基于信息检索和深度学习结合的单元测试用例断言自动生成
Posted 华为云开发者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于信息检索和深度学习结合的单元测试用例断言自动生成相关的知识,希望对你有一定的参考价值。
摘要:本章节介绍基于IR的方法(包括基础的信息检索技术IRar以及自动适配技术RAadapt)和结合的方法。
本文分享自华为云社区《基于信息检索和深度学习结合的单元测试用例断言自动生成》,作者:华为云软件分析Lab 。
一、背景介绍
单元测试用来验证软件基本模块的准确性。跟其他层次的测试(比如集成测试和系统测试)相比,单元测试可以更快地帮助软件系统发现错误。同时在单元测试阶段发现错误可以大大降低整个软件测试流程的测试开销虽然单元测试很重要,但是编写单元测试用例往往很费时间。
为了减轻开发者编写单元测试用例的负担,软件测试领域的研究者提出多个单元测试用例自动生成工具,来为开发者编写的程序自动生成测试用例。这些工具从生成测试输入的角度可以分为如下三类:(1)随机测试,比如Randoop[3],它使用带反馈的执行机制来收集执行路径。(2)动态符号执行,比如JBSE[4],它通过动态符号执行技术来为复杂对象提供测试输入。(3)基于搜索,比如Evosuite[5],它应用遗传算法来生成和优化满足测试覆盖标准的测试输入。
上述测试用例自动生成工具除了可以自动生成测试输入之外,还可以自动生成断言。这些工具从生成断言角度可以分为如下两类:(1)捕获执行然后进行断言生成[6],比如Evosuite和Randoop都是通过在已经生成的测试序列的基础上,执行这些序列,然后捕获跟待测方法相关的对象状态的值,作为assertion中的值。(2)差异测试[7],比如DiffGen[8]通过在同一个类的两个版本上执行测试方法,然后通过比较函数调用返回值以及对象的中间状态来是否相同来生成多言。
虽然上述的测试用例生成工具可以生成断言,但是它生成的断言在找bug的能力方面非常受限。对于给定的一个版本,这些工具生成的断言只能找崩溃类型的bug,无法找逻辑相关的bug。为了更好地生成断言,近期Watson等人[2]提出ATLAS来生成断言。ATLAS是一个基于深度学习的方法,它通过给定的待测方法以及测试方法(除去断言部分),来生成断言。本文将待测方法以及测试方法(除去断言部分)简称为focal-test方法。在训练阶段ATLAS使用focal-test方法作为输入,使用数据对应的断言作为label来训练模型。然而ATLAS的效果受限于两个方面,第一,ATLAS基于深度学习,其可解释型不强。第二,ATLAS生成断言的准确率不够高(只有31%),并且ATLAS在生成长assertion(长度大于15个token)的效果很差,只有18%。
为了解决上述提到的问题,本文提出使用基于信息检索的方法IR(包含基础的信息检索技术IRar以及基于信息检索结果的自动适配技术RAadapt)来提升断言生成的准确性,除了基于信息检索的方法,本文同样提出一个结合方法来将IR和基于深度学习的方法(比如ATLAS)进行结合,进一步提升断言生成的准确度。本文在两个数据集上评估本文提出的方法跟ATLAS的对比,实验结果表明本文提出的方法在两个数据集上的准确率比ATLAS分别高15.12%和20.54%。
二、方法
本章节介绍本文提出的基于IR的方法(包括基础的信息检索技术IRar以及自动适配技术RAadapt)和结合的方法。图1展示了本文提出的方法的整体流程图。给定一个Focal-test方法,本文首先通过IRar技术到训练集中检索最相似的Focal-test方法,并将其对应的assertion作为检索到的assertion返回。接着本文提出自动适配技术RAadapt,RAadapt技术包括两个适配策略:基于启发式搜索(RAadaptH)的适配和基于神经网络(RAadaptNN)的适配。最后本文基于相容模型提出一个结合的方法,来智能的选择应用适配完之后生成的assertion还是应用基于深度学习方法(ATLAS)生成的assertion。文本方法部分的详细介绍请参见本文发表在国际软件工程会议的论文[1]。

图1 本文提出的断言生成的方法流程图
2.1 IRar

2.2 RAadapt

2.3 Integration
本文通过计算测试集中的focal-test、模型生成的assertion以及基于信息检索方法生成的assertion的相容度来决定使用模型生成assertion还是使用基于信息检索的方法生成assertion。
三、实验设置
3.1 实验数据集
表1详细展示了本文用到的两个数据集中断言类别及个数的分布情况。

3.1.1 Datasetold
本文将ATLAS使用的数据集记为Datasetold,它是从GitHub的开源项目中挖掘得到。Datasetold将所有assertion中存在的token但是没有出现在focal-test方法中的数据全部去掉因为ATLAS无法为这些数据成功生成断言。最终Datasetold包含156,760条数据,并以8:1:1划分训练集、验证集和测试集。
3.1.2 Datasetnew
实际上ATLAS使用的Datasetold数据集是去掉了有挑战性的数据,进而简化了断言生成任务的评估。因此本文进一步通过将ATLAS去掉的数据加回到数据集中来构造一个更有挑战性的数据集,本文将该数据集记为Datasetnew。最终Datasetold包含265,420条数据,并以8:1:1划分训练集、验证集和测试集。
3.2 评估指标
本文使用的评估指标更ATLAS一致,使用准确率和BLEU值来评估本文提出的方法的有效性。
3.2.1 准确率
本文认为生成的断言准确的标准是断言在字符串级别完全相等。
3.2.2 BLEU值
BLEU值在自然自然语言处理领域被广泛使用,它用来评估生成的句子跟标注的句子的相似性。本文使用BLEU值来评估本文方法生成的断言跟标注的断言的相似性。
四、实验结果
4.1 IRar方法的有效性
4.1.1 IRar方法整体效果分析
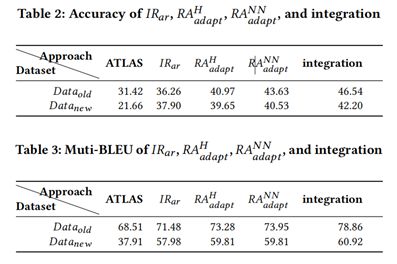
表2和表3的第三列展示了IRar方法在两个数据集上的准确率和BLEU值,从表中可以看到在两个数据集上,IRar方法在准确率和BLEU值上的表现都要明显优于ATLAS。

表4展示了IRar和ATLAS在每个断言类别上的准确率,从表中可以看到IRar在每个断言类别上的准确率都要优于ATLAS,进一步证明了IRar方法的有效性。
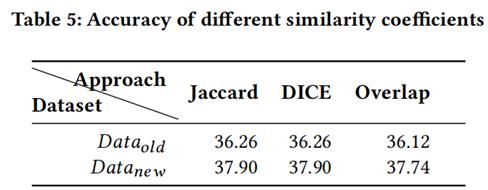
表5展示了IRar使用不同相似度系数检索的准确率,从表中可以看到不同的相似性系数对IRar的准确率影响不大,证明了IRar方法的普适性。
4.1.2 ATLAS和IRar成功生成的assertion
为了进一步研究ATLAS和IRar生成的assertion,我们首先分析ATLAS和IRar成功生成的assertion。
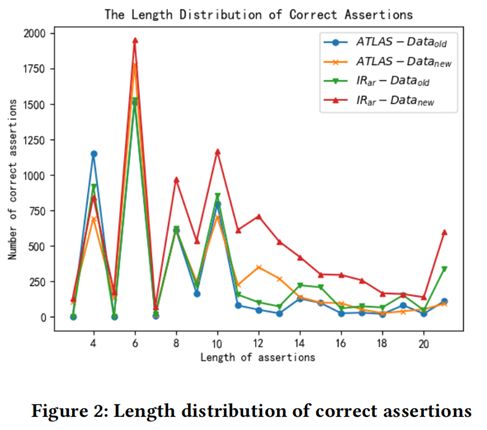
图2展示了ATLAS和IRar成功生成的断言语句的平均长度。从图中可以看出,在生成长的断言语句时,IRar比ATLAS效果更好。本文统计发现,在Datasetold数据集上,ATLAS和IRar成功生成的断言语句的长度平均分别为7.98和8.63,在Datasetnew数据集上,ATLAS和IRar成功生成的断言语句的长度平均分别为9.74和10.74。
接着本文分析ATLAS成功生成的断言语句中,有多少出现在训练集中(IRar生成的断言语句肯定全部都出现在训练集中)。经过统计本文发现,ATLAS正确生成的断言语句中,绝大多数都在训练集中出现过(其中Datasetold数据集中92.59%,Datasetnew数据集中98.76%)。实验结果表明ATLAS成功生成“新”的断言的能力还很弱。
4.1.3 ATLAS和IRar不能成功生成的assertion
在研究了ATLAS和IRar能成功生成的断言之后,本文接着分析ATLAS和IRar不能成功生成的断言。
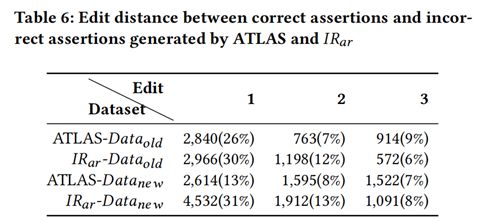
表6展示了ATLAS和IRar不能成功生成的断言距离标注断言的编辑距离。从表中可以看到,约40%-50%不能成功生成的断言可以在修改三个token的情况下将其改对。

表7展示了当编辑距离为1时,该token的类别。从表中可看到,常量是最需要开发者主要修改的地方。
4.2 RAadapt方法的有效性
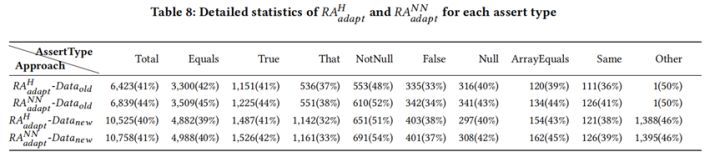
表8展示了RAadaptH和RAadaptNN在不同断言类型的准确率,实验结果表明RAadaptH和RAadaptNN在不同断言类型上的准确率都高于ATLAS,同时RAadaptNN可以达到最高的准确率。
4.3 结合方法的有效性
4.3.1 基于信息检索方法和基于深度学习方法的互补性
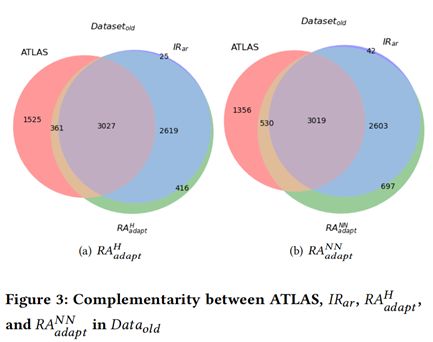
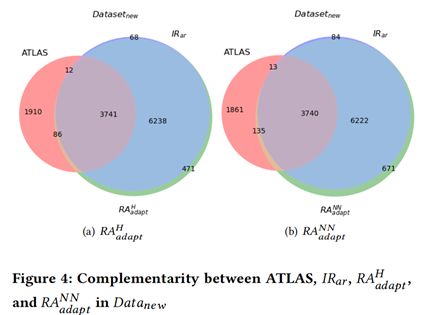
图3和图4分别展示了基于信息检索方法和基于深度学习方法在两个数据集上的的互补性。从图中我们可以看到,两种方法存在很强的互补性。因此本文进一步提出了结合的方法。
4.3.2 结合方法的准确率

表9展示了本文提出的结合的方法在不同断言类型的准确率,实验结果表明结合方法可以在两个数据集上达到最好的效果
五、 总结
本文首次尝试在断言生成中利用信息检索 (IR),并提出了一种基于 IR 的方法,包括IRar技术和RAadapt技术。本文还提出了一种结合方法,用于结合基于 IR 的方法和基于 DL 的方法(例如 ATLAS),以进一步提高有效性。本文的实验结果表明,IRar要比ATLAS 更有效,在两个数据集上分别达到 36.26% 和 37.90% 的准确率。此外,本文的RAadapt技术可以在两个数据集上分别达到 43.63% 和 40.53% 的准确率。最后,结合的方法在两个数据集上实现了 46.54% 和 42.20% 的准确率。本文的工作传达了一个重要信息,即基于 IR 的方法对于软件工程任务(如断言生成)具有竞争力且值得追求,鉴于近年来DL解决方案已经过分流行,研究社区应该认真考虑如果更准确有效地将DL用于软件工程任务。
文章来自北京大学、华为云PaaS技术创新Lab;PaaS技术创新Lab隶属于华为云(华为内部当前发展最为迅猛的部门之一,目前国内公有云市场份额第二,全球第五),致力于综合利用软件分析、数据挖掘、机器学习等技术,为软件研发人员提供下一代智能研发工具服务的核心引擎和智慧大脑。我们将聚焦软件工程领域硬核能力,不断构筑研发利器,持续交付高价值商业特性!加入我们,一起开创研发新“境界”!(招聘接口人:guodongshuo@huawei.com; huwei18@huawei.com;)
PaaS技术创新Lab主页链接:PaaS技术创新Lab-华为云
参考文献
- Hao Yu, Yiling Lou, Ke Sun, Dezhi Ran, Tao Xie, Dan Hao, Ying Li, Ge Li, Qianxiang Wang. 2022. Automated Assertion Generation via Information Retrieval and Its Integration with Deep Learning. In Proceedings of the 42th IEEE/ACM International Conference on Software Engineering (ICSE), https://taoxiease.github.io/publications/icse22-assertion.pdf
- Cody Watson, Michele Tufano, Kevin Moran, Gabriele Bavota, and Denys Poshyvanyk. 2020. On Learning Meaningful Assert Statements for Unit Test Cases. In Proceedings of the 42th IEEE/ACM International Conference on Software Engineering (ICSE). 1398–1409. https://doi.org/10.1145/3377811.3380429
- Carlos Pacheco and Michael D. Ernst. 2007. Randoop: Feedback-Directed Random Testing for Java. In Companion to the 22nd ACM SIGPLAN Conference on ObjectOriented Programming Systems and Applications Companion (OOPSLA). 815–816. https://doi.org/10.1145/1297846.129790
- Pietro Braione, Giovanni Denaro, and Mauro Pezzè. 2016. JBSE: A Symbolic Executor for Java Programs with Complex Heap Inputs. In Proceedings of the 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering (ESEC/FSE). 1018–1022. https://doi.org/10.1145/2950290.2983940
- Gordon Fraser and Andrea Arcuri. 2011. EvoSuite: Automatic Test Suite Generation for Object-Oriented Software. In Proceedings of the 19th ACM SIGSOFT Symposium and the 13th European Conference on Foundations of Software Engineering (ESEC/FSE). 416–419. https://doi.org/10.1145/2025113.2025179
- Tao Xie. 2006. Augmenting Automatically Generated Unit-Test Suites with Regression Oracle Checking. In Proceedings of the 20th European Conference on Object-Oriented Programming (ECOOP). 380–403. https://doi.org/10.1007/11785477_23
- Robert B. Evans and Alberto Savoia. 2007. Differential Testing: A New Approach to Change Detection. In Proceedings of the 6th Joint Meeting on European Software Engineering Conference and the ACM SIGSOFT Symposium on the Foundations of Software Engineering: Companion Papers (ESEC/FSE). 549–552. https://doi.org/10.1145/1295014.1295038
- Kunal Taneja and Tao Xie. 2008. Automated Regression Unit-Test Generation. In Proceedings of the 23rd IEEE/ACM International Conference on Automated Software Engineering (ASE). 407–410. https://doi.org/10.1109/ASE.2008.60
以上是关于基于信息检索和深度学习结合的单元测试用例断言自动生成的主要内容,如果未能解决你的问题,请参考以下文章