $JAVA_HOME/bin/java 99083- 版本问题,如果产品上装了多个JVM环境的化,注意core dump要和JVM的分析的版本一致
- SA环境需要root权限
3.2 分析对象
在前面提到的日志中,错误的对象地址是: Failed: 0x000000079ac5fe30 -> 0x0000000410bc55c0先扫描一下0x000000079ac5fe30附近的地址的对象
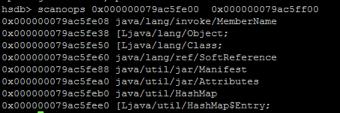
可以看到0x000000079ac5fe30地址最近的对象的地址0x000000079ac5fe08这是一个MemberName对象,继续查看地址0x000000079ac5fe30的内容
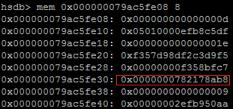
查看一下地址0x0000000782178ab8的对象,就是一个method的对象

这样我们就能构建了地址的 0x000000079ac5fe30对象
- 地址0x000000079ac5fe30 是属于0x000000079ac5fe08地址的对象的成员,也就是MemberName对象的成员
- 通过0x0000000782178ab8的地址分析,这是一个reinvokeTarget的method的地址
final class More ...MemberName implements Member, Cloneable
73 private Class<?> clazz; // class in which the method is defined
74 private String name; // may be null if not yet materialized
75 private Object type; // may be null if not yet materialized
76 private int flags; // modifier bits; see reflect.Modifier
77 //@Injected JVM_Method* vmtarget;
78 //@Injected int vmindex;
79 private Object resolution; // if null, this guy is resolved
但是有点不对,刚才不是地址是 0x0000000410bc55c0,怎么现在变成了0x0000000782178ab8? 要知道这两个地址为何不一样,我们先要对应代码段,地址 0x0000000410bc55c0是怎么获取到的?Crash report里会有堆栈信息 crash report就不贴了,最后调用的是VerifyFieldColsure:do_oop
class VerifyFieldClosure: public OopClosure
protected:
template <class T> void do_oop_work(T* p)
guarantee(Universe::heap()->is_in_closed_subset(p), "should be in heap");
oop obj = oopDesc::load_decode_heap_oop(p);
if (!obj->is_oop_or_null())
tty->print_cr("Failed: " PTR_FORMAT " -> " PTR_FORMAT, p, (address)obj);
Universe::print();
guarantee(false, "boom");
public:
virtual void do_oop(oop* p) VerifyFieldClosure::do_oop_work(p);
virtual void do_oop(narrowOop* p) VerifyFieldClosure::do_oop_work(p);
;日志里打印的
Failed: 0x000000079ac5fe30 -> 0x0000000410bc55c0inline oop oopDesc::load_decode_heap_oop_not_null(oop* p) return *p;
inline oop oopDesc::load_decode_heap_oop_not_null(narrowOop* p)
return decode_heap_oop_not_null(*p);
3. 指针的压缩
在继续分析下去之前,我们先要介绍oop, narrowOop的背景在JVM 1.6后面为了节省heap的堆内存会使用压缩指针地址的设计,因为对象结构里指向别的对象是指针引用oop,这个地址是保存在Heap中的,保存Bit 64的地址太浪费Heap空间,所以JVM里保存了一个以heap的基地址为基本地址,计算对象真实地址和基本地址差值并且通过位移(shift)来节省空间,该指针定义为narrow_oop而不同于常见的oop
| 一个小坑:虽然使用了narrow_oop,当指定的heap的地址空间低于一个阀值的情况下会将narrow_oop的基地址和shift都设置为0,也就是不压缩指针可以通过设置参数:-XX:+PrintCompressedOopsMode 打印来判断narrowoop的base和shift |
0x0000000410bc55c0 是个无效地址,而0x0000000782178ab8却是个有效地址,对应的是method instance同时也能匹配上MemberName.vmtarget,我们可以认为0x0000000782178ab8的地址是有效的,为何JVM通过decode地址是0x0000000410bc55c0确实个无效地址,非常有可能存在JVM并没有把压缩后的地址保存在vmtarget中,而是直接把真实的地址赋给了vmtarget,为了猜测是否有效,我们来看jvm的代码
void java_lang_invoke_MemberName::adjust_vmtarget(oop mname, oop ref)
mname->address_field_put(_vmtarget_offset, (address)ref);
4. MethodHandler
虽然我们找到了JVM crash问题的根因,但我们还需要继续深入的找到谁才是罪魁祸首,就是JVM为何会调整vmtarget的值 分析谁调用了adjust_vmtarget函数即可 void MemberNameTable::adjust_method_entries(methodOop* old_methods, methodOop* new_methods,
int methods_length, bool *trace_name_printed)
assert(SafepointSynchronize::is_at_safepoint(), "only called at safepoint");
- // search the MemberNameTable for uses of either obsolete or EMCP methods
+ // For each redefined method
for (int j = 0; j < methods_length; j++)
methodOop old_method = old_methods[j];
methodOop new_method = new_methods[j];
- oop mem_name = find_member_name_by_method(old_method);
- if (mem_name != NULL)
- java_lang_invoke_MemberName::adjust_vmtarget(mem_name, new_method);
-
- if (RC_TRACE_IN_RANGE(0x00100000, 0x00400000))
- if (!(*trace_name_printed))
- // RC_TRACE_MESG macro has an embedded ResourceMark
- RC_TRACE_MESG(("adjust: name=%s",
- Klass::cast(old_method->method_holder())->external_name()));
- *trace_name_printed = true;
-
- // RC_TRACE macro has an embedded ResourceMark
- RC_TRACE(0x00400000, ("MemberName method update: %s(%s)",
- new_method->name()->as_C_string(),
- new_method->signature()->as_C_string()));
- 很幸运,只有methodhandles.cpp调用,而函数adjust_method_entries,只在redefineclass的时候调用就是在instrument的时候,目前比较红火的RASP技术的核心关键,关于instrument的博客请参考本人的instrument的系列博客:( http://blog.csdn.net/raintungli/article/details/51593269)
5. 如何修复?
既然问题出现在地址压缩上,那么修复就变的非常简单,只要压缩地址后保存就可以了mname->address_field_put(_vmtarget_offset, (address)ref);mname->obj_field_put(_vmtarget_offset, new_method);如果你不想修改代码?
- 一种方法比较简单,就是instrument的时候不修改methodhandle的类就好
- 既然问题出在压缩指针上,不压缩不就没问题了么?JVM提供了环境参数可以控制是否压缩指针
-XX:+UseCompressedOops这样一个完成的通过JVM crash 日志和core dump进行JVM的问题定位和分析结束了,希望能对你有所帮助。
以上是关于案例分享:如何通过JVM crash 的日志和core dump定位和分析Instrument引起的JVM crash的主要内容,如果未能解决你的问题,请参考以下文章